
下载掌阅APP,畅读海量书库
立即打开



数据集中趋势 [2] (Central Tendency)描述是寻找反映事物特征的数据集合的代表值或中心值,这个代表值或中心值可以很好地反映事物目前所处的位置和发展水平,通过对事物集中趋势指标的多次测量和比较,还能够说明事物的发展和变化趋势。国家的人均GDP就是一个集中趋势指标,虽然每个人对国家的GDP贡献度不一样,但是人均GDP能够代表每个人对国家GDP的平均贡献度,从而反映一个国家的经济发展水平。下面介绍几种常用的表示数据集中趋势的度量。
1.算术平均值
算术平均值(Arithmetic Mean)是最常用的数据集中趋势指标,就是数据集合中所有数值的和除以数值个数,定义如下:

算术平均值是应用最广泛的数据集中趋势指标,受样本数据波动的影响最小,具有一定的稳定性,但是也有明显的缺陷:当数据集合中有极大值或极小值存在时,会对算术平均值产生很大的影响,其计算结果会掩盖数据集合的真实特征,这时算术平均值就失去了代表性。例如,统计全班同学的成绩平均值,班里几个同学未能参加考试,成绩为0分,这几个0分会拉低全班同学的平均成绩。因此,需要引入更多描述数据集中趋势的度量方法。
2.众数
数据集合中出现次数最多的数值被称为众数(Mode),当某个数值的数据较大并且集中趋势比较明显时,众数更适合作为描述数据代表性水平的度量。众数对定类数据、定序数据、定距数据和定比数据都适用,都能表示由它们组成的数据集合的数据集中趋势。
一个数据集合中,可能有一个或多个众数,也可能没有众数。如果在一个数据集合中,只有一个数值出现的次数最多,那么这个数值就是该数据集合的众数;如果有两个或多个数值出现的次数并列最多,那么这两个或多个数值都是该数据集合的众数;如果数据集合中所有数值出现的次数相同,那么该数据集合没有众数。例如,鞋厂生产鞋子,不能按照所有人的平均尺寸作为生产尺寸,更好的方式是按照众数作为生产尺寸,这样可以满足大多数人的需求。众数的应用场景很多,如饮料企业关心哪种“口味”的饮料销量最高、超市老板关心哪种“商品”的销量最多等。
3.中位数
中位数(Median)就是数据序列中排在最中间的数据。对于数据集合( x 1 , x 2 ,…, x n ),将所有数值按照它们的大小,从高到低或从低到高进行排序,如果数据集合包含的数值个数是奇数,那么排在最中间的数值就是该数据集合的中位数;如果数据集合包含的数值个数是偶数,那么取最中间两个数值的算术平均值作为中位数。
与算术平均值相比,中位数的优势在于不受数据集合中个别极端值的影响,能表现出稳定的特点。这一特点使其在数据集合的数值分布有较大偏斜时,能够保持数据集合特征的代表性,因此,中位数常被用来度量具有偏斜性质的数据集合的集中趋势。
4. k 百分位数
在一组数据从小到大排序,并计算相应的累计百分比时,处于 k %位置的值称为 k 百分位数(Percentile)。 k 百分位数是这样一个值,它使得至少有 k %的数据项小于或等于这个值,且至少有(100- k )%的数据项大于或等于这个值。前面介绍的中位数就是50百分位数。
求 k 百分位数的步骤如下。
第1步:以递增顺序排列原始数据(从小到大排列)。
第2步:计算指数 i =1+( n -1)× k %( n 是数据个数)。
第3步: i 是数据序列中 k 百分位数据的位置。
k 百分位数是用于衡量数据位置的量度,但它所衡量的不一定是中心位置。 k 百分位数提供了有关各数据项如何在最小值与最大值之间分布的信息。
【例2-1】有一组数据:3,13,7,5,21,23,39,23,40,23,14,12,56,23,29,求这组数据的50百分位数(也就是中位数)。
①排序后为3,5,7,12,13,14,21,23,23,23,23,29,39,40,56。
②计算50百分位数的位置:
1+(15-1)×50%=8
第8个数据(23)是50百分位数的位置。
程序实现:用Python计算数列的百分位数。

运行结果:

数据离散程度(Dispersion)的度量是指在一个数据集合中,各个数据偏离中心点的程度,是对数据间的差异状况进行的描述分析。
1.极差
极差(Range)是指在某个数值属性上的最大值和最小值之差。例如,例2-1中数列的最大值和最小值之差是56-3=53,53为这个属性值上的极差。
极差能体现一组数据波动的范围。极差越大,离散程度越大;但是极差未能利用全部测量值的信息,不能细致地反映测量值彼此相符合的程度,易受极端值的影响。
2.四分位极差
前面学习过的50百分位数(中位数)是指用中位数(IQR)把数据分布分成高低两半。这里的四分位数指的是有三个分位点把数据分布分成四个相等的部分。第一个分位点是25百分位数,记作 Q 1 ;第二个分位点是50百分位数,记作 Q 2 ;第三个分位点是75百分位数,记作 Q 3 。
四分位极差记作IQR,IQR= Q 3 - Q 1 。
经验公式:超过 Q 3 +1.5×IQR或者低于 Q 1 -1.5×IQR的数据,可能是离群点。
【例2-2】已知例2-1中的15个数:3,5,7,12,13,14,21,23,23,23,23,29,39,40,56,求IQR。
25百分位位置是4,25百分位数 Q 1 =12。
75百分位位置是12,75百分位数 Q 3 =29。
IQR=29-12=17.
根据经验公式计算可得离群点是56。
3.五数概括与箱图
因为 Q 1 、 Q 2 (Median)和 Q 3 并不包含数据序列的两个端点信息,因此,为了数据分布形状更完整地概括,可以同时给出两个端点信息,也就是最小值(Minimum)和最大值(Maximum),称为五数概括。分布的五数概括包括:内限内最小值、 Q 1 、中位数、 Q 3 和内限内最大值。
一般在五数箱图中内限内最小值不小于 Q 1 -1.5×IQR,内限内最大值不大于 Q 3 +1.5×IRQ。在内限内最小值到内限内最大值范围以外的数据称为离群点。
【例2-3】已知例2-1中的15个数:3,5,7,12,13,14,21,23,23,23,23,29,39,40,56,使用箱图来直观展示五数概括,如图2-2所示。
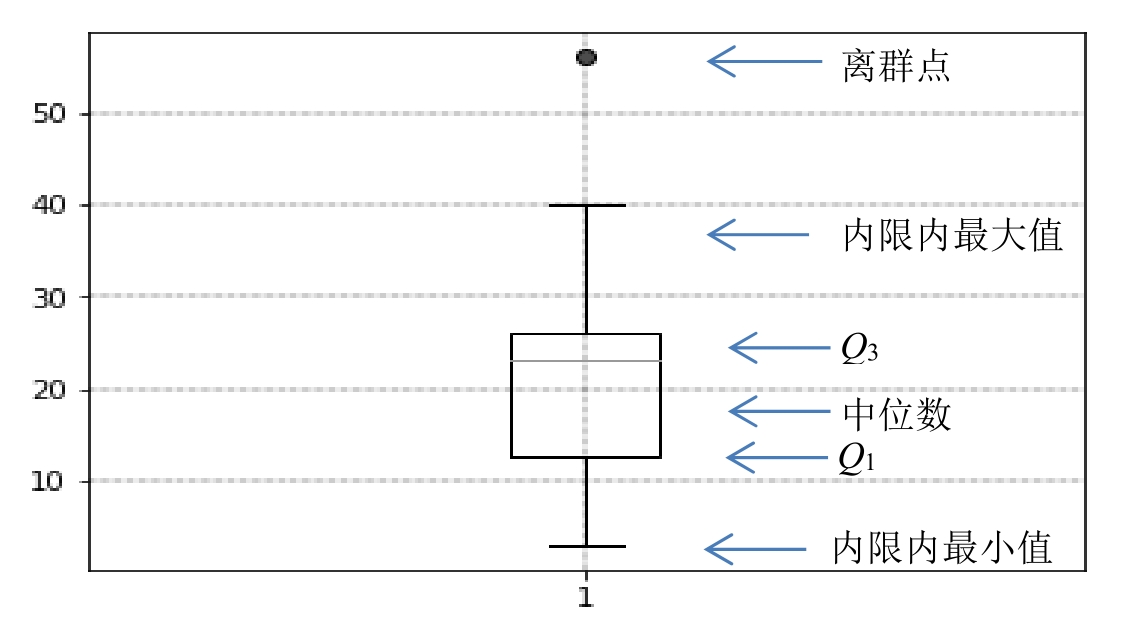
图2-2 箱图
此例中内限内最大值是40,内限内最小值是3,离群点是56。
程序实现:

4.方差和标准差
方差和标准差都是数据散布度量,它们指出了数据分布的散布程度。
方差 σ 2 的计算公式如下:

标准差 σ 是 σ 2 的开方。
方差大表示观测的数据两极分化大,方差小表示观测的数据比较靠近平均值。例如,两个班级中,A班级的成绩方差大,B班级学生的学习的成绩方差小,则说明A班级学生的学习成绩比较离散,适合分层教学;B班级学生的学习成绩比较集中,不适合分层教学。
方差和标准差适用于衡量相同量纲的数据集合或者样本相同属性之间的离散程度,如同年级不同班级成绩的比较、同年龄阶段男孩和女孩身高的比较等。但对于不同量纲和对象的不同属性之间的方差统计是没有意义的。离散系数可以解决这个问题。
5.离散系数
离散系数又称变异系数,是统计学中的指标。离散系数是度量数据离散程度的相对统计量,主要用于比较不同样本数据的离散程度。当进行两个或多个数据集合离散程度的比较时,在平均值相当的情况下,可以用标准差来判断离散程度;但是在平均值相差很大的情况下,用离散系数判断离散程度。
离散系数用符号 C v 表示,计算公式如下:

式中,
σ
是样本标准差;
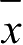 是样本平均值。
是样本平均值。
离散系数大,说明数据的离散程度大;离散系数小,说明数据的离散程度小。
【例2-4】甲、乙两名运动员都是中等水平,各连续打靶8次,请问哪名运动员发挥稳定?
甲、乙两名运动员连续打靶8次的记录按照先后顺序排列如下:
甲运动员:[8,9,8,9,9,8,10,10]
乙运动员:[10,6,8,10,8,9,9,10]
通过计算,得到了甲、乙两名运动员的平均值、标准差和离散系数,如表2-2所示。
表2-2 甲、乙两名运动员的平均值、标准差和离散系数

通过统计结果可以看到,甲、乙两名运动员的平均值相当,但是甲运动员的标准差和离散系数都比乙运动员的小,说明甲运动员的成绩更稳定。在平均值相当的情况下,标准差也可以比较两组数据的离散程度。
【例2-5】统计同一班级中15名高中生和同一班级中15名小学生的体重,数据如下:
高中生:[60,68,51,58,56,50,67,70,60,54,45,67,65,63,71]
小学生:[40,33,30,29,28,45,34,36,41,39,38,36,36,37,30]
通过计算,得到了高中生和小学生体重的平均值、标准差和离散系数,如表2-3所示。
表2-3 高中生和小学生体重的平均值、标准差和离散系数

续表

从这个统计数据结果可以看到,高中生体重和小学生体重的平均值相差很大,标准差不能作为比较高中生体重和小学生体重离散性的衡量参数。这时用离散系数来作为衡量参数是比较合理的,通过比较,说明小学生体重离散性更大些。
程序实现:

1.标称数据的卡方检验
对于离散数据,我们可以使用卡方检验来做类似计算。假设两个属性分别为 A 和 B ,卡方检验用符号 χ 2 表示,计算公式如下:
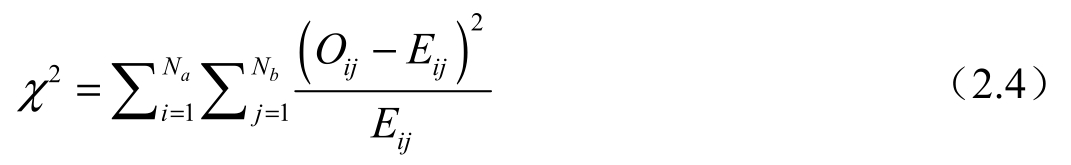
式中, O ij 表示 A 和 B 属性的配对值( A i , B j )的实际观测值; E ij 表示 A 和 B 属性的配对值( A i , B j )的理论值,卡方检验说明了理论值和实际观测值的偏差程度。卡方值越大,偏差越大;卡方值越小,偏差越小;卡方值为0,则理论值和实际观测值完全符合。
【例2-6】我们要观察性别和网上购物有没有关系。对987名顾客进行调查,结果如表2-4所示。那么,怎么判断线上买不买生鲜与性别有没有关联呢?
表2-4 性别与网上购物关系表

表2-4中数据是实际观测值,通过这个值,我们发现
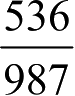 的人不在线上买生鲜,
的人不在线上买生鲜,
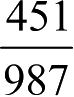 的人会在线上买生鲜,按照这个比例,我们可以算出(男,线上不买生鲜)的理论值是
的人会在线上买生鲜,按照这个比例,我们可以算出(男,线上不买生鲜)的理论值是
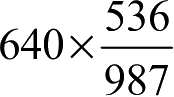 ,依次算出(男,线上买生鲜)、(女,线上不买生鲜)、(女,线上买生鲜)的理论值,我们还可以得到理论值,如表2-5所示。
,依次算出(男,线上买生鲜)、(女,线上不买生鲜)、(女,线上买生鲜)的理论值,我们还可以得到理论值,如表2-5所示。
表2-5 数据统计表

判断线上买不买生鲜与性别相关性的步骤如下。
(1)求出卡方值。
根据前面得到的实际观测值和理论值,可得:
χ 2 =(434-348) 2 /348+(102-188) 2 /188+(206-292) 2 /292+(245-159) 2 /159≈132.44
(2)求自由度,即(行数-1)×(列数-1)=(2-1)×(2-1)=1。
(3)此例置信度确定为90%,查找卡方分布表获得置信度为90%的卡方值是2.706,因为132.44远远大于2.706,所以,性别和线上购买生鲜两者之间是强关联的。
程序实现:

运行结果:


2.数值数据的协方差
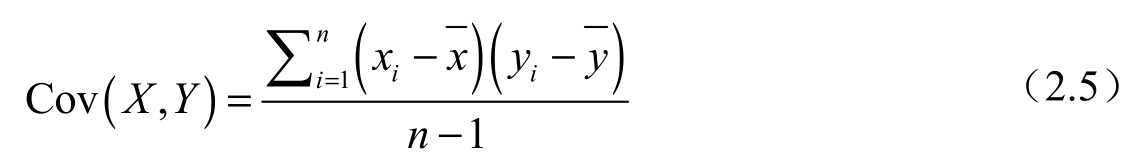
式中,
X
和
Y
为两个不同的属性集;
X
i
和
Y
i
分别是
X
和
Y
属性对应的属性值;
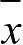 和
和
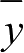 分别是
X
和
Y
属性值的平均值。假设协方差结果为
C
,
C
的取值范围为-1≤
C
≤1。
分别是
X
和
Y
属性值的平均值。假设协方差结果为
C
,
C
的取值范围为-1≤
C
≤1。
若Cov( X , Y )>0,则表明属性 X 和属性 Y 之间存在正线性相关关系,数据变化是同向的;若Cov( X , Y )<0,则表明属性 X 和属性 Y 之间存在负线性相关关系,数据变化是负向的;若Cov( X , Y )=0,则表明二者之间不存在线性相关关系,但并不排除存在非线性相关性。
因此,协方差的正负代表了两个属性之间相关性的方向,而协方差的绝对值代表了它们相互关系的强弱。
【例2-7】图2-3是商品销售量与温度数据散点图。
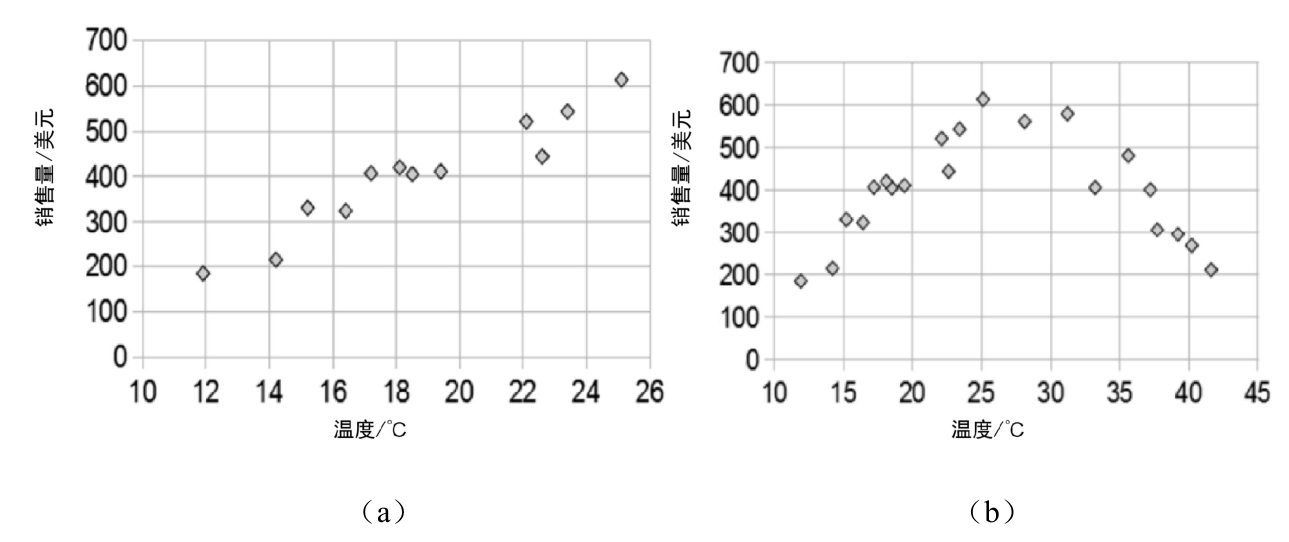
图2-3 商品销售量与温度数据散点图
在图2-3(a)中(销售量,温度)协方差是大于0的,说明这两个属性是正相关的。但是在图2-3(b)中(销售量,温度)协方差是等于0的,按照协方差规律,这两个属性是不相关的。显然根据数据分布情况,这两个属性是相关的,先是正相关,超过一定温度后呈现负相关,所以图2-3(b)显示的两个属性之间是存在非线性相关的,此时,用协方差结果来评判是不客观的。
所以,协方差只是针对线性相关有效,当协方差为0时有可能也存在非线性相关。
3.数值数据的相关系数
协方差的大小与属性的取值范围和量纲都有关系,造成不同的属性对之间的协方差难以进行横向比较。为了解决这个问题,把协方差归一化,就得到了样本相关系数,用 r ( X , Y )表示,计算如下:
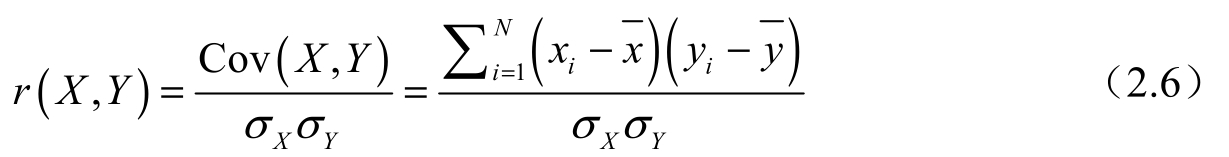
式中,
X
和
Y
为两个属性;
N
为元组的个数;
x
i
和
y
i
为第
i
个元组中
x
和
y
对应的值,
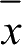 和
和
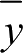 为它们的平均值;
σ
X
和
σ
Y
为
X
和
Y
的标准差。
为它们的平均值;
σ
X
和
σ
Y
为
X
和
Y
的标准差。
如果 r(X , Y )取值在-1与1之间,且 r(X , Y )>0,表示正相关,值越大,相关性越大。相反,如果 r(X , Y )<0,表示负相关。
【例2-8】冰淇淋销售量和温度的统计数据如图2-4中左侧的表格所示,图2-4右侧是数据分布散点图,用Python程序计算销售量和温度两个属性的协方差和相关系数。
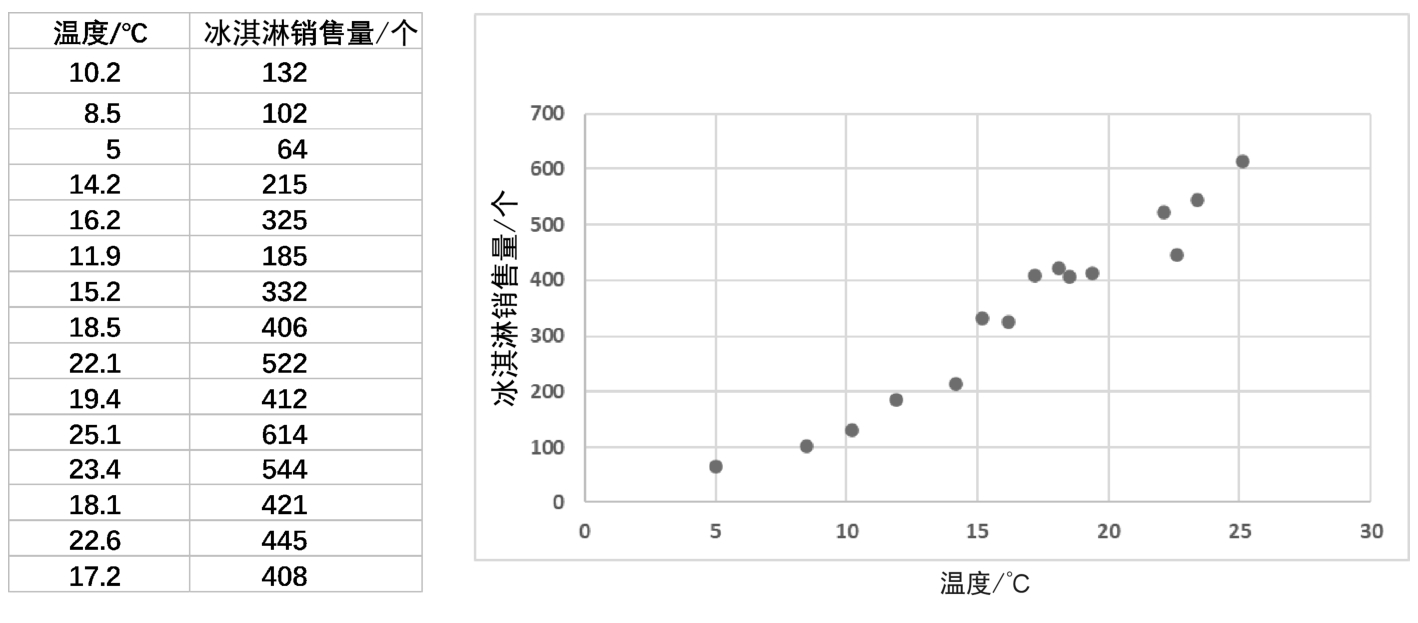
图2-4 冰淇淋销售量和温度的统计数据
程序实现:
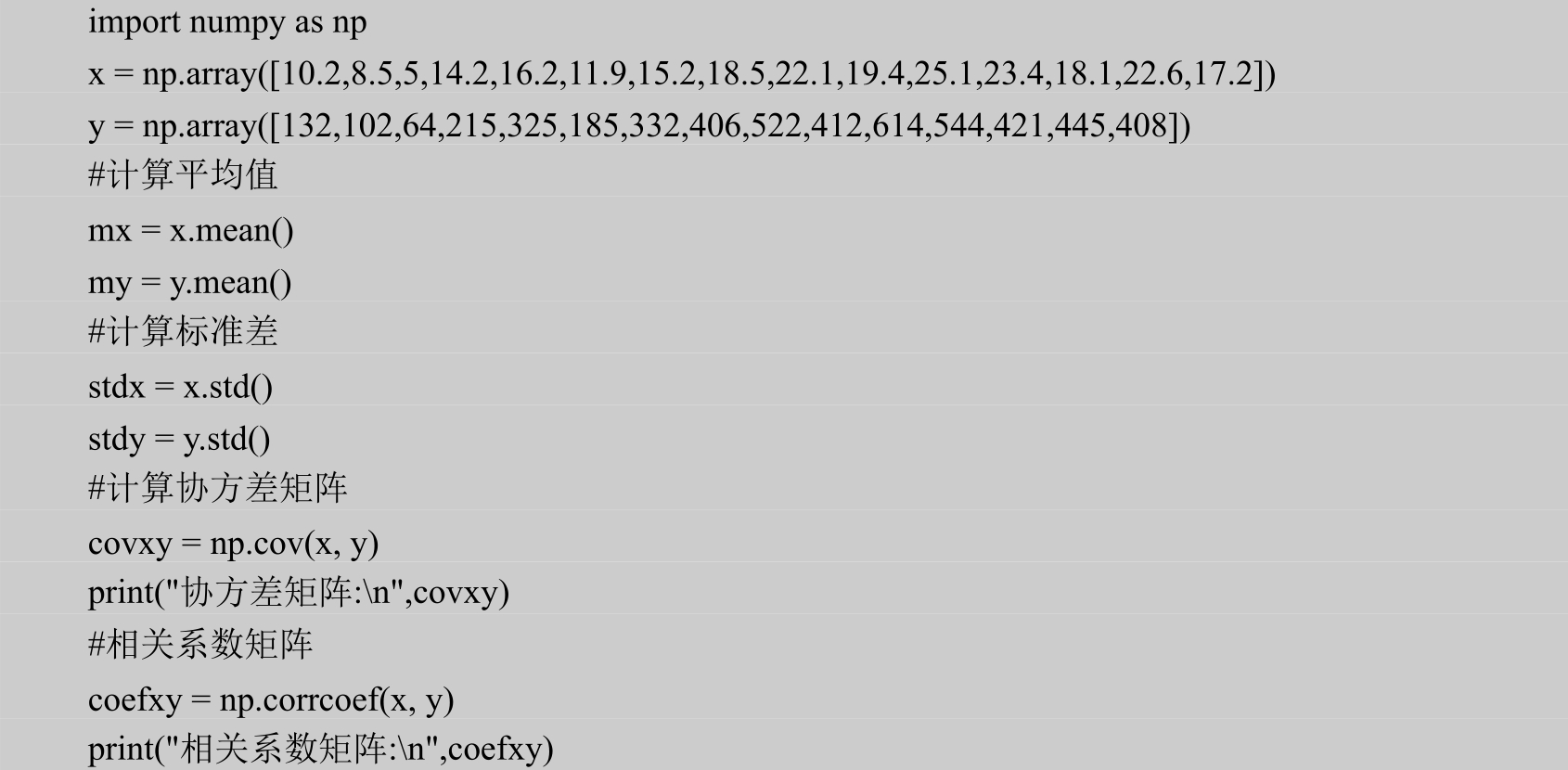
运行结果:


由运行结果显示,Cov( X , Y )=Cov( Y , X )≈953.2371, r(X , Y )= r(Y , X )≈0.9766,无论协方差还是相关系数,其值都是大于0的,说明温度和冰淇淋销售量两者之间存在正相关,但是相关系数是0.9766,是接近1的,更能说明温度和冰淇淋销售量两者之间是存在很强的正相关性的。读者也可以手动计算协方差和相关系数进行验证。