
下载掌阅APP,畅读海量书库
立即打开



InfluxDB的发展非常迅速,目前支持在各大主流操作系统中安装。最常见的操作系统有Linux、Windows和OS,其中Linux衍生出的RedHat & CentOS、Ubuntu & Debian都能安装InfluxDB,甚至很多嵌入式操作系统也可以安装。本章将讲解最新的InfluxDB 2.0.6版本在不同操作系统上的安装,安装InfluxDB之前,先大致了解一下InfluxDB对硬件资源的要求。
InfluxDB对硬件资源是有一些要求的,硬件资源直接影响InfluxDB的运行稳定性和性能。过于局限的资源,会导致InfluxDB不稳定,或者性能急剧下降。
如果只是为了学习InfluxDB,一台普通的办公计算机(内存为8GB、16GB都可以)就可以安装InfluxDB。但是在生产环境中使用,就必须注意以下一些问题了:
这里定义的InfluxDB的负载是基于每秒写入的数据量、每秒查询的次数以及唯一series的数量(series是一组数据的集合),如表2-1所示。
表2-1 InfluxDB的负载表
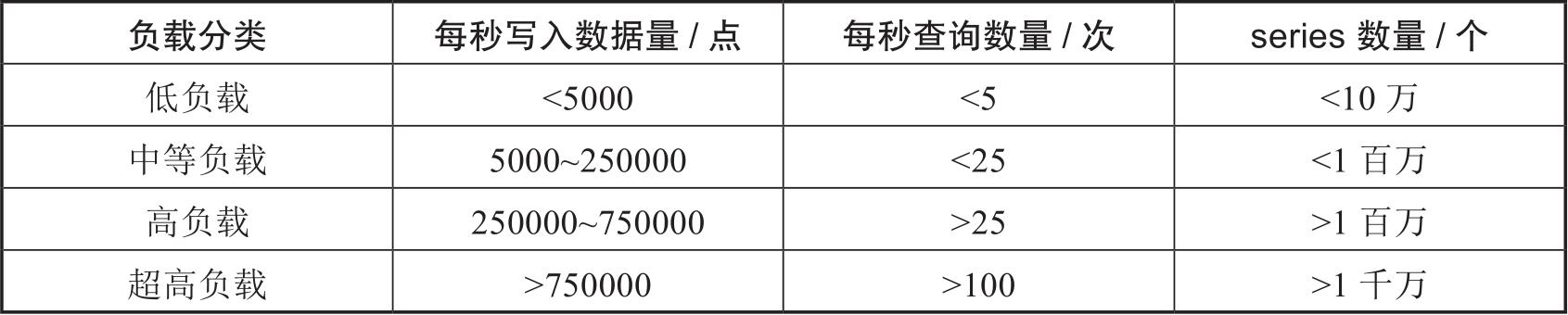
在实际选择硬件配置时,可以根据上面的指标来判断需要什么资源,下面分别说明不同的负载需要什么样的系统资源:
(1)低负载推荐的硬件配置。
低负载,也就是每秒写入数据量小于5000点:
● CPU:2~4核。
● 内存:2~4GB。
● IOPS:500。
(2)中等负载推荐的硬件配置。
中等负载,也就是每秒写入数据量小于25万点,大于5000点:
● CPU:4~6核。
● 内存:8~32GB。
● IOPS:500~1000。
(3)高负载推荐的硬件配置。
高负载,也就是每秒写入数据量大于25万点,小于75万点:
● CPU:8+核。
● 内存:32+GB。
● IOPS:1000+。
(4)超高负载的硬件配置。
要达到这个范围挑战很大,需要搭建大规模的集群,后文会对集群做相应的讨论。对于小项目,一般来说不使用集群,因为集群的维护成本较昂贵,使用单机就可以了。
deb是Debian系统中软件包格式,和Window中的exe一样,deb软件安装包的文件扩展名为.deb。和Debian的命名一样,deb也是因Debra Murdock(Debian创始人Ian Murdock的前妻)而得名。
首先需要在InfluxData网站(https://portal.influxdata.com/downloads/)下载最新的deb安装包,如图2-1所示。
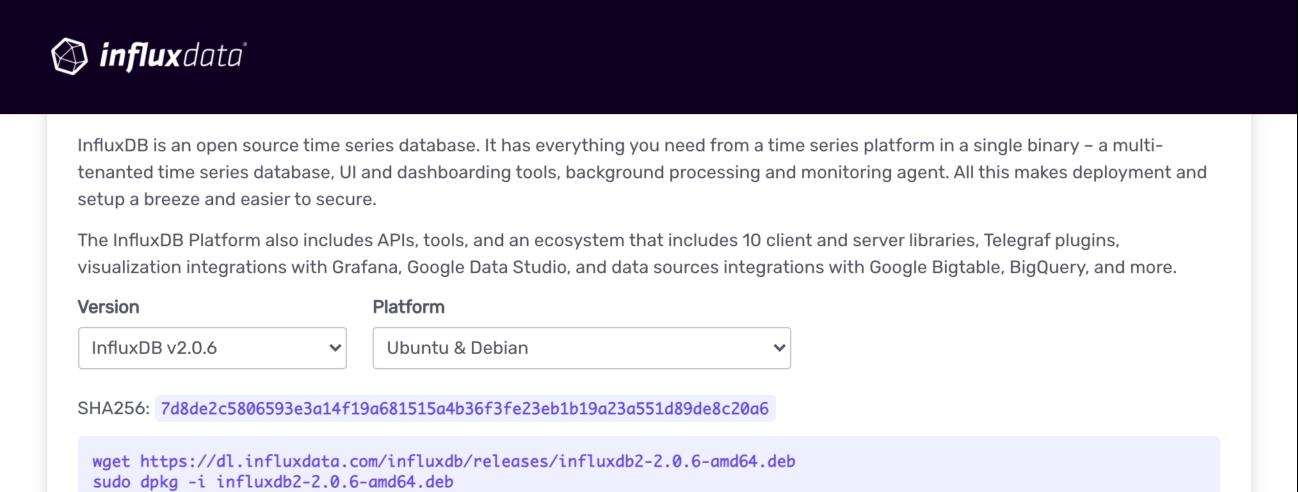
图2-1 InfluxDB下载界面
这里使用的是v2.0.6版本,Platform下拉列表框有其他系统的版本,如Ubuntu & Debian(ARM 64-bit)版本,这是为ARM处理器准备的版本。
下载v2.0.6的安装包,大小约104.58M,如代码清单2-1所示。
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.6-amd64.deb
然后可以使用dpkg命令进行安装。dpkg是Debian package的简写,是为Debian操作系统专门开发的软件包管理系统,用于软件的安装、更新和移除。dpkg的-i选项表示安装某个软件包的意思,-i是--install的缩写,安装命令如代码清单2-2所示。
安装好后,可以通过service服务来启动InfluxDB服务,如代码清单2-3所示。
sudo service influxdb start
服务启动后,可以通过sudo service influxdb status查看服务状态,如代码清单2-4所示。
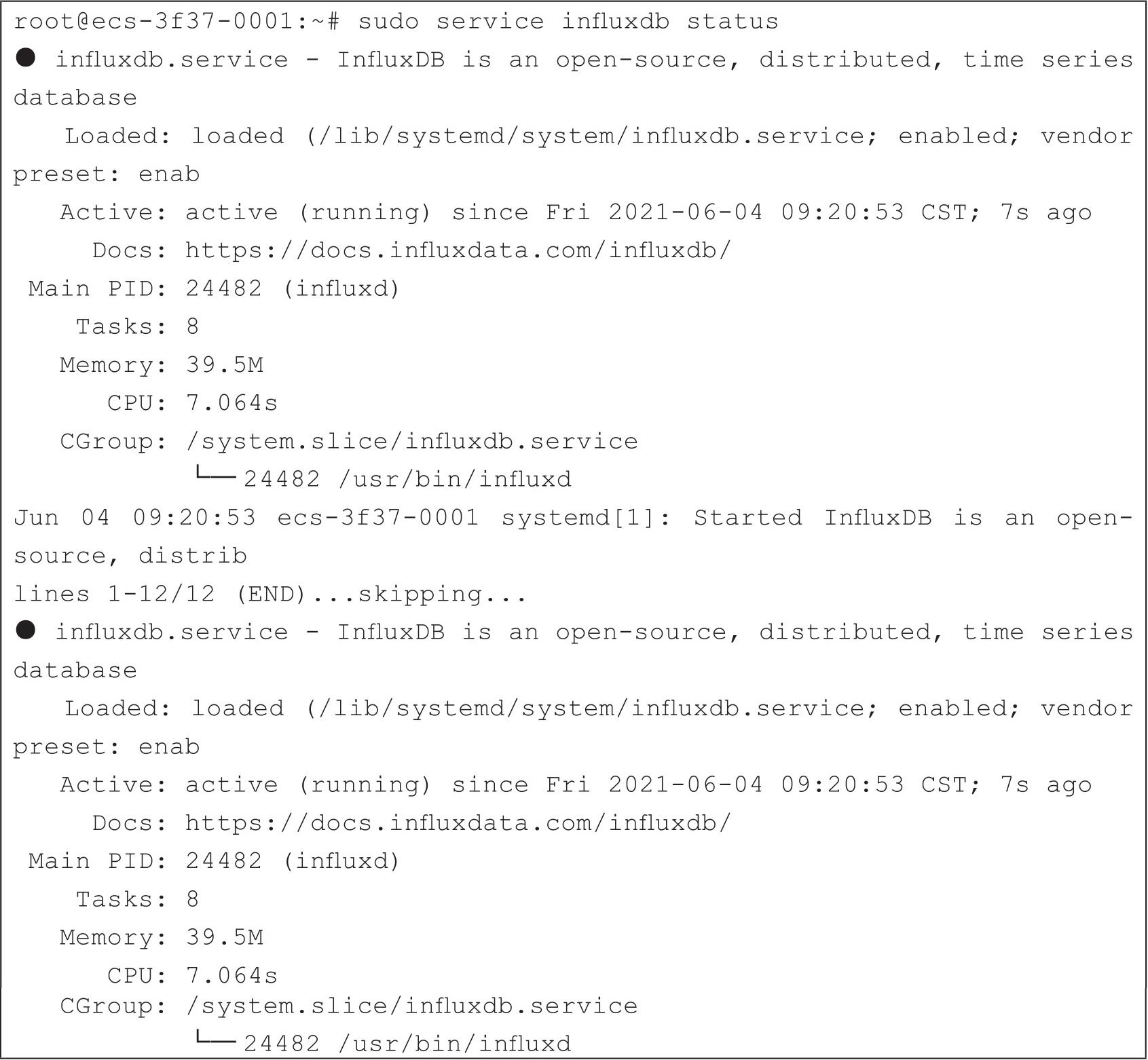
输出的内容中有Active:active (running),就表示服务启动成功了。通过telnet可以查询端口是否可以被访问,如代码清单2-5所示,如果能被访问,说明服务启动成功,如果不能被访问,说明启动失败。
root@ecs-3f37-0001:~# telnet 127.0.0.1 8086 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'.
如果启动失败,可以通过日志查询原因。
通过sudo service influxdb stop可以停用服务,如代码清单2-6所示。
sudo service influxdb stop
查看安装的InfluxDB信息如代码清单2-7所示。
root@ecs-3f37-0001:~# dpkg -l | grep influx ii influxdb2 2.0.6 amd64 Distributed time-series database.
其中influxdb2是软件包的名字,卸载的时候,需要使用到这个名字,如代码清单2-8所示。

这样就卸载成功了。
apt-get是Ubuntu & Debian的包管理器,是一款广受欢迎的命令行工具,可以用来安装一些组件和应用程序。使用apt-get命令安装最新InfluxDB的步骤如下:
(1)配置InfluxData软件仓库源。
(2)更新仓库。
(3)安装InfluxDB。
(4)启动InfluxDB。首先,需要将InfluxData软件仓库源添加到Ubuntu & Debian系统中,如果你使用的是Ubuntu系统,可以使用如代码清单2-9所示的方法在Ubuntu中添加软件源。

● https://repos.influxdata.com/influxdb.key:influxdb仓库的密钥文件。
● apt-key add -:把下载的key添加到本地信任(trusted)数据库中,表示apt(-?)get可以从这个源下载软件,下载的软件是可信的、没有病毒的、官方正版的。
● source /etc/lsb-release:刷新当前shell的环境变量,/etc/lsb-release是一个文本文件,里面存放的是一些系统相关的环境变量。
● ${DISTRIB_ID,,}:系统类型,这里是ubuntu。
● ${DISTRIB_CODENAME}:操作系统的开发代号,在笔者的操作系统中,这里是xenial。
代码最后一句是将下载地址添加到influxdb.list中。
这段脚本执行成功后,/etc/apt/sources.list.d/influxdb.list的内容如代码清单2-10所示。由于InfluxDB并不在Ubuntu的官方仓库中下载,/etc/apt/sources.list.d/influxdb.list文件表示将InfluxDB仓库添加到系统中。
deb https://repos.influxdata.com/ubuntu xenial stable
如果使用的是Debian系统,可以使用如代码清单2-11所示的方法添加软件源。

然后使用如代码清单2-12所示的方法更新仓库。
安装InfluxDB服务,如代码清单2-13所示。
安装完成后,通过service服务来启动InfluxDB服务,如代码清单2-14所示。
sudo service influxdb start
在RedHat & CentOS系统中,可以通过yum命令安装InfluxDB。为了让yum能找到最新的InfluxDB程序,需要将yum软件源添加到RedHat & CentOS系统中,如代码清单2-15所示。

在/etc/yum.repos.d目录中,查看influxdb.repo文件是否存在,如存在须查看influxdb.repo中的内容,是否为代码清单2-15所示内容,如果不是,则说明没有执行成功。
安装InfluxDB服务,如代码清单2-16所示。
sudo yum install influxdb
安装完成后,通过service服务来启动InfluxDB服务,如代码清单2-17所示。
sudo service influxdb start
RedHat和CentOS是同一家公司研发的,RedHat是CentOS的商业版本。rpm是RedHat & CentOS上的软件安装包,InfluxDB的rpm包下载地址如代码清单2-18所示。
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.6.x86_64. rpm
通过yum localinstall命令可以安装本地rpm软件包,如代码清单2-19所示。
sudo yum localinstall influxdb2-2.0.6.x86_64.rpm -y
安装完成后,可以通过service influxdb start命令启动服务,如代码清单2-20所示。
sudo service influxdb start
执行后显示代码清单2-21所示的内容。
Redirecting to /bin/systemctl start influxdb.service
也可以通过service influxdb stop命令,停止服务,如代码清单2-22所示。
sudo service influxdb stop
还可以通过service influxdb status命令,查看服务的状态,如代码清单2-23所示。
sudo service influxdb status
InfluxDB最好安装在Linux系统上,但是如果是Windows系统,用于学习目的,可以下载Windows版安装包,这里下载2.0.7版,如图2-2所示。下载地址是https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.6-windows-amd64.zip。

图2-2 InfluxDB Windows版下载界面
Windows版的InfluxDB是一个绿色包,直接解压即可,将InfluxDB解压到某个目录下,如图2-3所示。
图2-3 解压后的目录
influxd.exe是InfluxDB服务程序,在cmd命令行中执行该文件即可,如图2-4所示。
图2-4 influxd.exe运行效果
influx.exe是命令行工具,也需要在cmd命令行中启动。
在macOS系统中可以通过二进制包和brew包管理器来安装InfluxDB。
从InfluxDB官网(https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.6-darwin-amd64.tar.gz)下载influxdb2-2.0.6-darwin-amd64.tar.gz安装包,安装包大小约108M。
下载完成后,将文件复制到某个文件夹,文件夹路径最好不要带中文,然后解压,可以使用解压工具解压,或者通过命令解压,如代码清单2-24所示。
tar zxvf influxdb2-2.0.6-darwin-amd64.tar.gz
解压完成后的文件如图2-5所示。
图2-5 InfluxDB安装包解压后的效果
influxd是InfluxDB服务程序,在命令行执行该程序,可能会出现未验证程序无法启动的问题,需要到“安全性与隐私”界面去设置,单击“仍要打开”,程序即可正常打开,如图2-6所示。
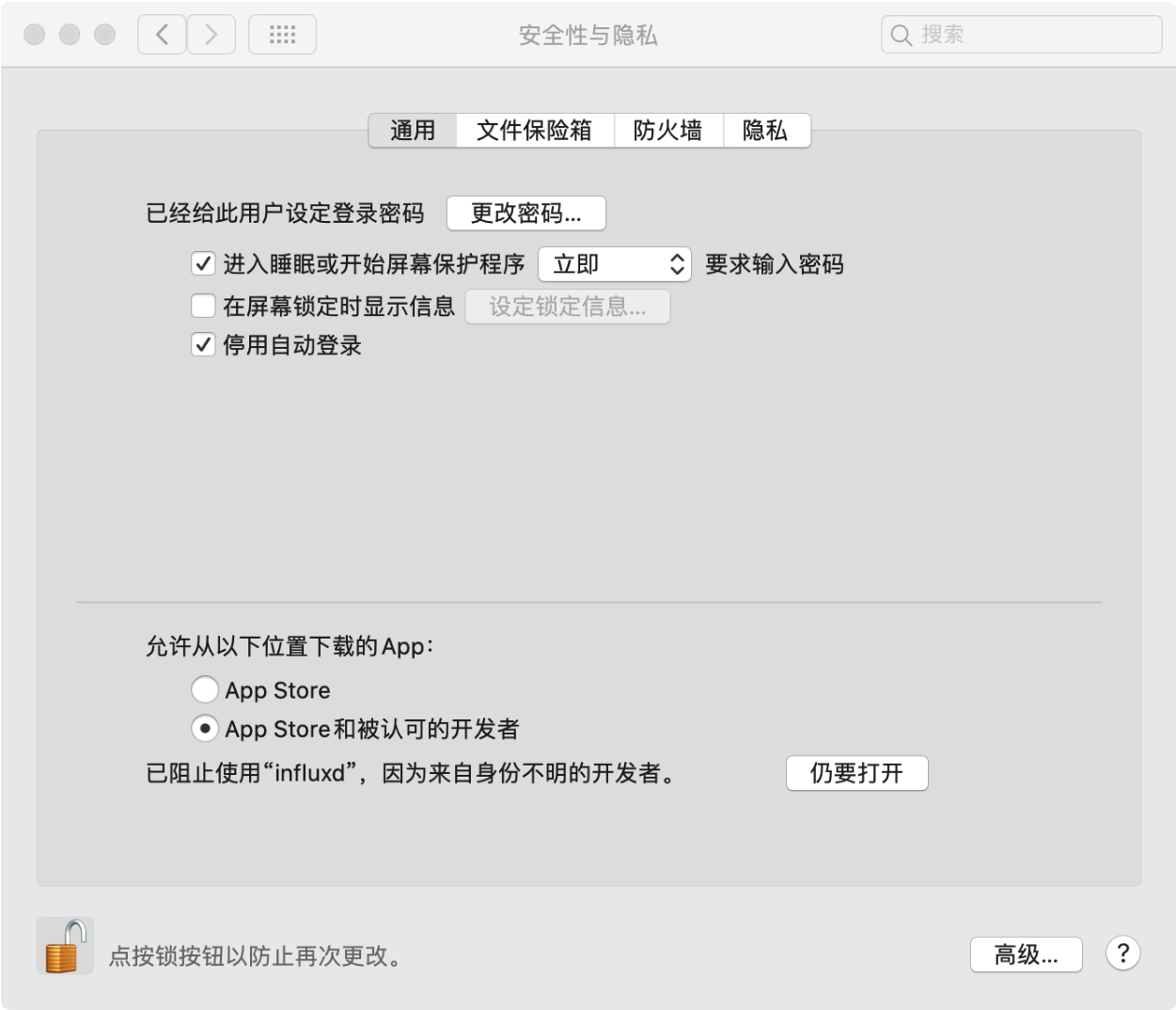
图2-6 influxd安全性设置
在弹出的提示中再次单击“打开”,即可确定该程序是安全的,如图2-7所示。
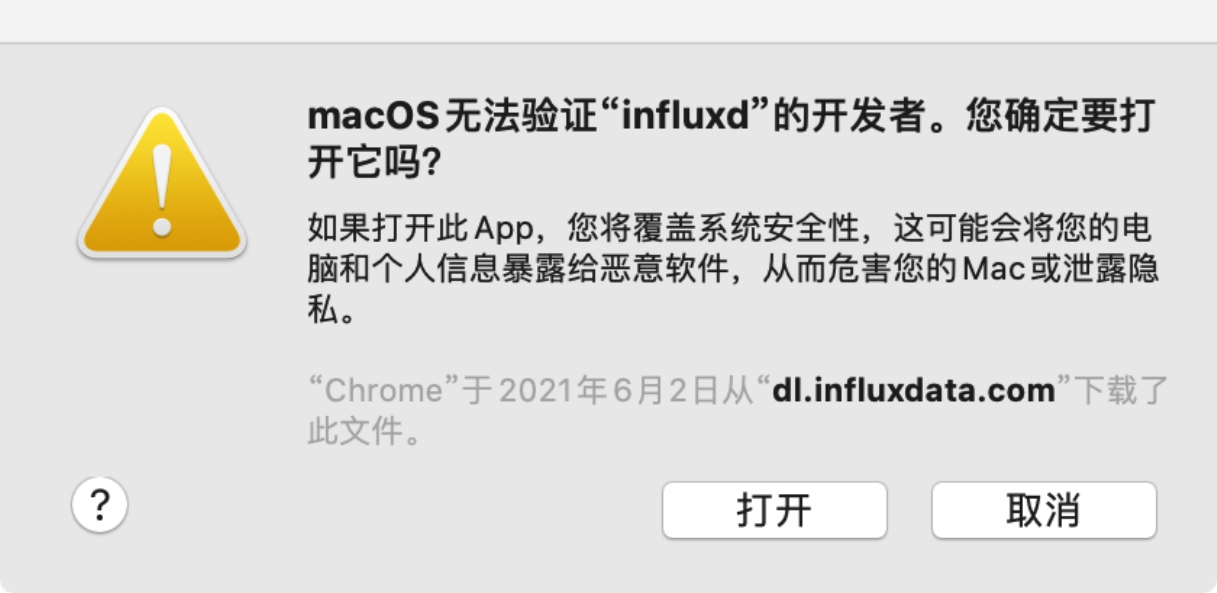
图2-7 influxd安全性验证
Homebrew是Mac的包管理器,仅需执行相应的命令,就能下载安装需要的软件包,省略了下载、解压、拖曳(安装)等烦琐的步骤。
通过brew命令安装InfluxDB,代码如代码清单2-25所示。
brew update brew install influxdb
● brew update:更新本地软件包索引。
● brew install influxdb:安装最新版的influxdb软件。
如果只想安装InfluxDB体验一下,可以使用Docker来安装,Docker的优势是简单易用,而且不会污染操作系统环境,就像Windows系统的绿色软件一样,不用写注册表。
第一步,安装Docker,操作非常简单,可以使用Iinux一键安装Docker脚本,如代码清单2-26所示。
wget http://hellodemos.com/download/script-litte-prince/app/install- docker.sh -O /root/install-docker.sh && sh /root/install-docker.sh
install-docker.sh是安装Docker的脚本,然后下载InfluxDB的Docker镜像,如代码清单2-27所示。
docker pull influxdb:2.0.6
这样InfluxDB就安装好了。
通过Docker命令运行InfluxDB,如代码清单2-28所示。
docker run -d -p 8083∶8083 -p 8086∶8086 --name my-influxdb influxdb
其中各个选项的含义如下。
● docker run:运行Docker镜像。
● -d:后台运行容器,并返回容器ID。
● -p 8083∶8083:将容器的8083端口映射到主机的8083端口。
● -p 8086∶8086:将容器的8086端口映射到主机的8086端口。
● --name my-influxdb:容器指定一个名称,为my-influxdb。
● influxdb:启动influxdb镜像。
启动成功后,可以通过telnet来查看端口是否启动成功。
InfluxDB通过端口和外部通信,默认使用以下2个端口。
● 8086:用于客户端和服务端交互的HTTP API端口。
● 8088:用于提供备份和恢复的RPC服务端口。
一般来说,为了让应用服务访问到InfluxDB,需要打开这2个端口。如果使用的是类似阿里云、华为云这样的云服务器,那么只需要在云服务器的安全组中进行设置,再打开这2个端口就可以了;如果是自己安装的服务器或者虚拟机,那么需要执行代码清单2-29所示的防火墙命令,再打开这2个端口。
sudo iptables -I INPUT 1 -p tcp --dport 8086 -j ACCEPT
InfluxDB软件包解压后,各个目录及文件如下。
● etc:配置主目录。
● etc/influxdb:配置文件目录。
● etc/influxdb/influxdb.conf:配置文件。
● etc/logrotate.d:管理日志文件夹。
● user:用户目录。
● usr/bin:可执行文件目录。
● usr/bin/influx:InfluxDB的命令行程序。
● usr/bin/influxd:InfluxDB的服务器程序。
● usr/bin/influx_inspect:探测程序。
● usr/bin/influx_stress:InfluxDB的压力测试程序。
接下来,对主要的几个可执行程序进行介绍。
influxd是一个守护进程,是InfluxDB的服务器程序,客户端就是和这个程序交互的。influxd完成了InfluxDB时序数据库的主要操作,数据库的增删改查都是influxd程序处理的。
一般来说,可以通过influxd程序直接启动InfluxDB,如代码清单2-30所示。
influxd
influxd程序可以带很多参数,使用influxd help可以查看influxd的帮助,如代码清单2-31所示。
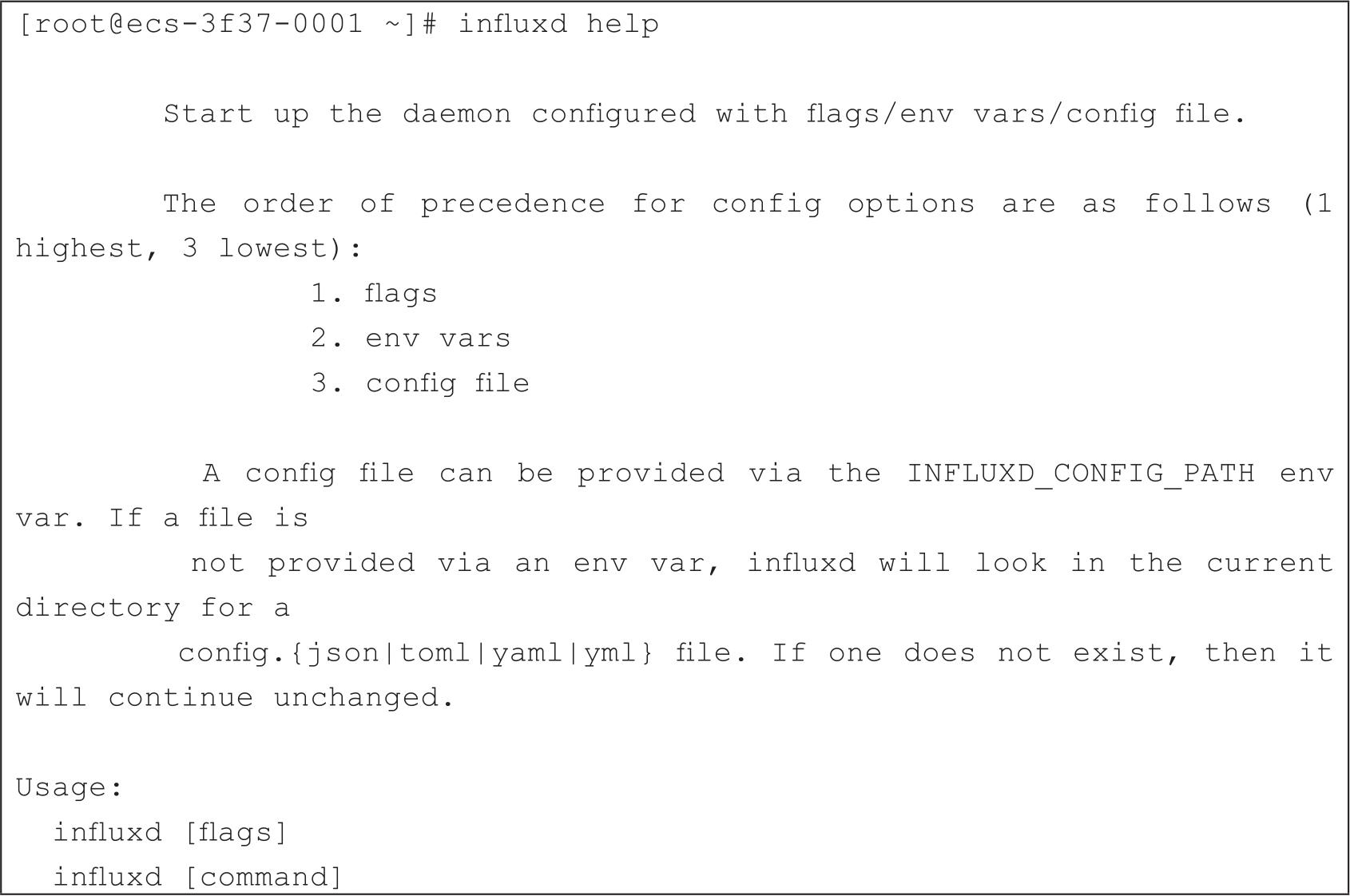
influxd是时序数据的主服务程序,可以接受很多配置信息,配置信息可以由3种方式传入,其优先级如下。
(1)flags:直接通过在influxd后添加flags来实现。
(2)env vars:通过环境变量来提供配置参数。
(3)config file:通过配置文件来提供配置参数。
config file配置文件的路径是通过环境变量INFLUXD_CONFIG_PATH提供的,如果没有通过环境变量提供配置文件,influxd程序会在当前目录查看配置文件config,config的后缀可以是.json、.toml、.yaml和.yml,这表示配置文件支持多种格式。
从帮助提示中,可以发现influxd支持两种语法,如代码清单2-32所示。
influxd [flags] influxd [command]
command表示influxd支持的命令,各个命令及作用见表2-2。
表2-2 influxd的command命令

直接在influxd后加入这些命令就可以了。查看版本信息的操作,如代码清单2-33所示。
[root@ecs-3f37-0001 ~]# influxd version InfluxDB 2.0.6 (git: 4db98b4c9a) build_date: 2021-04-29T16∶48∶12Z
使用print-config命令打印当前环境配置信息的操作,如代码清单2-34所示。

可以通过influxd inspect -h查看influxd inspect命令的具体使用方法,如代码清单2-35所示。
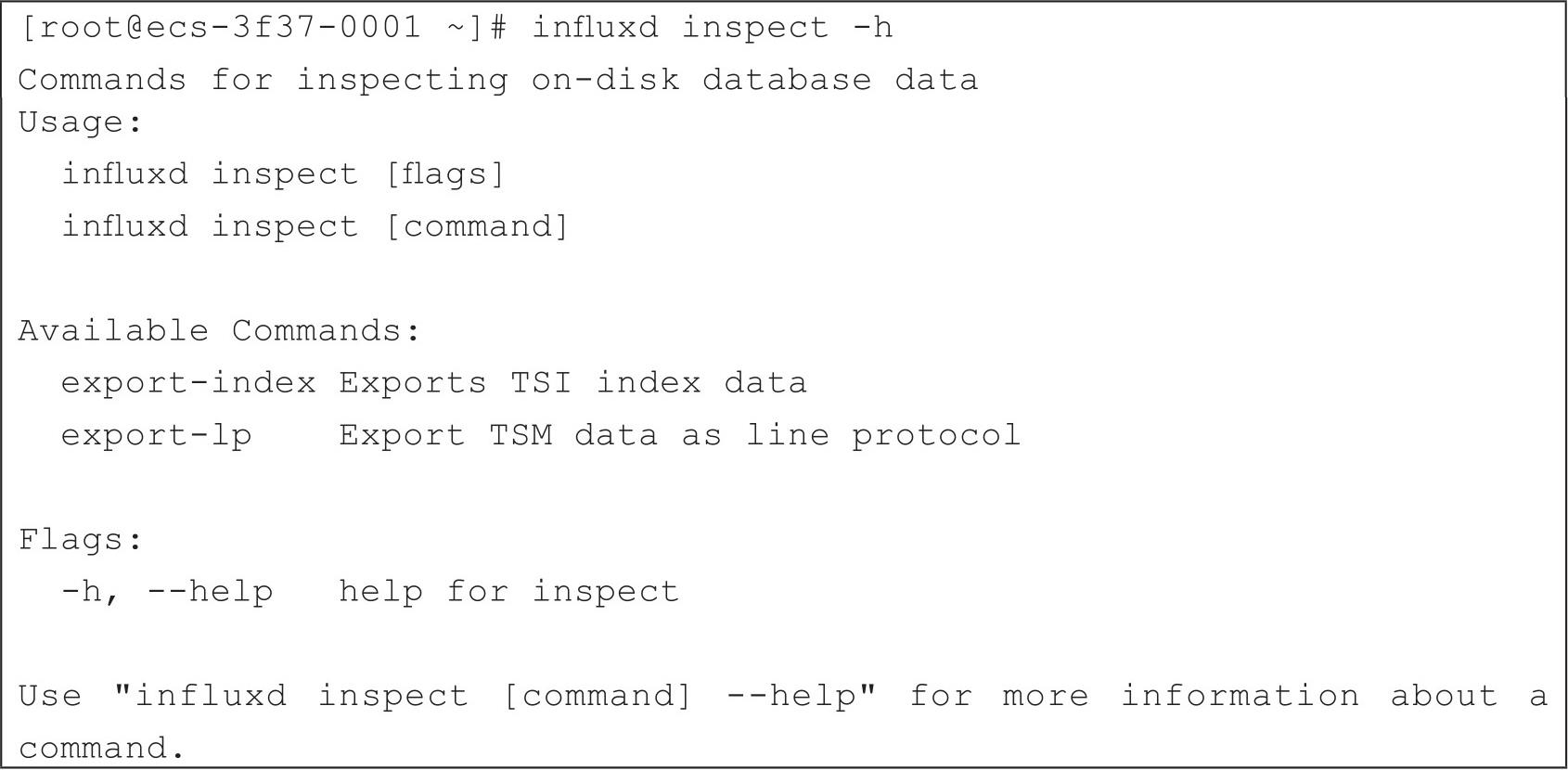
influxd inspect之后可接flags和command。flags一般是标记输出或设置一些信息,command一般是执行一些需要一定时间的任务。
这里的flags有两个参数-h和--help,表示获取帮助的意思。
command有两个参数export-index和export-lp,分别是导出TSI索引数据和TSM行协议数据。如需要进一步了解export-index怎么使用,可以使用influxd inspect export-index -h命令查看帮助,如代码清单2-36所示。

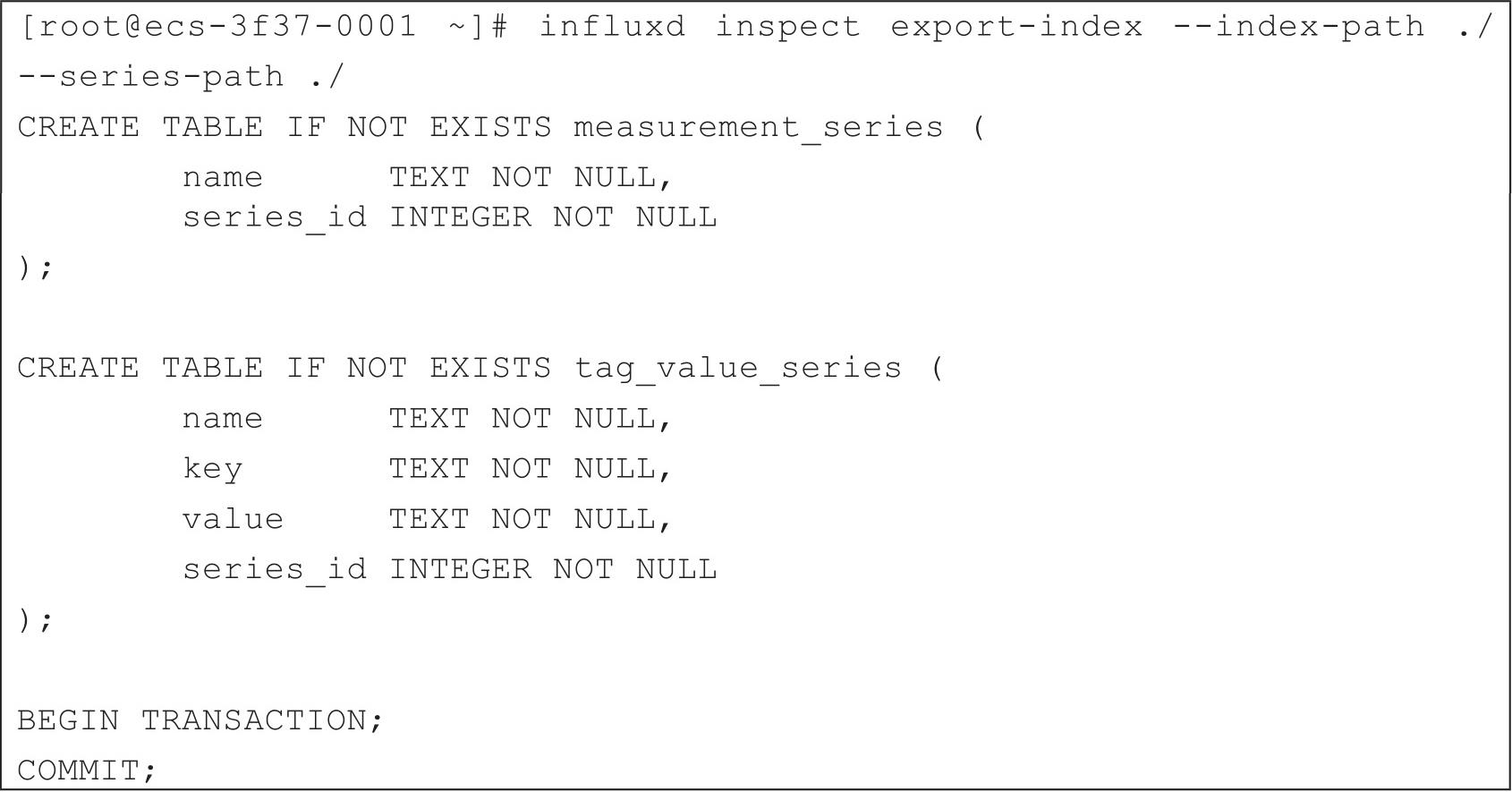
从帮助中可以看出influxd inspect export-index命令可以导出一个TSI索引文件到SQL文件中,便于查看和调试。可以使用influxd inspect export-index --index-path ./--series-path ./命令导出序列文件到当前目录中,如代码清单2-37所示。
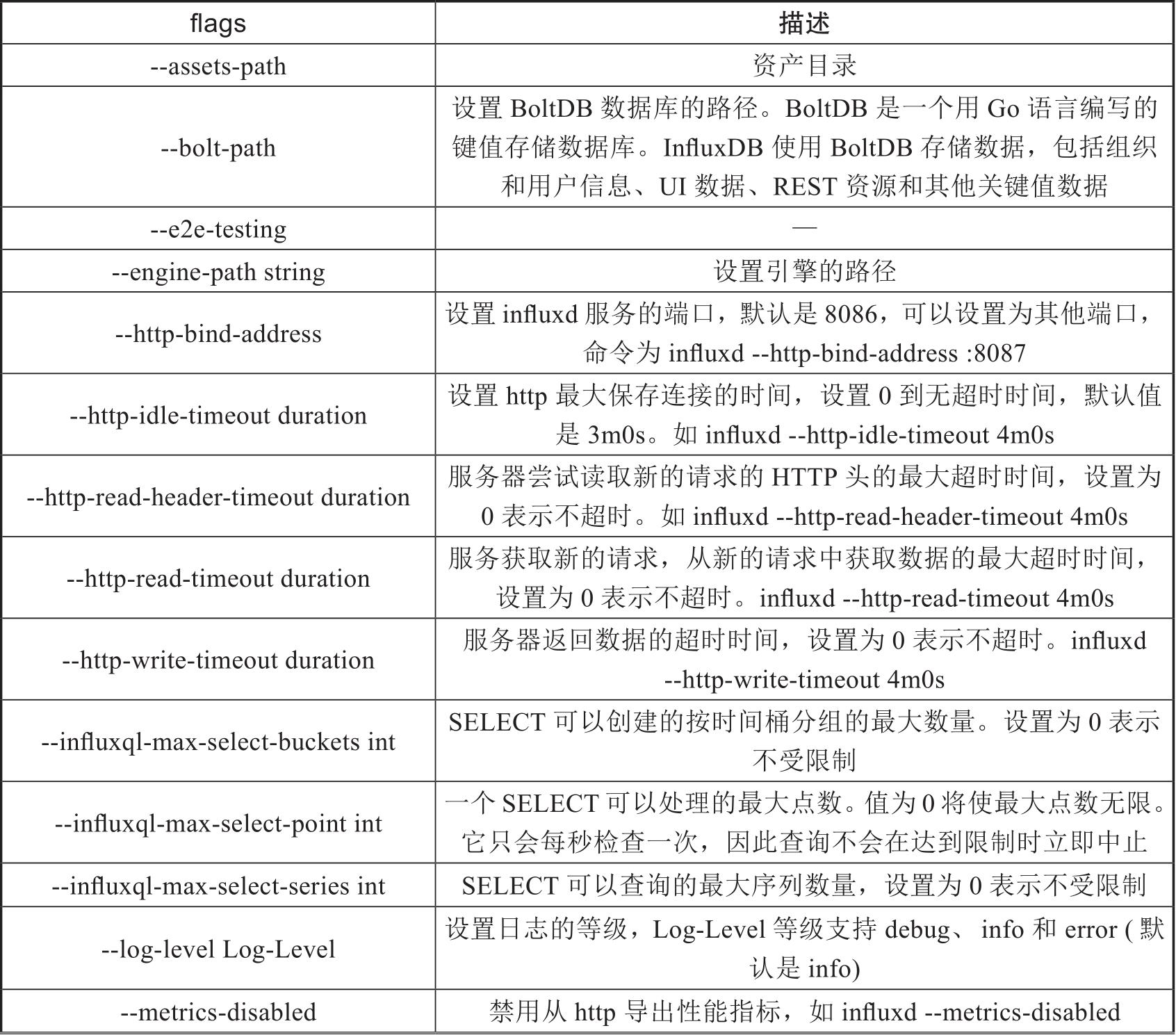
influxd的flags标志主要用于设置一些influxd的变量,flags的功能非常丰富,有多个变量,如表2-3所示。
表2-3 influxd的flags标志
续表
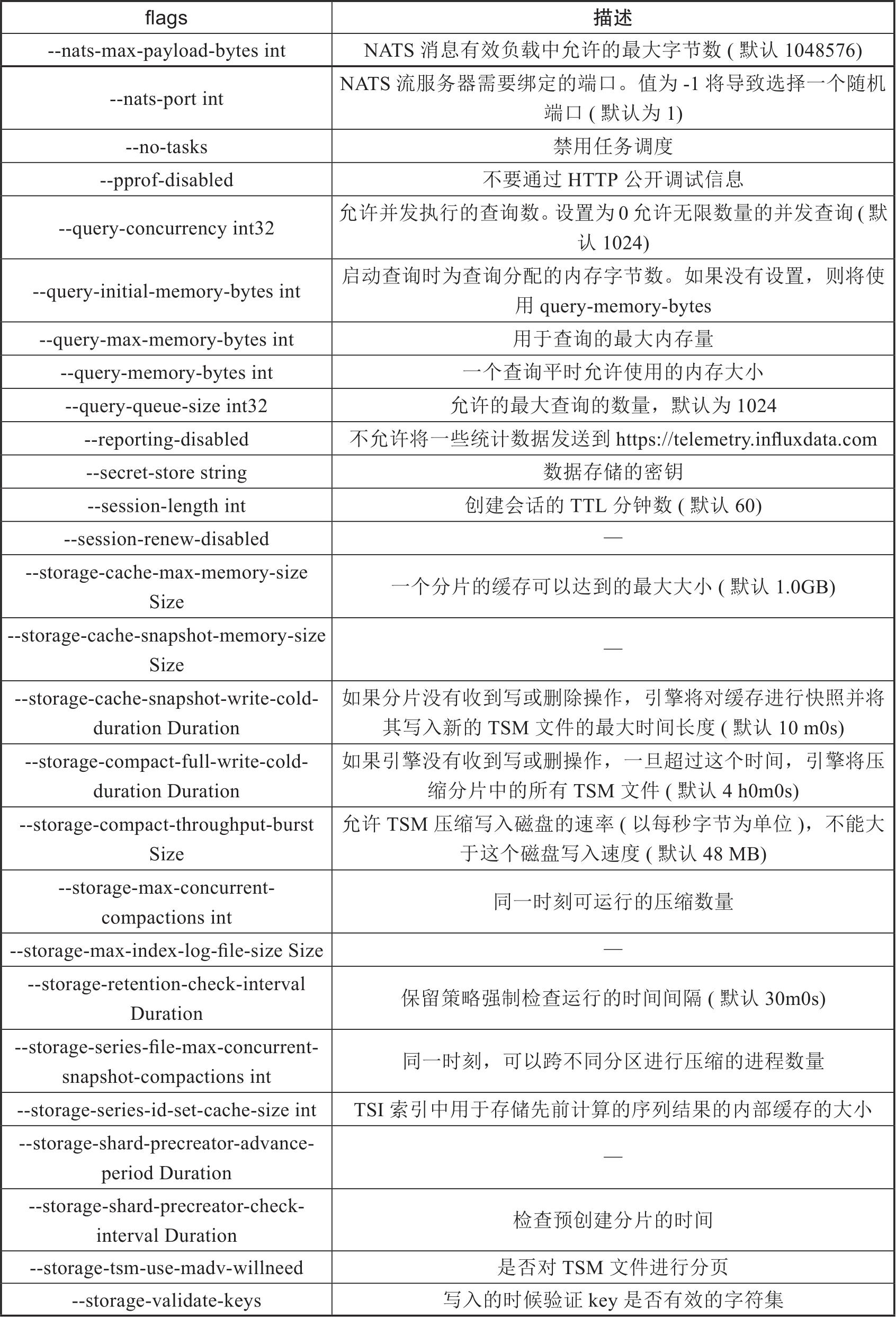
续表
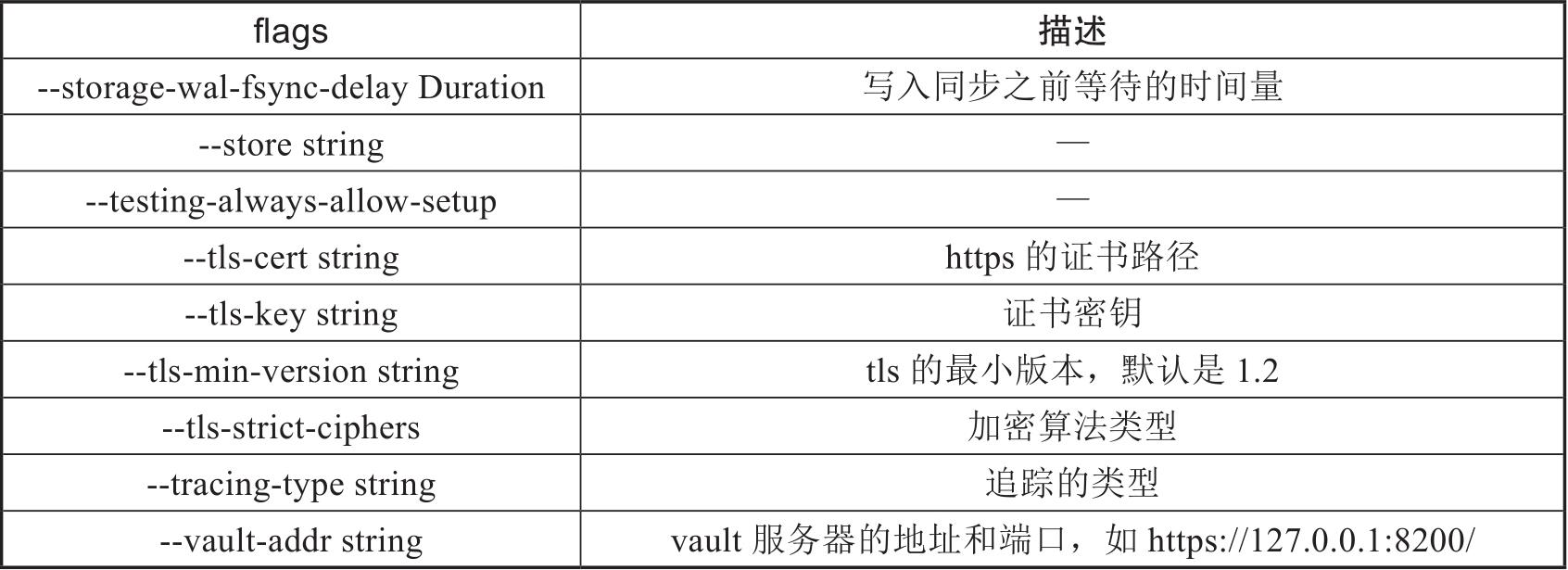
这些flags在实际使用InfluxDB中有特殊的用处,这里对几个主要参数做一些讲解,其他参数的解释,可以参考官网的说明https://docs.influxdata.com/influxdb/v2.0/reference/config-options/。
作为一个强大的时序数据库,InfluxDB拥有很多不同的配置,不同的使用场景下,可以通过设置不同的配置实现不同的功能,从而实现InfluxDB的柔性使用。InfluxDB的配置文件用于对InfluxDB进行配置。
当influxd启动时,会在当前工作目录下检查一个文件名为config.*的配置文件。文件扩展名取决于配置文件使用的语法。InfluxDB配置文件目前支持以下语法:
● YAML (.yaml, .yml)。YAML是“YAML Ain't a Markup Language(YAML不是一种标记语言)”的缩写。在开发这种语言时,YAML的意思其实是“Yet Another Markup Language(仍是一种标记语言)”。
● TOML (.toml)。TOML是前GitHub的CEO Tom Preston-Werner于2013年创建的语言,其目标是成为一个小规模的易于使用的语义化配置文件格式。TOML被设计为可以无二义性地转换为一个哈希表(Hash table)。
● JSON (.json)。JSON(JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式。它基于ECMAScript(欧洲计算机协会制定的JS规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得JSON成为理想的数据交换语言。易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
要自定义配置文件的目录路径,请将INFLUXD_CONFIG_PATH环境变量设置为自定义路径,如代码清单2-38所示。
export INFLUXD_CONFIG_PATH=/path/to/custom/config/directory
可以通过influxd config > influxd.config导出默认的配置选项,如代码清单2-39所示。
influxd config > influxd.config
打开influxd.config文件,部分配置选项如代码清单2-40所示。
除了通过配置文件对InfluxDB进行设置,还可以在启动influxd服务的时候,动态设置InfluxDB的配置。
为了更深入理解InfluxDB的常用配置,下面来看一下这些配置的含义。influxdb.conf中一般分为全局信息配置区、meta元数据配置区、data数据存储相关配置区、集群配置区、保留策略(retention)配置区等。
全局信息配置区,用于配置InfluxDB的一些全局信息,如代码清单2-41所示。

meta元数据信息,用于集群信息的配置,一般情况下,没有使用集群,所以大致了解一下就可以,如代码清单2-42所示。

控制InfluxDB的实际分片数据存在的位置以及如何从WAL中刷新数据。“dir”可能需要更改到适合当前系统的位置,但WAL设置是一种高级配置。默认值应该适用于大多数系统。
数据写入、压缩等相关配置,如代码清单2-43所示。

这里有一个WAL(Write Ahead Log)的概念,WAL的主要意思是在将元数据的变更操作写入磁盘之前,先预先写入一个Log文件中。WAL主要是用于提高性能而设计的。提高性能的原理是顺序写入磁盘的速度远远大于随机写入磁盘的速度。先把变更操作写入一个顺序写的Log文件中,随后再写入不连续的存储元数据的磁盘块中。这样Log就相当于一个缓冲区,能大大提高写入的速率。
保留策略表示数据默认在数据库中可以保存的时间,一旦超过这个时间,那么历史数据将会被删除。这是为了节省存储空间而设计的,如代码清单2-44所示。

shard-precreation用于集群中的分片设置,如代码清单2-45所示。

monitor控制InfluxDB自有的监控系统,如代码清单2-46所示。默认情况下,InfluxDB把这些数据写入_internal数据库,如果该库不存在则自动创建。_internal库默认的保留策略是7天。

InfluxDB非常适合作为监控系统使用,例如监控CPU使用率。CPU使用率是一个时序数据,横坐标是时间,纵坐标是CPU使用率,如图2-8所示。
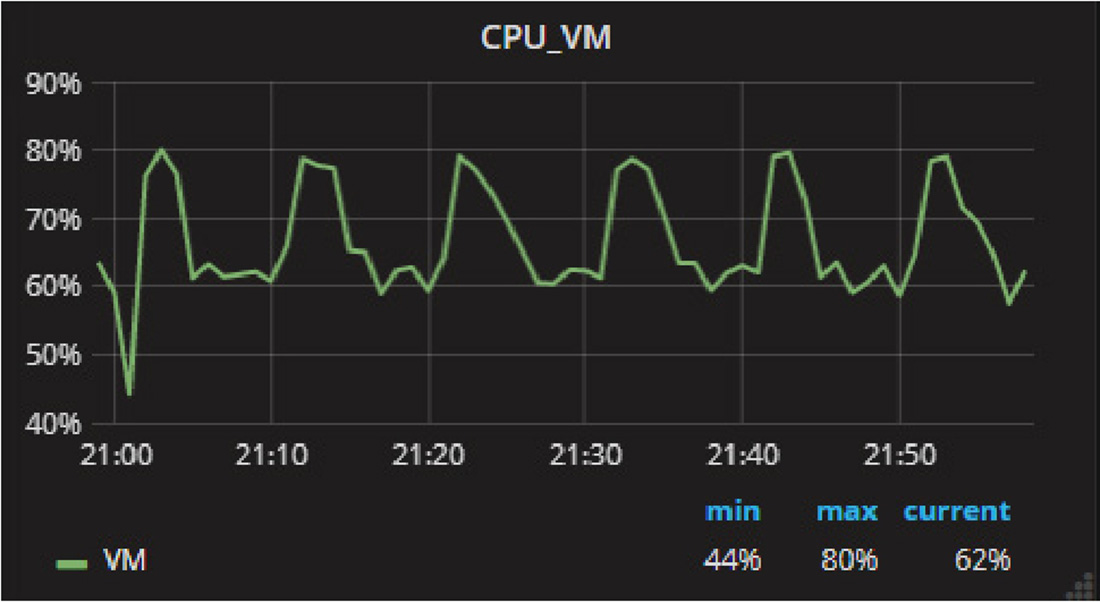
图2-8 CPU使用率监控
admin web用于InfluxDB的管理页面设置,如代码清单2-47所示。

访问InfluxDB可以使用http接口,[http]配置部分就是用来设置http接口参数的,如代码清单2-48所示。
