
下载掌阅APP,畅读海量书库
立即打开



许多机器学习模型属于参数化模型,模型的表达式受一组参数控制,即
对这类参数模型确定目标函数后,通过在训练集上做优化求出参数向量 θ 。最大似然方法是通过概率方法确定目标函数,通过优化求得模型参数的最常用技术。通过概率方法来表达这类模型时,得到的概率表达式中包含了待求的参数,因此其概率表达式可表示成 p ( x | θ )的形式。通过这种概率形式给出似然函数的一个定义。
定义2.3.1 似然函数 (likelihood function),若将表示样本数据的随机向量的概率密度函数 p ( x | θ )中的 x 固定(即 x 取一固定样本值),将 θ 作为自变量,考虑 θ 变化对 p ( x | θ )的影响,这时将 p ( x | θ )称为似然函数,用符号 L ( θ | x )= p ( x | θ )表示。
定义2.3.2
最大似然估计
(maximum likelihood estimator,MLE):对于一个样本向量
x
,令
θ
=
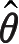 时使得似然函数
L
(
θ
|
x
)达到最大,则
时使得似然函数
L
(
θ
|
x
)达到最大,则
 是参数
θ
的最大似然估计(MLE),MLE可更形式化地写为
是参数
θ
的最大似然估计(MLE),MLE可更形式化地写为

这里 Ω 表示 θ 的取值空间。
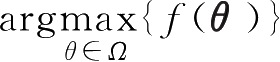 表示从
θ
的定义域中,求得
f
(
θ
)取最大值时对应的
θ
值
表示从
θ
的定义域中,求得
f
(
θ
)取最大值时对应的
θ
值
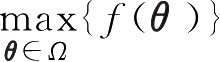 表示取得
f
(
θ
)的最大值。
表示取得
f
(
θ
)的最大值。
注意,在讨论最大似然估计时,为了概念清楚,可专设符号 L ( θ | x )= p ( x | θ )表示似然函数,在后续应用中,也可直接用 p ( x | θ )作为似然函数,不必再引入一个附加的符号。实际中更方便的是取似然函数的对数log L ( θ | x ),称其为 对数似然函数 。由于对数函数是(0,∞)区间的严格增函数,故log L ( θ | x )与 L ( θ | x )的最大值点一致,因此可以用对数似然函数进行求解,所得参数的解是一致的。许多概率函数属于指数类函数,对数似然函数的求解更容易。
最大似然估计是一个很直观的概念,当
θ
取值为
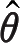 时已采样得到的样本
x
出现的概率最大。若
L
(
θ
|
x
)和log
L
(
θ
|
x
)是可导的,MLE可用如下方程求解
时已采样得到的样本
x
出现的概率最大。若
L
(
θ
|
x
)和log
L
(
θ
|
x
)是可导的,MLE可用如下方程求解

或

注意式(2.3.3)或式(2.3.4)的解只是MLE的可能解,式(2.3.3)或式(2.3.4)可能有多个解。当存在多个解时,其中任一个解可能对应极大值、极小值或拐点,若MLE解落在边界上,则可能不满足式(2.3.3)或式(2.3.4)。因此,对式(2.3.3)或式(2.3.4)的解要做进一步验证,比较这些解和边界点哪个使得似然函数取得最大值。
以上仅给出了一个样本点的情况,在机器学习中,更多的是给出一个样本集,若存在I.I.D样本集
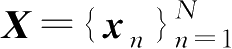 ,则样本集的似然函数可写为
,则样本集的似然函数可写为
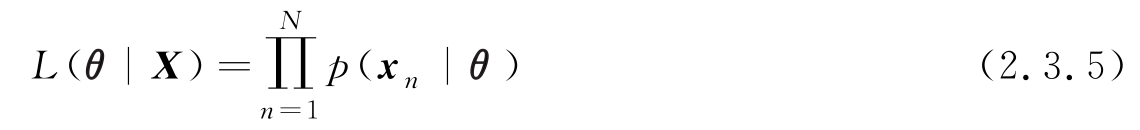
或对数似然函数为
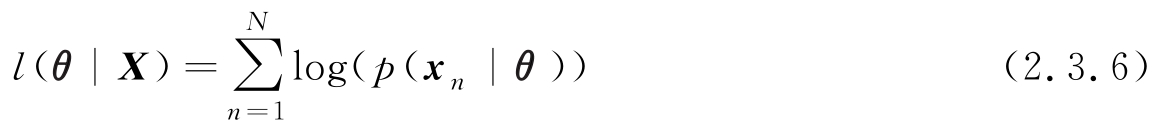
若使用对数似然函数,参数的解为
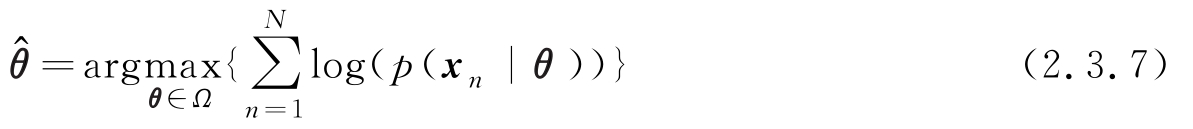
以下通过几个例子进一步介绍最大似然方法。首先考察对一个简单模型的参数估计,然后通过MLE对用参数化表示的概率函数的参数进行估计。
例2.3.1
考虑只有两个样本点的简单例子。样本集
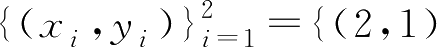 ,(3,0)}是I.I.D的,训练一个回归模型
,(3,0)}是I.I.D的,训练一个回归模型
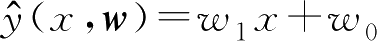 ,其中
w
=[
w
1
,
w
0
]
T
是模型参数。
,其中
w
=[
w
1
,
w
0
]
T
是模型参数。
设模型逼近标注值 y i ,但存在逼近误差 ε i ,即
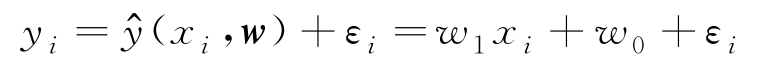
设
ε
i
满足高斯分布,即
ε
i
~
N
(0,
σ
2
),则
y
i
满足均值为
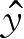 (
x
i
,
w
)的高斯分布,即
(
x
i
,
w
)的高斯分布,即
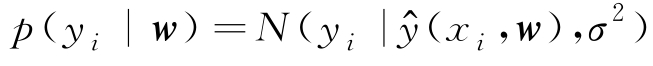
由于样本集是I.I.D的,故
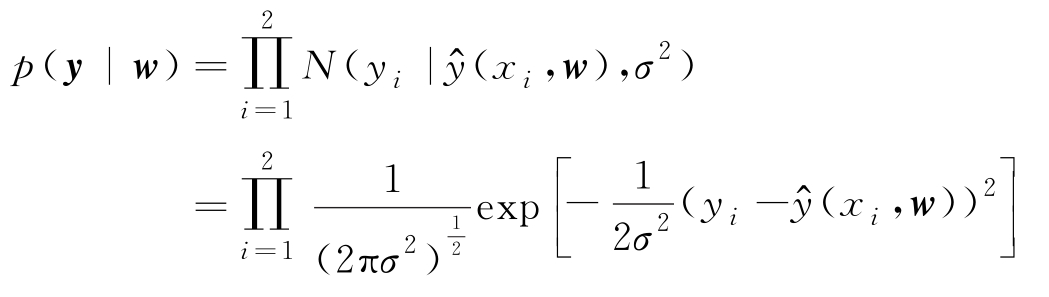
且样本值已知,故以上是似然函数,且可简化为
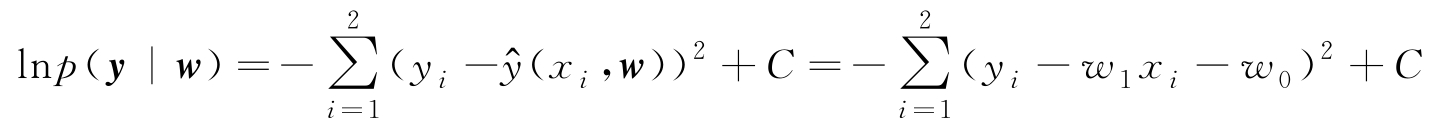
其中, C 是与求最大无关的常数。使以上似然函数最大,相当于求 w 使得
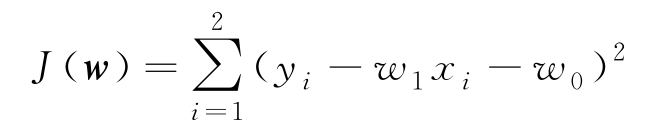
最小,即求
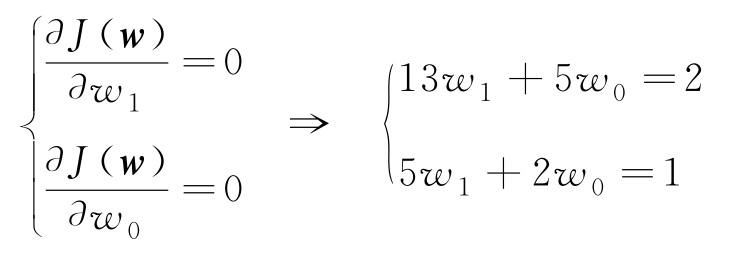
求得
w
1
=-1,
w
0
=3,所求的回归模型为
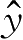 (
x
,
w
)=-
x
+3。这是一个很简单的例子,但是很多更复杂的机器学习模型的学习算法就是这个例子的扩展。
(
x
,
w
)=-
x
+3。这是一个很简单的例子,但是很多更复杂的机器学习模型的学习算法就是这个例子的扩展。
例2.3.2
设样本集
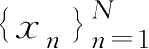 是I.I.D的,每个样本均服从
N
(
μ
,
σ
2
),且
σ
2
已知,但
μ
未知,由样本集估计概率密度函数的参数
μ
。
是I.I.D的,每个样本均服从
N
(
μ
,
σ
2
),且
σ
2
已知,但
μ
未知,由样本集估计概率密度函数的参数
μ
。
因为是标量样本,将所有样本排列在向量 x 内,则由I.I.D性, x 的联合概率密度函数为
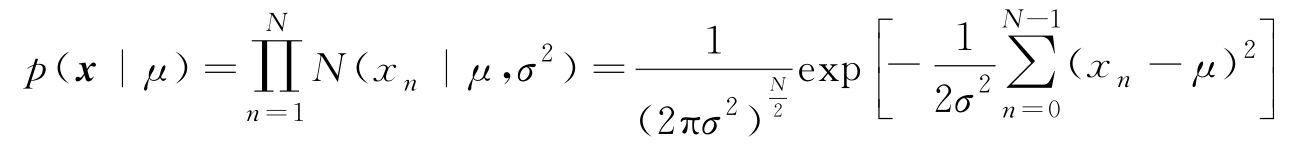
固定 x 并令似然函数 L ( μ | x )= p ( x | μ ),由式(2.3.4),有
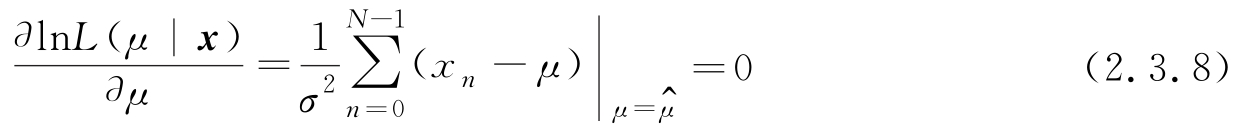
解得

可进一步验证
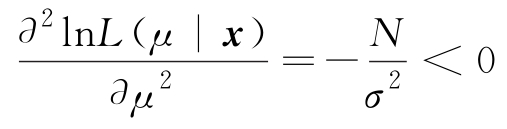
由于式(2.3.8)有唯一解,且其二阶导数为负,因此该解对应最大值点,故式(2.3.9)是MLE。本例中,式(2.3.9)的结果与例2.1.4用蒙特卡洛方法的结果一致。
对于例2.3.1和例2.3.2这样的情况,似然函数是 θ 的连续函数且只有唯一的峰值,参数取值范围为(-∞,∞),可省去后续的判断过程,由式(2.3.3)或式(2.3.4)求得的解就是MLE。
例2.3.3
将例2.3.2推广到一般情况,样本集
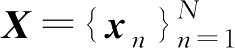 是I.I.D的,每个样本是向量
x
n
=[
x
n
1
,
x
n
2
,…,
x
nM
]
T
,其服从高斯分布,设向量
x
=[
x
1
,
x
2
,…,
x
M
]
T
的概率密度函数表示为
是I.I.D的,每个样本是向量
x
n
=[
x
n
1
,
x
n
2
,…,
x
nM
]
T
,其服从高斯分布,设向量
x
=[
x
1
,
x
2
,…,
x
M
]
T
的概率密度函数表示为
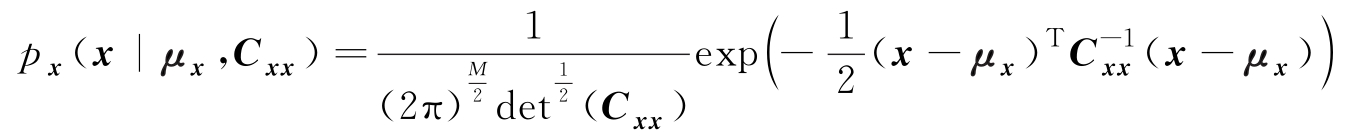
这里 μ x 是均值向量, C xx 是协方差矩阵,用样本集估计 μ x 、 C xx 。
对该问题定义似然函数为
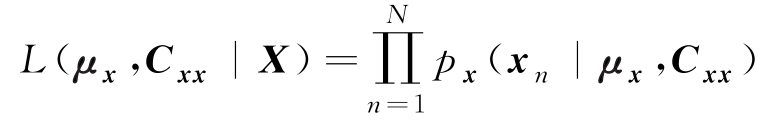
稍加整理,对数似然函数为
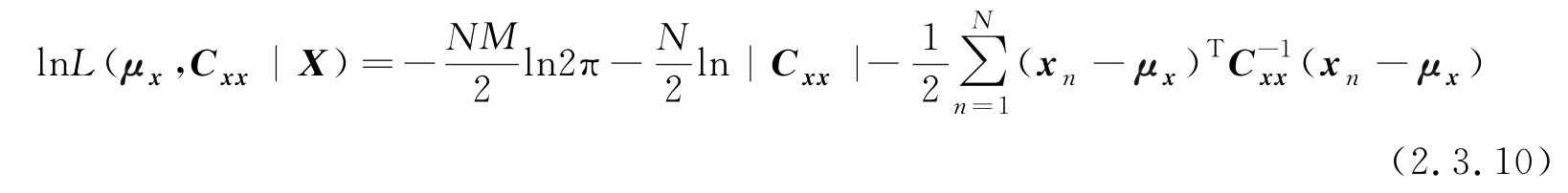
对 μ x 、 C xx 求极大值,附录B给出了标量函数对向量或矩阵求导的介绍,利用附录B的公式,经过代数运算得到

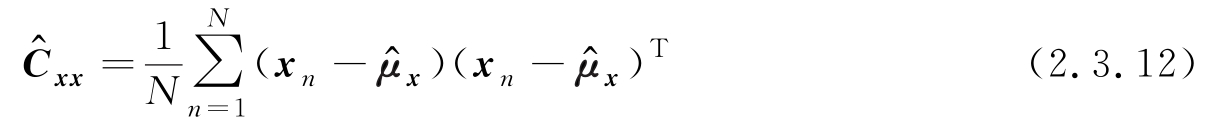
式(2.3.11)和式(2.3.12)是在得到 N 个独立同分布向量样本时,均值向量和自协方差矩阵的MLE。
这几个例子很简单,但说明了MLE应用的广泛性,例2.3.1可扩展到监督学习参数化模型的一般情况,例2.3.2和例2.3.3估计样本的概率函数参数,相当于无监督学习的例子。实际上将看到,最大似然函数是机器学习中应用最多的一种目标函数。
关于MLE的性能评价和变换不变性问题,不加证明地给出如下两个定理。
定理2.3.1 ( MLE渐近特性 ) 如果PDF p ( x | θ )满足规则性条件,未知参数 θ 的MLE渐近于如下分布

这里 I ( θ )是Fisher信息矩阵,且在 θ 的真值处取值。
其中,规则性条件是
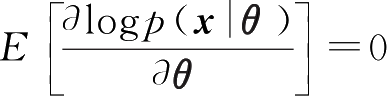 ,这是一个很宽松的条件,当
p
(
x
|
θ
)满足积分与求导可交换时,该条件成立。
I
(
θ
)为Fisher信息矩阵,其各元素定义为
,这是一个很宽松的条件,当
p
(
x
|
θ
)满足积分与求导可交换时,该条件成立。
I
(
θ
)为Fisher信息矩阵,其各元素定义为
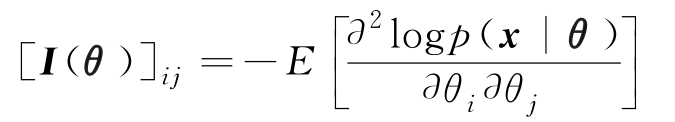
统计学中的克拉美-罗(Cramer-Rao)下界指出,最优无偏估计参数的协方差矩阵可达Fisher信息矩阵的逆。故定理2.3.1说明,在 N 充分大时,MLE逼近于一个无偏的、可达最小方差(协方差矩阵的对角线值)的估计器。换句话说,MLE是渐近最优的。尽管MLE有这样的良好性质,如上的几个例子也得到“漂亮”的解析表达式,但对于一般的问题,式(2.3.3)或式(2.3.4)所构成的方程式可能是高度非线性方程,MLE一般得不到解析表达式,这时可以通过数值迭代方法进行计算。一种有效的求解MLE的EM算法(expectation-maximization algorithm)得到广泛应用,EM算法在一些模型情况下得到非常有效的解,本书将在第11章对EM算法进行介绍并将其应用于混合高斯模型的参数求解。
定理2.3.2
(
MLE不变性
)
若
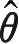 是
θ
的MLE,则对于
θ
的任何函数
g
(
θ
),
g
(
是
θ
的MLE,则对于
θ
的任何函数
g
(
θ
),
g
(
 )是
g
(
θ
)的MLE。
)是
g
(
θ
)的MLE。
MLE不变性有其意义,在一些应用中需要估计参数 θ 的函数 g ( θ ),但若参数的MLE更易于获得,则通过参数的MLE代入函数所获得的函数估计仍是MLE。
尽管MLE有其优良的表现,实际上也是目前机器学习中使用最多的目标函数之一,但MLE也有比较明显的弱点。MLE建立在概率的频率思想上,若对离散事件的概率进行估计,当样本集较小,且一些事件在样本集中没有发生时,其概率被估计为0。例如掷骰子,若只收集了少量样本,比如20个样本,面“3”在样本集中恰好没有出现,则面“3”的概率估计为0,这显然不符合常识。解决这个问题的一个方法是拉普拉斯平滑,将在第4章介绍。另外,最大似然敏感于样本集中的“野值”,这里所谓“野值”是指与样本集的统计性质相差很大的样本,可能是采样中突发噪声或其他意外因素所致,少量的野值很可能对MLE的性能产生较大影响,可通过对样本集的预处理删除野值。更重要的一点,MLE偏重更复杂的模型,易造成模型的过拟合,关于这一点,可通过正则化或贝叶斯方法给予解决。
最大似然估计中参数
θ
假设为确定量,实际上若参数
θ
是随机变量MLE方法仍然有效,如果参数
θ
是随机变量,符号
p
(
x
|
θ
)表示条件概率密度函数。对于MLE,样本
x
确定,作为随机变量一次实现的参数
θ
的求解与确定性情况一致,求似然函数
L
(
θ
|
x
)=
p
(
x
|
θ
)的最大值点确定参数的估计值
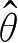 。从MLE的角度看,把参数
θ
看作确定性量还是随机变量的一次实现是无关紧要的。在2.4节讨论的贝叶斯(Bayesian)估计中,把参数
θ
作为随机变量,并且在获得样本值之前即知道
θ
的概率密度函数,因此在获取样本之前,对
θ
的可能取值范围和趋势预先就有一定的知识,故将
θ
的概率分布称为先验分布,在得到一组样本值之后,由样本值和先验分布一起对
θ
的值(随机变量的一次实现)进行推断。若先验分布是正确的,贝叶斯估计将利用
θ
的概率密度函数带来的附加信息改善估计质量,尤其在样本数量较少时更为明显。
。从MLE的角度看,把参数
θ
看作确定性量还是随机变量的一次实现是无关紧要的。在2.4节讨论的贝叶斯(Bayesian)估计中,把参数
θ
作为随机变量,并且在获得样本值之前即知道
θ
的概率密度函数,因此在获取样本之前,对
θ
的可能取值范围和趋势预先就有一定的知识,故将
θ
的概率分布称为先验分布,在得到一组样本值之后,由样本值和先验分布一起对
θ
的值(随机变量的一次实现)进行推断。若先验分布是正确的,贝叶斯估计将利用
θ
的概率密度函数带来的附加信息改善估计质量,尤其在样本数量较少时更为明显。
本节注释 本书对于一般的对数运算,例如对数似然函数采用对数的通用符号log表示,在实际计算中遇到概率函数是e的指数函数时,自动取自然对数ln。本书在大多数情况下,对使用log和ln不加区分。