
下载掌阅APP,畅读海量书库
立即打开



在目前的科学研究中,相对简单的问题已经解决得差不多了,剩下未解决的都异常复杂。台风的形成、大脑的运作、致病基因……要揭开潜藏在这些复杂现象背后的规律,就必须理解它们的成因网络,将纷乱如麻的事件梳理清楚。用基于穷举法的联合概率分布显然不可行。科学家为了从众多可想到的原因中确定那些他们认为最为匹配的原因,过去是依靠直觉在已经掌握的知识中搜寻,希望找到一个可以弥补数据空白的方法,而这恰恰就是贝叶斯公式能做到的。
现在科学家只需将所有假设代入贝叶斯公式,就能得到正确的概率。而要破解某种现象的成因,不必依靠直觉,只需要将公式编织成网络。公式网络化真的能解决难题?这一想法的提出经历了悠长的过程,直到20世纪80年代才终于被美国数学家珀尔证明,使用数百个贝叶斯公式结成网络真的就可以推测出复杂问题背后的成因。

图 3-22 珀尔
珀尔1936年出生于以色列的特拉维夫,1960年他去美国深造。5年后,他如愿在罗格斯大学取得了物理学硕士学位。同时,珀尔又拿到了电气工程学博士学位。现在,珀尔在加利福尼亚大学担任计算机科学系的教授,兼任该校认知科学实验室的主任。1985年他提出了贝叶斯网络的构想,1986发表因果推断方面奠基性的论文《信念网络中的融合、传播和结构化》。2011年珀尔教授由于这两项工作被授予了誉为“计算机领域诺贝尔奖”的图灵奖。
珀尔提出贝叶斯网络与概率推理是由于当时专家系统面临的困境。专家系统是一种智能计算机系统,其中含有特殊领域的具有专家水平的经验和知识,使得非此领域的人能借助计算机使用专家的经验,我们在后面第11章会说到。早期的专家系统中,基于规则的专家系统占有主要地位,它的知识库是由多个“If-then”语句构成,并且使用符号推理。但是这样的系统很难应对充满不确定性的真实环境。概率方法正是处理不确定性的数学方法,概率推理应运而生。在珀尔之前,人们普遍认为概率论不适用于专家系统,主要原因首先在于当时频率学派占据了支配地位,老一辈的统计学家坚持只有在相同条件下可以重复无数次试验的概率才有意义,这就排除了对一次性事件谈论概率的可能性。其次是当时人们还没发现可以将联合概率分布分解成多个较为简单的概率分布。 珀尔的贝叶斯网络关键是用到了变量间的条件独立关系,从而降低了运算的难度,使得人们可以用最简单的概率方法来解决大型问题。从此之后,能够运行大型贝叶斯网络计算程序的计算机也日益增多。
珀尔构建贝叶斯网络的操作原理是这样的:如果我们并不清楚一个现象的原因,就首先根据我们认为最有可能的原因来建立一个模型——计算机程序。然后将每个可能的原因连接入网络,根据我们的主观概率给每条连接分配一个先验概率值。换句话说,网络中的每个节点都通过贝叶斯公式和其他节点相连。接下来,只需向这个计算机程序输入观测数据,通过网络节点间的贝叶斯公式计算出后验概率值即可。为每一个新数据、每一条连接重复这一计算——直到形成一个网络图,所有原因的连接都得出精确的后验概率值。最后挑选使得后验概率值最大的原因,这事便成了!现今,贝叶斯网络在医疗诊断中被用于对病人所患的疾病类别和程度进行确诊,在工业中被用于对产品故障的原因进行分析,在计算机系统中被用于比如在Windows和Office中嵌入打印机故障诊断程序和用户助手程序,在通信领域为iPhone的Siri语音识别奠定了基础。不过现在贝叶斯网络已有被马尔科夫网络取代之势。

图 3-23 专家系统的早期平台
现在让我们来说说贝叶斯网络的一个特例——朴素贝叶斯分类器。这属于当今机器学习的领域。
机器学习与数据分析有极广的交集和延伸。机器学习大致被分为符号学派和统计学派,早期由符号学派掌舵,现在被统计学派掌管。数据分析与机器学习相交的部分就是统计学派的机器学习。后文讨论的机器学习都是指统计学派的机器学习,即统计机器学习。机器学习、统计机器学习与统计学习也不再加以区别。机器学习是如今红透了的人工智能(具体什么是人工智能将于第7章介绍)的一个子领域,研究的是如何让计算机模拟人类的学习行为,从经验数据出发,通过学习不断提高自己完成某项任务的能力。机器学习的三大主题是预测、聚类和分类,朴素贝叶斯分类器属于其中的一个主题——分类,简单来说分类是从一系列给定类别的数据出发,为下一个未知类别的数据归类。朴素贝叶斯分类器最早由华纳等人于1961年提出,用于先天心脏病的诊断。它是一个包含一个“根”和多个“叶”的树,如下图。
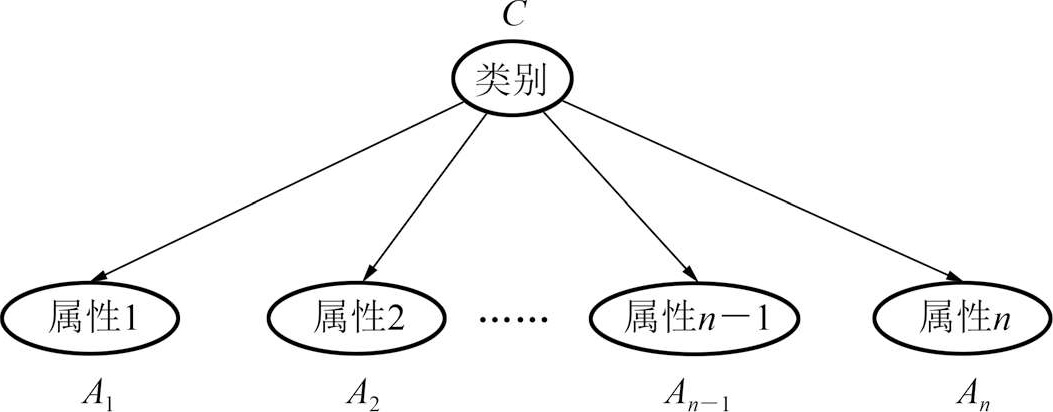
图 3-24 朴素贝叶斯分类器
其中叶节点 A 1 ,…, A n 都是属性变量,表示待分类对象的属性,根节点 C 是类别变量,表示对象的类别。用此分类器进行分类就是给定一个数据点,即各属性变量的取值 A 1 = a 1 ,…, A n = a n ,计算后验分布 P ( C | A 1 = a 1 ,…, A n = a n ),然后选择概率最大的那个 C 值作为这个数据点所属的类别。这个模型内含一个简单的局部独立假设,即给定类别变量 C ,各属性变量 A i 相互条件独立(注7)。
实际上,朴素贝叶斯分类器经常用于文本分类,比如文章作者识别、文章主题分类以及办公时很常用的垃圾邮件过滤等 [20] 。继续看上面那棵树,以过滤垃圾邮件为例,其中的原理大致上就是把类别 C 分为两类: C 1 是垃圾邮件, C 2 是正常邮件。属性 A 1 , A 2 ,…, A n 就是邮件文本中的单词 a 1 , a 2 ,…, a n (要去除没有意义的单词如and、but和or等,另外还要将单词如hello、HELLO和Hello都作为单词hello来处理,以及需要其他一些清理步骤)。然后根据这些出现在文本中的单词,用贝叶斯定理结合局部独立假设来计算后验概率 P ( C | A 1 = a 1 ,…, A n = a n )。最后概率较大的如果是 C 1 ,那就是垃圾邮件,如果是 C 2 ,就是正常邮件。更具体地,问题可以被描述为求:
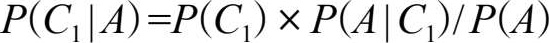
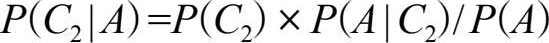
其中 P ( C 1 )和 P ( C 2 )这两个先验概率都是很容易求出来的,只需要计算邮件库里面垃圾邮件和正常邮件的比例就行了。然而 P ( A | C 1 )却很难求,因为 A 里面含有 n 个单词 a 1 , a 2 ,…, a n ,即 P ( A | C 1 )= P ( a 1 , a 2 ,…, a n | C 1 )。我们用乘法公式将 P ( a 1 , a 2 ,…, a n | C 1 )展开为 P ( a 1 | C 1 )× P ( a 2 | a 1 , C 1 )× P ( a 3 | a 2 , a 1 , C 1 )×…。利用局部独立假设,给定 C = C 1 时 a i 与 a i -1 是相互条件独立的,式子就简化为 P ( a 1 | C 1 )× P ( a 2 | C 1 )× P ( a 3 | C 1 )×…。而计算 P ( a 1 | C 1 )× P ( a 2 | C 1 )× P ( a 3 | C 1 )×…就简单了,只要统计 a i 这个单词在垃圾邮件中出现的频率即可。这个所谓的局部独立假设却是朴素贝叶斯方法的“非凡”之处,一点也不“朴素”,虽然很理想化效果却出奇的好,原因有很大的可能性是由于各个独立假设所产生的消极影响和积极影响互相抵消,最终导致结果受到的影响不大,有兴趣的读者请参阅文献 [21] 。接下来用同样的方法计算正常邮件的概率 P ( A | C 2 ),然后计算出 P ( A )= P ( C 1 )× P ( A | C 1 )+ P ( C 2 )× P ( A | C 2 ),这在初等概率论中被称为全概率公式。搞定 P ( C 1 )、 P ( A | C 1 )和 P ( A )后就得出了垃圾邮件的后验概率 P ( C 1 | A )。同样的方法可以计算正常邮件的后验概率 P ( C 2 | A ),最后比较两者大小得出最终结论。