
下载掌阅APP,畅读海量书库
立即打开



潜藏于人类语言之下的语法到底是如何组合文字的?迈克尔·弗莱恩(Michael Frayn)在他的小说《罐头人》( The Tin Men )中提供了一种最简单的解释:按序排列。小说的主人公是某个自动化研究所的工程师,他必须设计出一个能够生成各种类似新闻故事的计算机系统,例如像“瘫痪女孩决心重返舞台”这样的励志报道。以下是他手工测试程序的情景,这个程序专门用来构造各种以皇室仪式为背景的故事:
他打开档案柜,从中挑出第一张卡片。上面显示“Traditionally”(传统地)一词。接下来就是在“coronations”(加冕)、“engagements”(约会)、“funerals”(葬礼)、“weddings”(婚礼)、“comings of age”(成年)、“births”(出生)、“deaths”(死亡)、“churching of women”(安产感谢礼)等卡片中随机抽取一张。昨天他选择的是“funerals”,随之被准确地引导到一张内容为“occasions for mourning”(哀悼的场合)的卡片上,今天他闭上眼睛,抽到了“weddings”,并被引导到一张内容为“occasions for rejoicing”(欢庆的场合)的卡片上。
接下来的逻辑选择是“The wedding of X and Y”(X与Y的婚礼),然后他面临两个选择:一个是“is no exception”(没有特别之处),一个是“is a case in point”(是一次特别的婚礼),而无论选择哪一个,后面都可以接“indeed”(事实上)。的确,无论以哪一种场合开头,比如加冕、死亡或者出生,戈德瓦塞尔(Goldwasser)都能以计算的方式轻松应对,但现在他也遇到了同样的瓶颈。他在“indeed”上停顿了下来,然后紧接着抽出了一张卡片,内容是,“it is a particularly happy occasion, rarely, and can there have been a more popular young couple”(这是一次特别欢乐的场面,真是难得一见,没有比他们更受大家喜爱的一对新人了)。
在接下来的选择中,戈德瓦塞尔抽到的是“X has won himself/herself a special place in the nation’s affections”(X已赢得了全国人民的心),这使得他(或她)再接再厉,而“英国人民也已经从心里接纳了Y”。
戈德瓦塞尔惊讶地发现,“fitting”(合适)一词还没有出现,这让他感到有些不安。但紧接着他就抽到了这张卡片:“it is especially fitting that”(特别合适的是)。
这个结果将他引导到“the bride/bridegroom should be”(新娘或新郎应该)这张卡片上。接下来他有大量的卡片可选:“of such a noble and illustrious line”(出自如此的名门望族)、“a commoner in these democratic times”(生于民主时代的平民家庭)、“from a nation with which this country has long enjoyed a particularly close and cordial relationship”(来自与本国长期保持着深厚友谊的国家)、“from a nation with which this country’s relations have not in the past been always happy”(来自一个与本国存在历史摩擦的国家)。
戈德瓦塞尔觉得,在上一次编造故事时,“fitting”一词的表现相当不错,因此他特意再次挑选了它,卡片的内容是“It is also fitting that”(也很合适的是)。紧接着出现的是“we should remember”(我们应该记住的是)和“X and Y are not merely symbols—they are a lively young man and a very lovely young woman”(X和Y不仅仅是两个符号——他们还是一对充满朝气、活泼可爱的年轻人)。
戈德瓦塞尔闭上眼睛,抽了下一张卡片,内容是“in these days when”(在……的日子里)。他沉思了一下,考虑是应该选“it is fashionable to scoff at the traditional morality of marriage and family life”(对传统的婚姻和家庭观念的嘲弄蔚然成风),还是选“it is no longer fashionable to scoff at the traditional morality of marriage and family life”(对传统的婚姻和家庭观念的嘲弄已经不再时髦)。戈德瓦塞尔决定选择后者,因为它的结构更加华丽繁复。
这台设备的学名叫“有限状态机”(finite-state)或“马尔可夫模型”(Markov model),不过我们姑且把它称为“字串机”(word-chain device)。这台机器拥有一大批词语列表(或者预设短语),以及一套在各个列表之间进行对应、筛选的操作规则。它的处理器会先在某个列表中选择一个单词,然后在另一个列表中再选择一个单词,以此类推,最终制造出一个句子。如果要理解他人说出的句子,这台机器只能以列表为参照,依次核对句中的每个单词。像弗莱恩这样的讽刺作家经常拿字串系统开涮,把它视为一种可以自动生产赘语冗辞的工具,例如有一种所谓的“社会科学术语生成器”(Social Science Jargon Generator),读者只需依次从以下三栏中各选出一个词,便可组成像归纳性聚合式相互依赖“inductive aggregating interdependence”这样听起来冠冕堂皇的术语。


最近我见过一台字串机,它可以自动生成书封上的宣传广告,另外还有一台字串机能够替代鲍勃·迪伦(Bob Dylan)编写歌词。
字串机是最为简单的一种离散组合系统,它可以从一组有限的元素中创建出无限的特定组合。尽管它的表现略显拙劣,但一台字串机可以生成无限数量的符合语法的英文语句,例如,一些最为简单的句式:“A girl eats ice cream”(一个女孩吃着冰激凌)或“The happy dog eats candy”(这只欢快的狗吃着糖果)。
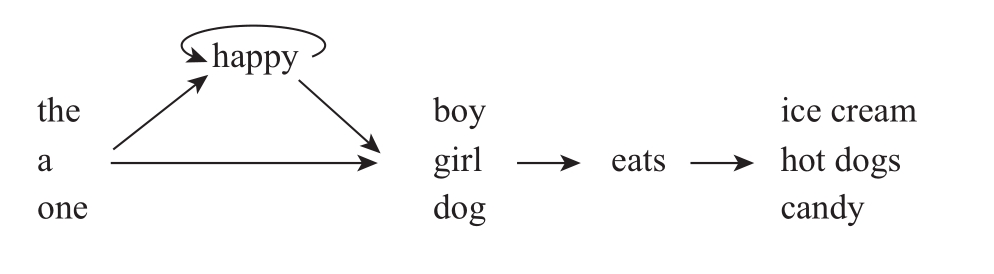
这种句式包含着无限个句子,因为“happy”上的循环箭头标志着字串机可以任意重复“happy”一词的次数,例如“The happy dog eats ice cream”“The happy happy dog eats ice cream”等,以至于无穷。
当工程师准备建立一套符合特定顺序的字词组合系统时,他首先想到的必然是字串机。电话查询台的语音录音就是一个很好的例子,它事先录下10个数字的读音,并且每个数字的读音又分作7个音调(位于电话号码首位的数字是一个音调,位于第二位的数字又是一个音调,以此类推)。有了这70个录音,它就可以播报出1 000万个电话号码,再加上3位数的区号所产生的30个录音,一共可以组合成上亿个电话号码(不过在实际生活中,由于各项规定的限制,许多号码并不会被用到,比如说0和1不能作为电话号码的第一位数)。事实上,已经有人付出了极大的努力,希望为英语构建出一套巨大的字串模型。为了使它尽可能地符合现实情况,设计者将各个单词之间的转移情况与它们在英语中的衔接概率进行了匹配,例如“that”一词后面紧跟“is”的概率要大于“indicates”。研究人员通过两种方法建立了一个庞大的“跃迁概率”(transition probability)数据库:一是借助计算机对大量英语文献进行分析;二是向参加试验的志愿者播报一个或一系列单词,然后询问他们第一时间联想到的是哪个单词。一些心理学家表示,人类语言其实就是一个储存在大脑中的巨型字串。这个看法与“刺激-反应”理论不谋而合:一个刺激引发一个反应,在这里,反应就是嘴里说出的某个单词,而当说话者察觉到自己的反应时,这个反应又转变为新的刺激,引发他做出下一个反应,即说出后面的单词。
但事实上,正如弗莱恩在小说中描写的那样,字串机的工作原理是那么的拙劣可笑,这不能不引起我们的怀疑。如果将我们的语言机制看成一台字串机,那就等于说我们的大脑是如此的盲目无知、缺乏创意,以至于一台简单的机器就可以制造出无穷无尽且足以以假乱真的例句。而弗莱恩的小说之所以显得异常幽默,正是因为我们的语言机制与字串机并非一回事。所有人都相信,人类(包括社会学家和记者在内)并不是真正意义上的字串机,二者之间只不过是有几分相似而已。
然而,乔姆斯基认为,字串机理论不仅仅是一个值得怀疑的看法,在人类语言机制的问题上,它其实犯了一个根本性的错误。由此,乔姆斯基拉开了现代语法研究的序幕。在他看来,虽然字串机也属于离散组合系统,但它与语言机制有着根本区别。以下是它存在的三个问题,而这三个问题也恰好反映了语言机制的三个特性。
首先,一个英文句子与一串根据跃迁概率连接起来的英文单词截然不同,例如乔姆斯基的句子“Colorless green ideas sleep furiously”。乔姆斯基杜撰这个句子的目的,不仅是为了表示毫无意义的句子也可以符合语法,他同时还想说明,那些概率极小的字序连接也可以符合语法。在英语文本中,单词“colorless”之后紧跟“green”的概率显然为零。“green”之后紧跟“ideas”的概率也为零,再如“ideas”之后紧跟“sleep”,“sleep”之后紧跟“furiously”等,莫不如此。尽管如此,这一串文字仍然算得上是一个语法精当的英语句子。相反,如果一个人真的只根据跃迁概率来串联字词,他得出的字串恐怕会毫无语法可言。例如,假设你采用的方法是根据前4个单词来推测下一个最可能出现的单词,由此逐字逐词地生成一个字串,其中每个单词的出现都取决于它前面的4个单词,其结果是:你将看到一堆莫名其妙的英语单词,而非一个英文句子。例如:“House to ask for is to earn our living by working towards a goal for his team in old New-York was a wonderful place wasn’t it even pleasant to talk about and laugh hard when he tells lies he should not tell me the reason why you are is evident.”
英文语句与英语字串的区别让我们明白了两个道理。第一,在学习语言的时候,人们学习的是如何将字词合理地排列,而不是机械地记住其前后顺序。人们是通过词性(如名词、动词等)的搭配原则来实现这一点的。换言之,我们之所以可以辨认出“colorless green ideas”这个短语,是因为它在形容词和名词的搭配上与“strapless black dresses”(无肩带的黑色裙子)这样的常见短语完全一致。第二,名词、动词和形容词的搭配并不是以首位相接的形式连成一串的,在句子的构建过程中,存在着一个整体蓝图或者框架,为每个单词设定了具体的安放位置。
如果字串机拥有足够的智慧,它或许可以解决这些问题。但乔姆斯基已经明确地驳斥了将人类语言视为字串的观点。他证明说,即使从理论上说,某些英语句型也无法由字串机来完成,无论这台字串机的功能有多强大,也无论它是否完全以概率表为准则。例如下面这两个句子:
Either the girl eats ice cream, or the girl eats candy.
这个女孩要么吃冰激凌,要么吃糖果。
If the girl eats ice cream, then the boy eats hot dogs.
如果这个女孩吃冰激凌,这个男孩就吃热狗。
乍看之下,这两个句子似乎很容易分解:
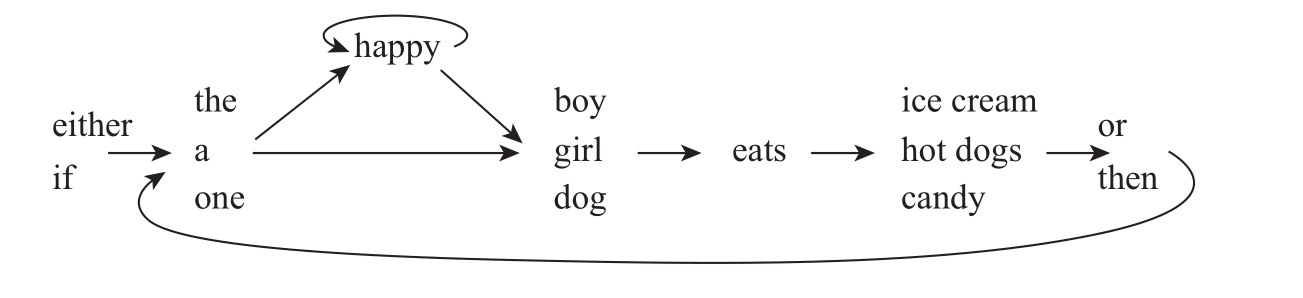
但字串机对此束手无策。在一个句子中,“Either”之后必须连接以“or”引起的分句,没有人会说“Either the girl eats ice cream, then the girl eats candy”。同样,“if”之后跟随的是“then”,没有人说“If the girl eats ice cream, or the girl likes candy”。但是,要满足句中早先出现的单词与稍后出现的单词之间的对应关系,字串机必须在逐字炮制句子的同时记住早先出现过的单词。而这就是问题所在:字串机是一个“健忘者”,它只能记住自己刚刚选取的单词列表,而无法记住之前的内容。当字串机运行到“or”或者“then”列表时,它根本记不清句子的开头到底是“if”还是“either”。当然,我们可以从制高点的位置居高临下地鸟瞰整个“路线图”,记住这台字串机在第一个岔口上所选择的道路;但对于在列表之间匍匐前进的字串机而言,要记住自己之前走过的道路却是不可能的事情。
或许你认为这只是一个很简单的问题,我们只需对字串机进行重新设计,让它可以记住自己先前选择的内容,例如,这台字串机能够将单词“either”和“or”以及它们中间可能出现的字序组合成一个大序列,再将“then”和“if”以及它们中间的字序组合成另一个大序列,然后再进行第三个序列的生成。例如:
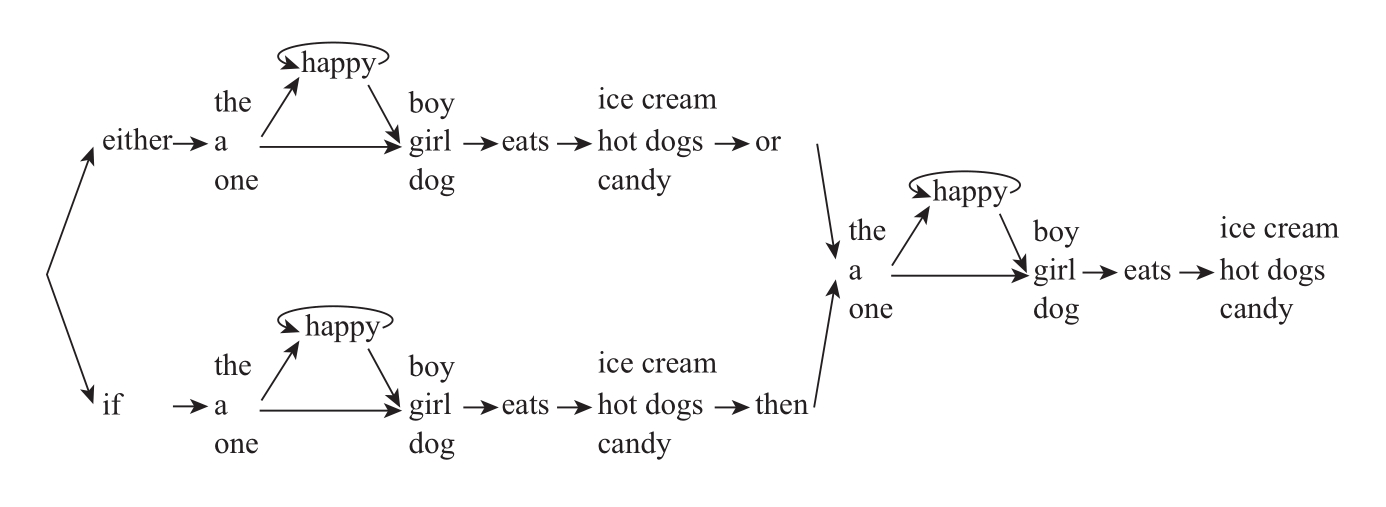
然而,这一解决方案存在非常明显的问题:它产生出三个相同的“子网”(subnetwork)。显然在现实语境中,无论人们在“either”和“or”之间插入什么内容,它们都同样可以插入“if”和“then”之间,也可以插入“or”或“then”之后。但是,人类的这种能力乃是出自大脑语言机制的自然设计,而并非依赖于某位设计者精心编写的三组相同的指令集(或者貌似更加合理的是,儿童在学习该句的句式时必须分三次进行,先是“if”和“then”之间的序列,然后是“either”和“or”之间的序列,最后是“then”和“or”之后的序列)。
不过,乔姆斯基对这个问题看得更深。他表示,以上两个句子都可以嵌入其他任何句子之中,甚至包括它们自己在内:
If either the girl eats ice cream or the girl eats candy, then the boy eats hot dogs.
如果这个女孩要么吃冰激凌要么吃糖果的话,那么这个男孩就吃热狗。
Either if the girl eats ice cream then the boy eats ice cream, or if the girl eats ice cream then the boy eats candy.
如果这个女孩吃冰激凌,那么这个男孩要么吃冰激凌,要么吃糖果。
就第一个句子而言,字串机必须分别记住“if”和“either”,然后才能在稍后的过程中依次选择“or”和“then”。就第二个句子而言,它必须分别记住“either”和“if”,然后才能选择“then”和“or”来完成句子。从理论上说,位于句子开头部分的“if”和“either”的数量可以无限多,而每个“if”或“either”都需要一个“then”或“or”来完成句子。因此,分别列出每一个可供记忆的字串序列其实并没有多大意义,你必须为此记住无限个字串,而这显然超出了我们大脑的容量。
这种学术性的论证可能会让你颇感诧异。在现实生活中,没人会说出以“Either either if either if if”开头的句子,因此谁又会在乎这台语言机制的模拟装置是否能用“then…then…or…then…or…or”来完成句子呢?不过,乔姆斯基只是借用了数学家的研究方法,他将“either-or”与“if-then”的交替现象视为一种最简单的语言特性,即前后单词的“长距离依存关系”(long-distance dependencies),以便从数学上证明字串机无法处理这些依存关系。
事实上,这种依存关系在语言中比比皆是。人们时时刻刻都在用它,不但距离超长,而且经常一次数个,但字串机却做不到这一点。例如,语法学家常常用这个以5个介词结尾的句子为例:Daddy trudges upstairs to Junior’s bedroom to read him a bedtime story. Junior spots the book, scowls, and asks,“Daddy, what did you bring that book that I don’t want to be read to out of up for?”(父亲步履蹒跚地爬上楼,来到孩子的卧室,只为给孩子读一个睡前故事,孩子看见书,皱着眉头问道:“爸爸,你怎么把这本我不想听的书带上来了呢?”)这个孩子在说到“read”一词时,已经在脑海中形成了4个依存关系:“read”与“to”、“that book that”与“out of”、“bring”与“up”、“what”与“for”。不过,下面这个源于现实生活的例子或许更能说明问题,它出自某位读者写给《电视指南》( TV Guide )的一封信:
How Ann Salisbury can claim that Pam Dawber’s anger at not receiving her fair share of acclaim for Mork and Mindy’s success derives from a fragile ego escapes me.
安·索尔兹伯里说,帕姆·道伯之所以没有因《默克与明蒂》的成功获得应有赞誉而生气,是源于她脆弱的自我。我不明白她为什么这样说。
显然,这位写信者在写到“not”时,脑海中一定形成了4个需要完成的语法结构:(1)“not”之后需要接动词的“-ing”形式(“her anger at not receiving acclaim”);(2)“at”之后需要接名词或动名词(“her anger at not receiving acclaim ”);(3)单数主语“Pam Dawber’s anger”规定了它的动词(即其后第14个单词)也必须保持单数形式(Dawber’s anger… derives from);(4)以“How”开头的单数规定了它的动词(即其后第27个单词)也必须保持单数形式(How … escapes me)。同样,读者在理解这个句子时,也需要将这些依存关系牢记于心。从技术上讲,我们可以制造出一个能够处理这些句子的字串机,只要说话者需要记住的依存关系在数量上有具体的限度(比如说4个)。但是,这台机器的冗余度将大得不可思议,因为面对每一种依存组合,这台机器都必须对同一个字串进行重复复制,而这种依存组合的数量多达千计。即使耗尽我们的大脑,也无法记住这样的超级字串。