
下载掌阅APP,畅读海量书库
立即打开



1996年,Oren Etioni首次提出了Web数据挖掘概念。该学者认为,Web数据挖掘可运用数据挖掘技术,从Web页面或服务中自动地发现和提取信息,它既是一项综合性技术,也是数据挖掘技术在Web领域中的应用。Srivastava对Web数据挖掘做出了如下定义:从Web页面或服务中提取出感兴趣的潜在的有用模式和隐藏信息。在维基百科上,Web数据挖掘又被定义为利用数据挖掘技术从Web中发现模式。若从传统数据挖掘的角度出发,则可对Web数据挖掘做出如下定义:从大量非结构化或异构的Web资源中,发现有效的或潜在可用的,以及最终可以理解的知识。话题就是这些知识集合中的一个对象。
早在1996年美国国防部高级研究计划局就已提出,要在没有人工干预的情况下自动检测出Web新闻数据流中的话题,这也是对TDT(Topic Detection and Tracking,话题检测与跟踪)技术进行研究的开端。这项研究更多地关注如何检测新话题,如何获取与特定话题相关的信息。因此,在对话题检测与跟踪技术进行研究的过程中,对话题定义的描述也有别于对传统话题定义的描述,它更倾向于对某特定事件及相关活动进行描述。
Web新闻信息的复杂性决定了Web数据挖掘任务的多样性,可将其划分为如下三个类别。第一,Web内容挖掘;第二,Web结构挖掘;第三,Web使用挖掘。由此形成了具有层次性的研究框架,在该框架中,每层所包含的研究方法或采用的技术手段都对计算机能够自动分析Web资源中所蕴含的知识做出了一定的贡献。但即使这样,计算机仍然不能像人类那样去深入理解Web资源。这是因为人类在浏览Web资源时加入了对信息特征的理解。如何使计算机像人类一样在理解Web资源时也考虑到该资源所具有的信息特征,有针对性地去分析Web资源,正是笔者基于传统数据挖掘思想开展Web文本挖掘研究的出发点。
近年来,随着社会事件的不断发生,网络上及时发布的Web新闻已成为用户关注社会事件发展脉络的主要信息源之一。
如图1.3所示,在主题时间轴上,从每个社会事件发生开始,就会有海量的Web新闻对其进行报道。面对海量的Web新闻,公众更渴望从社会事件主题中获知能够体现大数据特点的信息,而这些信息又能反映出社会事件在不同发展阶段的一系列演化过程。因此,在研究过程中,笔者将发生的社会事件定义为主题,针对发生的每个社会事件,先从Web新闻内容归属的主题角度进行分析,以便将海量报道社会事件的Web新闻实例聚类在相应主题下,再对主题背景下的Web新闻实例信息进行增量式提取,以便进行五元组语义描述分析。

图1.3 主题时间轴

图1.3 主题时间轴(续)
作为网络服务中的一种流式资源,聚类在相应主题下的Web新闻具有明显的动态变化性,而这种变化的载体就是话题。随着时间的流逝,话题反映了Web新闻所报道的事态在某一阶段中的渐变过程。该过程正体现了用户获知事态变化的逻辑顺序,用户在关注某个Web新闻所报道的社会事件主题时,总是希望能够获知该主题下各阶段所反映出的话题。因此,若能准确检测出主题下各阶段所反映出的话题信息,并对其出现时间排序,再进行精练描述,则可使用户更深一层获知主题下事件发展的脉络。
如图1.4所示,以德国A320客机坠毁事件为例,在主题下的话题时间轴上,表示出了公众对此事件的关注过程,即救援、遗体、身份、默哀、黑匣子、副驾驶、蓄意等。在上述过程中的每个关注点上,又有海量的Web新闻给予支持,从研究者的角度观察,可将其视为由一系列事件支持的话题。因此,在研究过程中,针对发生的每个社会事件,可将主题下的海量Web新闻实例聚类在相应话题下,利用其五元组语义来描述,通过其实用性分析来评价,以便进行话题检测与跟踪分析。

图1.4 主题下的话题时间轴

图1.4 主题下的话题时间轴(续)
作为一种能够传播话题演化过程的网络资源,聚类在话题下的Web新闻还具有另外一种明显的动态变化性,这种变化的载体就是事件。随着时间的流逝,事件能够反映Web新闻所报道的事态在某一话题下的渐变过程。该过程正体现了用户获知事态变化的逻辑顺序,该顺序打破了Web新闻话题的某个状态,注重对Web新闻话题整个动态演化过程的深度理解,同时突出了Web新闻话题演化过程中各状态之间的关系。因此,若能准确地挖掘出话题下的一系列衍生事件信息,并对其出现时间排序,再进行精练描述,则可使用户更深一层获知话题的演化过程。
如图1.5所示,在话题下的事件时间轴上,对于德国A320客机坠毁事件的副驾驶话题,公众的关注经历了昏厥、自杀、动机等过程。在上述过程中的每个关注点上,又有海量的Web新闻给予支持,从研究者的角度观察,可将其视为由海量Web新闻支持的事件。因此,在研究过程中,针对发生的每个社会事件,可将话题下的海量Web新闻实例聚类在所衍生的事件下,以便进行大数据背景下的Web层次化话题检测与跟踪分析的应用。

图1.5 话题下的事件时间轴
话题检测是一个对海量语料进行分析,从分析结果中获取新的知识,并将其描述出来的工程性过程。为了确保话题检测结果的准确率,在检测过程中需要分析海量语料的多维特征,定义解决问题的模型,提出解决问题的方法。在现有研究中,多从分析Web文本内容中的关键词和关键主题两个方向对隐含的话题进行检测,如表1.1所示。
表1.1 话题检测方法研究现状
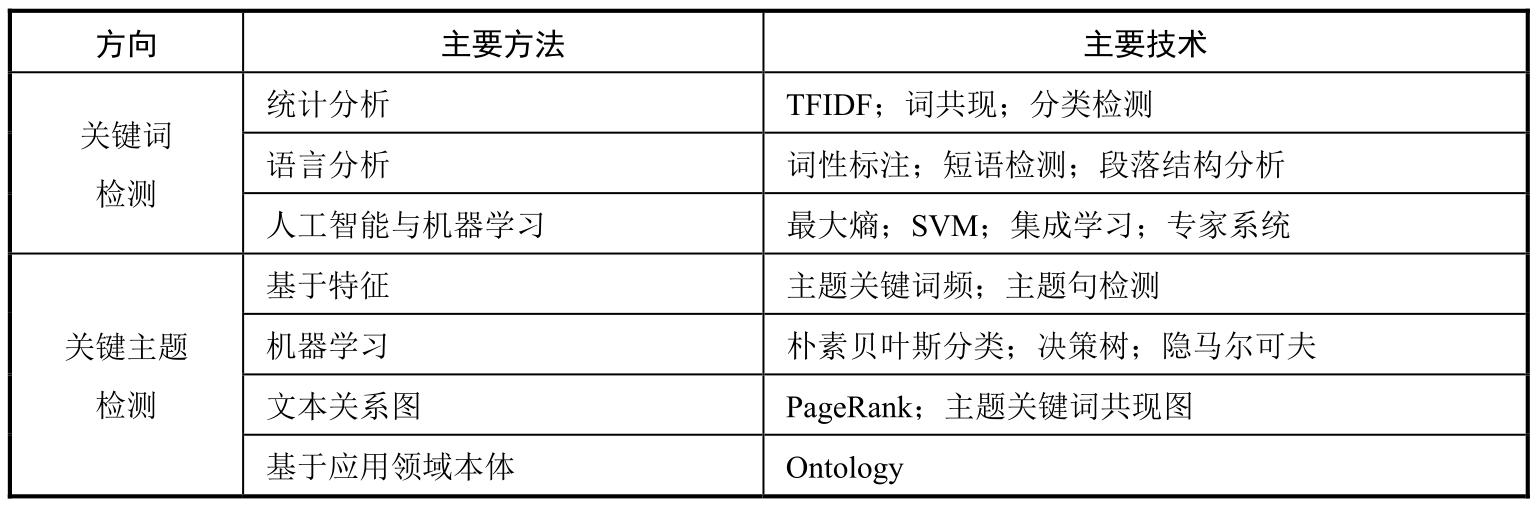
Zhang等提出了一种基于密集关键词群权值计算的话题检测方法,该方法检测出了基于信息的带有权值的粗糙密集关键词群,重新定义了基于信息间链接关系和权值更新的关键词群,检测出了与关键词群最为相似的信息所归属的文档,分析出了海量文档中所蕴含的话题信息,实验过程和结果说明了该方法对于话题检测的有效性。Bagheri等提出了一种基于先验知识的话题检测方法,该方法分析了文本中先验句子所在的位置,提取出了具有多先验知识的文本,检测出了基于多先验知识文本的话题,分析出了海量文本中所蕴含的话题信息,实验过程和结果说明了该方法相对于传统的话题检测方法的优势。Bao等提出了一种面向信息流的话题检测与描述方法,该方法分析了信息所具有的特征,提取出了信息中的共现关键词,过滤了不属于信息特征的内容,构建了关键文本与关联实例之间的关系,描述了面向信息流的话题内容,分析出了海量信息中所蕴含的话题内容,实验过程和结果说明了该方法在质量和数量分析上均具有优越性。Pang等提出了一种基于相似扩散视角的话题检测方法,该方法设计了类似于相似级联的聚类模式,检测出了最大化的聚类范围和基于候选集合的相似话题,分析出了海量记录中所蕴含的话题信息,实验过程和结果说明了该方法相对于传统的话题检测方法的优越性。Sayyadi和Raschid提出了一种基于关键图的话题检测方法,该方法分析了关键词的共生特点,过滤了不相关的文档信息,检测出了基于关键图的话题,分析出了海量文档中所蕴含的话题信息,实验过程和结果说明了该方法相对于传统的话题检测方法可提高话题检测的准确率,其算法执行性能也优于其他方法。
综合上述话题检测方法的分析可得出,依据网络信息所具有的特点,目前在话题检测方法研究中,仍存在着一些问题和亟待突破的难点。
第一,仅考虑了如何提取其中的关键信息,而忽视了其所归属的主题背景,也未针对信息量增长迅速的特点考虑增量式提取信息。若不充分考虑主题背景下的增量式提取,则具有针对性的信息提取范围会增大,提取复杂度也会增大,并且还会增大对信息进行分析的难度。
第二,没有充分考虑如何准确地描述话题,即网络信息中的哪些内容能够完整地描述其所支持的话题。若不充分考虑这一点,则会增大对网络信息实用性评价的难度,降低对用户使用行为记录的获取准确率。
第三,没有充分考虑能够描述话题的网络信息是否实用,即反映或支持该话题的网络信息是否具有较高的时效性和真实性。若不充分考虑这一点,则不具有实用性的网络信息将会增大话题检测的范围和难度,增加算法的复杂性,降低话题检测的准确率。
第四,仅考虑了从静态特征角度分析,而忽视了话题不仅存在于网络信息中,还反映在用户对其的关注行为中。如果不考虑用户与网络信息的交互过程,就失去了研究的实际价值。
依据上述话题检测过程中所存在的问题和亟待突破的难点,笔者拟从如下三个方面进行研究。第一,研究基于大数据五元组语义描述分析的话题检测关键技术,以对能够描述话题的网络信息进行提取,以及描述网络信息所支持的话题;第二,研究基于大数据实用性评价的话题检测关键技术,以对能够描述话题的网络信息进行实用性判定;第三,研究基于大数据使用行为分析的层次化话题检测与跟踪关键技术,以从用户使用行为中检测出蕴含的话题信息。
若要对海量的Web新闻五元组语义描述进行分析,就必须获取Web数据源,即Web新闻语料。因此,笔者首先要对已有的Web新闻内容采集方法展开研究,分析出其中存在的问题和亟待突破的难点。
20世纪80年代,国外的Web数据采集技术研究起步。迄今为止,国内外在该理论及技术方面的研究仍在不断发展和进步,并取得了一些较有意义的成果。在对Web新闻进行数据采集的研究中,Soderland提出了面向Web新闻的基于自然语言处理方式的信息提取方法,利用该方法的主要原因是Web新闻中包含大量的非结构化文本,而这些文本在Web新闻发布规则下又合乎一定的语法逻辑。因此,研究者借鉴自然语言处理技术,利用Web新闻结构与内容的特点,构建了基于语法和语义的提取规则,实现了对Web新闻内容的提取。目前,主要采用该方法对Web新闻内容进行提取的系统有RAPIER与SRV等。Muslea等提出了面向Web新闻的基于包装器归纳方式的信息提取方法,该方法利用用户已标记的Web新闻实例,应用了机器学习方式的归纳算法,并生成了基于对所关注语义内容上下文描述的提取规则。目前,主要采用该方法对Web新闻内容进行提取的系统有SJALKER与SOFTMEALY等。Embley等提出了面向Web新闻的基于Ontology方式的信息提取方法,该方法主要基于知识专家所构建的应用领域本体,并利用对Web新闻自身的描述信息实现对Web新闻信息的提取。由Brigharn Yong University小组研发的Web新闻信息提取工具就采用了该方法,由QUIXOTE小组研发的Web新闻信息提取工具也采用了该方法。针对Web新闻的特点,Cooley提出了面向Web新闻的基于HTML结构的信息提取方法,该方法主要依据Web页面结构来定位信息,在提取Web新闻信息之前,先通过解析器将Web新闻源文件内容解析成语法树,再通过自动或半自动方式生成一定的提取规则,以将对Web新闻信息的提取过程转化为对语法树的操作过程。目前,主要采用该方法对Web新闻内容进行提取的系统有LIXTO与XWARP等。Yan等提出了面向Web新闻的基于Web查询的信息提取方法,该方法将对Web新闻信息的提取过程转化为使用标准的Web查询语言对Web新闻进行查询的过程。目前,主要采用该方法对Web新闻内容进行提取的系统有WEB-OQL与PQAgent等。其中,PQAgent引入了学习生成基于XQuery的提取规则,应用该规则可直接定位到提取对象,并将对Web新闻信息的提取过程转化为利用XQuery对Web新闻进行查询的过程。在该过程中,统一了HTML和XML查询,这不仅有助于最终用户的使用,还有助于其他应用程序对包装器的调用。
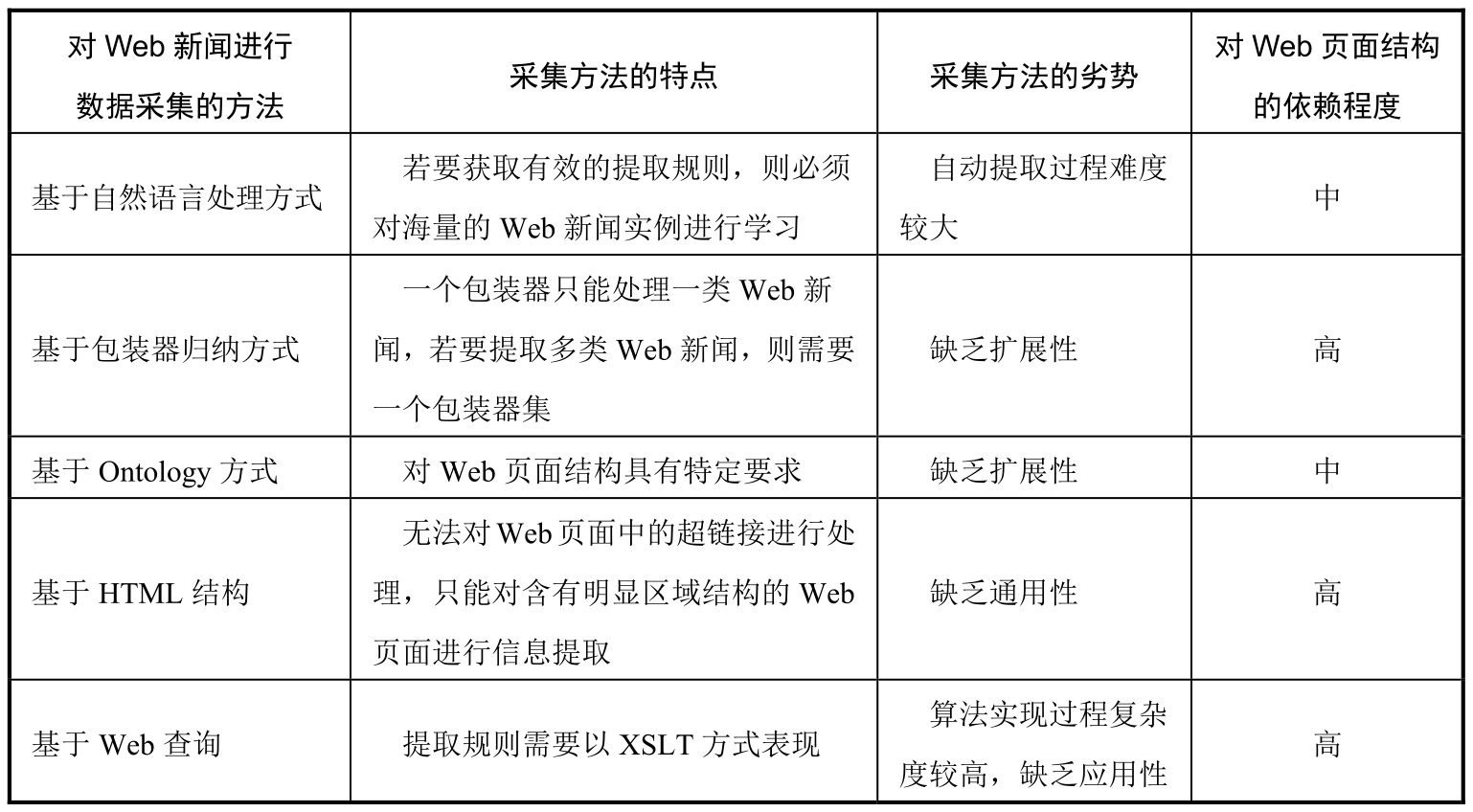
在上述对Web新闻进行数据采集的五类研究中,由于对Web新闻内容进行提取的方式不同,因此对Web页面结构的依赖程度也有所不同。虽然每类研究均有各自的优势,但其劣势也较为明显,如表1.2所示。
表1.2 面向Web新闻的数据采集方法研究现状
目前,针对频发的社会事件发布的Web新闻数量正在不断地动态增长。基于上述对面向Web新闻的数据采集方法研究现状的分析,笔者拟通过将Web新闻内容作为数据采集的对象,并从其归属的主题角度分析,采取增量式元素提取方法,以获取对Web新闻进行分析的语料库,解决面向Web新闻的数据采集方法中所存在的问题。
除要获取能够检测话题的Web新闻语料以外,还要对其进行五元组语义描述分析,以使计算机能够理解Web新闻所报道的内容。因此,笔者还要对已有的Web新闻内容语义分析方法展开研究,分析出其中存在的问题和亟待突破的难点。
早在20世纪90年代国外研究者就已经开始对Web新闻信息进行语义分析。在这个过程中,研究者采用了关键词提取与语义相似度计算等技术。近年来,国内外研究者在该理论及技术方面的研究仍在不断发展和进步,并取得了一些较有意义的成果。在对Web新闻内容进行语义分析的研究中,Guo等提出了采用两种方法对Web新闻特征进行选择:一种是阈值过滤法;另一种是排序筛选法。前者通过设定一个阈值,将所有特征权值小于该阈值的特征过滤掉,只保留特征权值大于或等于该阈值的特征;后者则先对所有的特征按照权值大小进行降序排序,再选出前 N 个特征作为Web新闻特征。在基于特征选取的聚类过程中,需要进行相似度度量,因此采用式(1.1),利用欧几里得距离计算理论,对Web新闻实例之间的相似度进行计算,并得出其相似度值。其中, x 与 y 分别表示两个Web新闻实例的内容向量。
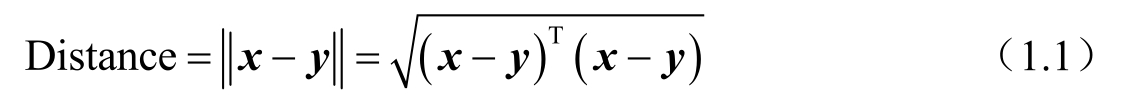
在采用布尔模型的情况下,Chen认为,两个Web新闻实例之间的相似度与其中共现的索引项比例有关,该观点简单直观。在采用向量空间模型的情况下,Zhan等认为,需要将Web新闻内容解析成一些特征的集合,并通过计算权值来衡量这些特征。因此,可采用式(1.2),将Web新闻内容用特征向量进行表示,并通过比较向量之间的距离判定Web新闻内容之间的相似度。其中, x 与 y 分别表示两个Web新闻实例的特征向量。
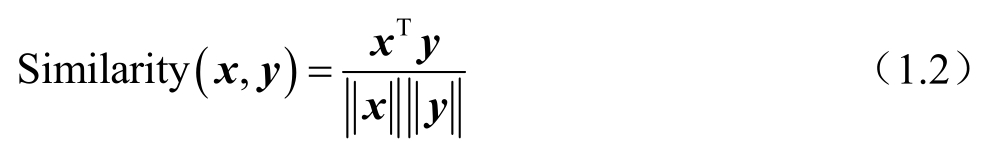
Sjovaag和Stavelin提出,用四维向量空间表示Web新闻内容,四个维度的特征共同构成Web新闻的主体信息。在该文档模型中,还将时间的概率分布函数放大或缩小了相似的系数,并对重要特征的相似度进行了加权处理。因此,采用式(1.3),表示组成Web新闻主体信息的四个维度。其中,WebNews title 表示Web新闻中的标题维度;WebNews content 表示Web新闻中的内容维度;WebNews noun 表示Web新闻中的名词维度;WebNews time 表示Web新闻中的时间维度。

采用式(1.4),表示Web新闻实例之间相似度的计算方式,以判定Web新闻实例之间的相似度。其中,Distance time ( i , j )表示时间距离;Similarity title ( i , j )表示标题相似度;Similarity content ( i , j )表示内容相似度;Similarity noun ( i , j )表示名词相似度。
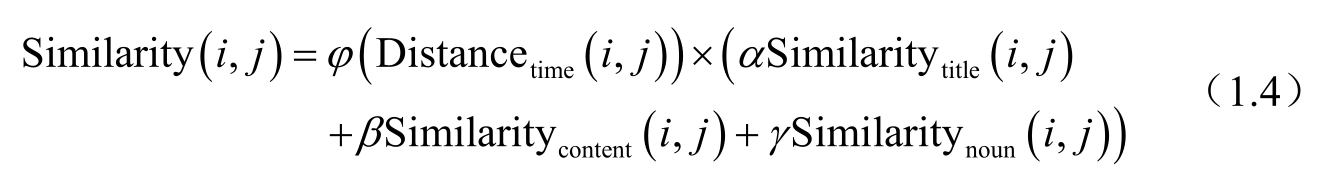
基于上述Web新闻内容语义分析方法的研究现状可总结出,大部分研究均采取了如下处理流程,即对Web新闻进行中文分词,提取关键特征,构建相似度计算模型,计算语义相似度等。然而,对于目前网络上发布的报道社会事件的Web新闻来说,上述流程对如下细节并未加以考虑。第一,Web新闻主要反映的是社会事件中所包含的五元组语义描述信息,而关键特征提取技术还不能准确分析出上述信息;第二,中文时间的表达方式多样复杂,而关键特征提取技术还不能对其实现标准化。若考虑了上述对Web新闻进行语义分析的细节,则可降低话题检测的复杂度,提高话题检测的准确率。
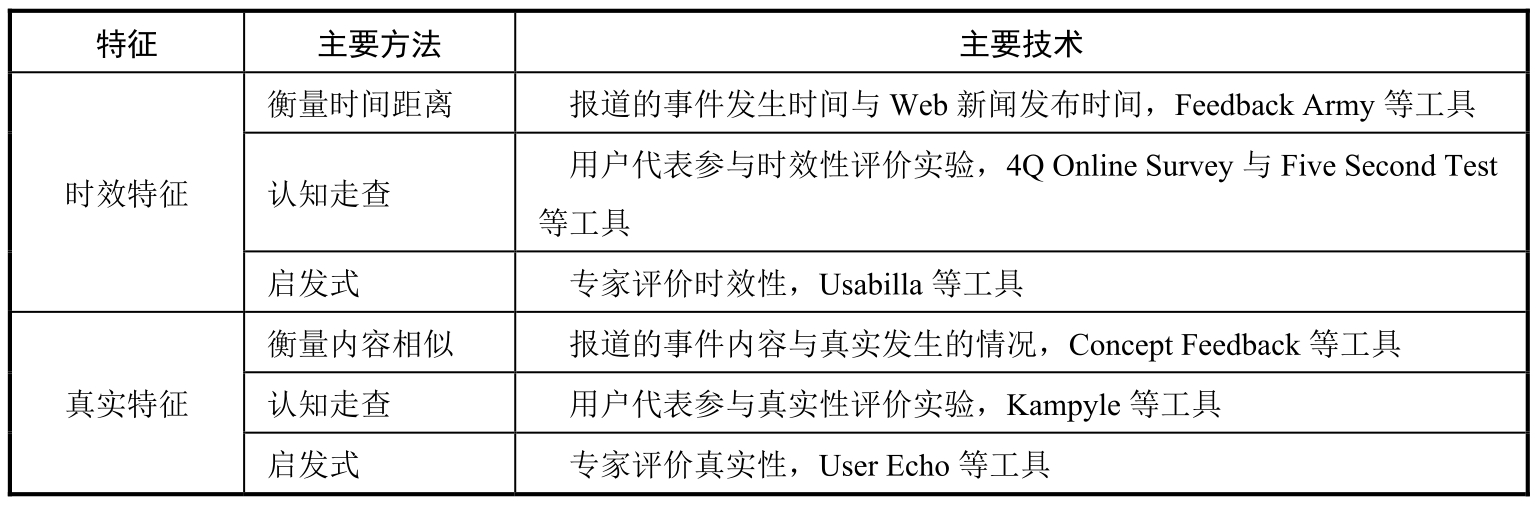
若要对海量的Web新闻进行话题检测,除了要分析其语料的五元组语义,还要对其进行实用性分析,以使支持话题与事件的Web新闻所报道的内容具有时效性和真实性。因此,本节要对已有的Web新闻实用性评价方法展开研究,分析出其中存在的问题和亟待突破的难点。在现有研究中,分别从分析Web新闻的时效特征与真实特征两个方面,对其进行了评价,如表1.3所示。
表1.3 面向Web新闻的时效特征与真实特征评价方法研究现状
Lu等提出,可用性对网络应用的发展具有指导性的作用。该特征并不仅是对用户界面进行考量的一个单维属性,还应具有可学习性与可记忆性,以及满意度等多维成分。若每维属性均能达到可用性的衡量标准,则可说明相应的网络应用具有较高的可用性。然而,具体到Web新闻网络应用,在所发布的海量Web新闻特征及上述可用性背景下,存在两个明显的特征。它们最能说明Web新闻实例是否具有实用性,即时效性和真实性。其中,Web新闻时效性是指,报道每个具体事件的时间要与其实际发生时间接近;Web新闻真实性是指,报道的每个具体事件内容要与真实发生的情况接近。从用户的角度观察,一则Web新闻所报道的事件发生时间与Web新闻发布时间越接近,说明其时效性越高;从研究者的角度观察,Web新闻实例之间的语义距离越小,说明它们之间的相似度越大,它们分布在同时效区间内的概率也就越大。从用户的角度观察,一则Web新闻所报道的事件内容与真实发生的情况越接近,说明其真实性越高;从研究者的角度观察,Web新闻实例之间的语义距离越小,说明它们之间的相似度越大,对真实性评价所做出的贡献也就越大。目前,在对Web新闻进行实用性评价的研究过程中,Wang等提出了如下两类方法。一类是先通过分析Web新闻的时间特征评价其是否具有时效性,再通过分析Web新闻发布来源评价其是否具有真实性。另一类是组织能够代表各种类型目标用户的评价者,按照预定的评价流程,通过对Web新闻各种敏感特征的检测来评价Web新闻是否具有时效性和真实性。
在上述对Web新闻进行实用性评价的研究过程中,存在着如下缺陷。第一,没有充分考虑到研究对象的语义特征,只从时间特征上衡量了其时效性,从发布来源特征上衡量了其真实性,该评价方法是片面的,也是不准确的。第二,存在着主观评价意识,不具有客观性,既会给评价结果附加上个人情感标签,也会使评价结果具有一定的延时。第三,当组织大量评价者对Web新闻进行实用性评价时,组织方需要花费大量的时间来安排所有评价者,观察并指导评价者完成评价流程,统计并分析导出的评价结果,该方式很难利用所有的Web新闻语料特征。第四,Web新闻实例有可能表现出高时效性、低真实性或低时效性、高真实性的情况,若对Web新闻的时效性和真实性分别进行评价,则无法综合两个特征指标并准确评价其实用性。
因此,本书拟将Web新闻语义特征库作为实用性评价的数据源,基于五元组语义描述分析,采取基于时效性和真实性的实用性评价方法,以获取对Web新闻进行话题检测的语料库,解决面向Web新闻的实用性评价方法中存在的问题。