
下载掌阅APP,畅读海量书库
立即打开



随着社会上不断发生各种事件,Web新闻已成为公众对社会事件进行准确了解的信息源之一。随着事件的进展,具有权威性的Web新闻网所发布的信息源数量也会激增。此时,公众更希望从精简的Web新闻内容中获知事件的发展脉络,更希望从对事件所关注的话题角度浏览Web新闻内容。因此,若想以精简的方式描述Web新闻所支持的话题,就要分析蕴含在Web新闻中的语义,并让计算机能够从语义的角度去理解Web新闻。
从全局的角度观察,具有权威性的Web新闻网所报道的每则Web新闻均可看作一个实例节点。该实例节点还可链接多个相关的实例节点。一些实例节点的集合所支持的社会事件则可看作一个主题。该主题又可归属于Web新闻网的专栏节点,主题与多个Web新闻实例之间还可用不同的维度进行衔接,并将它作为一个层次节点。
如图2.1所示,该结构就是分别以具有权威性的Web新闻网为根节点,以海量Web新闻实例为叶子节点的树状结构。从局部的角度观察,在单独分析一个Web新闻实例的结构特征时,可发现其通常包含两部分内容:一部分是与Web新闻报道相关的文本信息;另一部分是与Web新闻报道无关的噪声信息。
因此,若在对Web新闻信息进行提取的过程中能够将Web新闻实例及它们之间的关系部署在树状结构中,并且过滤掉与Web新闻报道无关的噪声信息,则将为对Web新闻进行分析提供一个具有层次性和高质量的Web新闻语料库。
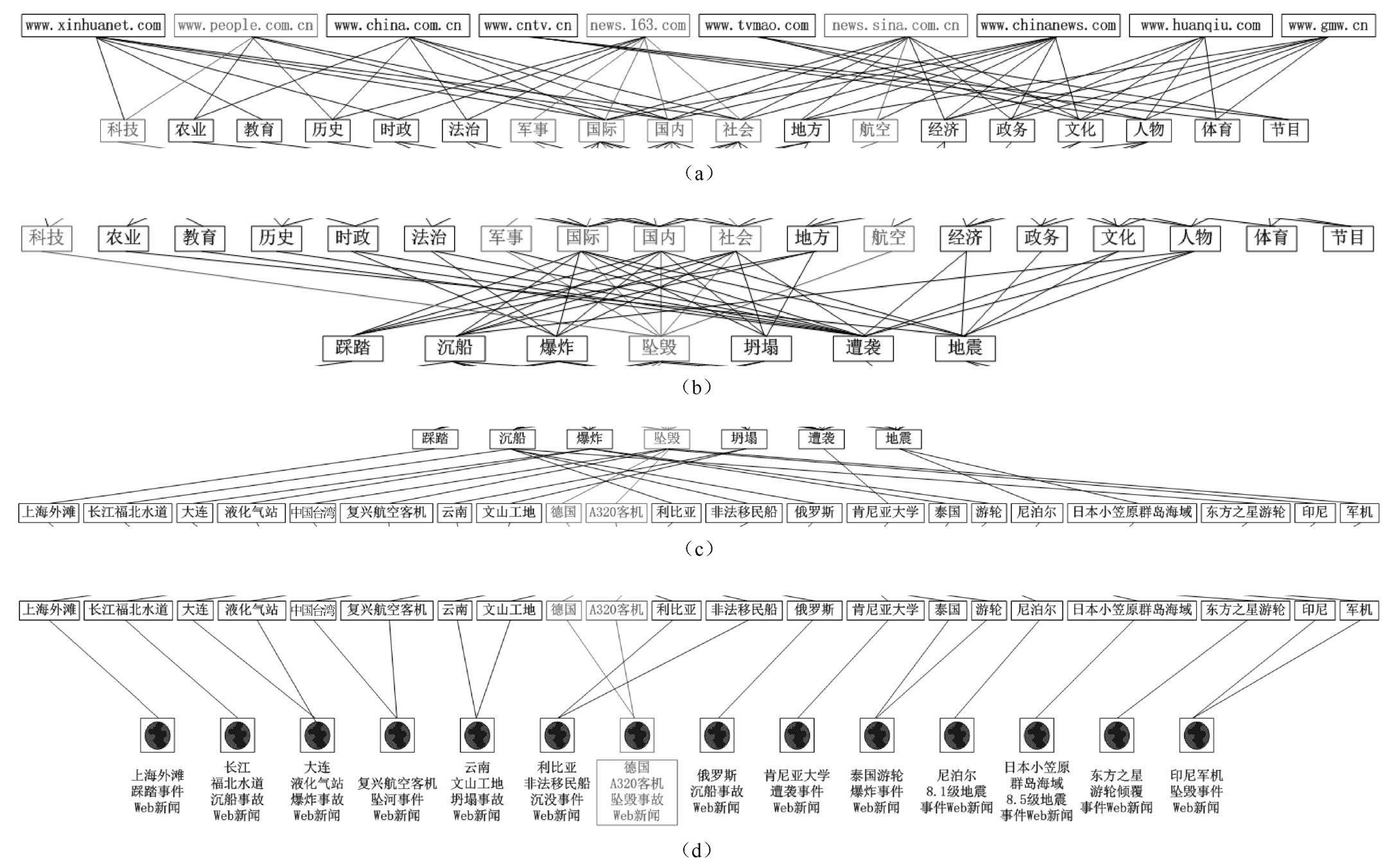
图2.1 面向Web新闻的树状结构层次图
与Web新闻报道相关的文本信息,其内容已呈现非结构化的特征,如图2.2所示。这使得信息提取过程具有一定的难度。

图2.2 Web新闻实例内容特征
通过分析Web新闻所应用的发布模板可看出,<title>元素标签中包含两部分内容。一部分内容是Web新闻标题,另一部分内容是发布机构的名称,两部分内容之间用下画线分隔。<h1>元素标签中也包含Web新闻标题,<div>元素标签中包含Web新闻发布时间和Web新闻发布来源,<p>元素标签中包含Web新闻正文。在分析Web新闻所应用的发布模板时可发现,可从感知Web新闻内容所呈现出来的样式特征角度,确定Web新闻实例数据项所处的位置。例如,在Web新闻中,重要的内容或需要被强调的内容通常会利用<strong>与<h1>等元素标签进行控制。在分析发布在不同网站的多则Web新闻所应用的模板时,可发现一些模板具有相同之处。例如,它们会将Web新闻正文部署在<p>与<div>等元素标签中,并且为具有一定长度的文字。
因此,若在对Web新闻信息进行提取的过程中能够将Web新闻的非结构化内容转储为半结构化内容,则将为对Web新闻进行分析提供一个具有半结构化和高质量的Web新闻语料库。
在半结构化的Web新闻标题和正文中,还蕴含着由多个信息项所组成的较为复杂的语义特征。例如,在Web新闻标题或正文中,存在着Web新闻核心事件,Web新闻核心事件发生时间(该时间有别于Web新闻发布时间),Web新闻核心事件发生地点,Web新闻核心事件发起对象,与Web新闻核心事件相关联的事件。这些主要信息项,既是用户希望从Web新闻标题和正文的大量文本中获知所报道核心内容的需求,也是研究者分析Web新闻内容时的关键切入点。它们表明了Web新闻报道了什么核心事件,该核心事件发生在什么时间和地点,发起该核心事件的对象是谁,与该核心事件相关联的事件是什么。正是这些在Web新闻标题和正文的大量文本背后的语义特征,精练地表示出了Web新闻所要报道的核心内容,它们可构成Web新闻实例的五元组,并可作为话题检测与跟踪分析的完备性语义描述指标,如图2.3所示。
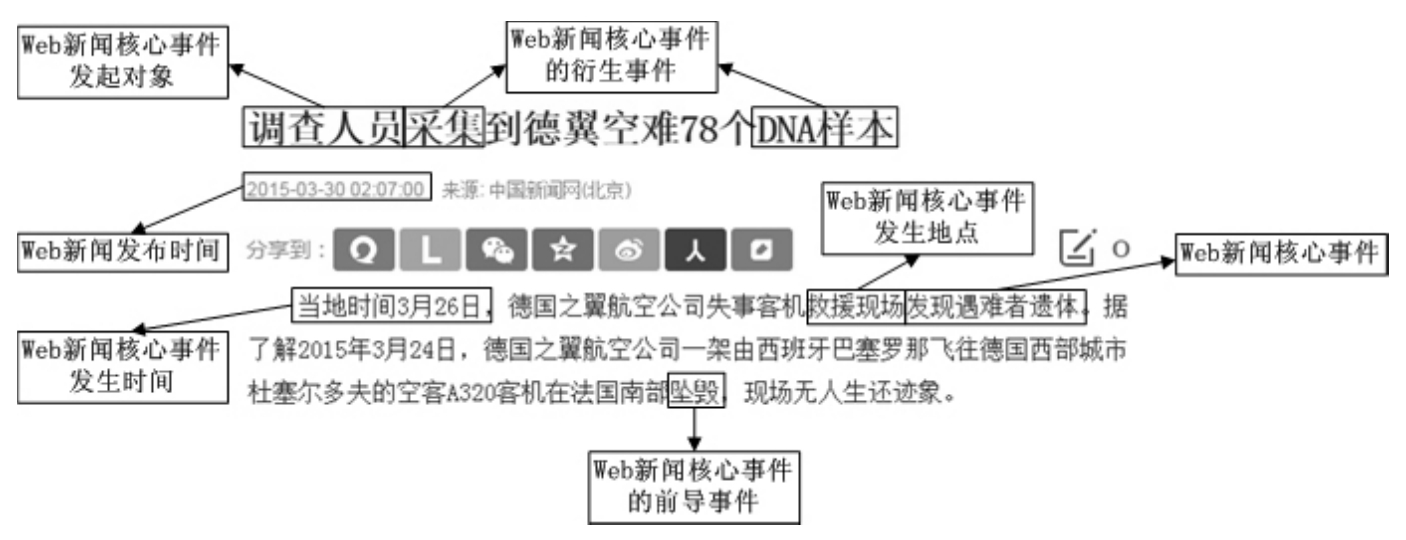
图2.3 Web新闻实例语义特征
因此,若在对Web新闻信息进行分析的过程中能够准确分析出Web新闻实例五元组语义描述信息,则将为对Web新闻进行评价提供一个具有逻辑语义背景的Web新闻语义特征库。
定义2.1:NewsSet是一个Web新闻URL集合,该集合是Web新闻信息提取的种子数据源,它包含具有权威性的Web新闻网中的海量Web新闻URL。
NewsSet={ns 1 ,ns 2 ,ns 3 ,…,ns i -1 ,ns i ,ns i +1 ,…,ns n },ns i 中包含海量Web新闻实例的超链接,可描述为HyperLinkSet={hls i 1 ,hls i 2 ,hls i 3 ,…,hls i ( j -1) ,hls ij ,hls i ( j +1) ,…,hls im }。其中,hls ij 表示ns i 中第 j 个超链接,参数 i 的取值范围为1至 n ,参数 j 的取值范围为1至 m 。
定义2.2:UrlSet是一个Web新闻的集合,该集合是Web新闻信息提取的数据源,它包含具有权威性的Web新闻网中的海量Web新闻实例。
UrlSet={us 1 ,us 2 ,us 3 ,…,us i -1 ,us i ,us i +1 ,…,us n }。其中,参数 i 的取值范围为1至 n 。若某个Web新闻实例发布在Page i 网页中,则us i 能被表示为<url i ,title i ,pubtime i ,pubsource i ,content i >。其中,url i 表示Page i 的网址;title i 表示Web新闻标题;pubtime i 表示Web新闻发布时间;pubsource i 表示Web新闻发布来源;content i 表示Web新闻正文文本。
定义2.3:TopKeyWordSet是一个Web新闻的主题集合,该集合是Web新闻信息提取的主题,它包含所发生的社会事件中的关键词。
TopKeyWordSet={tkws 1 ,tkws 2 ,tkws 3 ,…,tkws i -1 ,tkws i ,tkws i +1 ,…,tkws n }。其中,参数 i 的取值范围为1至 n 。tkws i .wordvalue中存储了主题关键词,tkws i .weightvalue中存储了主题关键词权值。
定义2.4:InitialUrlQueue是一个存放Web新闻URL的初始队列,WaitingUrlQueue是一个存放Web新闻URL的待处理队列。
InitialUrlQueue={iuq 1 ,iuq 2 ,iuq 3 ,…,iuq i -1 ,iuq i ,iuq i +1 ,…,iuq n },WaitingUrlQueue={wuq 1 ,wuq 2 ,wuq 3 ,…,wuq i -1 ,wuq i ,wuq i +1 ,…,wuq n }。其中,参数 i 的取值范围为1至 n 。
定义2.5:Pattern是一个过滤模式,它可对子层的Web新闻URL进行过滤。BasePattern是一个基过滤模式,它可对兄弟层的Web新闻URL进行过滤。
对应于从UrlSet集合中提取出的顶层链接组,即 U ={ u 1 , u 2 ,…, u n },可将有效的子层链接组表示为UV={uv 1 ,uv 2 ,…,uv n },可将无效的子层链接组表示为UN={un 1 ,un 2 ,…,un n }。若存在过滤模式Pattern,则可将UV和UN检测出来,并过滤掉UN。对应于从顶层链接组过滤出来的有效的子层链接组,若存在过滤模式BasePattern∈uv i ( i =1,2,…, n ),并且不存在其子模式属于BasePattern或uv i 的情况,则称BasePattern为子层链接组的基过滤模式。
FiveTuple可描述Web新闻实例中所蕴含的五元组语义描述信息,基于大数据五元组语义描述分析的话题检测关键技术需要解决的问题如下。从海量的Web新闻中提取出与主题相似的实例,并从这些实例中检测出从父层到子层的过滤模式和兄弟层中的基过滤模式,以将交错复杂的URL网络系统从图结构转变为树状结构。其结果可被描述为TopWebNews={twn 1 ,twn 2 ,twn 3 ,…,twn i -1 ,twn i ,twn i +1 ,…,twn k }。其中,参数 i 的取值范围为1至 k 。twn i .url存储了Web新闻的网址,twn i .title存储了Web新闻标题,twn i .pubtime存储了Web新闻发布时间,twn i .pubsource存储了Web新闻发布来源,twn i .content存储了Web新闻正文文本,twn i .dividedtitle存储了Web新闻标题的分词结果,twn i .dividedcontent存储了Web新闻正文文本的分词结果,twn i .contentkeyword存储了Web新闻内容中的关键词,twn i .relativityvalue存储了Web新闻内容与主题的相似度,twn i .parenturl存储了Web新闻实例父层节点的地址,twn i .pattern存储了Web新闻实例过滤模式的描述,twn i .systemtime存储了Web新闻实例被提取的系统时间。从海量的Web新闻实例中分析出其关键的语义特征信息,结果可被描述为FiveTuple={ft 1 ,ft 2 ,ft 3 ,…,ft i -1 ,ft i ,ft i +1 ,…,ft k }。其中,参数 i 的取值范围为1至 k 。ft i =<Time, Place, Object, CoreEvent, RelationEvent>,ft i .Time表示Web新闻核心事件发生时间,ft i .Place表示Web新闻核心事件发生地点,ft i .Object表示Web新闻核心事件发起对象,ft i .CoreEvent表示Web新闻核心事件信息,ft i .RelationEvent表示与Web新闻核心事件相关联的事件信息,RelationEvent.preamble表示衍生出核心事件的前导事件信息,RelationEvent.derivative表示由核心事件衍生的事件信息。
要解决上述问题,首先应在海量的Web新闻中提取出与主题相似的Web新闻实例。但在未知哪些Web新闻实例归属于哪些主题的情况下,若逐例去筛选,则必将增加计算复杂度。其次应对主题下的Web新闻实例进行五元组语义描述分析,但在未知哪些Web新闻实例归属于哪些主题的情况下,若进行全局范围内的分析,则必将增加计算复杂度。因此,需要解决的问题体现了非确定性。若待提取的Web新闻实例集合为{ns 1 ,ns 2 ,ns 3 ,…,ns i -1 ,ns i ,ns i +1 ,…,ns n },则可将其中每个Web新闻实例都视为集合中的一个节点。若在提取与分析对象的路径中设计提取归约,则可缩短提取路径,缩小对象分析的范围。在每个Web新闻实例URL都能唯一地匹配Web新闻实例集合中节点ns i 的情况下,不存在多项式时间复杂度的算法可解决提出的问题。