
下载掌阅APP,畅读海量书库
立即打开



列联表分析(Crosstabs)是通过分析多个变量在不同取值情况下的数据分布情况,从而进一步分析多个变量之间相互关系的一种描述性分析方法。列联表分析至少指定两个变量,分别为行变量和列变量,如果要进行分层分析,则还要规定层变量。通过列联表分析,不仅可以得到交叉分组下的频数分布,还可以通过分析得到变量之间的相关关系。

【例2.4】 表2.13给出了山东省两所学校的高三毕业生的升学情况。试据此对两所学校学生的升学情况进行列联表分析,研究两所学校的学生升学率之间有无明显的差别。
表2.13 甲乙两所中学高三毕业生的升学情况表

在用SPSS进行分析之前,我们要把数据录入到SPSS中。本例中3个变量分别是学校、升学和计数。我们把学校定义为字符型变量,把升学和计数定义为数值型变量,对学校和升学两个变量进行相应的值标签操作,对学校变量用“1”表示“甲中学”,“2”表示“乙中学”,对升学变量用“1”表示“升学”,“0”表示“未升学”,然后录入相关数据。录入完成后,数据如图2.21所示。
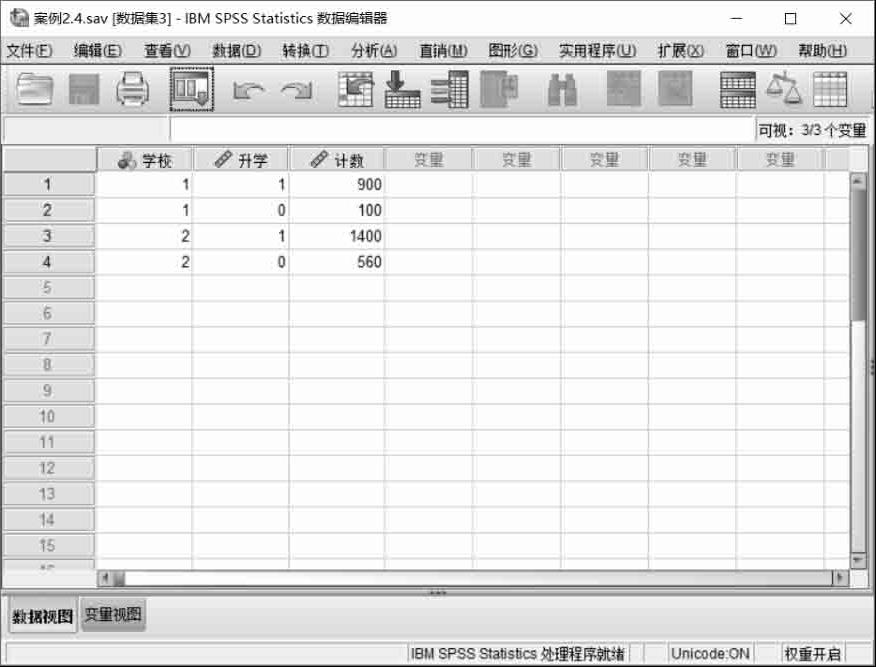
图2.21 案例2.4数据
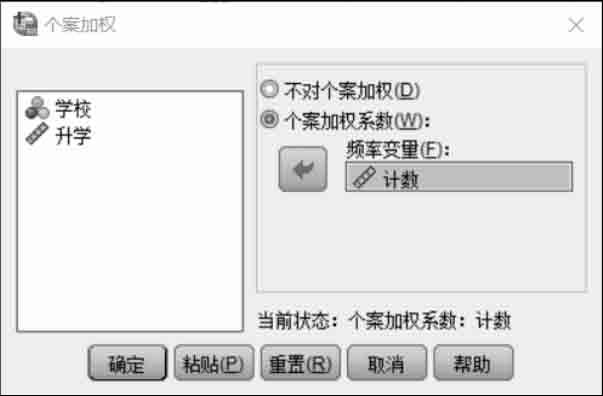
图2.22 “个案加权”对话框
对数据进行保存,然后展开分析,步骤如下:
 进入SPSS 24.0,对数据进行预处理,以计数变量对升学变量进行加权。选择“数据”|“个案加权”命令,弹出如图2.22所示的对话框。在“个案加权”对话框中选中“个案加权系数”单选按钮,然后在左侧的列表框中选中“计数”,单击
进入SPSS 24.0,对数据进行预处理,以计数变量对升学变量进行加权。选择“数据”|“个案加权”命令,弹出如图2.22所示的对话框。在“个案加权”对话框中选中“个案加权系数”单选按钮,然后在左侧的列表框中选中“计数”,单击
 按钮,使之进入“频率变量”列表框中。单击“确定”按钮,完成数据预处理。
按钮,使之进入“频率变量”列表框中。单击“确定”按钮,完成数据预处理。
 选择“分析”|“描述统计”|“交叉表”命令,弹出如图2.23所示的对话框。首先定义行变量,在对话框左侧选择“学校”并单击
按钮,使之进入右侧的“行”列表框。然后定义列变量,在左侧的列表中选择“升学”并单击
按钮,使之进入右侧的“列”列表框。因为没有别的变量参与列联表分析,所以这里没有层控制变量。最后选中“显示簇状条形图”复选框。
选择“分析”|“描述统计”|“交叉表”命令,弹出如图2.23所示的对话框。首先定义行变量,在对话框左侧选择“学校”并单击
按钮,使之进入右侧的“行”列表框。然后定义列变量,在左侧的列表中选择“升学”并单击
按钮,使之进入右侧的“列”列表框。因为没有别的变量参与列联表分析,所以这里没有层控制变量。最后选中“显示簇状条形图”复选框。
 选择检验统计量的计算方法。单击“交叉表”对话框右上角的“精确”按钮,弹出如图2.24所示的对话框,选中“仅渐进法”单选按钮,单击“继续”按钮,返回“交叉表”对话框。
选择检验统计量的计算方法。单击“交叉表”对话框右上角的“精确”按钮,弹出如图2.24所示的对话框,选中“仅渐进法”单选按钮,单击“继续”按钮,返回“交叉表”对话框。
 选择相关统计检验。单击“交叉表”对话框右侧的“统计”按钮,弹出如图2.25所示的对话框,在该对话框中可以设置相关统计检验。选中“卡方”复选框,用于检验学校和升学之间是否相关。
选择相关统计检验。单击“交叉表”对话框右侧的“统计”按钮,弹出如图2.25所示的对话框,在该对话框中可以设置相关统计检验。选中“卡方”复选框,用于检验学校和升学之间是否相关。
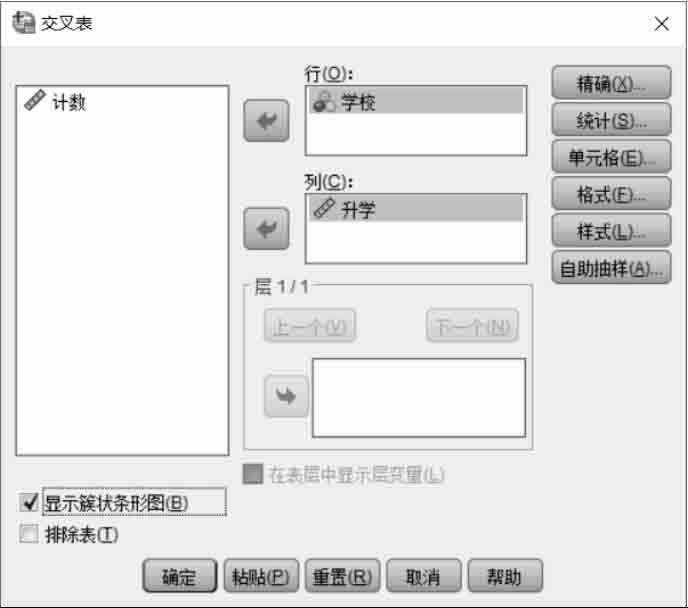
图2.23 “交叉表”对话框
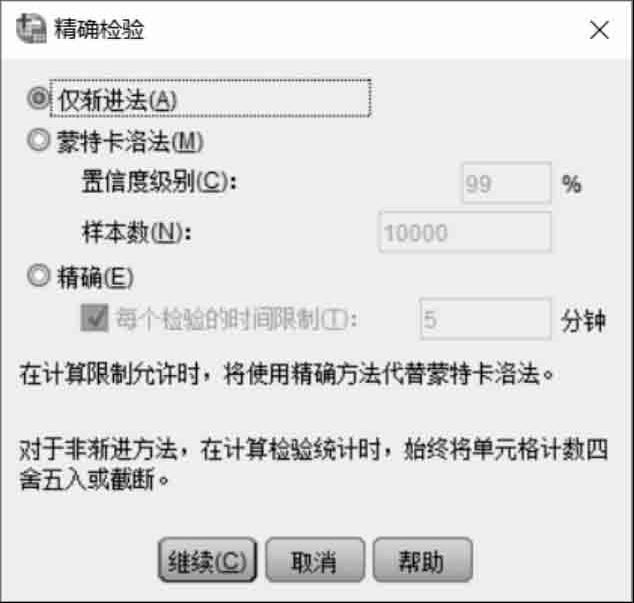
图2.24 “精确检验”对话框
 选择列联表单元格中需要计算的指标。单击“交叉表”对话框右侧的“单元格”按钮,弹出如图2.26所示的对话框,在该对话框中可以设置相关输出内容。在“计数”选项组中选中“实测”复选框;在“百分比”选项组中选择“行”“列”“总计”复选框;在“非整数权重”选项组中选中“单元格计数四舍五入”复选框。设置完毕后,单击“继续”按钮返回“交叉表”对话框。
选择列联表单元格中需要计算的指标。单击“交叉表”对话框右侧的“单元格”按钮,弹出如图2.26所示的对话框,在该对话框中可以设置相关输出内容。在“计数”选项组中选中“实测”复选框;在“百分比”选项组中选择“行”“列”“总计”复选框;在“非整数权重”选项组中选中“单元格计数四舍五入”复选框。设置完毕后,单击“继续”按钮返回“交叉表”对话框。
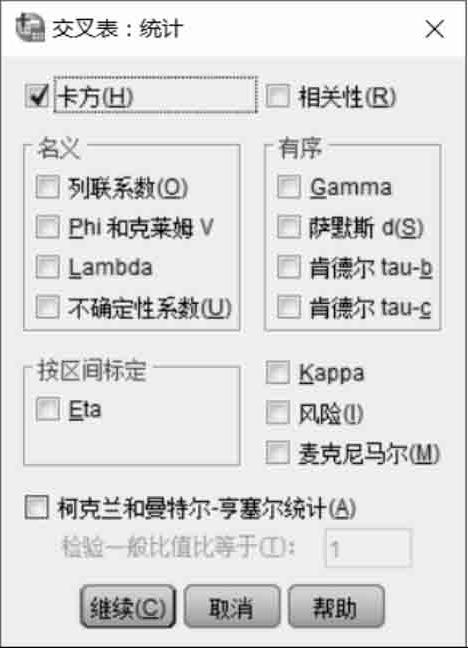
图2.25 “交叉表:统计”对话框
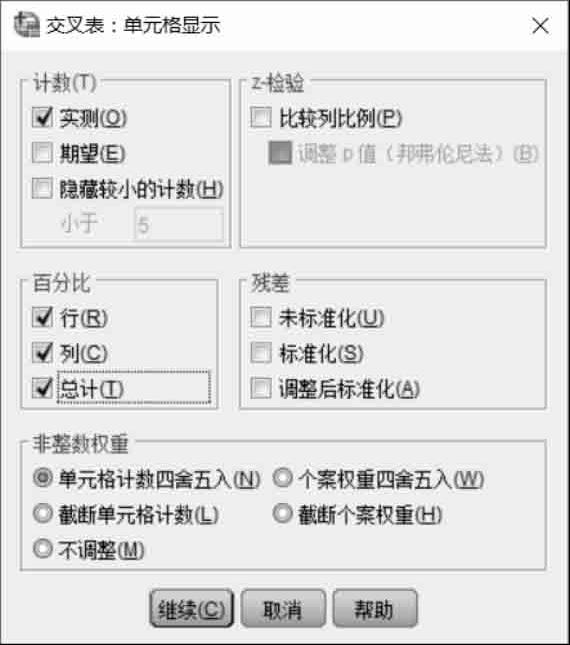
图2.26 “交叉表:单元格显示”对话框
 最后选择行变量是升序排列还是降序排列。单击“交叉表”对话框右侧的“格式”按钮,弹出如图2.27所示的对话框,在该对话框中可以设置行变量的排序方式。这里选中“升序”单选按钮。
最后选择行变量是升序排列还是降序排列。单击“交叉表”对话框右侧的“格式”按钮,弹出如图2.27所示的对话框,在该对话框中可以设置行变量的排序方式。这里选中“升序”单选按钮。
图2.27 “交叉表:表格式”对话框
 设置完毕后,单击“确定”按钮,等待输出结果。
设置完毕后,单击“确定”按钮,等待输出结果。
(1)本例的数据信息
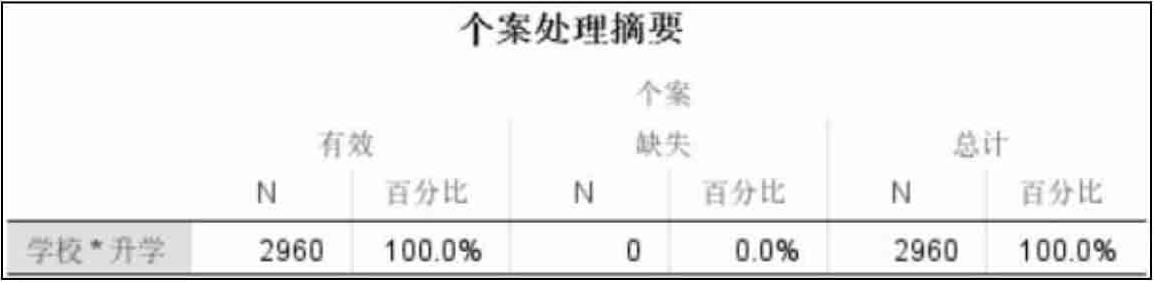
如表2.14所示,样本数为2960,没有缺失值。
表2.14 样本统计
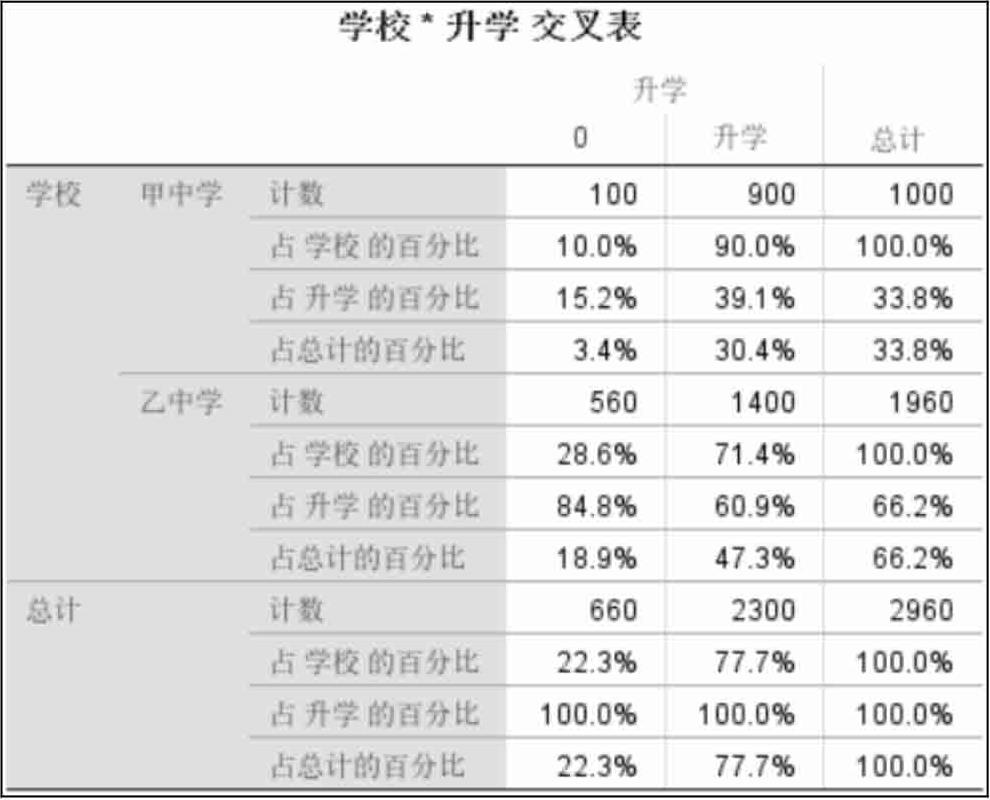
(2)列联表
如表2.15所示,甲中学的升学率是90%,未升学率是10%;乙中学的升学率是71.4%,未升学率是28.6%。甲中学的升学人数占全部升学人数的39.1%,乙中学的升学人数占全部升学人数的60.9%;甲中学的未升学人数占全部未升学人数的15.2%,乙中学的未升学人数占全部未升学人数的84.8%。
表2.15 列联表
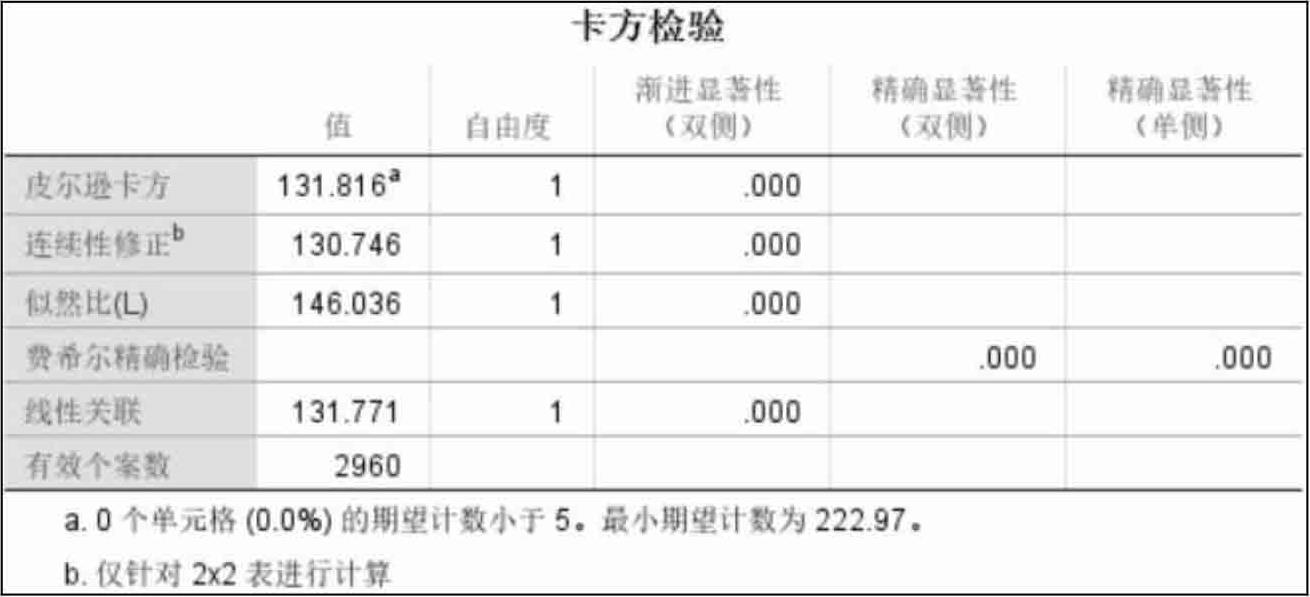
(3)卡方检验结果
如表2.16所示,卡方检验的结果是非常显著的,说明两个学校的升学率之间有着明显的差别。
表2.16 卡方检验
(4)频数分布图
分组下的频数分布如图2.28所示。
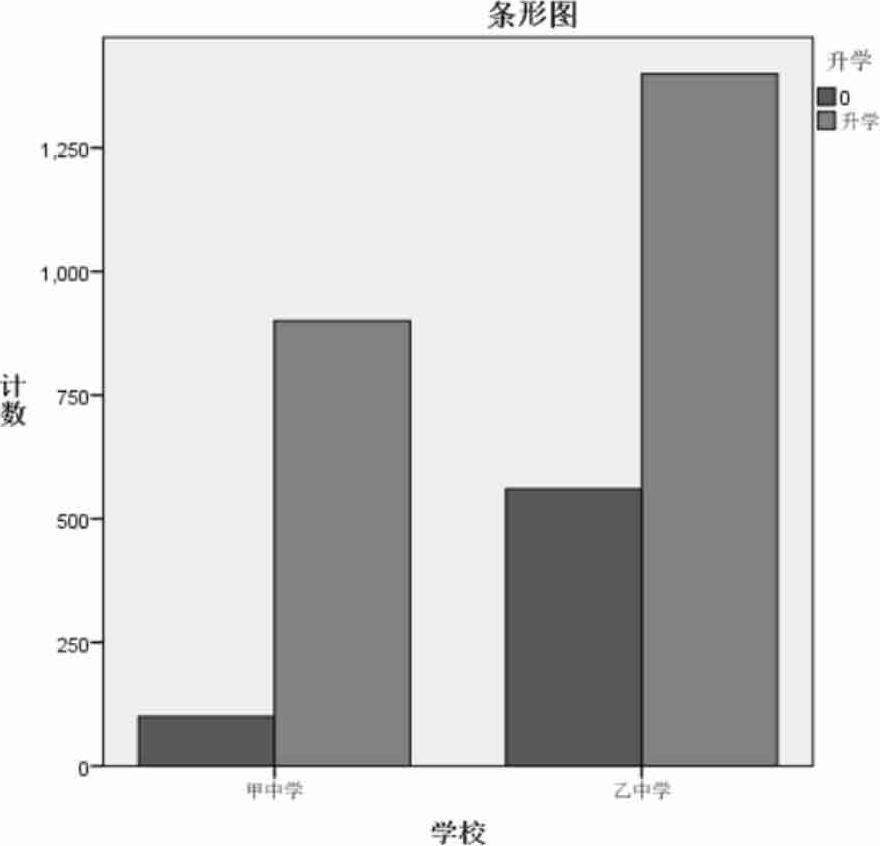
图2.28 频数分布图