
下载掌阅APP,畅读海量书库
立即打开



在面向对象的开发过程中,任何事物都是对象。而在日常开发过程中,我们可以从数据出发来设计对象的表现形式。这些数据对象只包含了一组数据属性,没有提供任何对业务逻辑的处理过程,开发人员更关注数据而不是领域。这种开发模式非常常见,但却不是DDD推荐的做法。在DDD中,我们关注的是领域模型对象而并非数据本身。领域模型对象与数据对象之间的本质区别在于前者不只包含数据属性的定义,还具有一系列的标识和行为定义。
在DDD中,领域模型对象指3类对象,即聚合、实体和值对象。其中实体和值对象是聚合的组成部分,而值对象同时是实体的组成部分,这3种对象之间的组成关系如图2-5所示。
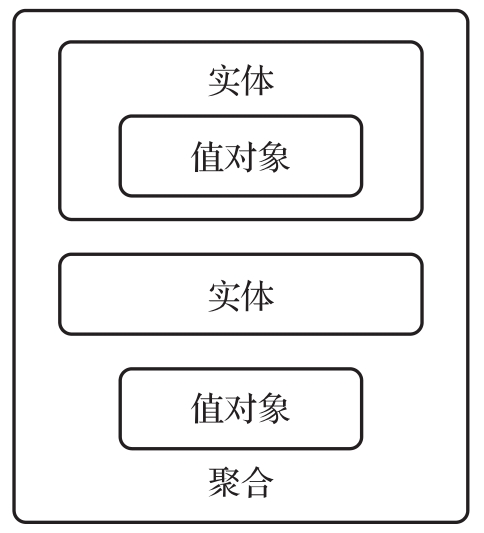
图2-5 领域模型对象之间的组成关系示意图
理解实体和值对象是构建聚合的基础。本节先从实体和值对象开始讲起,下一节将重点讨论聚合。
1.实体
与数据对象一样,实体对象本身也包含数据属性。但实体对象和数据对象的区别在于实体包含了业务的状态以及围绕这些状态产生的生命周期。换言之,实体应该具有两个基本特征,即唯一标识和可变性。
(1)唯一标识
唯一标识是实体对象必须具备的一种属性,也是实体与值对象之间的核心区别之一。如代码清单2-1所示的HealthTask就是一个典型的实体对象,其中包含了代表该对象唯一性的TaskId属性。
代码清单2-1 HealthTask实体对象示例代码

这里唯一标识TaskId的创建方式可以有多种,常见的方法如下。
1)系统内部自动生成唯一标识。这种方法被广泛应用于各种需要生成唯一标识的场景。生成策略上可以简单使用JDK自带的UUID;也可以借助第三方框架,如支持雪花算法的Leaf;更为常见的做法是通过时间、IP、对象标识、随机数、加密等多种手段混合生成。
2)系统依赖持久化存储生成唯一标识。这种方法实现简单,经常被应用于具备持久化条件的系统中,常见的做法包括使用Oracle的Sequence、MySQL的自增列、MongoDB的_id等。而在生成唯一标识的时机上存在两种做法:一种是在持久化对象之前就生成唯一标识;另一种则是延迟生成,即唯一标识生成是在将对象保存到数据库之后。在本书中,我们将引入UML(Unified Modeling Language,统一建模语言)中的图例来展示系统建模的结果,并且会使用UML中的时序图(sequence diagram)来展示核心流程。图2-6展示了基于后者的时序图。显然,我们可以使用数据库中自增主键的功能来获取唯一标识。
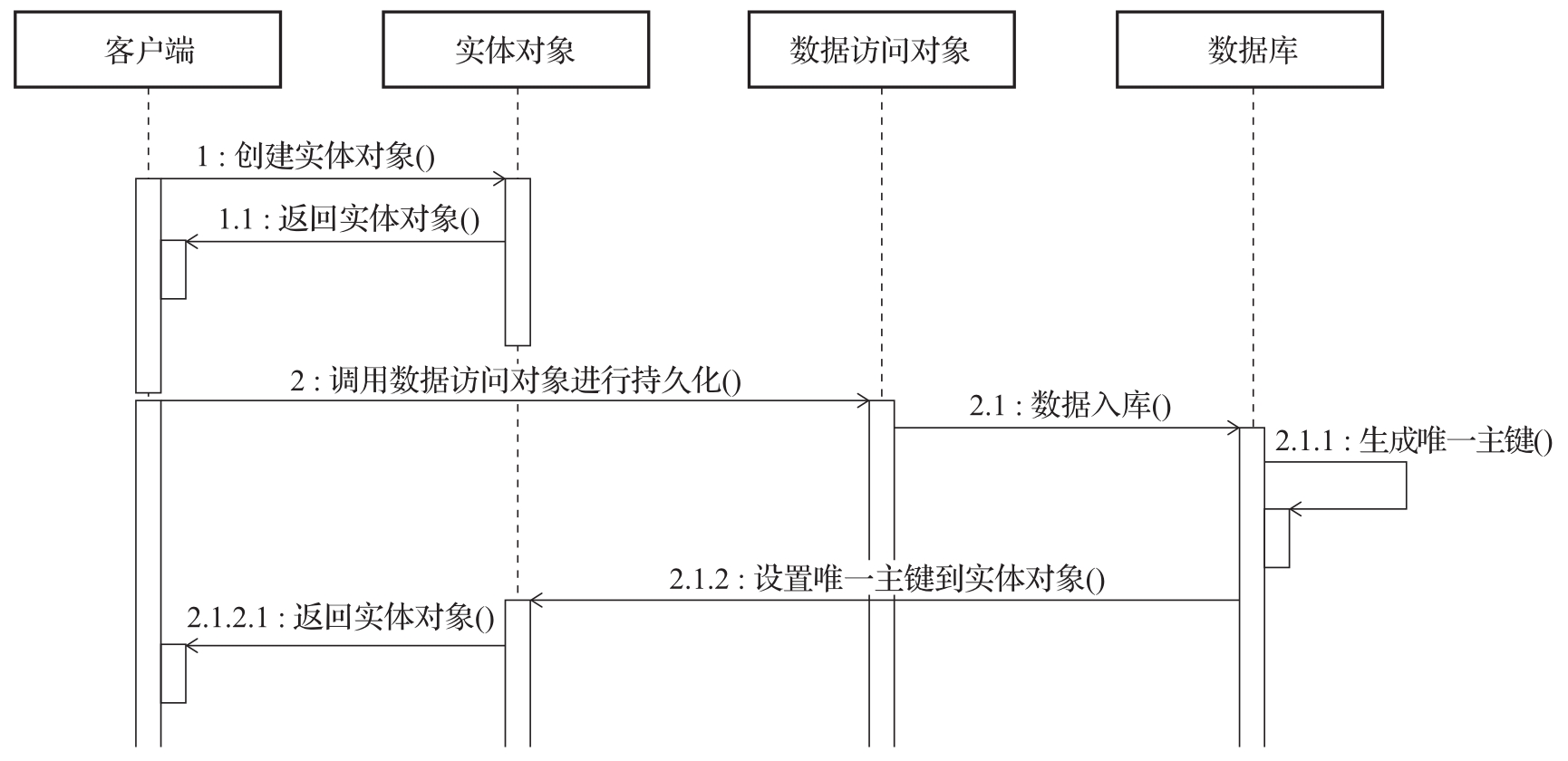
图2-6 延迟生成唯一标识的时序图
原则上,唯一标识的生成过程应该位于该实体所处的上下文中,但也存在从另一个上下文传入唯一标识的情况。这种情况比较少见,实现起来也需要依赖事件机制以及考虑数据一致性问题,一般不推荐。
(2)可变性
可变性是实体对象与值对象的另一个核心区别。实际上,关于实体对象可变性的讨论,已经不仅仅局限于领域模型对象的设计,还延伸到了关于架构模式的探讨。这里,我们不得不提一个老生常谈的话题,即贫血模型和充血模型之间的对比。
在贫血模型中,领域对象实际上就是数据对象,即领域对象的作用只是传递状态,自身并不包含任何业务逻辑。从代码实现上讲,贫血模型中的领域对象通常只包含针对各个属性的getter/setter方法,而没有提供任何针对业务状态控制和对象生命周期管理的方法。
与之相对,充血模型中的领域对象一般都具备自己的基础业务方法,同时对自身对象的生命周期进行统一的管理和维护。如代码清单2-2所示,这就是一个包含了初始化及状态更新操作的HealthTask实体对象。
代码清单2-2 包含了业务逻辑处理的HealthTask实体对象示例代码

充血模型中领域对象职责更加单一,所有关于对象本身的操作都包含在对象内部,更加适合复杂业务逻辑的设计开发。
2.值对象
一般在对系统的实体对象和值对象进行提取时,关注点首先在实体上,把实体提取完毕,就需要进一步梳理实体中是否包含了潜在的值对象。
值对象的特征决定了分离值对象的方法。与实体对象相比,值对象自身没有状态,是一种不可变对象。另外,因为值对象没有唯一标识,所以对值对象可以进行相等性比较,也可以相互替换。图2-7展示了值对象的一个具体示例。
在图2-7中,我们首先设计了一个账户对象Account,显然该对象具有唯一标识符accountId,所以是一个实体对象。然后我们发现Account对象中包含了该账户所对应的地址信息对象Address,而Address就是一个值对象,因为Address将Street、City、State等相关属性组合成了一个概念整体。Address对象没有唯一标识,也可以作为不变量,当该Address改变时,可以用另一个Address值对象予以替换。
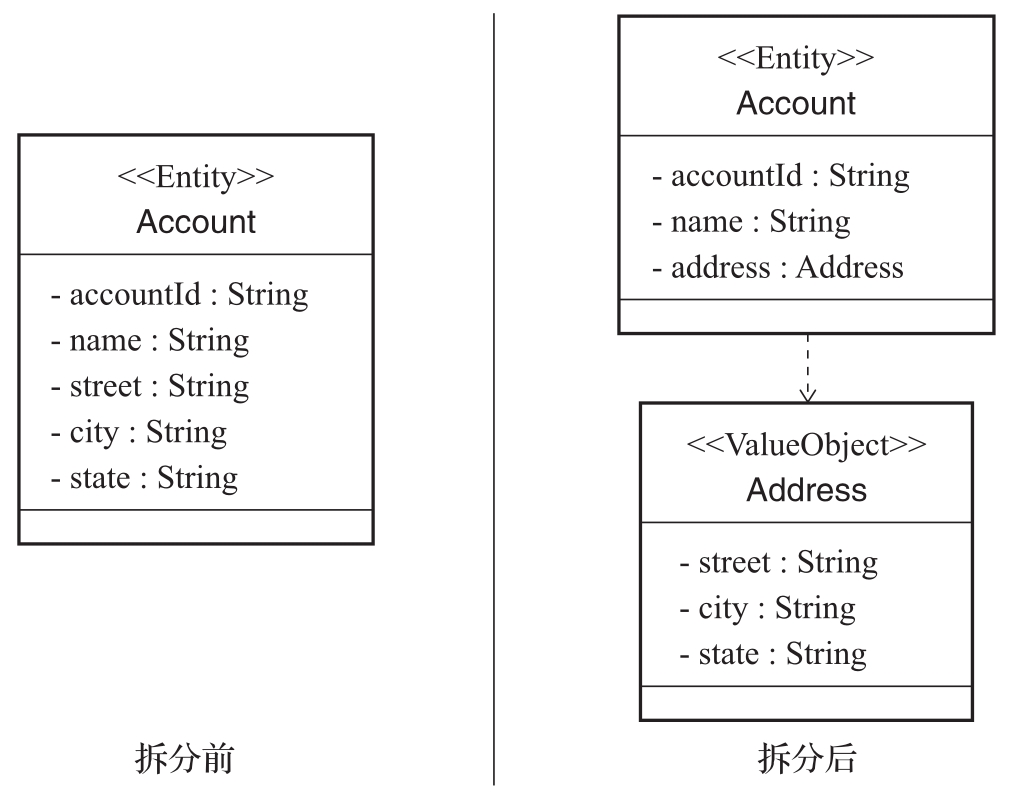
图2-7 从实体中分离值对象
在DDD中,值对象主要有两大类应用场景。首先,值对象可以用来表示业务数据,就像前面示例中的Address对象。然后,值对象也可以在上下文集成中充当对外的数据传输媒介。值对象在实现上需要严格保持其不变性,我们通过只用构造函数而不用setter方法等手段可以构建一个合适的值对象。
3.识别实体和值对象
识别实体和值对象是面向领域的战术设计中非常基础也非常重要的一步,基本思路还是充分利用通用语言中的信息,并采用如图2-8所示的4个步骤。
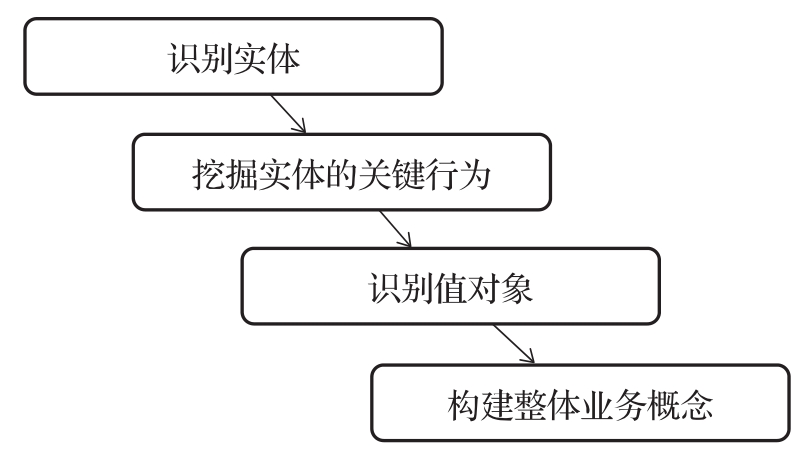
图2-8 识别实体和值对象的4个步骤
这里通过一个简单的示例来演示如何识别实体和值对象。我们知道围绕用户(User)这个概念有这些常见的业务需求:对系统中的User进行认证;User可以处理自己的个人信息,包含姓名、联系方式等;User的安全密码等个人信息能被本人修改。这些描述构成了针对用户的通用语言。在接下来的内容中,我们将围绕User这个业务概念来演示识别实体和值对象的具体步骤。
(1)识别实体
通过“认证”“修改”等关键词,我们可以判断出User应该是一个实体对象而不是值对象,所以User应该包含一个唯一标识及其他相关属性。考虑到User实体的唯一标识UserId可能是一个数据库主键值,也可能是一个复杂的数据结构,所以我们把UserId提取成一个值对象,这是DDD经常采用的一种实体唯一标识的实现方法。这样就识别出了基础的User实体,如图2-9所示。
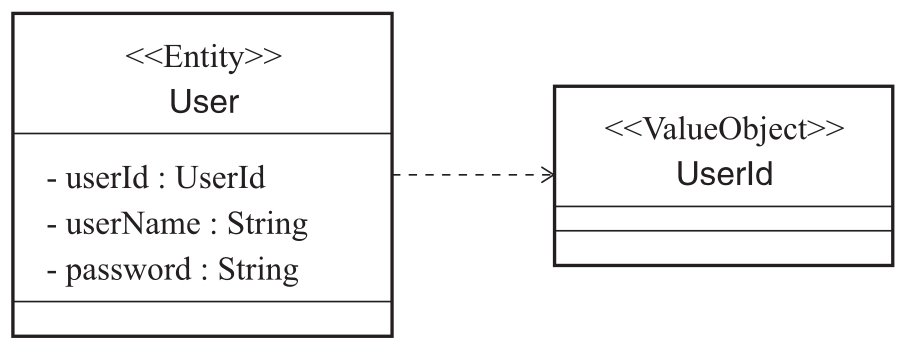
图2-9 User实体对象及其属性
(2)挖掘实体的关键行为
通过对User进行通用语言的分析,我们再进一步细化它的关键行为。一般而言,用户在应用上会产生登录、退出以及修改密码的行为,包含这些行为的User实体如图2-10所示。
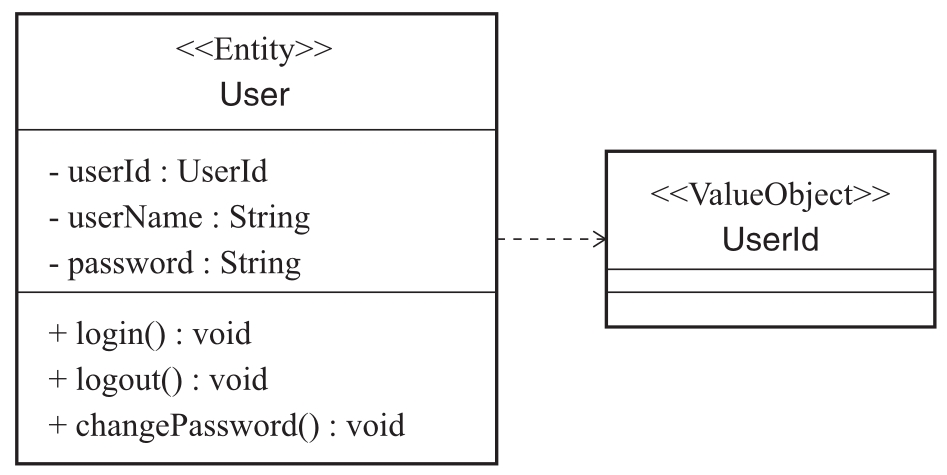
图2-10 User实体对象的属性与行为
(3)识别值对象
考虑到激活状态的User可以修改姓名、联系方式等个人信息,我们势必要从User实体中提取姓名、联系方式等信息,这些信息实际上构成了一个完整的人(Person)的概念,但显然Person不等于User,而是User的一部分。User作为一个抽象的概念,包含Person相关信息,也包含用户名、密码等账户相关的信息,所以这个时候我们发现需要从User中进一步分离Person对象。Person也是一个实体,但与Person紧密相关的联系方式等信息建议被分离成值对象。基于这些分析,我们对User实体进一步细化,可以得到如图2-11所示的结果。
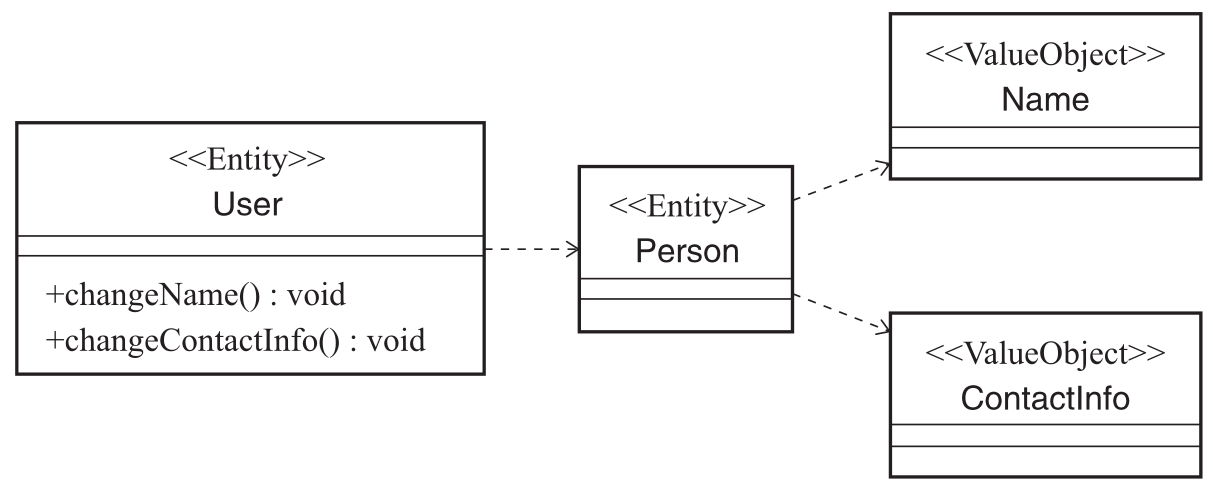
图2-11 从User属性中分离实体和值对象
(4)构建整体业务概念
通过以上分析,我们发现从通用语言出发,围绕User概念所提取出来的实体和值对象有多个,其中User和Person代表两个实体,User包含Person实体和UserId值对象,而Person则包含PersonId、Name和ContactInfo值对象。完整的实体和值对象提取结果如图2-12所示。
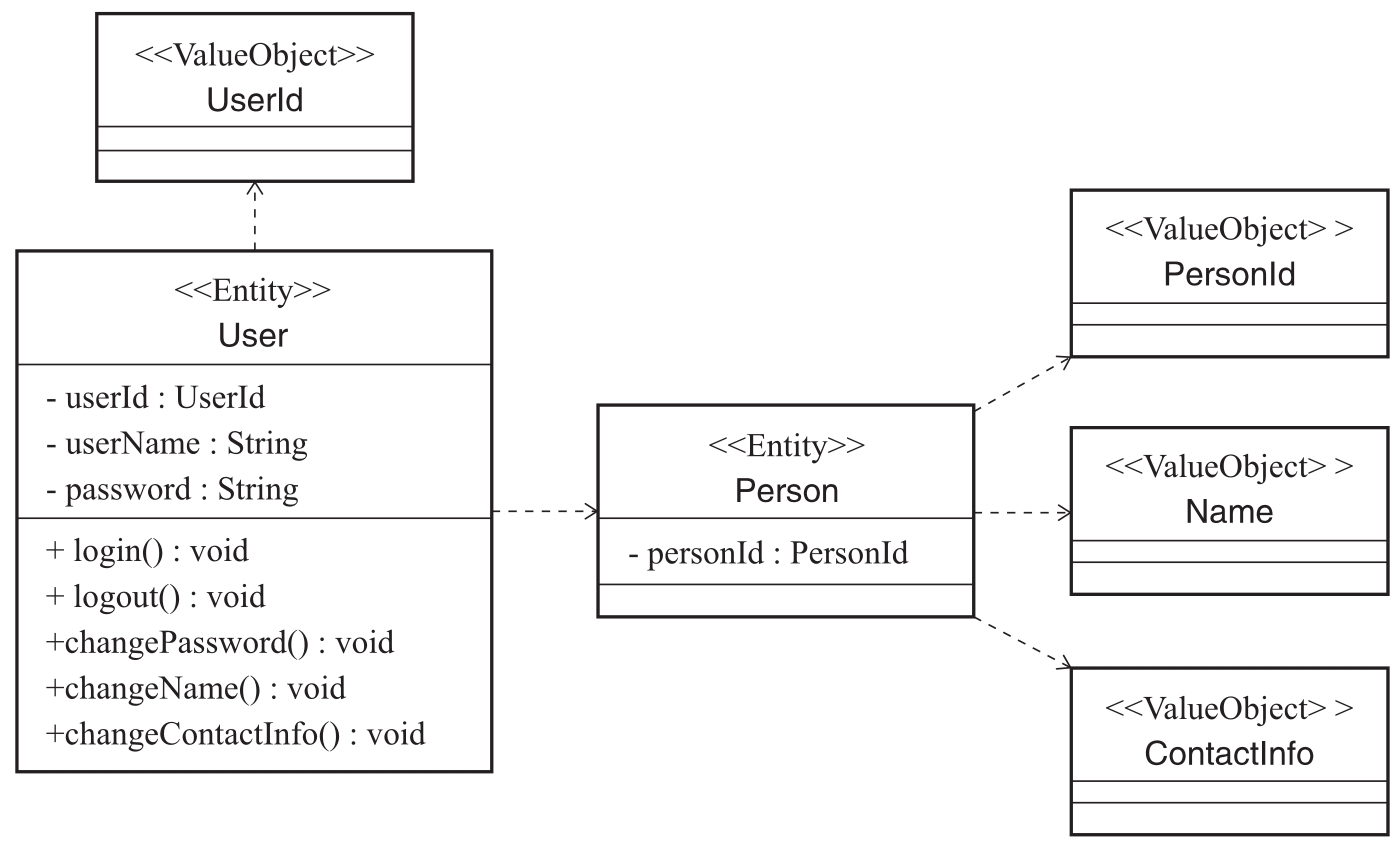
图2-12 完整的与User相关的实体和值对象
在本节最后,我们再来总结一下实体和值对象的区别。从唯一性的角度看,实体有唯一标识,值对象则没有,不存在“这个值对象”或“那个值对象”的说法。从是否可变的角度看,实体是可变的,值对象是只读的。另外,实体具有生命周期,而值对象则无生命周期可言,因为值对象代表的只是一个值,需要依附于某个具体实体。
在DDD中,聚合可以说是最核心的一种领域模型对象。聚合概念的提出与软件复杂度有直接关联。通常,一个系统中的对象之间都会存在比较复杂的交互关系,图2-13展示了系统具有8个对象时各对象之间的交互示意图。
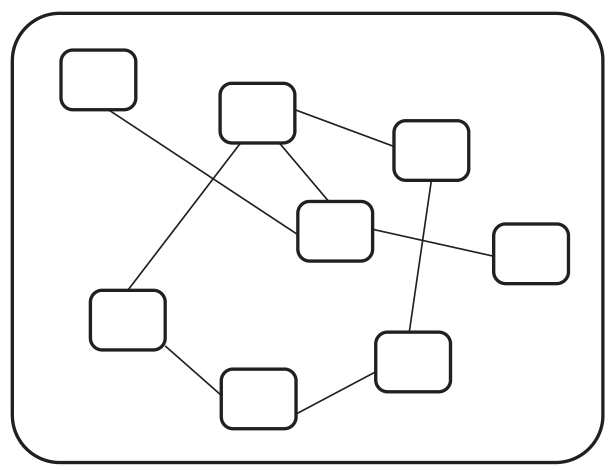
图2-13 对象交互示意图
从图2-13中可以看出,原则上这8个对象之间的交互方式最多可以达到2 8 -1种。为了降低对象交互所带来的复杂度,DDD引入了聚合的概念。那么,聚合是如何降低复杂度的呢?
1.聚合的设计思想
聚合的核心思想在于将领域对象的关联关系减至最少,这样就简化了对象之间的遍历过程,从而降低了系统的复杂度。聚合由两部分组成:聚合根,指聚合中的某一个特定实体;聚合边界,定义聚合内部包含的范围。
聚合代表一组相关对象的组合,是数据修改的最小单元,也就意味着对领域模型对象的修改只能通过聚合根实现,而不能通过组合中的任何实体直接修改。换句话说,只有聚合根的实体暴露了对外操作的入口,其他对象必须通过聚合内部的遍历才能进行访问,而删除操作也必须一次性删除聚合之内的所有对象。通过这种固定的规则,我们确保聚合内部的数据操作具有严格的事务性。
关于聚合,我们可以进一步看图2-14所示的聚合示意图。在这张图中,根据聚合思想把原有的8个对象划分成3个边界,每个边界包含一个聚合。我们可以看到与外部边界直接关联的就是聚合根,只有根对象之间才能直接交互,其他对象只能与该聚合中的根对象直接交互。
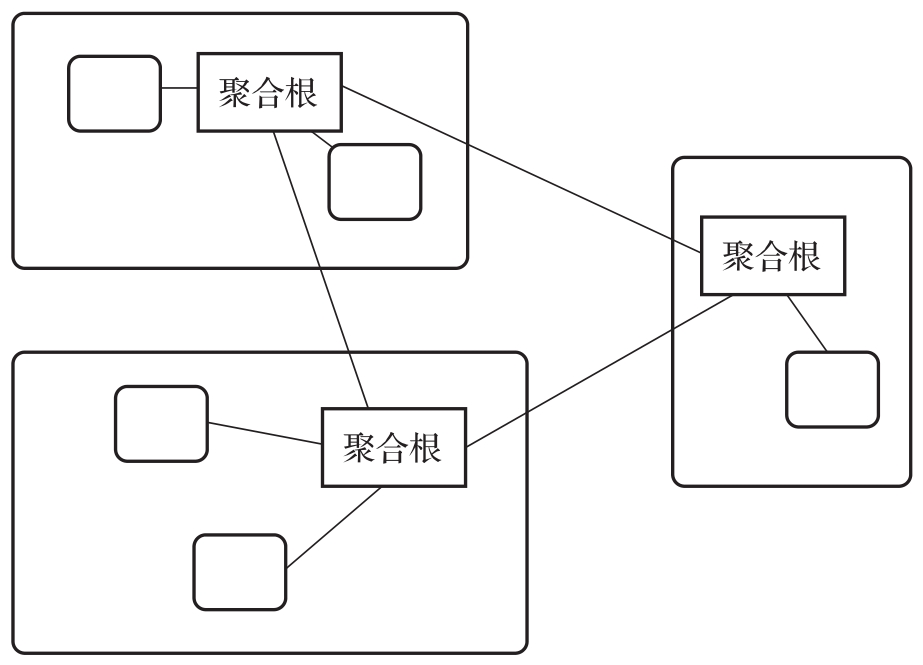
图2-14 聚合示意图
显然,以图2-14中的8个对象为例,通过聚合可以把对象之间最多2 8 -1次直接交互减少为2 3 -1次。
2.聚合建模
在本节中,我们同样通过一个典型的案例来解释聚合建模的实现过程。在日常开发过程中,我们通常都需要对业务功能(Feature)进行评审,然后通过拆分任务(Task)的方式完成工作量评估和排期(Schedule)。在这个业务场景中,一个业务功能可以创建很多个任务,同时需要制定一个排期。通过分析,我们可以识别Feature、Task、Schedule这3个主要实体或值对象。关于如何设计这些对象之间的关联,我们有几种思路。
如图2-15所示,这是一种基于聚合的建模方案,我们把Feature、Task、Schedule归为实体对象,并把Feature上升为聚合根对象。这样外部系统只能通过Feature对象访问Schedule和Task对象,而Feature中存在着对Schedule和Task的直接引用。
我们再来看另一种方案,我们把Task和Schedule同样上升到聚合级别,这意味着重新划分了系统边界,3个对象构成了3个不同的聚合。显然,这种情况下Feature对象包含对Task和Schedule的直接引用是不合适的。在不破坏现有实体关系的前提下,我们可以引入值对象来调整这种现象,通过把唯一标识提取成一个值对象FeatureId,Feature通过FeatureId与Task和Schedule对象进行关联,如图2-16所示。
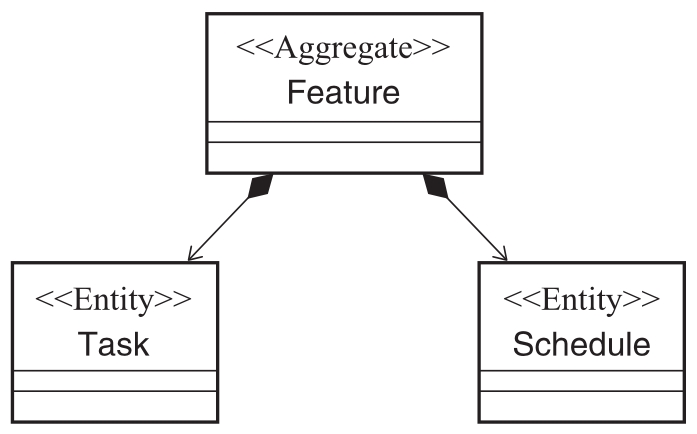
图2-15 聚合建模方案一
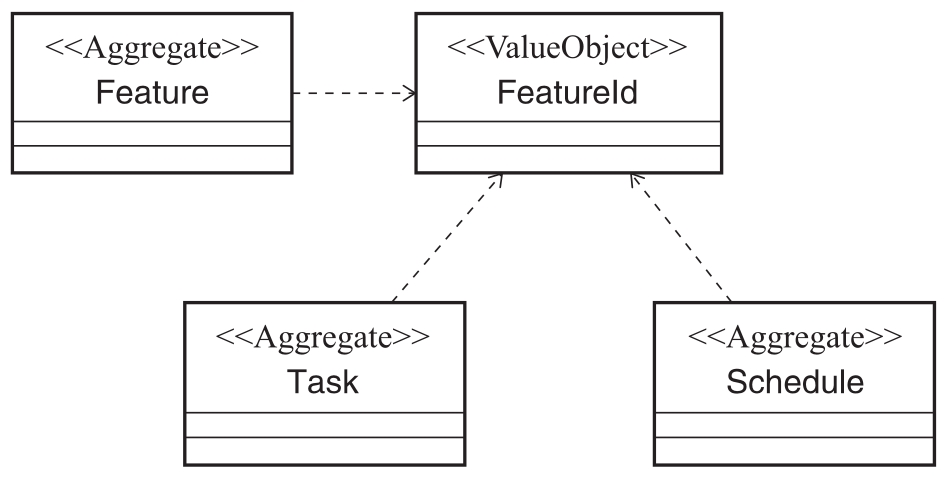
图2-16 聚合建模方案二
上述两种方案代表着两种极端。其中方案一中只有一个聚合,其他都是实体对象;而方案二则把这些对象都设计成聚合。这两种方案都不是最合理的,有如下3条聚合建模的原则可以帮我们找到其中存在的问题。
1)聚合内部真正的不变条件。第一条建模原则关注聚合内部建模真正的不变条件,即在一个事务中只修改一个聚合实例。如果一个事务内需要修改的内容处于不同聚合中,就要重新考虑聚合划分的边界和有效性。另外,聚合内部保持强一致性的同时,聚合之间需要保持最终一致性。
对应到上述案例中,因为系统的目的就是获取Feature的Schedule,而不是分别管理Feature和Schedule,也就是说更新Feature的同时应该更新Schedule,Feature和Schedule的更新处于同一个事务中,所以把Schedule放到以Feature为根实体的聚合中更加符合聚合建模的这一条原则。
2)设计小聚合。聚合可大可小,设计聚合大小的通用原则是考虑性能和可扩展性,我们倾向于使用小聚合。大聚合可以减少系统边界的数量,但聚合内部会包含更多实体和值对象。从性能角度讲,聚合内部复杂的对象管理和深层次的对象遍历会降低系统的性能,因为很多边界处理过程实际上并不会涉及很多聚合内部对象。而对于可扩展性,系统的变化对大聚合的影响显然大于小聚合。另外,考虑到实体具备生命周期和状态变化,聚合建模也推荐优先使用值对象来降低聚合内部复杂度。
3)通过唯一标识引用其他聚合。这条原则对聚合设计产生的影响在于:通过标识而非对象引用使多个聚合协同工作。聚合中的根实体应该具备唯一标识,我们在方案二中引入值对象FeatureId作为Feature的唯一标识,并通过该值对象与其他聚合中的根实体进行交互,这就是这条原则的具体体现。如果将Task对象作为一个根实体,一般会提取一个值对象TaskId作为其唯一标识。
综合运用上述3条聚合建模的原则之后,我们可以得到如图2-17所示的第三种聚合建模方案,这是我们对上述场景进行聚合建模的最终结果。
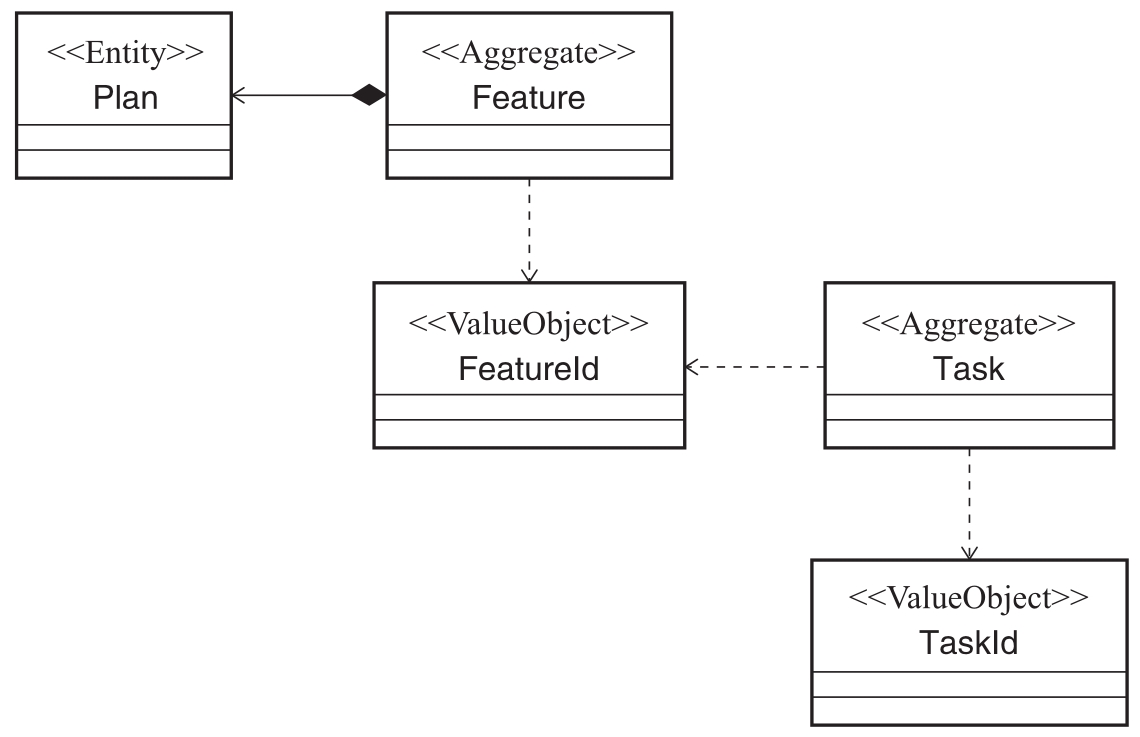
图2-17 聚合建模方案三