
下载掌阅APP,畅读海量书库
立即打开



无论采取何种隐私理论和规范,因技术变革而产生的隐私威胁终究要依靠技术本身来缓解,这也是本书的核心内容。 隐私保护计算 (Privacy-Preserving Computation,PPC)是在计算过程中解决隐私问题的一系列技术方案,涉及密码学、统计学、人工智能等诸多学科和领域的知识。长期以来,隐私保护计算以 隐私增强计算 (Privacy-Enhancing Computation,PEC)和 隐私感知计算 (Privacy-Aware Computation,PAC)等名称出现,并蕴含了以下3个关键问题。第一,隐私保护计算涉及哪些参与角色,这些角色的具体任务和潜在威胁是什么?第二,隐私保护计算支持哪些计算类型,每种类型的计算方式和性能度量方法是什么?第三,隐私保护计算提供哪些隐私保证,各项保证的基础理论和支撑技术是什么?接下来,本节依次回答这些问题。
隐私保护计算的工作流程涉及许多角色,他们往往具有不同的能力,并承担着不同的职能。通常,隐私保护计算的参与方分为 数据提供者、隐私服务者、结果使用者 3类,各方之间的关系如图2.4所示。 市场监管者 负责对各参与方进行认证、评估与审计,既不接触数据,也不提供与数据处理相关的服务。
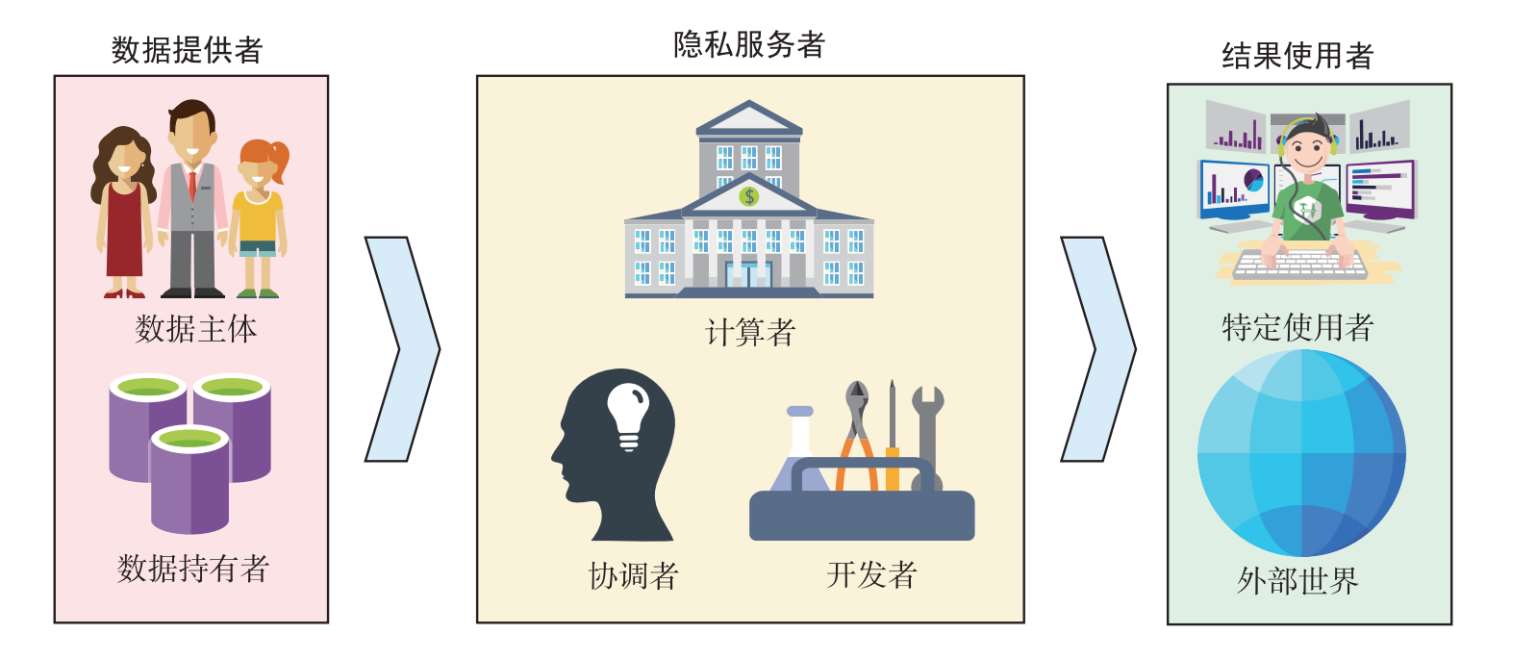
图2.4 隐私保护计算的参与方
数据提供者负责供应隐私保护计算所需要的数据,并对相应的处理规则进行授权。根据数据来源的不同,数据提供者可以分为数据主体与数据持有者两类。前者是直接生产数据的自然人,因而又称为数据所有者。后者则是持有数据的组织,其事先从数据主体处收集相关数据。隐私保护计算可能涉及多个数据提供者。为实现信任最小化,他们可以采取一系列保护措施,包括将原始数据留存在本地或对其进行预处理等。
隐私服务者负责提供隐私保护计算所需要的技术方案、基础设施及管理能力。根据工作职能的不同,隐私服务者可以分为开发者、计算者及协调者等。开发者负责对算法流程进行设计、开发与验证,必要时可对算法参数进行保密。计算者提供算力支持,其接收数据提供者的输入,并将输出发送给结果使用者。协调者按照约定配置隐私保护计算任务,并将计算所需的信息分发给各参与方。当数据提供者变更授权时,隐私服务者应及时做出响应,如删除相关数据及其依赖数据。
结果使用者负责接收隐私保护计算的成果,并对其进行二次加工与处理。根据限制条件的不同,结果使用者可以分为特定使用者和外部世界两类。前者在使用目的和范围等方面受到制约,因而在进行操作时仍需考虑隐私问题。后者则不受任何限制,也无须存在任何隐私顾虑。隐私服务者应根据结果使用者的不同采取不同等级的保护措施。
在实际应用中,数据提供者、隐私服务者及结果使用者这3类角色往往存在重叠。数据提供者经常作为结果使用者,享受隐私保护计算带来的红利;而隐私服务者亦常作为数据提供者和结果使用者,与其他数据提供者一同开展联合计算。本书后续章节中将根据语境进行判别。
在理想情况下,每个角色都各司其职,除了履行自己的义务,不会关心其他任何事情。然而,在好奇与利益的驱使下,无论数据提供者、隐私服务者,还是结果使用者,均有可能改变初心,从而对隐私构成威胁。根据攻击行为的不同,攻击者可以分为 半诚实攻击者 (semi-honest adversary)和 恶意攻击者 (malicious adversary)两类。半诚实攻击者又称为被动攻击者或诚实但好奇(honest-but-curious)攻击者,其会诚实地执行协议,但也会竭尽所能地获得更多信息。恶意攻击者又称为主动攻击者,其可以在协议执行期间采取任意行动,以使协议的执行偏离原有目的。从数据提供者的视角看,半诚实的数据提供者可以监视所有源自隐私服务者的中间计算结果,而恶意的数据提供者则可以在此基础上篡改计算过程。从隐私服务者的视角看,半诚实的隐私服务者可以监视所有源自数据提供者的信息,而恶意的隐私服务者同样可以篡改计算过程。从结果使用者的视角看,半诚实的结果使用者可以通过黑盒模式或白盒模式监视最终的计算结果。
从字面上看,隐私保护计算包含“隐私”与“计算”两个要素。在进一步触及“隐私”之前,本小节对“计算”加以介绍。简单来说, 计算 (computation)是一种可机械化的过程,用于在给定输入的情况下产生相应的输出。在讨论计算时,有必要对规范(specification)和实现(implementation)这两个概念进行区分。前者关心需要执行什么任务,即通过函数确定输入与输出的关系,这也是本小节的重点。后者则关心如何执行这项任务,即通过程序设法将输入变换为输出,我们将在本书后续章节中看到各式各样的算法。
根据输出性质的不同,计算任务可以分为面向个人的计算和面向群体的计算,如图2.5所示。 面向个人的计算 是指数据的处理结果仍然针对个人,会对个人的活动产生直接或间接的影响,如信息检索、集合求交等。 面向群体的计算 是指数据的处理结果仅与群体相关,不针对具体个人进行识别、分析或评估,如统计推断、机器学习和数据合成等。下面简要介绍这些任务。
信息检索 (information retrieval)是一种协议,它允许客户端从拥有数据库的服务器中检索其选择的数据项。信息检索的目标是在消耗较少的情况下快速、全面地返回准确结果,对应的性能指标分别为响应时间、查全率(recall)和查准率(precision)。
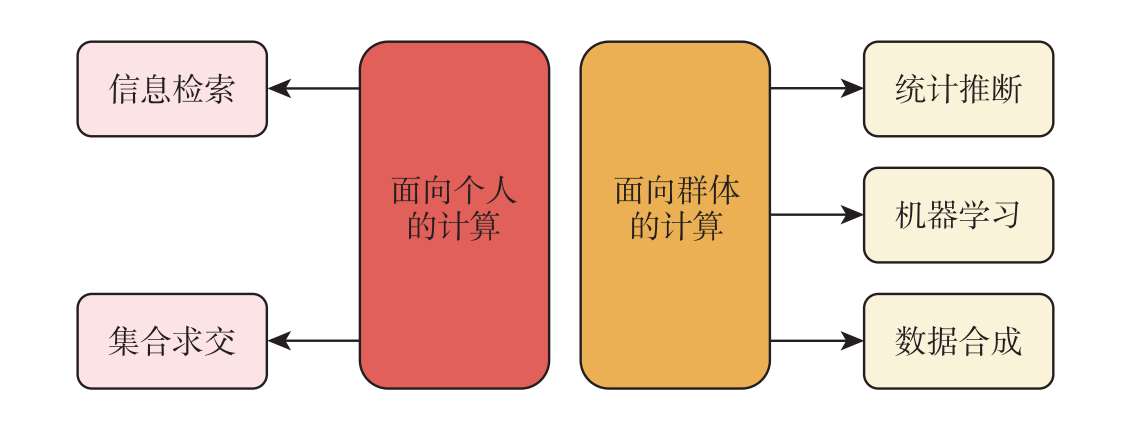
图2.5 计算类型
集合求交 (set intersection)允许持有各自集合的多方共同计算集合的交集。在多方联合参与计算的场景中,集合求交是计算前的关键步骤,用于找到多个数据提供者共有的数据样本,如纵向联邦学习中的数据对齐。在设计集合求交的方案时,通常需要考虑多方集合极度不均衡,以及通信、计算和内存开销等问题。
统计推断 (statistical inference)是一种从样本特征推断总体特征的方法,它能够对统计总体的参数(如期望、方差等)做出概率性的陈述。统计推断的基本问题可以分为参数估计和假设检验两大类。其中,参数估计的目标是估计总体参数的真值,而假设检验的目标是判断总体的先验假设是否成立。一个好的估计量应该在多次观测中,其观测值能够围绕被估计参数的真值摆动,具体的衡量指标有无偏性(unbiasedness)、有效性(eficiency)和一致性(consistency)。当试验者决定接受或拒绝原假设时,犯错的概率可以用来评估和比较假设检验。
机器学习 (machine learning)专注如何通过计算机来模拟或实现人类的学习行为,以获取新的知识或技能,并不断提高其性能。机器学习算法的核心是通过模型训练提取样本数据的特征和规律,并使用这些信息对未来数据做出预测。机器学习强调所学模型对“新样本”的适用性,即模型的泛化能力,具体的评估指标包括准确率(accuracy)、查全率和查准率等。需要注意的是,相同的性能度量可能会让不同的机器学习模型产生不同的结果,这意味着机器学习模型的“好坏”不仅取决于算法和数据,还取决于任务需求。
数据合成 (data synthesis)是通过计算机程序人为地产生模拟数据的过程。该人工模拟数据可以从统计学的角度反映真实数据的分布,还可以节省数据采集的成本。由于潜在目的不同,数据合成的评估需要在保真度(fidelity)和多样性(diversity)两个方面进行权衡。前者指生成的模拟数据与真实数据在统计性质上的逼近程度。
信息隐私与个人对自我信息的控制有关,而这种控制通常可以分为以下3个方面,如图2.6所示。
输入隐私 (input privacy)规定“如何计算”。具体来说,它的作用是确保隐私服务者不能访问或推导数据提供者的任何输入,以及计算过程中所产生的任何中间结果。这无疑很好地限制了个人信息的流动,杜绝了隐私服务者通过侧信道攻击获得原始数据的可能。输入隐私的概念适合各参与方互不信任的环境,任何一方如果获得比约定输出更多的知识,都会被视为隐私侵犯。
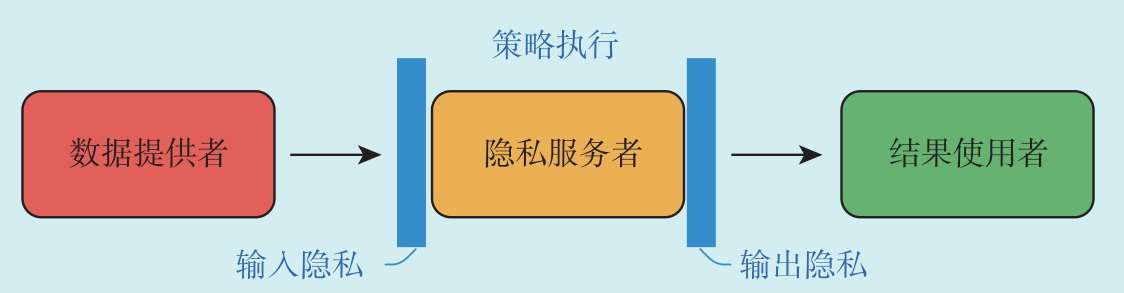
图2.6 隐私保证
输出隐私 (output privacy)决定“披露什么”。具体来说,它的作用是确保隐私服务者的输出中不包含任何超出数据提供者允许范围的可识别信息。这一方面使得结果使用者无法从输出中推断出与数据提供者相关的信息,另一方面也允许数据提供者对隐私泄露的程度进行度量和限制。输出隐私的概念十分适合数据发布场景,它使得敏感数据的公开成为可能。
策略执行 (policy enforcement)与控制高度相关,包括但不限于“能算什么”和“向谁披露”。它的作用是确保已制订的隐私策略和计算策略能够按预期执行。与输入隐私和输出隐私不同,策略执行覆盖了所有角色,它能够对各参与方的行为加以规范,使其遵守预先达成的各项协议。