
下载掌阅APP,畅读海量书库
立即打开



如何研究随机现象的统计规律性并为科学决策提供有效的依据,是“概率论与数理统计”课程需要解决的核心问题.先看一个有关管理人员年薪的具体案例.
例 1.2.1 某部门负责人将为公司制订一份简报,内容包括 2018 年中层管理人员的年龄和年薪分布情况.该负责人可调取原始数据,获得 2 500 名中层管理人员的年龄和年薪作为研究总体,并进一步分析年龄和年薪分布的总体特征.但是在实际情况下,可能因为个人隐私、节约成本和时间等现状,无法获得 2 500 名中层管理人员的年龄和年薪.这时,该负责人需要考虑的是,随机抽取一部分中层管理人员的年龄和年薪构成研究样本,并以此推测出所有中层管理人员年龄和年薪分布的统计规律.假定随机选择 30 名中层管理人员的年龄(单位:岁)和年薪(单位:万元)构成研究样本,见表 1.2.在此基础上分析年龄和年薪的分布特征并编写简报,显然比分析 2 500 名人员的年龄和年薪要节约时间和成本.
表 1.2
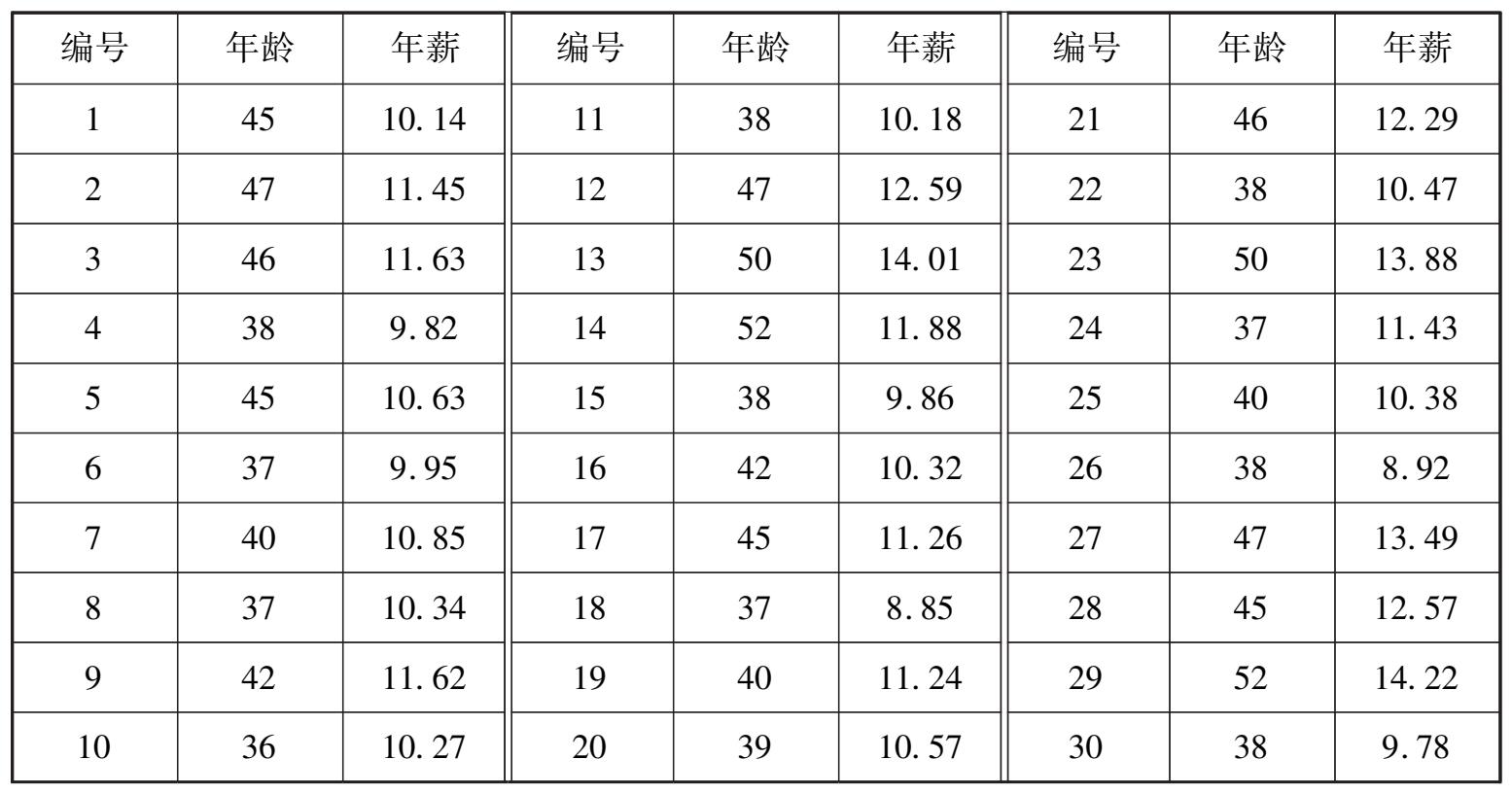
思考以下问题:
①30 个样本数据的图形和数字特征如何?(描述统计问题,见第 1 章)
②是否可以用这 30 名中层管理人员的年薪数据来推测 2 500 名中层管理人员年薪的分布特征?需要怎样的前提假设?(抽样问题,见第 5 章)
③如何用 30 名中层管理人员的年薪来推测所有中层管理人员的平均年薪?精确度如何计算?(参数估计问题,见第 6 章)
④如果上一年度所有中层管理人员的平均年薪是 10.5 万元,能否认为本年度的平均年薪超过上一年度的平均年薪?作此推论有多大把握?(假设检验问题,见第 7 章)
⑤年薪和年龄之间是否具有某种相依关系?(回归分析问题,见第 8 章)
在上述问题中,如果只研究年薪(或年龄)问题,每名中层管理人员的年薪(或年龄)是研究个体,2 500 名中层管理人员的年薪(或年龄)是研究总体,随机抽取的 30 名中层管理人员的年薪(或年龄)是研究样本,每名管理人员的具体年薪(或年龄)称为样本值,30 个样本值构成样本数据集.如果要研究年龄和年薪之间的关系,则每名中层管理人员的年龄和年薪是研究个体,2 500 名中层管理人员的年龄和年薪是研究总体,随机抽取的 30 名中层管理人员的年龄和年薪是研究样本.
将研究对象全部元素构成的集合称为 总体 ,组成总体的每个元素称为 个体 .总体中所含个体的个数,称为总体的 容量 ,它可以有限个、无限可列个或无限不可列个.为了研究推断总体的统计规律性,我们经常从总体中抽取一个子集,称为 样本 .每一个样本的测量值称为 样 本值 ,所有样本值构成样本数据集.
如何有效地收集、整理样本数据,并对样本数据分析研究,从而推断出总体的性质、特点和统计规律性,这就是统计分析的目的.比如,为了估计某顾客群体的平均年龄,只需要收集部分顾客的年龄信息,得到平均年龄的估计值后,就可以针对这个年龄层的顾客投放广告.
统计分析涉及两个不同的阶段:①描述统计,即利用所得到的数据绘制统计图(直观粗略地反映研究对象的规律),并计算数字特征值(反映数据的集中趋势和分散程度等).②推断统计,即根据样本信息对研究总体进行推断,包括推断研究对象的分布规律、不同因素间的相关性、多个因素间的统计关系等.
推断统计主要建立在研究不确定性现象的理论——概率论的基础上.概率论是统计分析的理论基础,而且在金融、保险、会计等领域有着广泛的应用.
基于上述分析,本书的基本知识结构如图 1.1 所示.第 1 章简单介绍描述统计学,第 2—4 章学习概率论的基本理论,第 5—8 章在概率论的基础上学习推断统计学.
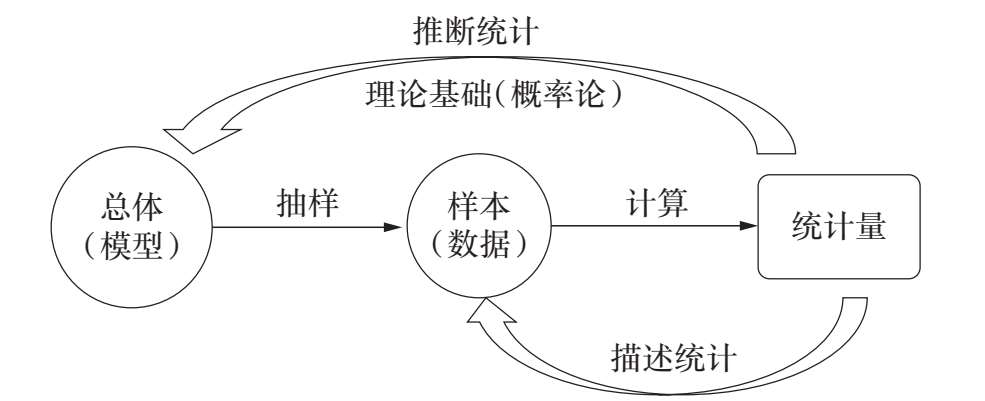
图 1.1
统计是关于数据的科学.表格和图形是呈现数据的直接方式,能揭示数据的重要特征,如数据的范围、集中程度和对称性.通过图形和表格,对例 1.2.1 中的问题①进行分析.
例 1.3.1 把薪酬分为 4 个类别:≤ 9 万元、9 万 ~ 11 万元、11 万 ~ 13 万元、≥ 13 万元,并编制频数分布表,简称 频数表 ,见表 1.3,这里每个类别的人数,就是对应类别的频数.每个类别的观测个数占总数的比例,就是 相对频数 (或 频率 ),反映该类别在总体中所占的比重.有时人们感兴趣的是 累积频数 ,将各类别的频数逐级累加起来,而 累积相对频数 就是将各类别的相对频数逐级累加起来.
表 1.3

相对频数可以用直方图或饼状图表示,如图 1.2 所示.

图 1.2
面对海量的数据,人们常用数值方法进行定量描述.常用方法有两种:①数据的集中趋势测度,即描述数据聚集的趋势或某些数据的中心位置,如图 1.3(a)所示;②数据的变异性测度,即描述数据的分散状况,如图 1.3(b)所示.

图 1.3
最常用、最容易理解的反映数据集中趋势的统计量是数据集的算术平均数(简称为均值).
定义 1.4.1 设有 n 个样本值 x 1 , x 2 ,…, x n ,其 样本均值 定义为

另外,描述样本中心位置的统计量是样本中位数和样本众数.
定义
1.4.2
将样本值
x
1
,
x
2
,…,
x
n
从小到大排列
 <
<
 <
…
<
<
…
<
 ,处于中间的数值就是
样本中位数
,计算公式为
,处于中间的数值就是
样本中位数
,计算公式为

定义 1.4.3 样本众数 是指样本数据中出现次数最多的测量值.
例 1.4.1 计算下列样本测量值的样本均值、样本中位数和样本众数.
样本测量值:5,3,8,5,6.

样本值从小到大排列:3,5,5,6,8,样本中位数和样本众数都是 5.
样本均值和样本中位数是描述数据中心位置十分有用的统计量.样本均值对所有的样本值求平均,容易受离群值(远离数据一般水平的特别大或特别小的值)的影响.而样本中位数只利用一个或两个中间值,不受离群值的影响.例如,在分析某专业联盟中球员的薪酬时,其中几个顶级球星(如詹姆斯、科比等)的薪酬就是离群值,将对薪酬的均值产生比较大的影响,此时中位数能更准确地描述该联盟中球员平均薪酬的状况.样本均值和样本中位数哪个更实用取决于问题的实际背景.
样本均值和样本中位数可分别用Excel软件中的AVERAGE函数和MEDIAN函数得到.
例 1.4.2 利用Excel软件,计算例 1.2.1 中 30 名中层管理人员年薪的均值和中位数.
解 (1)将数据一次输入单元格A1 至A30.
(2)在某一空白单元格(如B1 )中输入“= AVERAGE ( A1: A30 )”,得到样本均值11.163,即平均年薪为 11.163 万元.
(3)在某一空白单元格(如B2)中输入“=MEDIAN(A1:A30)”,得到样本中位数 10.74,即年薪的中位数为 10.74 万元.
集中趋势的测度提供了数据集的一部分描述,不包括数据集的变异性(分散)描述.例如,要比较一家大型建筑公司的两个子公司A和B的工程利润率(利润占总标价的百分比).假设两个子公司分别承包了 100 个工程,它们的平均利润相等,但是子公司A的利润率更加平稳(大多数工程的利润率集中在数据集中心的周围),而子公司B的利润率具有更大的变异性(大多数工程的利润率取值更分散).通过变异性测度来描述数据集的分散程度,其中最简单的统计量是它的极差.
定义 1.4.4 样本数据集的 极差 等于它的最大测量值减去最小测量值.
数据集的极差很容易计算和理解.但是,当数据集很大时,它对数据变化的反应是不敏感的.有时两个数据集的极差相同,但是在数据变化上有很大不同.下面探讨一种比极差更灵敏的描述数据变异程度的方法,即样本方差和样本标准差.
如果样本值集中在样本均值周围,则对应较小的变异性;反之,对应较大的变异性.每个样本值
x
i
在样本均值
 周围的集中程度通过绝对值
周围的集中程度通过绝对值
 来量化.为便于计算,改用平方
来量化.为便于计算,改用平方
 .一组样本值对样本均值的变异性,用所有样本函数值
.一组样本值对样本均值的变异性,用所有样本函数值
 的平均值来度量,称为样本方差.
的平均值来度量,称为样本方差.
定义 1.4.5 设有 n 个样本值 x 1 , x 2 ,…, x n ,其 样本方差 定义为

这里平均值的分母是 n - 1 而不是 n ,将在第 5 章具体说明.为消除样本方差表达式中因平方导致的量纲影响,可对样本方差进行开方处理.
定义 1.4.6 样本方差的算术平方根称为 样本标准差 ,其表达式为

例 1.4.3 计算例 1.4.1 中样本的方差和标准差.

样本方差和样本标准差可分别用Excel软件中的VAR和STDEV函数得到.
例 1.4.4 计算例 1.2.1 中 30 名中层管理人员年薪的样本方差和样本标准差.
解 (1)在某一空白单元格(如C1)中输入“=VAR(A1:A30)”,得到样本方差 s 2 = 2.067.
(2)在某一空白单元格(如C2)中输入“= STDEV(A1:A30)”,得到样本标准差 s = 1.44.
用集中趋势和变异性可描述样本数据集的一般特性.除此之外,我们常常关心某个特定测量值在数据集中的相对位置.对某个测量值相对位置的一种测度是它的 样本百分位数 .粗略地说,对于 0≤ m ≤100,一个数据集的样本 m % (下侧)分位数是指这样一个数值,该数据集里小于它的数据个数约占 m % ,中位数就是 50%分位数.例如,称 2019 年A公司的年销售量在同类行业中的样本百分位数为 80%,表明同类行业中公司的年销售量比A公司低的约占 80%.
样本百分位数的确切定义有多种,结果略有差异.下面给出Excel软件中所采用的定义.
定义
1.4.7
将样本量为
n
的数据集由小到大排序,记为
 ,对于0≤
p
≤1,令
,对于0≤
p
≤1,令

该数据集的 样本 100 p %(下侧)分位数 定义为
(1)如果 t 是整数 i ,它定义为数据集 x ( i ).
(2)如果 t 不是整数, i < t < i + 1,它定义为两个相邻数据的加权平均值

可用Excel软件中的PERCENTILE函数计算样本百分位数.
定义 1.4.8 ( 四分位数 ) 样本 25%分位数称为第一个四分位数(下四分位数),样本50%分位数称为第二个四分位数(样本中位数或中间四分位数),样本 75%分位数称为第三个四分位数(上四分位数).
四分位数把样本数据集划分为四个部分,大约 25%的数据小于第一个四分位数,25%的数据在第一个四分位数和第二个四分位数之间,25%的数据在第二个四分位数和第三个四分位数之间.
例 1.4.5 计算并解释例 1.2.1 中 30 名中层管理人员年薪的四分位数.
解 (1)在某一空白单元格(如D1)中输入“= PERCENTILE (A1:A30,0.25)”,得到第一个四分位数 10.20.
(2)在某一空白单元格(如D2)中输入“= PERCENTILE(A1:A30,0.50)”,得到第二个四分位数 10.74.
(3)在某一空白单元格(如D3)中输入“= PERCENTILE(A1:A30,0.75)”,得到第三个四分位数 11.82.
得到数据集的四分位数以后,通过 箱线图 可直观展示数据集的分布信息.如图 1.4 给出了例 1.4.5 中有关年薪的数据集箱线图.先将一个矩形(箱子)拉开,它的上下两条边分别拉至下四分位数和上四分位数的位置,观测值的中间四分位数落在箱子内部,代表数据分布的中心位置.盒子的长度等于上四分位数减去下四分位数,被称为数据集的四分位距.这里数据集的四分位距为 1.62.

图 1.4
人们通常认为年龄和年薪是高度相关的,国民生产总值(GDP)和通货膨胀率也被认为是有关系的.为关注两个变量之间的关系(常称为 二元关系 ),选用 成对数据集 .表 1.1 中 30名中层管理人员的年龄和年薪可用成对数据集表示,见表 1.4.这里的每对数据都有一个 x 值和一个 y 值,第 i 对数据记为( x i , y i ).
表 1.4

描述成对数据关系的一个有效方法是画 散点图 .散点图是一个二维图形,其中,一个变量的取值沿横轴建立,另一个变量的取值沿纵轴建立,图形中每个点的坐标对应一对数据( x i , y i ).如图 1.5 所示的散点图描述了 30 名中层管理人员的年龄和年薪之间的关系,暗示了中层管理人员的年薪随着年龄的增大而增加的大体趋势.

图 1.5
一般来说,当一个变量随着另一个变量的增长呈递增趋势时,称这两个变量是“正相关的”,如图 1.5 所示.另外,当一个变量随着另一个变量的增长呈递减趋势时,称这两个变量是“负相关的”.为了定量描述这种关系,引入样本协方差和样本相关系数.
定义 1.4.9 成对数据集( x i , y i )( i = 1,…, n )的 样本协方差 定义为

样本相关系数定义为

其中 s x 和 s y 分别是 x 1 , x 2 ,…, x n 和 y 1 , y 2 ,…, y n 的样本标准差.
可使用Excel软件中的COVAR函数计算样本协方差,用CORREL函数计算样本相关系数.
例 1.4.6 计算表 1.4 中 30 名中层管理人员的年龄和年薪之间的样本协方差和样本相关系数.
解 (1)将 30 名中层管理人员的年龄值依次输入单元格A1:A30,年薪值依次输入单元格B1:B30.
(2)在某一空白单元格(如C1)中输入“= COVAR(A1:A30,B1:B30)*30 /29”,得到样本协方差 5.86(这里COVAR函数使用的系数是
 不是
不是
 ,需要加一个修正因子
,需要加一个修正因子
 ).
).
(3)在某一空白单元格(如C2)中输入“= CORREL(A1:A30,B1:B30)”,得到样本相关系数 0.82.
样本相关系数的取值范围在-1 和 1 之间,
 的大小度量两个变量之间线性关系的紧密程度,如图 1.6 所示.当
r
xy
=
1 时,表明两个变量之间存在正的线性关系的概率为 1,可用一个变量的线性函数近似表示另一个变量;当
r
xy
=
0.787 时,表明两个变量是正相关的,而且线性关系比较强;当
r
xy
= -
0.503 时,表明两个变量是负相关的,而且线性关系比较弱;当
r
xy
=
0 时,两个变量不相关,即不存在线性关系.
的大小度量两个变量之间线性关系的紧密程度,如图 1.6 所示.当
r
xy
=
1 时,表明两个变量之间存在正的线性关系的概率为 1,可用一个变量的线性函数近似表示另一个变量;当
r
xy
=
0.787 时,表明两个变量是正相关的,而且线性关系比较强;当
r
xy
= -
0.503 时,表明两个变量是负相关的,而且线性关系比较弱;当
r
xy
=
0 时,两个变量不相关,即不存在线性关系.

图 1.6
需要强调的是,相关系数只表明两个变量之间的线性关系.当相关系数趋近于 0 或等于0 时,只说明两个变量的线性关系很弱,但不排除两个变量之间存在很强的非线性关系,如 y= x 2 .另外,相关关系不是因果关系.例如,例 1.4.6 中年龄和年薪之间的相关系数是 0.82,只表明两个变量之间存在比较强的正线性相关性,但不能因此断定管理人员的年龄增加直接导致年薪的增加,这一情况的发生有可能是第三方因素引起的,有待进一步分析.