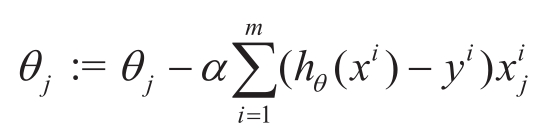下载掌阅APP,畅读海量书库
立即打开



回归模型是对统计关系进行定量描述的一种预测性数学模型,它研究的是自变量和因变量之间的关系。针对大量观察或试验所获得的数据样本,研究其中蕴含的相关关系,并给出相关关系的数学表达——假设函数,从而建立回归模型。
回归包括线性回归、逻辑回归、岭回归、套索回归和弹性回归等,以下主要介绍线性回归和逻辑回归。
一元线性回归是对一维自变量与其所对应的因变量之间的线性关系进行建模,给定数据集 D ={( x 1 , y 1 ), ( x 2 , y 2 ),…,( x m , y m )},样本数据( x i , y i )的上标为其编号 i ,找到一条最能代表这些数据点的直线,使得所有数据点到该直线的距离之和最小,这条直线的函数表达即一元线性回归的假设函数:
h θ ( x )= θ 0 +θ 1 x
我们可以通过估计值 h θ ( x i )与真实值 y i 的差的平方( h θ ( x i ) -y i ) 2 度量其欧几里得距离(简称“欧式距离”),以衡量数据点与假设函数的直线之间的距离。计算样本平方差的平均值,即“均方误差”,可以用来评价参数 θ 0 和 θ 1 所决定的假设函数 h θ ( x )的好坏,即
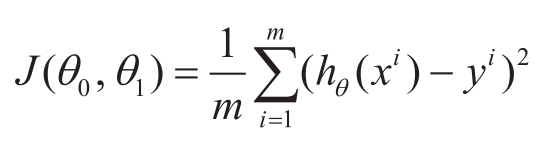
此函数通常称为损失函数,最小化该损失函数可求得最优的参数组合 θ 0 和 θ 1 ,求解可以通过最小二乘法,对 J ( θ 0 , θ 1 )中 θ 0 与 θ 1 分别求导,得到
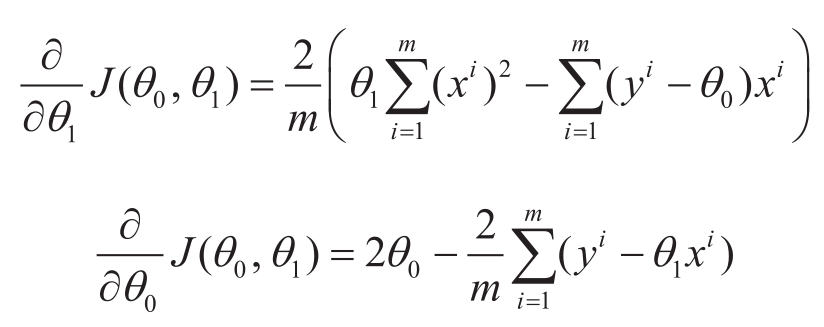
上面两个导数式子等于零时,对应于损失函数可取得最小值的情况,可解得

从而得到对于数据的相关性的最优表达 h θ ( x ),进一步,对于给定的 x ,可利用 h θ ( x )推断其对应的 y 。
一元线性回归的方法可以推广到更一般的形式——多元线性回归。当自变量个数为 n ( n ≥2)时,线性回归模型为多元线性回归模型,假设函数为
h θ ( x )= θ 0 + θ 1 x 1 + θ 2 x 2 +…+ θ n x n
为了简化表示形式,定义 θ 0 是恒等于1的变量 x 0 的系数,则假设函数可以表示为
h θ ( x )= θ T x
其中,(·)
T
表示向量或矩阵的转置,
θ
=(
θ
0
,
θ
1
, …
θ
n
)
T
,
x
=(1,
x
1
, …,
x
n
)
T
。给定数据集
D
={(
x
1
,
y
1
), (
x
2
,
y
2
), …, (
x
m
,
y
m
)},其中,
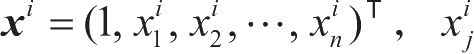 下标为维度,上标为样本编号,对
D
进行线性回归,损失函数为
下标为维度,上标为样本编号,对
D
进行线性回归,损失函数为
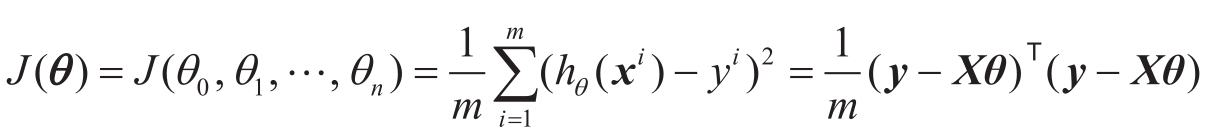
其中,
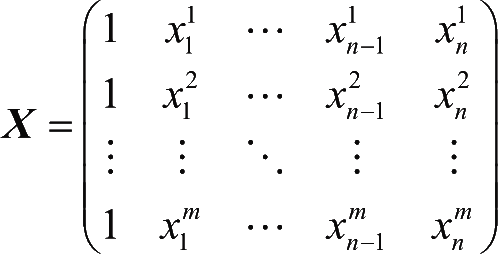 是由
是由
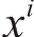 组成的矩阵,
y
=
组成的矩阵,
y
=
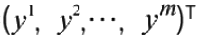 是由
对应的
是由
对应的
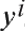 组成的列向量,对向量
θ
求导,以矩阵形式表达可得
组成的列向量,对向量
θ
求导,以矩阵形式表达可得
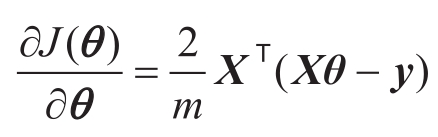
令此导数为0,可求得参数 θ 的解为
θ= ( X T X ) -1 X T y
( X T X ) -1 是矩阵 X T X 的逆,在 X T X 是满秩或正定的情况下,上式可求得 θ 的闭式解。而如果数据集中数据量大,求解的复杂度也随之增大,也可使用梯度下降法得到数值解。
梯度下降法首先随机对 θ 赋初始值,通过沿着损失函数值梯度下降的方向不断迭代 θ ,损失函数梯度的方向由对 θ 的偏导数决定,梯度下降的方向是负的偏导数的方向,梯度下降法中 θ 的每个维度 θ j 的更新公式为
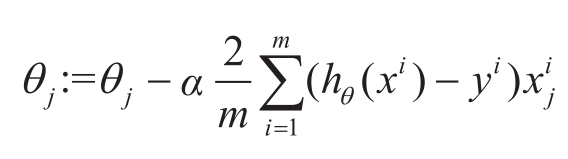
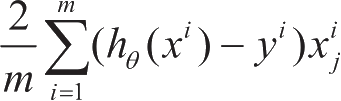 是
θ
j
维度上的梯度,
α
是步长,表示每一步移动的大小,减号表示向梯度下降的方向移动,也就是损失函数减小的方向。按照此方法不断迭代,当达到终止条件时,可近似得到参数
θ
的数值解。
是
θ
j
维度上的梯度,
α
是步长,表示每一步移动的大小,减号表示向梯度下降的方向移动,也就是损失函数减小的方向。按照此方法不断迭代,当达到终止条件时,可近似得到参数
θ
的数值解。
逻辑(logistic)回归进一步将线性回归扩展到分类问题。对于二元分类任务,给定数据集 D ={( x 1 , y 1 ), ( x 2 , y 2 ),…, ( x m , y m )},每一个 x i 对应的 y i 只分为两类,记 y i ∈ {0, 1},通常称 y i =1为正例, y i =0为负例。而线性回归函数产生的预测值 z = θ T x 是实值,需要利用函数将 z 转换为0/1值。最理想的是使用阶跃函数:当 z ≥0时,函数值为1,否则函数值为0,但阶跃函数在 z =0处不满足连续可导,难以进行回归。阶跃函数常用的替代函数是对数概率函数,也称为Sigmoid函数:
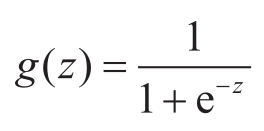
对数概率函数处处连续可导, g ( z )可以理解为 z 被判为正例的概率大小,满足 z ≥0,则 g ( z )≥0.5,判为正例的概率更大,则判为正例 y =1,否则, g ( z )<0.5,判为负例的概率大,则判为负例 y =0。利用对数概率函数,逻辑回归的假设函数为
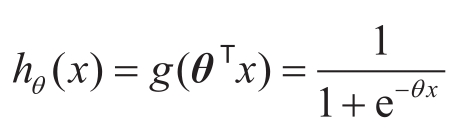
相当于推断 x 被判为正例的概率。逻辑回归对于假设函数的优化目标是令每一个 x i 属于其真实类别 y i 的概率越大越好,即 y i =1时,最大化 h θ ( x i ); y i =0时,最大化1 -h θ ( x i )。在计算概率时,通常对概率取对数,上述目标可统一写为最大化 y i ∗log( h θ ( x i ))+(1 -y i )∗log(1 -h θ ( x i )),相当于最小化损失函数:
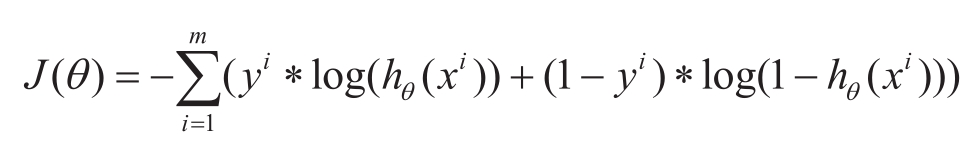
以梯度下降法求 θ 的每个维度 θ j 的更新公式为