
下载掌阅APP,畅读海量书库
立即打开







假如有这样一个例子,需要统计在过去10年间计算机论文中出现次数最多的几个单词,以分析当前的热点研究议题是什么。
这一经典的单词计数案例可以采用MapReduce处理。MapReduce中已经自带了一个单词计数程序WordCount,如同Java中的经典程序“Hello World”,WordCount是MapReduce中统计单词出现次数的Java类,是MapReduce的入门程序。
例如,输入内容如下的文件,要求计算出文件中单词的出现次数,且按照单词的字母顺序进行排序,每个单词和其出现次数占一行,单词与出现次数之间有间隔:
hello world
hello hadoop
bye hadoop
直接运行MapReduce自带的WordCount程序对上述文件内容进行计算即可,其计算结果如下:
bye 1
hadoop 2
hello 2
world 1
下面进一步对WordCount程序进行分析。
WordCount对于单词计数问题的解决方案为:先将文件内容切分成单词,然后将所有相同的单词聚集到一起,计算各个单词出现的次数,最后将计算结果排序输出。
根据MapReduce的工作原理可知,Map任务负责将输入数据切分成单词;Shuffle阶段负责根据单词进行分组,将相同的单词发送给同一个Reduce任务;Reduce任务负责计算单词出现的次数并输出最终结果。
由于MapReduce中传递的数据都是<key,value>对形式的,而且Shuffle的排序、聚集和分发也是按照<key,value>对进行的,因此可将map()方法的输出结果设置为以单词作为key,1作为value的形式,表示某单词出现了1次(输入map()方法的数据则采用Hadoop默认的输入格式,即以文件每一行的起始位置作为key,本行的文本内容作为value)。由于reduce()方法的输入是map()方法的输出聚集后的结果,因此格式为<key, value-list>,也就是<word, {1,1,1,1,…}>;reduce()方法的输出则可设置成与map()方法输出相同的形式,只是后面的数值不再是固定的1,而是具体计算出的某单词所对应的次数。
WordCount程序的执行流程如图5-5所示。
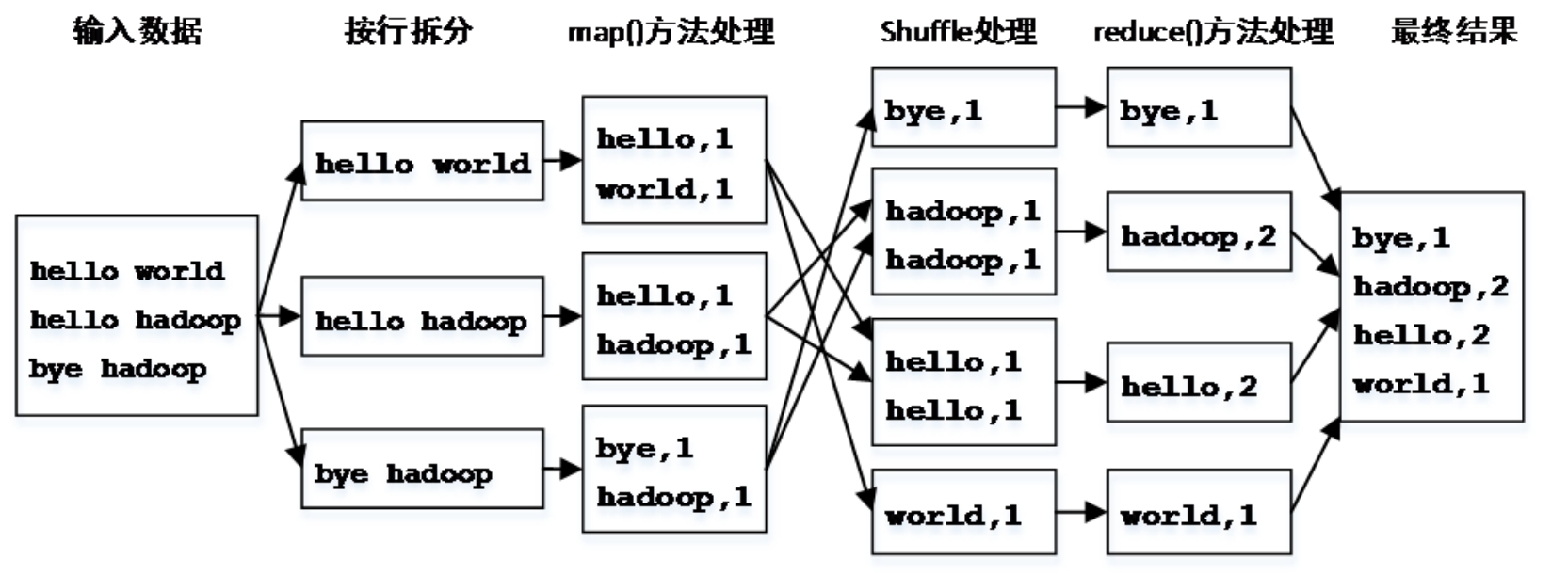
图5-5 WordCount程序的执行流程
WordCount程序类的源代码如下:

Hadoop本身提供了一整套可序列化传输的基本数据类型,而不是直接使用Java的内嵌类型。Hadoop的IntWritable类型相当于Java的Integer类型,LongWritable相当于Java的Long类型,TextWritable相当于Java的String类型。
TokenizerMapper是自定义的内部类,继承了MapReduce提供的Mapper类,并重写了其中的map()方法。Mapper类是一个泛型类,它有4个形参类型,分别指定map()方法的输入key、输入value、输出key、输出value的类型。本例中,输入key是一个长整数偏移量;输入value是一整行单词;输出key是单个单词;输出value是单词数量。Mapper类的核心源码如下:
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* 对输入拆分后的每个<key,value>对将调用一次该方法,大多数应用程序需要重写该方法
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
同样,IntSumReducer是自定义的内部类,继承了MapReduce提供的Reducer类,并重写了其中的reduce()方法。Reducer类与Mapper类一样,是一个泛型类,有4个形参类型,分别指定reduce()方法的输入key、输入value、输出key、输出value的类型。Reducer类的输入参数类型必须匹配Mapper类的输出类型,即Text类型和IntWritable类型。
本例中,reduce()方法的输入参数是单个单词和单词数量的集合,即<word, {1,1,1,1,…}>。reduce()方法的输出也必须与Reducer类规定的输出类型相匹配。Reducer类的核心源码如下:
public class Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
/**
* 对输入的每个<key,value-list>对将调用一次该方法,大多数应用程序需要重写该方法
*/
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
}
main()方法中的Configuration类用于读取Hadoop的配置文件,例如core-site.xml、mapred-site.xml、hdfs-site.xml等。也可以使用set()方法重新设置相关配置属性,例如重新设置HDFS的访问路径而不使用配置文件中的配置,代码如下:
conf.set("fs.default.name", "hdfs://192.168.170.133:9000");
main()方法中的job.setCombinerClass(IntSumReducer.class);指定了Map任务规约的类。这里的规约的含义是,将Map任务的结果进行一次本地的reduce()操作,从而减轻远程Reduce任务的压力。例如,把两个相同的“hello”单词进行规约,由此输入给reduce()的就变成了<hello,2>。实际生产环境是由多台主机一起运行MapReduce程序的,如果加入规约操作,每一台主机会在执行Reduce任务之前对本机数据进行一次规约,然后再通过集群进行Reduce任务操作,这样就会大大节省Reduce任务的执行时间,从而加快MapReduce的处理速度。本例的Map任务规约类使用了自定义Reducer类IntSumReducer。需要注意的是,并不是所有的规约类都可以使用自定义Reducer类,需要根据实际业务使用合适的规约类,也可以自定义规约类。
下面以统计文本文件中的单词频数为例,讲解如何运行上述单词计数程序WordCount,操作步骤如下:
01 执行以下命令,在HDFS根目录下创建文件夹input:
$ hadoop fs –mkdir /input
在本地新建一个文本文件words.txt,向其写入以下单词内容:
hello world
hello hadoop
bye hadoop
执行以下命令,将words.txt上传到HDFS的/input目录中:
$ hadoop fs -put words.txt /input
02 进入Hadoop安装目录,执行以下命令,运行Hadoop自带的WordCount程序:
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
上述命令中的/input为数据来源目录,/output为结果数据存储目录。
需要注意的是,HDFS中不应存在目录/output(程序会自动创建),若存在则会抛出异常。
若控制台输出以下信息,表示程序运行正常:
16/09/05 22:51:27 INFO mapred.LocalJobRunner: reduce task executor complete.
16/09/05 22:51:28 INFO mapreduce.Job: map 100% reduce 100%
16/09/05 22:51:28 INFO mapreduce.Job: Job job_local1035441982_0001 completed
successfully
16/09/05 22:51:28 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=569202
FILE: Number of bytes written=1134222
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=30858
HDFS: Number of bytes written=8006
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=289
Map output records=2157
Map output bytes=22735
Map output materialized bytes=10992
Input split bytes=104
Combine input records=2157
Combine output records=755
Reduce input groups=755
Reduce shuffle bytes=10992
Reduce input records=755
Reduce output records=755
Spilled Records=1510
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=221
Total committed heap usage (bytes)=242360320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=15429
File Output Format Counters
Bytes Written=8006
程序运行过程中也可以访问YARN ResourceManager的Web界面http://centos01:8088查看程序的运行状态,如图5-6所示。
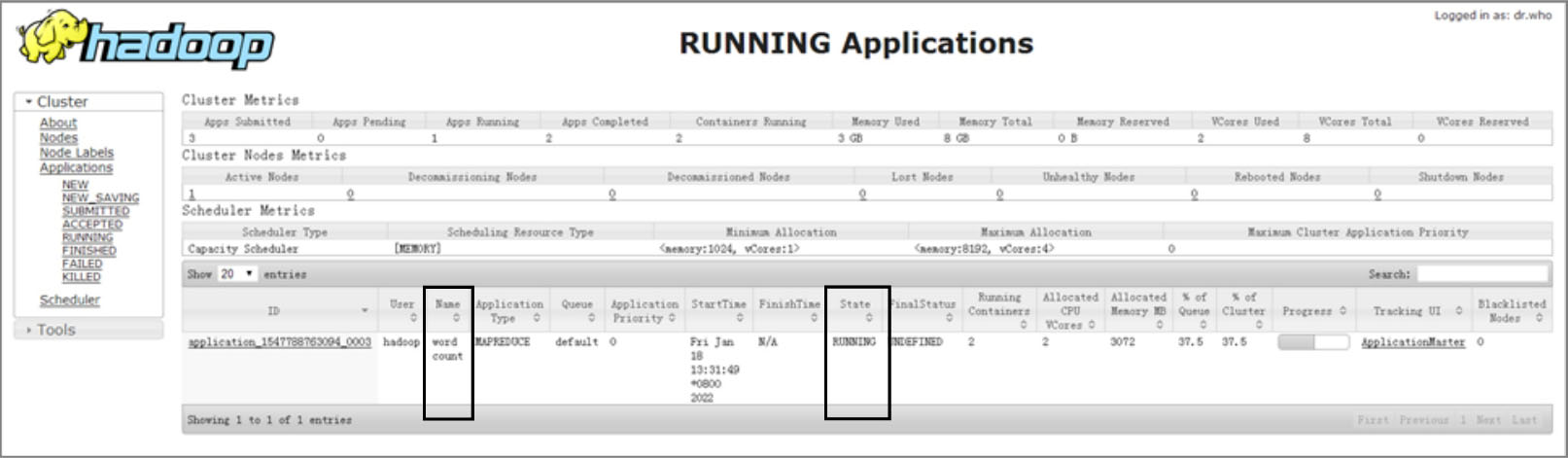
图5-6 YARN ResourceManager的Web界面
03 程序运行的结果以文件的形式存放在HDFS的/output目录中,执行以下命令,查看目录/output中的内容:
$ hadoop fs -ls /output
可以看到,/output目录中生成了两个文件:_SUCCESS和part-r-00000,_SUCCESS为执行状态文件,part-r-00000则存储实际的执行结果,如图5-7所示。

图5-7 查看结果文件
可以执行以下命令,将运行结果下载到本地查看:
$ hadoop fs –get /output
也可以执行以下命令,直接查看结果文件中的数据,如图5-8所示。
$ hadoop fs -cat /output/*
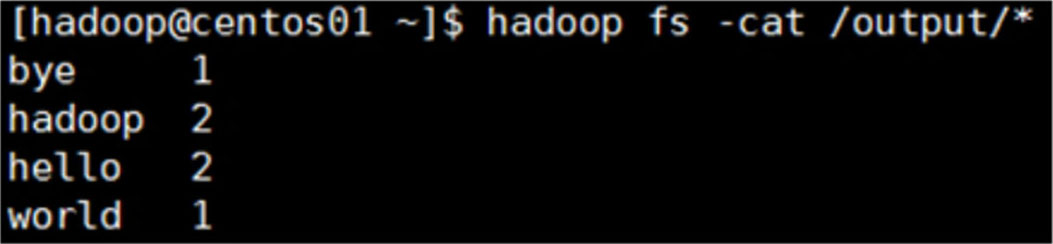
图5-8 查看单词计数结果数据