
下载掌阅APP,畅读海量书库
立即打开




陈义飞 3,4 ,于春磊 1 ,郑世良 3 ,梁爽 2 ,陆彦辉 4,5 ,赵亚丽 2 ,江昆 1
1.清华大学 车辆与运载学院
2.清华大学 电子工程系
3.北京超星未来科技有限公司
4.郑州大学 信息工程学院
5.深圳市大数据研究院
【摘要】 基于激光雷达点云的目标检测是自动驾驶汽车环境感知的重要手段。本文针对自动驾驶系统对激光点云数据目标检测实时性和高能效的要求,利用FPGA平台并行处理与低能耗的优势,提出了基于FPGA软硬件协同优化的点云目标检测方案。针对三维点云数据处理的时延瓶颈问题,提出了定制化IP(Intelligent Property)的解决方案进行加速;针对嵌入式平台难以高效运行三维点云目标检测算法的难题,提出了适配FPGA运算的MobileNet-YOLOv3算法,并实现了相应的硬件加速系统以进行验证。本文基于KITTI数据集验证了方案的有效性,测试结果表明基于ZCU102平台的系统可以将点云预处理加速7倍,总体感知方案保持在低功耗和高准确率的前提下处理帧率为25FPS。本研究提出的点云感知方案可以满足自动驾驶实时性要求且能效比较高,为点云深度学习算法在自动驾驶领域的技术落地提供了技术支撑。
【关键词】 汽车工程,点云目标检测,软硬件协同优化,自动驾驶,深度学习
Real-time Point Cloud Object Detection for Autonomous Vehicles Based on Hardware-Software Co-Optimization with FPGA
Chen Yifei 3,4 , Yu Chunlei 1 , Zheng Shiliang 3 , Liang Shuang 2 , Lu Yanhui 4,5 , Zhao Yali 2 , Jiang Kun 1
1. Tsinghua University , the School of Vehicle and Mobility
2. Tsinghua University , Department of Electronic Engineering
3. Beijing Novauto Technology Co ., Ltd.
4. Zhengzhou University , School of Information Engineering
5. Shenzhen Research Institute of Big Data
Abstract: Object detection based on lidar point-clouds is essential in the field of autonomous driving environment perception.This article proposes a point-cloud object detection method of hardware-software co-optimization which leverages the advantages of the FPGA platform's capability of parallel processing at a low power consumption.It meets the requirements for real-time processing of point-cloud data and the operating power consumption of real-time autonomous driving systems.A customized IP(Intelligent Property)solution is proposed to accelerate the point-cloud processing stage to mitigate higher latency.To solve the current low efficiency problem when running a 3D point-cloud object detection algorithm on the embedded FPGA platform,we propose a new MobileNet-YOLOv3 algorithm for this platform,and a hardware acceleration system for evaluation.Furthermore,we demonstrate the effectiveness of the solution on the KITTI data set.The results show that the system implemented on ZCU102 achieves 7x acceleration for the pre-process of the point cloud and 25 FPS throughput in the overall perception solution,while keeping a high accuracy with low power consumption.Therefore,the proposed method satisfies the real-time requirement of autonomous driving while maintaining low power consumption and high accuracy leading to an easier deployment of point-cloud deep learning algorithms in the field of autonomous driving.
Key words: vehicle engineering,point cloud object detection,Software and hardware co-optimization,autonomous driving,deep learning
自动驾驶汽车有望成为减少交通事故和缓解交通拥堵的重要手段 [1] 。自动驾驶技术的迅速发展也极大地推动了各类传感器的研究,例如摄像头、激光雷达和惯性导航等。激光雷达是自动驾驶系统中的重要传感器,在自动驾驶的环境感知及定位系统中应用广泛 [2] 。近年来,深度学习在人工智能领域取得了令人瞩目的成果,但面向自动驾驶产品落地的深度学习技术不仅要求算法具有足够的准确性、鲁棒性与泛化能力,还要求在嵌入式车载硬件平台上的模型部署能满足功能需求、功耗低且成本可控。由此可见,深度学习在自动驾驶领域的应用受到软件算法和硬件资源的双重限制。本研究围绕点云目标检测的深度学习算法及其在面向车载嵌入式硬件平台上的软硬件协同优化展开。
激光雷达三维点云目标检测是自动驾驶环境感知的重要环节,其任务是确定三维空间中的感兴趣目标的类别、位置和朝向 [3-4] ,然后提供给下游模块。现有点云目标检测算法可以分为传统目标检测算法和基于深度学习的目标检测算法。传统目标检测算法通过人工提取特征并利用机器学习算法实现目标检测,该方法耗费人力和时间。而基于深度学习的目标检测算法通过深度神经网络自动学习样本特征并进行目标检测,随着硬件加速设备和大数据技术的发展,3D点云目标检测技术成为自动驾驶领域的研究热点。
3D点云数据是由不同线束激光雷达扫描场景并返回的激光点,具有天然的稀疏性、无序性和不均匀性,根据点云处理方式的差异,现有基于点云的3D目标检测算法可以分为三大类:点云体素化、点云平面化和点云直接法 [5] 。点云体素化需要将点云转化为体素网格并进行特征编码,然后再连接目标检测算法生成检测结果。为避免手工提取点云体素特征,Zhou和Tuzel提出了一种端到端的目标检测网络VoxelNet,将特征提取与目标包围框检测统一到可训练的深度神经网络中 [6] 。点云平面化是将3D点云映射到特定的平面,然后再利用图像领域的目标检测算法进行处理 [7] 。Chen [8] 等提出了融合视觉与点云信息的目标检测框架MV3D,通过将点云转化为鸟瞰图生成3D候选区域,然后再联合RGB和点云前视图预测目标包围框。基于MV3D鸟瞰图构建方法 [9] ,Yang [10] 等提出了一阶段的基于像素级的神经网络对三维物体进行估计,Ali等 [11] 搭建了端到端的YOLO3D模型,通过拓展YOLOv2的损失函数生成具有朝向的3D包围框。Simony等在YOLOv2 [12] 的基础上提出了3D点云目标检测框架Complex-YOLO,可通过欧拉区域候选网络估计目标的姿态 [13] 。点云直接法是针对原始点云数据进行建模。Qi等 [14] 构建了一种端到端的目标感知框架PointNet,能实现目标分类、分割和场景语义解析等多种功能,为了提高网络性能,Qi等 [15] 在PointNet的基础上提出了PointNet++网络,提高了点云的分类分割准确性。Li等 [16] 提出点云特征学习框架PointCNN,利用X变换对原始点云进行特征提取,然后再利用3D卷积实现目标检测。在实际应用中由于原始点云数据量巨大且特有的稀疏性、无序性和不规则性 [17] ,基于点云体素化和原始点云的深度学习目标检测方法在运算过程中需要消耗更多的硬件资源,对计算硬件平台的内存和算力都具有极大的挑战 [18] 。在自动驾驶系统中部署深度学习模型需要综合考虑硬件的成本、性能与功耗 [19] ,因此在嵌入式平台部署点云平面化的深度学习方法是目前的研究趋势。
此外,由于目前大规模自动驾驶应用尚未兴起,算法也处于不断更新迭代中,选择具备可重构性的硬件能够避免定制化硬件带来的高风险。现有深度学习的计算硬件平台主要包括CPU、GPU、ASIC和FPGA等。其中,FPGA通过支持门级的硬件开发,在特定功能上可以实现比CPU和GPU更高的速度和能量效率。相比于ASIC,FPGA还具有更高的灵活性,以适应不断迭代的算法 [20] 。因此,FPGA是当前自动驾驶领域深度学习模型部署的最佳选择之一。
面向自动驾驶的点云感知技术需要保证性能、功耗和成本符合自动驾驶产品落地要求。本文的主要贡献有:①本文提出了可在FPGA平台快速部署的一种高分辨率且轻量级的MobileNet-YOLOv3点云目标检测网络;②针对非结构化三维激光点云数据处理面临的时延瓶颈问题,本文基于FPGA平台提出了定制化IP加速器将三维点云编码为鸟瞰图像,并结合深度学习加速器实现了完整的硬件加速系统;③基于KITTI测试数据集进行测试,结果表明本文提出的软硬件协同优化的点云目标检测算法低功耗、高帧率且满足自动驾驶检测精度。
本研究设计了面向FPGA平台的激光雷达点云目标检测算法,设计实现了相应的硬件加速系统,并在FPGA平台上进行算法部署与测试。总体研究框架如图1所示。本研究的主要内容包含点云预处理、点云目标检测算法以及数据后处理等模块。
软硬件协同设计的理念是通过设计适合硬件执行的算法,以及定制适合运行算法的硬件,来提高计算系统运行的效率。图1为本文总体研究框架,在算法设计上本文选择轻量级的Mobilenet-YOLOv3来提取点云鸟瞰图像中的特征,并采用欧拉区域候选网络(E-RPN)进行点云场景目标位置和朝向预测。数据后处理包含数据sigmoid函数激活操作、非极大值抑制(NMS)和目标三维信息输出。在硬件设计上,本文采用定制化的IP进行算法中的点云前处理设计,采用XILINX DPU(Deep Learning Processing Unit)IP完成提取特征的神经网络计算,并集成为完整系统。
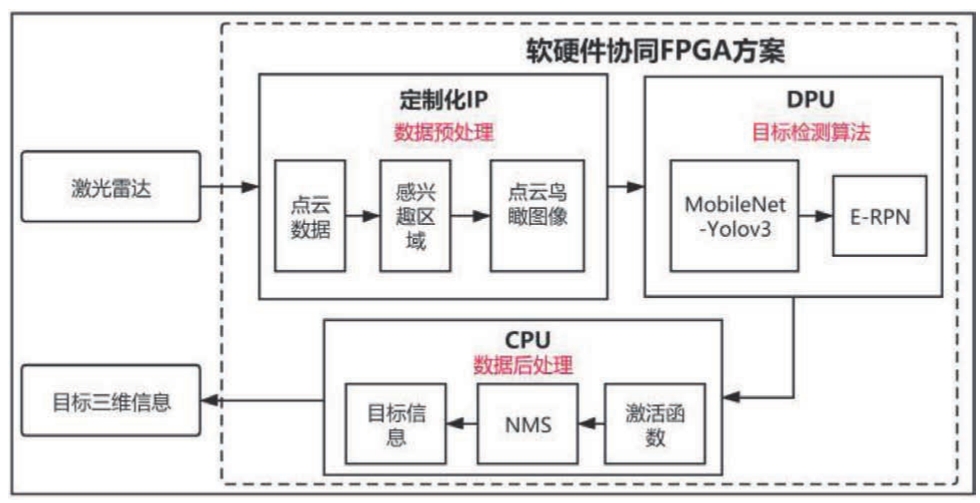
图1 总体研究框架
最终对整个框架进行验证,基于KITTI数据集进行了点云目标检测算法训练与测试,将训练好的算法移植到XILINX ZCU102的FPGA硬件平台上,并评价算法在FPGA平台上的性能。
自动驾驶场景下的算法需要满足实时性、低功耗和低成本等要求,基于FPGA平台进行深度学习目标检测算法部署可在满足算法检测性能的前提下同时满足功耗和成本等要求。本研究选择基于XILINX的ZCU102硬件平台进行算法的设计与部署,硬件结构图如图2所示。该硬件平台核心芯片为一块ZU9EG的FPGA,其内部结构包含ARM A53的CPU以及基础的逻辑门、触发器和存储器等,可通过注入配置文件实现定制化的电路设计,针对不同场景设计相应的功能。

图2 ZCU102硬件结构图
基于MV3D [8] 和Complex YOLO [12] 的点云处理方法,并考虑到自动驾驶场景中一般不存在物体碰撞与重叠,本研究采用将点云转化为鸟瞰图的方式设计目标检测算法。运用图像2D CNN运算高效的特性,将点云压缩为图像来保证检测的准确性和推理的实时性。类似于提出的多视图思想,我们使用特征编码的方式将原始点云转化为单个的RGB鸟瞰图,确保点云的多特征信息基本无损失保留下来。激光雷达在每一帧扫描到的点云为360°环绕方向的,由于激光雷达的线数不同,因此每帧所得点数从几万到十几万不等。为了减少数据量且满足车辆周围的感知范围,取三维空间中车辆前方50m、左右25m、地面以上3.5m范围作为感兴趣区域,并将点云转换成RGB鸟瞰图。其中编码图像的特征为点云的反射率、高度值和密度值。设定鸟瞰图像大小为608×608的图像,将3D点云投影并离散化为分辨率约为8cm的2D图像中的像素大小,可实现更少的误差并具有更高的输入分辨率。由于效率问题,在预处理阶段只使用一层高度图。点云鸟瞰图的R通道取感兴趣范围内的最高点的反射率,G通道取感兴趣范围内最高点的高度值,B通道则取感兴趣范围点的总数。整个前处理过程所得到的点云RGB鸟瞰图可以准确显现在自动驾驶场景中所遇到的不同类别目标,如图3所示,图中红色框中的是汽车,黄色框中的是骑车人,白色框中的是行人。

图3 点云鸟瞰图
本研究提出了三维多目标检测算法MobileNet-YOLOV3,图4所示为该算法的流程图,主要包含YOLOV3和欧拉区域候选网络。本文使用YOLOV3的架构针对不同类型大小的目标进行特征提取,然后使用欧拉区域候选网络预测目标的类别、三维空间位置和朝向信息。其中MobileNet网络作为神经网络的基本单元嵌套在YOLOV3中,可大大降低网络的参数量。
点云目标检测是在点云鸟瞰图中检测目标的最小边界框和边界框的朝向,即待检测目标的位置和方向。如图5所示,本文骨干网络使用了MobileNet-YOLOV3的多尺度预测结构。为节省算法推理的时间,网络设计采用单阶段目标检测的思想。整个网络采用Anchor Box的方式,将物体的长宽高、三个坐标以及物体的朝向角一次预测出来,最后网络的输出值为物体真实长宽高对应鸟瞰图中的像素个数,物体坐标值相对于物体中心所在网格左上角像素点的偏移量,物体相对于Anchor三个不同方向的偏移量。
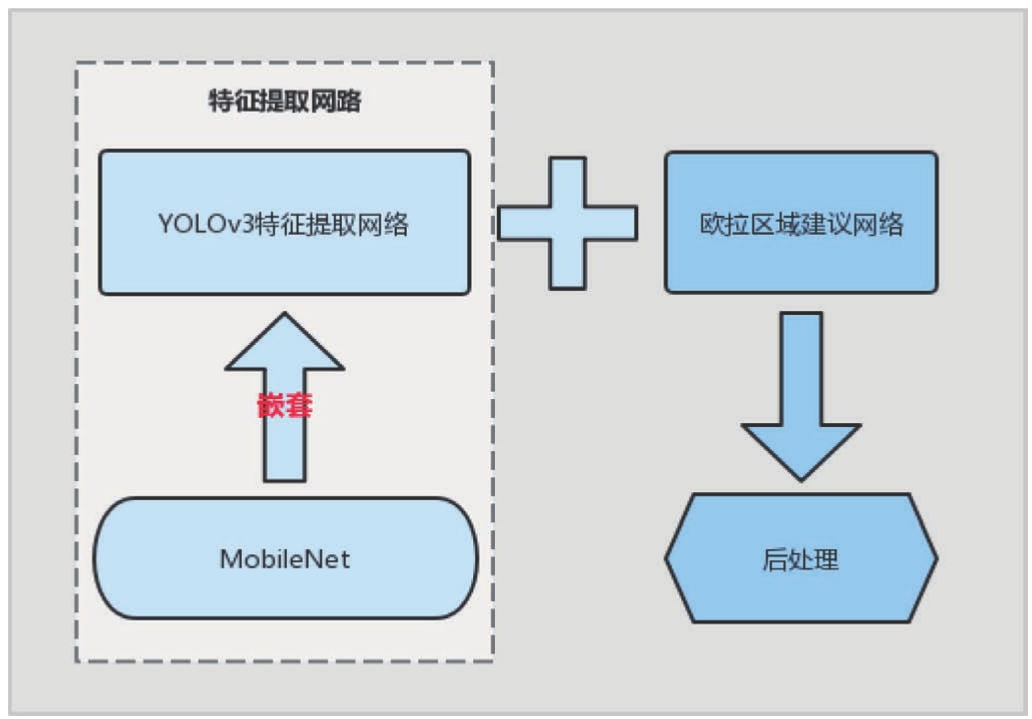
图4 目标检测算法流程图
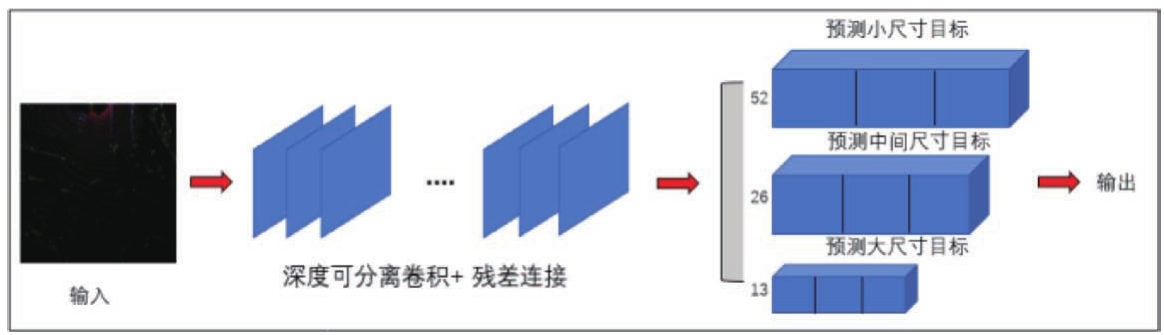
图5 MobileNet-YOLOV3的多尺度预测结构
MobileNet网络主要由反转残差单元构成,反转残差单元包含深度可分离卷积和残差连接。深度可分离卷积是神经网络结构的关键组件,将标准卷积分成两步实现。深度卷积通过对每个输入通道执行利用单个卷积核进行滤波来实现轻量级滤波,逐点卷积通过计算输入通道间的线性组合来构建新的特征。该卷积模块通过稀疏化的大的中间层来减少测试阶段所占用的内存空间,适合移动端设计。由于减少嵌入式硬件设备对内存访问的需求,提供了少量非常快的软件控制缓存策略,故选其作为点云检测网络的基本结构。在特征提取和预测头输出阶段,分别使用深度可分离的卷积用于降低网络的运算量,大幅提升推理速度。为解决小目标检测不准确问题,使用了MobileNet-YOLOv3的结构思路,在32倍上采样和16倍上采样后分别进行反卷积,保证特征不丢失,然后与上一个特征图进行聚合。在网络输出头进行预测时,分别设定三个不同的卷积层来预测不同尺寸的目标信息。结合方向信息,在Anchor取值时,每个输出头对应一种尺寸,对于每一个输出头对应三个不同方向但同一尺寸的Anchor,一共为9个Anchor。最后一层网络特征图中每一个网格需要预测9个边界框及其长宽高、三维坐标、朝向角虚部实部、物体置信度、四个类别的类别置信度等共13个值。
欧拉区域网络可同时输出笛卡儿坐标系下的物体的长宽高、三个坐标以及物体的朝向角,网络的输出值为物体真实长宽高对应鸟瞰图中的像素个数,物体坐标值相对于物体中心所在网格左上角像素点的偏移量,物体相对于Anchor三个不同方向的偏移量。为避免0°和360°在预测时出现奇异值突变,引入了欧式坐标系,将朝向角拆分为实轴和虚轴,在Anchor中设定三个方向,即0°、120°和240°,从而以最小的代价使得预测值更加接近真实值。
网络优化的损失函数是基于YOLO网络结构设计的,定义损失函数如下:

式中, L yolo v 3 为本文基于YOLOv3网络的损失函数; L euler 为本文基于欧拉区域候选网络的损失函数。其中, L yolo v 3 和 L euler 可分别表示为
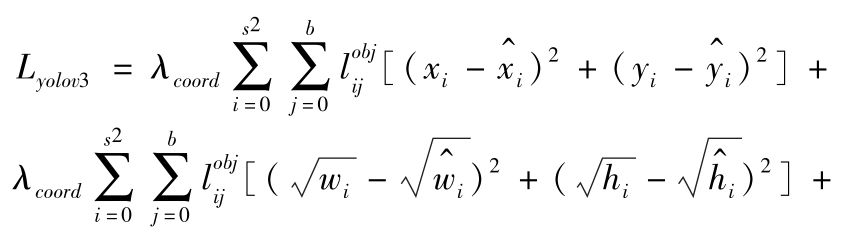
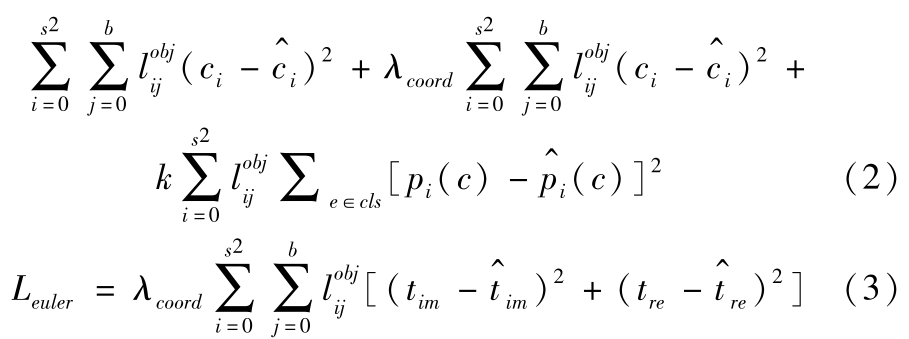
式中,
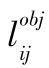 为第
i
个栅格中第
j
个边界框是否负责检测目标,与目标真值框的IOU最大的边界框负责该物体的坐标预测;
s
,
b
分别表示特征图的网格数量和anchor的数量;
k
(取值为0或者1)表示目标是否为此类的系数;
x
i
,
y
i
,
w
i
,
h
i
,
c
i
,
p
i
,
t
im
,
t
re
分别代表目标物体在图像中的横坐标偏移量、纵坐标偏移量、宽度值、高度值、物体置信度、类别置信度、朝向虚部和朝向实部真值;
为第
i
个栅格中第
j
个边界框是否负责检测目标,与目标真值框的IOU最大的边界框负责该物体的坐标预测;
s
,
b
分别表示特征图的网格数量和anchor的数量;
k
(取值为0或者1)表示目标是否为此类的系数;
x
i
,
y
i
,
w
i
,
h
i
,
c
i
,
p
i
,
t
im
,
t
re
分别代表目标物体在图像中的横坐标偏移量、纵坐标偏移量、宽度值、高度值、物体置信度、类别置信度、朝向虚部和朝向实部真值;
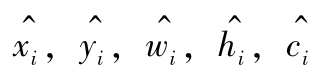 ,
,
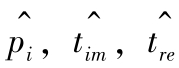 是对应量的估计值。
是对应量的估计值。
在自动驾驶感知模块中,不仅要考虑硬件资源中数据传输与运算,还要考虑软件算法运行的高效性。针对本文所设计的激光雷达感知算法,CPU处理的部分甚至已经成为瓶颈。
基于CPU的点云预处理速度慢的主要原因在于对存储器的大量随机访问。预处理的计算过程根据点的位置计算输出矩阵对应元素的特征。由于点云位置的稀疏性和随机性,CPU在工作时存在大量的cache miss,造成整体性能损失。另一方面,嵌入式CPU本身的运算能力较弱,并行度低,也影响了计算性能。
为此,本文针对所提出的点云鸟瞰图目标检测算法进行了定制化的硬件加速系统设计。首先,预处理加速器通过定制化的片上缓存和计算任务调度方式来避免计算过程反复访问外部缓存。其次,通过流水线设计并行化每一组特征的计算。最后,以共享内存的方式结合Xilinx DPU完成硬件系统,实现点云目标检测的高效处理。
对于点云预处理部分,本文使用FPGA逻辑部分设计定制化的预处理加速器,实现将实时扫描的三维原始点云转换为二维RGB鸟瞰图。本研究设计了高效的硬件架构,充分利用流水线技术,极大地提高了数据吞吐率,并对数据存储结构进行了优化,极大地节省了片上存储资源。
图6所示为点云预处理加速器的系统框图。点云预处理加速器系统主要包括四个部分:控制模块、数据搬移模块、特征提取模块以及特征映射模块。
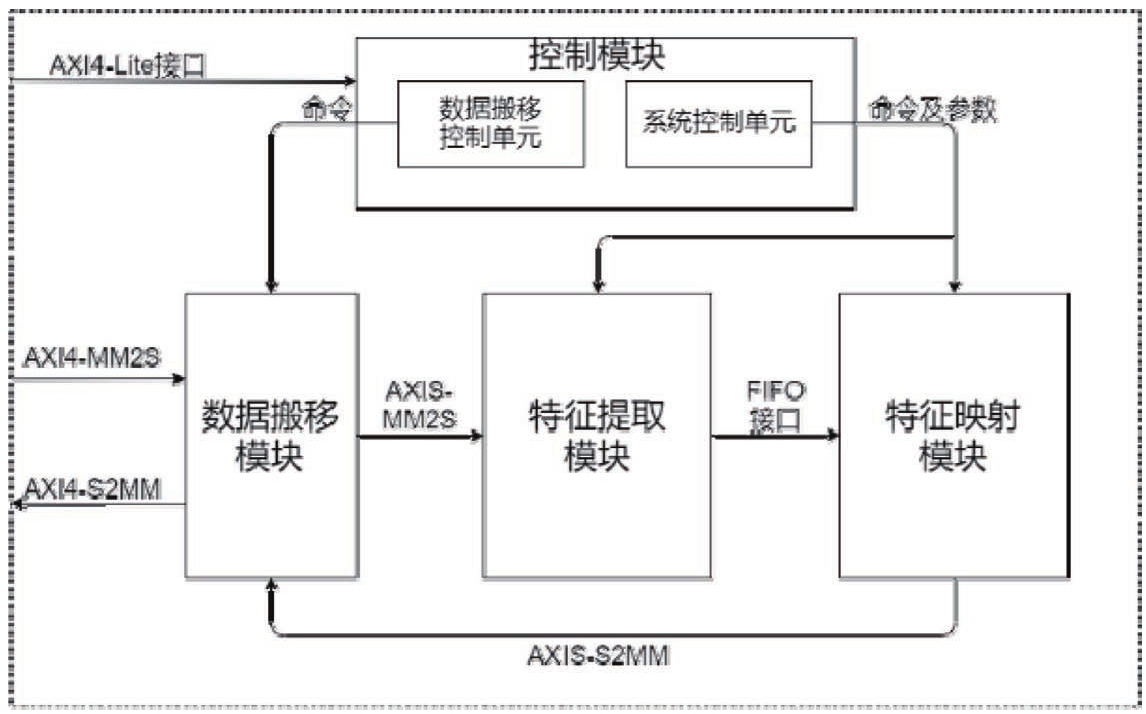
图6 点云预处理加速器的系统框图
控制模块包括数据搬移控制单元和系统控制单元。外部可通过AXI4-Lite总线接口对加速器进行参数配置。数据搬移控制单元负责给数据搬移模块发送控制命令,以进行正确读写操作。
系统控制单元主要负责对特征提取模块、特征映射模块进行参数配置及控制。数据搬移模块负责与系统内存进行数据交互,包括MM2S和S2MM两个通道。MM2S通道负责从系统内存中读取点云数据,并通过AXI4-Stream总线接口发送至特征提取模块。S2MM通道负责从特征映射模块接收处理完的RGB特征图,通过AXI4-Stream总线接口写回到系统内存中,以进行后续的处理。
特征提取模块用于以四条并行的数据处理链路分别对点云数据的坐标值以及反射率 r 值进行处理,得到每个点云数据在RGB鸟瞰图中的对应位置坐标以及特征值。图7为预处理加速器特征提取模块的结构框图。
该模块每个周期从MM2S通道读取4个浮点数(即一个点云数据)进行并行处理,首先进行边界选择,判断该点是否在感兴趣范围内,不在范围内的点直接抛弃。在范围内的点需要进行尺度变换,将三维点云的空间坐标映射为二维RGB鸟瞰图坐标( x , y ),并将 z 值和 r 值进行归一化。
然后进行浮点转定点操作,定点数的精度设置由算法决定。对四条数据链路的计算结果通过FIFO进行同步。最后计算RGB鸟瞰图坐标( x , y )所对应的RAM地址,并将RAM地址、 z 值和 r 值拼接后存入特征映射模块内的FIFO中。
特征映射模块主要负责特征图的存储、更新与写回。该模块的结构如图8所示。特征提取模块可以每个时钟周期处理一个点,形成一组特征。而存储特征图的缓存因为数据依赖关系无法在一个时钟周期处理一个点。为了保证更新特征图的速度,本研究将3D点云映射后的RGB特征图存储分为4个区域,各由一个双端口RAM维护,按列进行间隔存放,以在按行读出的过程中可以一次读取4个特征。每个特征点计算后,根据其位置去更新对应RAM中的特征。同时每组计算单元之前设置FIFO来缓解因为特征点在四个RAM中分布的不确定性而导致的阻塞。
当特征图全部更新完成后,启动特征图回传模块。特征图以每个周期四个像素点的速度写回系统内存,同时将RAM中的特征图清零,等待下一帧计算。以KITTI数据集为例,单张特征图的分辨率达到608×608,保存整张RGB特征图会消耗超过1MB的缓存,这将极大地恶化电路时序并影响系统中其他模块的配置。因此本设计对存储结构进行优化,并可通过参数化配置,对特征图进行切割后分多次进行处理和传输,在确保性能满足需求的情况下,尽可能降低片内存储资源的消耗。CPU可通过AXI-Lite总线完成对加速器内寄存器的配置,以实现对加速器的控制。具体的配置由应用场景决定。当参数配置完成后启动加速器,开始从内存的指定地址处读入原始点云数据。加速器工作过程中经处理得到的RGB特征图会根据配置的地址回传到系统内存中的指定位置,同时CPU会轮询状态寄存器查询加速器状态。当加速器完成工作后,对加速器顶层控制逻辑进行复位。
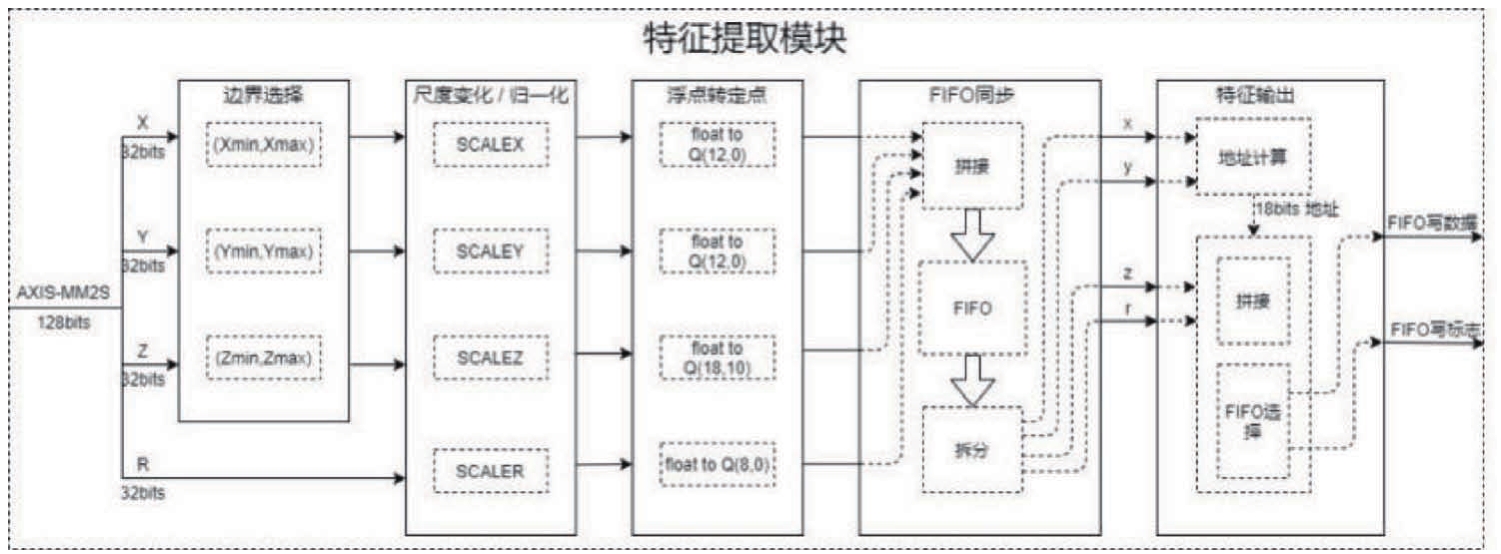
图7 点云预处理特征提取模块的系统框图
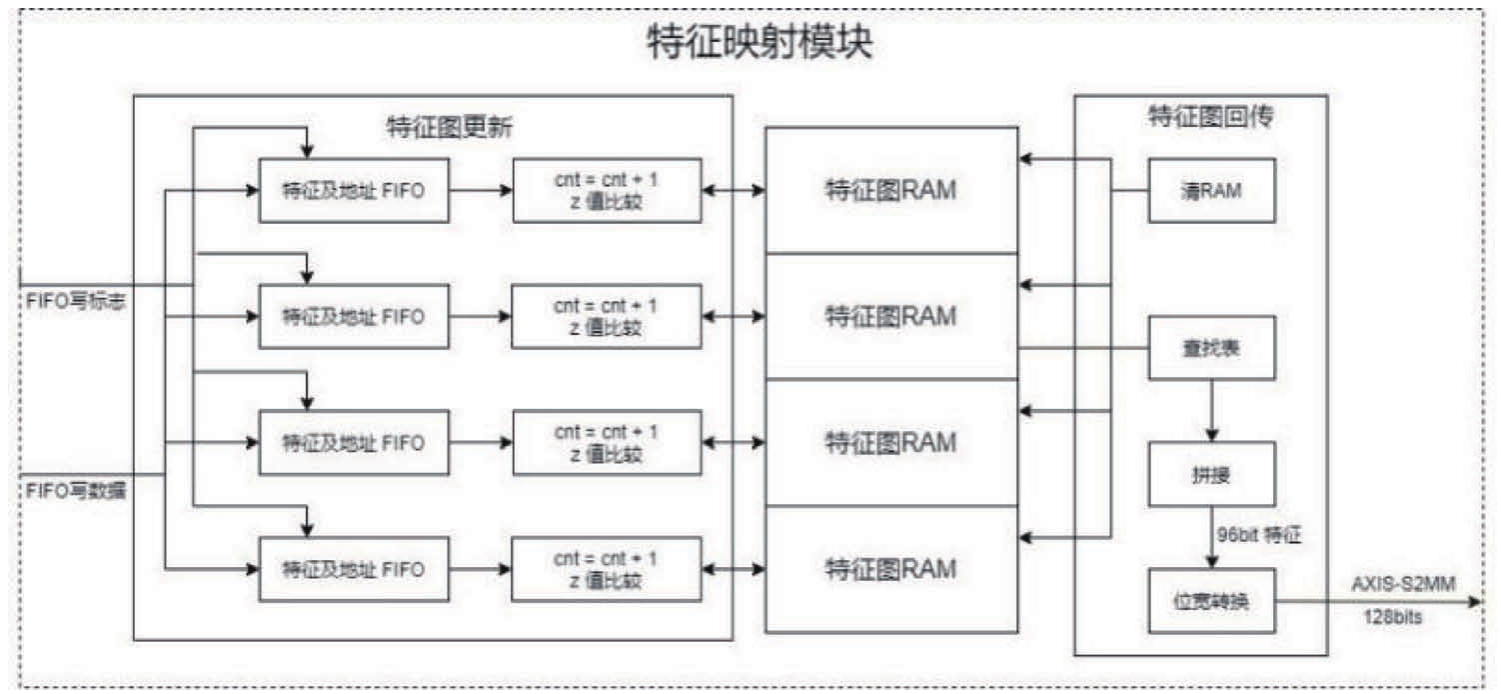
图8 点云预处理特征映射模块的系统框图
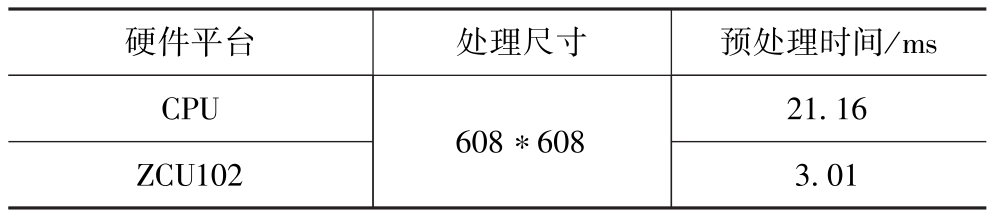
本文使用KITTI数据集对点云预处理加速器进行专门的速度测试,对比了使用CPU和通过预处理加速器加速后的性能,对比测试结果见表1,结果表明使用定制化加速器的预处理方法可以实现7倍的加速。
表1 点云预处理加速器速度测试结果
对目标检测算法部分,我们采用Xilinx面向神经网络的DPU定制化处理器进行加速处理,网络模型通过Xilinx的官方量化工具,将原模型的32位浮点数量化转化为8位整型数,将内存减少为原来的四分之一,乘法器单元得到复用,随后,模型被编译转化为DPU可接收的指令,配置FPGA片上的定制化DPU逻辑进行加速并行处理。
对于数据后处理部分,则放置在FPGA处理系统(Processing System,PS)侧的ARM CPU上进行处理。而对于数据后处理部分,目标检测网络的输出为三层特征图的每个像素点预测的向量值,包括长宽高、三维坐标值、朝向实部和虚部、物体置信度、类别置信度等13个值。后处理的具体过程包括将网络输出值进行激活函数激活获取到对应特征图尺度的可用数据,经过NMS操作后,得到了类别得分最高且只对应单个目标的边界框,其作为最终检测结果。
本研究选择KITTI数据集对比分析验证了方案的有效性,KITTI数据集训练阶段包含训练集3712张、验证集3769张,测试阶段包含测试集7518张。本文基于KITTI官方测试集进行了性能测试。测试集中有三种不同等级,难度等级划分依据标注边界框的属性,简单表示目标无截断和无遮挡,中等表示目标部分截断和部分遮挡,困难表示目标大面积截断和大面积遮挡。
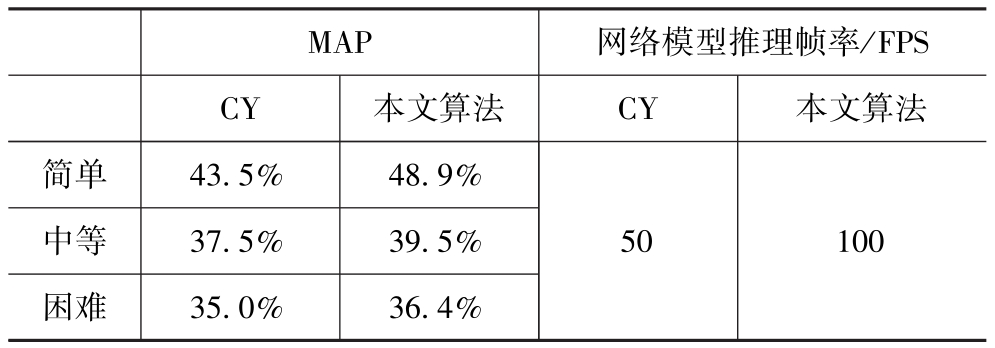
为了验证本文提出算法在速度和精度上的优势,选择在服务器GPU端基于KITTI测试集进行测试。表2为本文算法MobileNet-YOLOV3与Complex YOLO在车辆、行人和骑车人目标不同难度等级的检测精度平均精准率AP(Average Precision)对比。表3为本文算法与Complex YOLO(CY)不同难度等级目标检测任务中的总的平均精准率MAP(Mean Average Precision)与效率对比。由表可见,本文算法在模型推理帧率提升2倍的前提下,不同难度等级下三类目标检测的精度都比Complex YOLO要高,证明了本文提出算法的高效性。
表2 本文算法与Complex YOLO(CY)车辆、行人和骑车人不同等级的检测精度AP对比
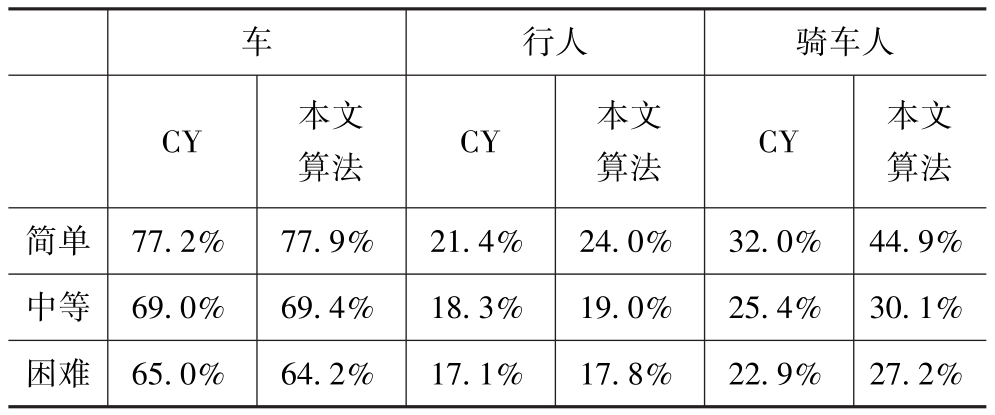
表3 本文算法与Complex YOLO(CY)在不同难度等级的目标检测任务中的精度MAP与效率对比
如图9所示为KITTI测试集中复杂场景下的检测效果对比图,左侧为Complex YOLO的测试效果,右侧为本文算法的测试效果。两种算法对于车的检测效果基本一致;对于骑车人检测的位置基本相似,但是目标的包围框尺寸大小略有不同,但本文的算法精确度更高;对于行人这类小目标而言,左侧Comlex-YOLO算法中实体白色框中为漏检的行人目标,虚体白色框为行人的朝向误检,而本文提出的算法避免了这些情况。总体来讲,本文算法在复杂场景下对于目标的检测显示出了更好的性能。
在GPU和FPGA平台的性能对比上,我们在服务器端使用了一块Nvidia GeForce RTX 2080 Ti配置的GPU卡进行处理,其操作系统环境为Ubuntu 16.04.6 LTS,使用的软件框架为Tensorflow v1.9。而在FPGA上,则在ZU9EG的FP-GA上部署了2个B4096的DPU核心和1个点云预处理加速器核心,频率运行在300MHz,硬件加速系统的FPGA资源占用情况见表4。

图9 复杂场景下算法测试结果对比
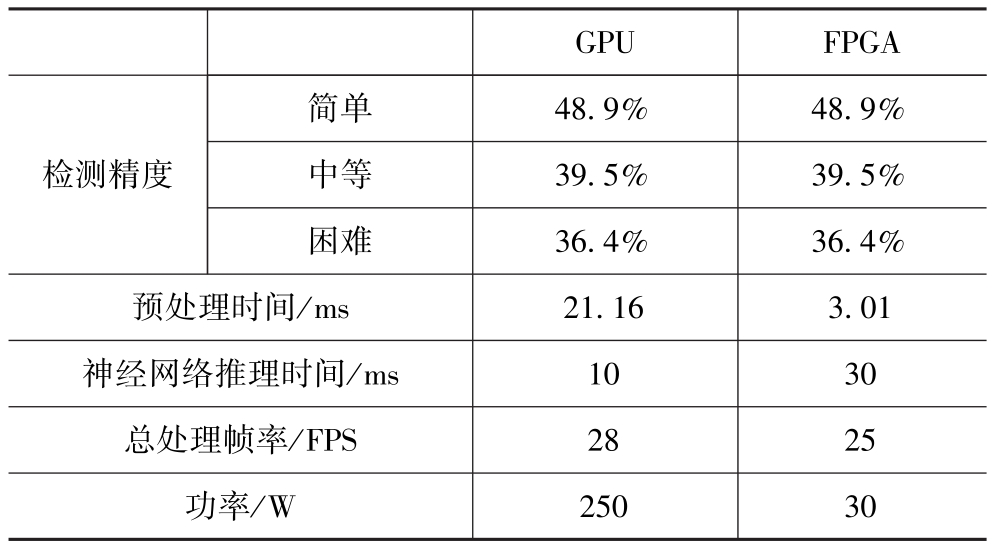
表5为本文算法分别在GPU和FPGA平台上部署后的目标检测精度、运行速度和功耗对比。由表5可得,本文提出的算法在FPGA平台上部署后对于三种不同目标的检测精度与GPU保持一致;FPGA定制化IP的点云预处理时间明显低于GPU;证明了本文提出的软硬件协同点云目标检测方案在FPGA中可以高效率低功耗地运行,FPGA的能效比更高。在满足无人驾驶的低成本、实时性要求下,FPGA平台更能满足落地需求。
表4 硬件加速系统的FPGA资源占用情况
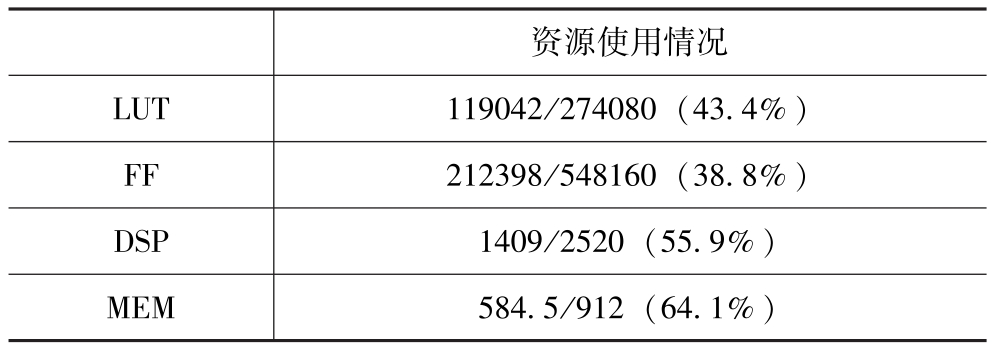
表5 本文算法在GPU和FPGA平台上目标检测精度、效率和功耗对比
本研究提出了一种面向嵌入式系统的自动驾驶激光雷达点云目标检测算法。从软硬件协同优化角度提出定制化IP的数据处理方式将原始3D点云数据转化为鸟瞰图,并提出适合FPGA神经网络推理的轻量级MobileNet-YOLOv3目标检测网络。在FPGA平台部署算法的过程中,又引入量化策略以节省硬件资源和计算成本。本研究提出的点云目标检测算法在FPGA平台上的处理帧率可达25FPS,保证了感知系统中点云数据处理的实时性;且功耗仅30W,达到了自动驾驶低成本应用方案。未来,激光点云的深度学习感知算法会朝着更加多样化的方向发展,因此设计相应的FPGA硬件加速方案来满足自动驾驶落地需求非常有必要。
[1]GEIGER A,LENZ P,URTASUN R.Are We Ready for Autonomous Driving? The Kitti Vision Benchmark Suite[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition,2012:3354-3361.
[2]詹军,董学才,洪峰,等.智能汽车传感器实时功能模型及验证[J].汽车工程,2019,41(7):731-737.
[3]ENGELCKE M,RAO D,WANG D Z,et al.Vote3deep:Fast Object Detection in 3d Point Clouds Using Efficient Convolutional Neural Networks[C]//2017 IEEE International Conference on Robotics and Automation(ICRA),2017:1355-1361.
[4]CHEN X,MA H,WAN J,et al.Multi-view 3d Object Detection Network for Autonomous Driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2017:1907-1915.
[5]徐国艳,牛欢,郭宸阳,等.基于三维激光点云的目标识别与跟踪研究[J].汽车工程,2020,4(1):38-46.
[6]ZHOU Y,TUZEL O.Voxelnet:End-to-end Learning for Point Cloud Based 3d Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2018:4490-4499.
[7]LI B,ZHANG T,XIA T,et al.Vehicle Detection from 3D Lidar Using Fully Convolutional Network[J].arXiv:Computer Vision and Pattern Recognition,2016
[8]CHEN X,MA H,WAN J,et al.Multi-view 3d Object Detection Network for Autonomous Driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2017:1907-1915.
[9]YANG B,LUO W, URTASUN R.Pixor:Real-time 3d Object Detection from Point Clouds[C]//The IEEE Conference on Computer Vision and Pattern Recognition(CVPR),June 2018.
[10]REDMON J, FARHADI A.Yolo9000:Better,Faster,Stronger.In Computer Vision and Pattern Recognition(CVPR)[C]//2017 IEEE Conference on,2017:6517-6525.
[11]ALI W,ABDELKARIM S,ZIDAN M,et al.Yolo3d:End-to-end Real-time 3d Oriented Object Bounding Box Detection from Lidar Point Cloud[C]//Proceedings of the European Conference on Computer Vision(ECCV).2018:0-0.
[12]SIMONY M,MILZY S,AMENDEY K,et al.Complex-yolo:An Euler-region-proposal for Real-time 3d Object Detection on Point Clouds[C]//Proceedings of the European Conference on Computer Vision(ECCV).2018:0-0.
[13]ENGELCKE M,RAO D,WANG D Z,et al.Vote3deep:Fast Object Detection in 3d Point Clouds Using Efficient Convolutional Neural Networks[C]//2017 IEEE International Conference on Robotics and Automation(ICRA).IEEE,2017:1355-1361.
[14]QI C R,SU H,MO K,et al.Pointnet:Deep Learning on Point Sets for 3d Classification and Segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2017:652-660.
[15]Qi C R,Yi L,SU H,et al.PointNet++:Deep Hierarchical Feature Learning on Point Sets in a Metric Space[J].2017:5099-5108.
[16]LI Y,BU R,SUN M,et al.Pointcnn:Convolution on X-transformed Points[C]//Advances in neural information processing systems.2018:820-830.
[17]CHEN Y,LIU S,SHEN X,et al.Fast Point R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision.2019:9775-9784.
[18]FONNEGRA R D,BLAIR B, D G M.Performance Comparison of Deep Learning Frameworks in Image Classification Problems Using Convolutional and Recurrent Networks[C]//Proceedings of the 2017 IEEE Colombian Conference on Communications and Computing(COLCOM),2017:1-6.
[19]BECHTEL M G,MCELLHINEY E,KIM M,et al.DeepPicar:A Low-cost Deep Neural Network-based Autonomous car[C]//2018 IEEE 24th International Conference on Embedded and Real-Time Computing Systems and Applications(RTCSA).IEEE,2018:11-21.
[20]GUO K,ZENG S,YU J,et al.A survey of FPGA-based neural network accelerator[J].arXiv preprint arXiv:1712.08934,2017.