
下载掌阅APP,畅读海量书库
立即打开




联邦学习是为数据安全与隐私保护设计的联合机器学习方案,为实现数据可用不可见,联邦学习系统需要在性能、效率与隐私安全之间进行权衡。包括由于数据异质性带来的模型性能下降、加密技术中增加的通信负载。同时联邦学习参与者的行为是不可知的,系统设计应有足够的鲁棒性以应对可能的机器离线、恶意参与者等问题。如图1-1所示,我们将联邦学习系统性的挑战总结为三个: 性能挑战、效率挑战、隐私与安全挑战 。
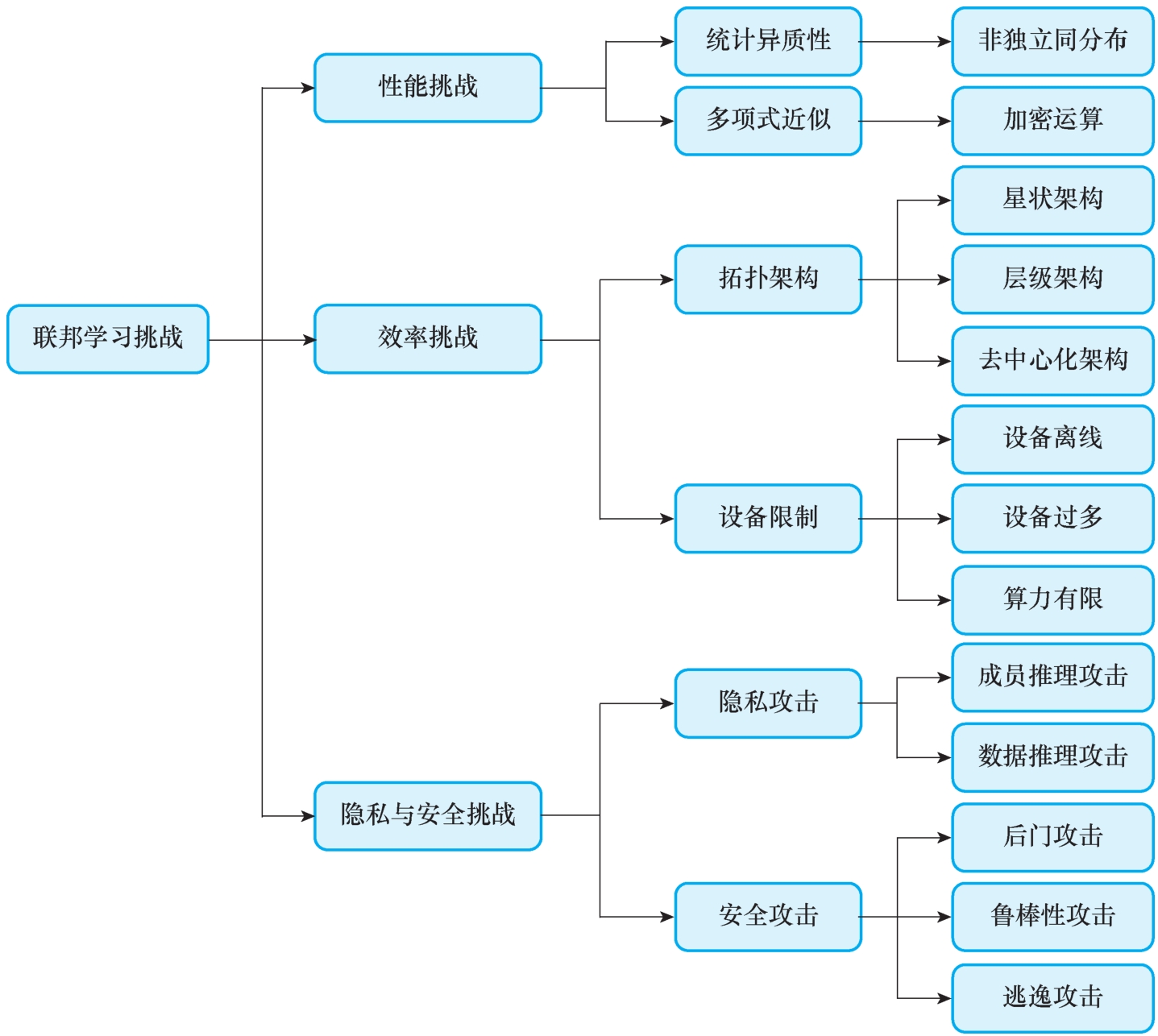
● 图1-1 联邦学习挑战
通常,联邦学习通过聚合客户端模型得到的最终全局模型的性能相比于通过传统的集中数据的训练方式得到的模型性能会有不同程度的下降,也被称为 性能降级 (Performance Degradation)。性能降级的原因是多方面的,一方面是数据原因。在联邦学习的框架下,联邦学习算法的设计者会缺乏对联邦数据的洞见。当前的研究仅能证明分布式数据在满足独立同分布的条件时,联邦学习的理论性能会逼近集中训练模型。而当跨设备数据不能满足独立同分布的条件时,联邦学习基线算法FedAvg学习得到的全局模型上下界便会缺乏理论保证,甚至在某些极端情况下,模型将不能收敛。造成数据非独立同分布的原因可能是多方面的,以医疗联邦学习为例,不同的医疗机构加入同一个联邦学习协议,但是其拥有的训练样本的体量是不一样的,大型医院生产收集的数据远多余普通小型医院的医疗数据。由于区域差异、门诊设置的区别、不同医院不同类型疾病的样本数量差异明显。即使对应于同一种疾病,不同的数据采集设备、不同的医务人员、不同的医院其要求也各不相同,难以保证图像标注采用的是相同的标准。此外,由于缺乏对全体数据的了解,有些特殊样本可能不能被正确分析,所以数据预处理由于不能及时过滤这些样本而导致样本比设想的要脏。另一个可能导致模型下降的原因是在算法层面。在某些场景下,联邦学习需要通过密码学机制,比如同态加密,来交换不同客户端之间的参数。在此过程中需要进行 多项式逼近 来评估机器学习算法中的非线性函数。大规模部署的联邦学习系统中,如果某个参与方的本地模型参数变化不太大,没有必要频繁地把模型更新上传到中央服务器上。同样,也没有必要在每一步都对本地模型进行校准。因此联邦学习需要在模型性能与系统效率间寻找一个平衡点。
联邦学习的训练时间一般长于传统的数据集中式的机器学习。一方面由于数据统计异质性带来更长的模型收敛时间;另一方面由于客户端与服务器之间频繁通信,深度学习模型所需要传递的参数数量远高于一般的机器学习模型,随着联邦学习参与客户端数量的增加,联邦学习的内部通信负载也会随之线性增加。因此对于大型联邦学习系统而言,通信所占用的时间高于本地模型参数更新所用的时间。为此,联邦学习系统通常需要降低本地模型与服务器交换参数的频率,并通过压缩模型或者梯度来减少通信环节的通信量,对于某些大规模系统,需要限制每一轮参与模型聚合的客户端数量来减少服务器的等待时间。
1.联邦学习拓扑架构
由于地理位置、数据之间的统计性的差异,客户端之间的可信任程度也不尽相同,人们在设计联邦学习系统的时候也会考虑不同的架构,来保证隐私与效率之间的平衡。联邦学习的拓扑架构包括 星状架构、层级架构 与 去中心化架构。
(1)星状架构
星状架构中所有的客户端与服务器直接相连,便于网络控制与管理。故障诊断与隔离非常容易,单方的故障调试不会对全局有影响。但是服务器的负载要求很大,一旦服务器节点瘫痪,会使得整个网络服务崩溃且不容易扩大网络规模。
(2)层级架构
层级架构通过层级聚合来优化,聚合原则可以基于地理位置,也可以是用户特征。层级聚合缓解了中央服务器的负载压力,同时有助于实现模型的本地化与特征化。层级聚合需要设计额外的聚合策略。对聚合的标准以及不同层级间的模型同步策略需要调优。
(3)去中心化架构
去中心化架构可在网络的中央及边缘区域共享内容和资源。拓扑结构的资源较为分散,对所有参与方的资源进行备份与恢复是较为复杂的。从机器学习的角度来看,去中心化架构优化算法非常复杂,一般是基于谣言协议(Gossip Protocol)实现谣言学习(Gossip Learning)。
2.设备限制
影响联邦学习系统效率的另一个原因就是设备限制,包括存储、CPU与GPU计算能力、网络传输带宽等多个方面的差异,这些使得设备的计算时间不同,甚至会出现客户端设备掉队/退出的问题。此外在跨设备联邦学习中,终端设备过多,同样会导致通信负载加剧,带宽紧张。在一些典型的联邦学习框架下,系统会将一些网络带宽受限或访问受限的客户端排除在训练的轮次之外,即不将全局模型发送给这些客户端进行本地优化。这种简单的处理方式会大大影响这些客户端所提供的服务,进而影响用户的使用体验。
任意的数据共享往往会泄露用户隐私等敏感信息,导致不可预测的未来风险,并损害用户对服务提供商甚至是相关权威机构的信任。作为一种高效的隐私保护手段,联邦学习可以实现在不直接获取原始数据的基础上,通过参数传递训练出一个共享模型。联邦学习隔绝了对用户隐私数据的直接访问与操作,但是在共享的模型参数或者梯度蕴含大量隐私信息并没有严格的理论性证明,一系列研究表明,联邦学习仍然面临诸多隐私与安全的挑战。
传统的机器学习包括分布式机器学习中自主的系统参与者是唯一的,该参与者负责数据的收集、整理、清洗、训练与部署,对整个机器学习的生命周期负责。但是联邦学习与传统机器学习不同,联邦学习有众多的参与者,每个参与者独立地负责数据预处理和执行联邦学习协议。联邦学习协议无法做到对所有参与者的用户行为、用户数据的有效监督。
1.隐私攻击
从攻击的目标可以将隐私性攻击分为 成员推理攻击 (Membership Inference Attacks, MIA)和 数据推理攻击 (Data Inference Attacks, DIA)。
● 成员推理攻击又称追溯攻击(Tracing Attacks),旨在判断某条数据或者某个用户是否包含在训练集中。一般来说,假设攻击者拥有部分训练数据或者与训练任务相关的数据,但是在现实中,攻击者很难获得训练数据。
● 数据推理攻击旨在直接获取用户隐私信息,如重构出用户的训练数据及标签。或者推断出训练的某些属性,这些属性与训练任务无关,但是可能在无意中泄露。
2.安全性攻击
隐私攻击的攻击者可能从服务器端发起攻击,也可能从客户端发起攻击。攻击者能从服务器处获得每一个独立的客户端的模型,他们将试图挖掘上传的本地模型中更多的私密信息。客户端由于能接触到全局模型,并且全局模型中可能包含其他用户的私密信息,因此用户有可能利用全局模型推断出自己可能不曾拥有的类别的训练数据信息。在联邦学习中,客户端攻击其他客户端的私密信息并且攻击者甚至有可能违背联邦学习协议来放大攻击的效果。
从攻击的目标上可以将隐私性攻击分为 后门攻击 (Backdoor Attacks)、 鲁棒性攻击 (Robustness Attacks)、 逃逸攻击 (Evasion Attacks)。其中,后门攻击和逃逸攻击是机器学习安全领域最常见的两种攻击方式。这里讨论的鲁棒性攻击是针对联邦学习协议,它是一种联邦学习独有的攻击形式。
● 后门攻击又称为有目标攻击(Targeted Attacks),在模型的训练过程中通过某种方式在模型中埋藏后门(Backdoor),在推理过程中,攻击者通过预先设定的触发器(Trigger)激发埋藏好的后门。在后门未被激发时,被攻击的模型表现与正常模型无异;而当模型中埋藏的后门被攻击者激活时,被攻击的模型会按照攻击者意图输出结果。
● 鲁棒性攻击又称为无目标攻击(Untargeted Attacks),区别于常规机器学习中讨论的模型鲁棒性,对于样本中的噪声鲁棒,联邦学习是指联邦学习对系统中非恶意或者恶意的行为鲁棒,如预处理过程中的漏洞、未清洗的训练数据,或者违背联邦学习协议的模型更新,试图破坏整个联邦学习过程。常见的鲁棒性攻击方式包括女巫攻击(Sybil Attacks)和拜占庭攻击(Byzantine Attacks)。
● 逃逸攻击在不修改模型的前提下,试图生成对抗性样本(Adversarial Samples)使得样本绕过模型的检测,得出跟真实结果(人眼判定结果)不一样的结论。
图1-2展示了联邦学习不同挑战之间的相互关系。为了增强联邦学习的安全与隐私性,在一些严格要求隐私保证的系统中,联邦学习需要与其他隐私保护技术相结合,当使用差分隐私、多项式逼近等技术进行隐私保护的时候,模型就会为了安全和隐私牺牲部分性能。同样,当使用其他密码学技术,如与秘密共享、混淆电路等相结合时,加密计算对应负载又会使得联邦学习的效率降低。同样,异步更新、通信频率等超参数调优也是联邦学习为了平衡性能与效率,在工程化时需要考虑的因素。
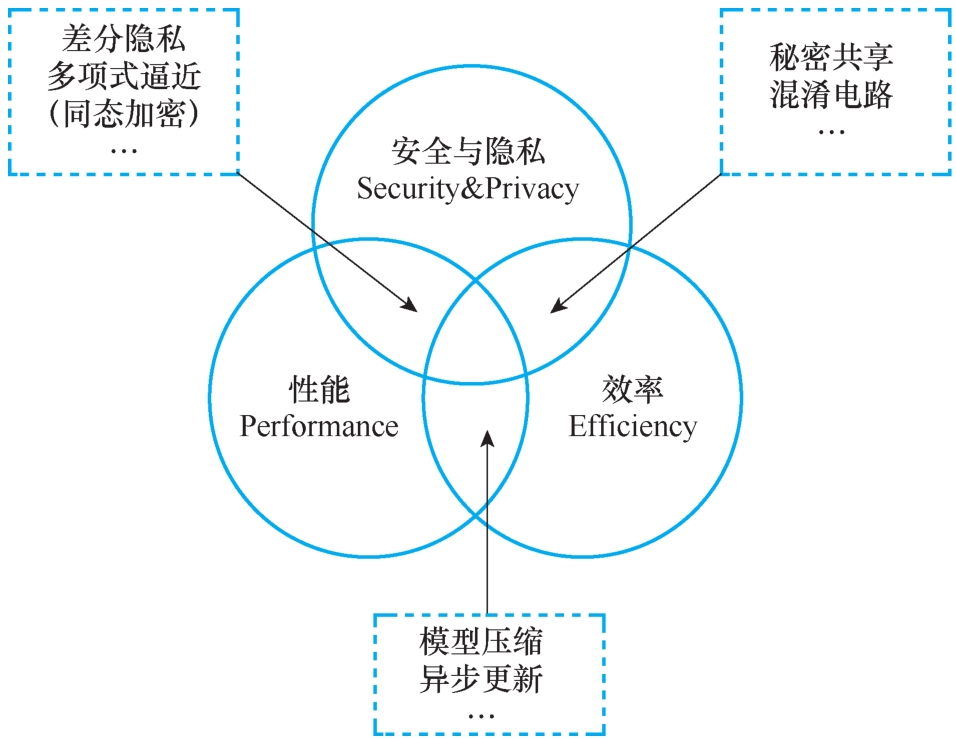
● 图1-2 联邦学习挑战之间的互相关系