
下载掌阅APP,畅读海量书库
立即打开



人们常说:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”好的特征工程融合了专业领域知识、直觉和基本数学能力。在经典数据分析中,特征提取通常需要人工处理,特征提取通常花费60%的时间,特征库或自动特征工程等手段将大大提升数据分析效率。深度学习在一定程度上避免人工加工特征,很适合天然具有层次结构的数据(如图像、时间序列),例如,卷积神经网络(CNN)通过多个层次的卷积操作,抽取不同时空粒度上的特征,在使用循环神经网络(RNN)算法提取序列模式特征时,通过状态和门限函数等机制保证变化的局部性。在深度学习中通过参数共享(Parameter Sharing,假设局部性结构是全局共享的)等稀疏性机制防止过拟合。但深度学习结构较少关注变量间的非线性交互,另外,网络结构蕴含的结构特征可解释性不好。因此,在很多数据分析中,特征工程仍然是一项重要的工作。
特征工程包括特征提取、特征选择两项工作。特征提取指的是手工或自动将原始变量转换为一组有业务/统计意义的特征变量;特征选择是从特征变量集合中挑选一组与分析问题相关的特征子集,达到降维的效果。本节重点讨论自动特征提取算法,包括针对特定数据类型(时序、序列、文本、图像等)的自动特征提取、根据实体(数据框)间的关联关系[如基数(cardinality)]的自动特征提取,以及多个变量间的组合运算。
1.连续变量
连续变量通常需要做预处理,广义上也可以视为特征提取,主要包括以下4种。
1)归一化特征:很多学习算法假设数据符合正态分布,另外不同变量间数值相差太大在误差计算或数值计算的时候容易误导,归一化是通常的做法,包括中心化/标准化、区间化(如Min-Max)、数据变换消除偏度(如Box-Cox变换)。R的caret包提供了preProcess、BoxCoxTrans等函数。
2)离散化/分箱:将数值型属性转换成类别变量,降低信息量,减少噪声对算法的干扰。可以根据数值分布的分位数划分区间,也可以根据领域知识划分区间。对于多个变量,可以采用聚类的方法进行离散化。
3)降维特征:采用PCA、ICA等方法提取主成分或独立成分,新的组分可以视为特征变量,降低预测量间的多重共线性,也可以采用RBM、AutoEncoder等算法进行降维。
4)非线性特征:对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。或者通过引入核函数,隐性地引入非线性关系。
2.类别变量
不少机器学习算法只接受连续变量,这时候需要把类别变量转化为定量变量,有两种常见方式。
1)独热(One-hot)编码方式:类似于转换成哑变量,假设有 N 种定性值,则将这一个定量变量扩展为 N 维0/1特征,当原始特征值为第 i 种定性值时,第 i 个扩展特征赋值为1,其他扩展特征赋值为0。独热编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用独热编码后的特征可达到非线性的效果。
从直觉的角度,可能会觉得独热方式太繁琐(因为编码大量地增加了数据集的维度),不如根据唯一值直接用整数编号方便。例如颜色属性{红,绿,蓝}分别用{1,2,3}表示。但直接编号存在一些潜在问题,整数变量默认有序、距离、线性关系等性质,而原始的类别变量不一定具有该性质。例如,根据整数距离性质,|1-3|>|1-2|,在前面的编号下就意味着红色和绿色比和蓝色更“相似”,这可能会误导算法模型。更糟糕的情况是线性运算,红色和蓝色均值是2,也就是绿色的意思,通常是不合理的。
2)嵌入(Embedding)表示方式:将一个或多个类别变量(组合通常非常大)用一个低维的连续向量来表示,同时变换后的记录间的关系(例如相似度)与原始记录保持高度一致,也就是说,保持原来的拓扑结构。Embedding一词来源于拓扑,表示实际数据是低维Manifold(流形)嵌入与原始变量构成的高维空间中,在实际应用中,这个概念被放宽了,很多高维连续变量映射为低维流形的特征向量也被称为Embedding。嵌入式表示有时候也称为分布式表示,独热表示中,每行向量中只有一个维度为1,其余全部为0,而嵌入式向量通常所有维度均非零。例如,在颜色表示时,假若存在很多种不同的中间颜色,独热表示就不再适用(需要的维度太高),这时候可以用一个3维的嵌入式向量表示,向量间的距离表示颜色间的不相似度。颜色的例子仅仅是为了更好理解嵌入式表示的概念(其实RGB值就是一个很好的表示,不用嵌入式也可以很好表征),单词的嵌入式表示就没有那么直观了,单词的嵌入式主要是根据词与词间的共现或上下文关系来获得各个词对应的特征向量,特征向量间的距离表示了词的不相似度。
对于类别变量,也有不少特征提取策略。
1)交叉特征:两个或更多的类别属性组合成一个,组合的特征有时比单个特征更显著。假如类别变量A有两个可能值{A1,A2},类别变量B存在{B1,B2}等可能值,A与B之间的交叉特征包括{(A1,B1),(A1,B2),(A2,B1),(A2,B2)}。
2)频繁模式:把频繁模式作为特征,根据频繁分析结果,对频繁模式项是否出现、频繁模式项编码等特征量进行加工。
3.时间戳变量
时间戳属性包含年、月、日、小时、分钟、秒等信息,但是在很多的应用中,大量的信息是不需要的,仅需要保留小时、日、月等需要的颗粒度,这依赖于领域知识,例如在城市车流量预测中,星期几、时间段是典型的周期性。
对于连续变量、类别变量、时间戳等基础变量,Zheng [21] 有很多讨论,感兴趣可以进一步阅读了解。
4.复杂类型
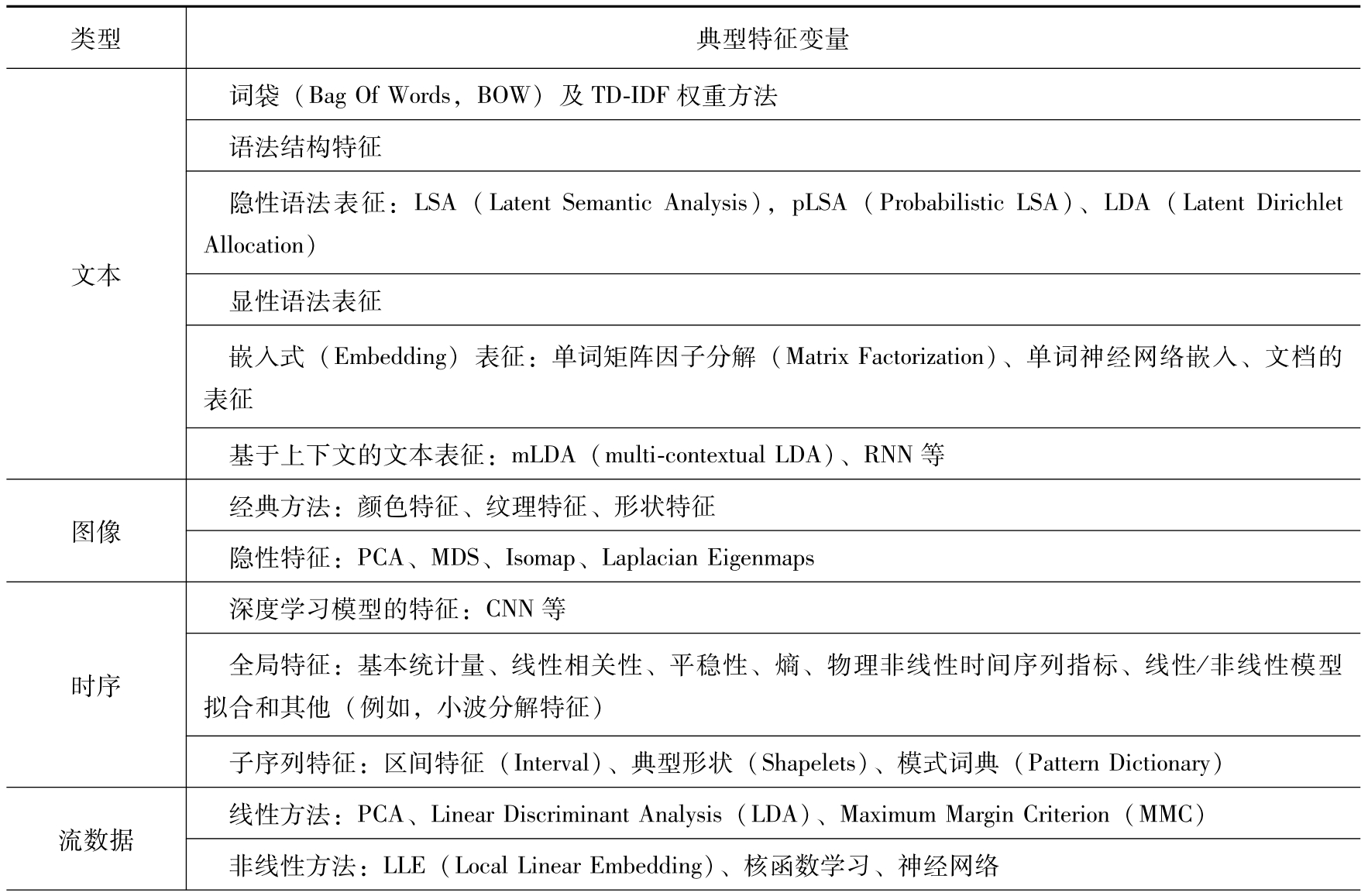
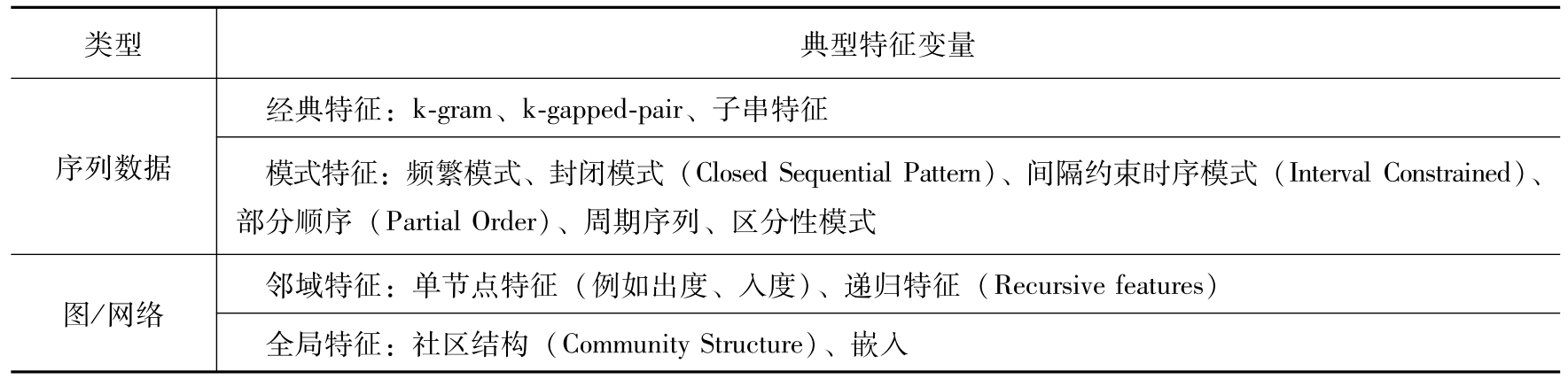
Dong、Liu主编的图书 Feature engineering for machine learning and data analytics [22] 中按照数据类型、通用算法、领域应用三个维度对特征工程技术进行了论述。在数据类型中,文本、图像、时序、流数据、序列数据(Sequential Data)、图/网络等6类数据常见特征见表2-6。Duboue [23] 对图数据、带时间戳数据、文本数据、图像数据、视频、GIS等数据的特征提取也有很好的介绍和案例分析。
表2-6 6类数据常见特征
(续)
领域模型中不同对象间的关系及数据记录(Record)间的关系也可以用来自动生成特征。在参考文献[24]中讨论过,对象间主要关心特征生成的连接关系,即1∶1、1∶ n 、 n ∶1、1∶{0,…, n }的关系(但不能存在 n ∶ m 的关系),可以从UML、ER等形式化模型中提取。
Featuretools [25] 是一个可以自动进行特征工程的python库,主要原理是针对多个数据表以及它们之间的关系,通过转换(Transformation)和聚合(Aggregation)操作自动生成新的特征。转换操作的对象是单一数据表的一列或多列(例如对某列取绝对值或者计算两列之差);聚合操作的对象是具有父子(one-to-many)关系的两个数据表,通过对父表的某列进行归类(groupby)计算子表某列对应的统计值。函数的输入信息包括各个实体表(数据框)的信息、各个实体间的父子关系(及其对应的外键字段)、目标实体(待加工特征的实体)等三类信息。
在工具内置的客户(customers)画像特征例子中,包括4个数据实体,一个客户可能有多个会话(sessions),一个会话中可能涉及多个产品交易项(transactions),一个交易项目涉及一个产品(products),在这样的结构下,客户的特征可以是会话的数量、终端设备的种类数、平均会话时间、交易的笔数、不同类产品的购买量等变量,如图2-17所示。
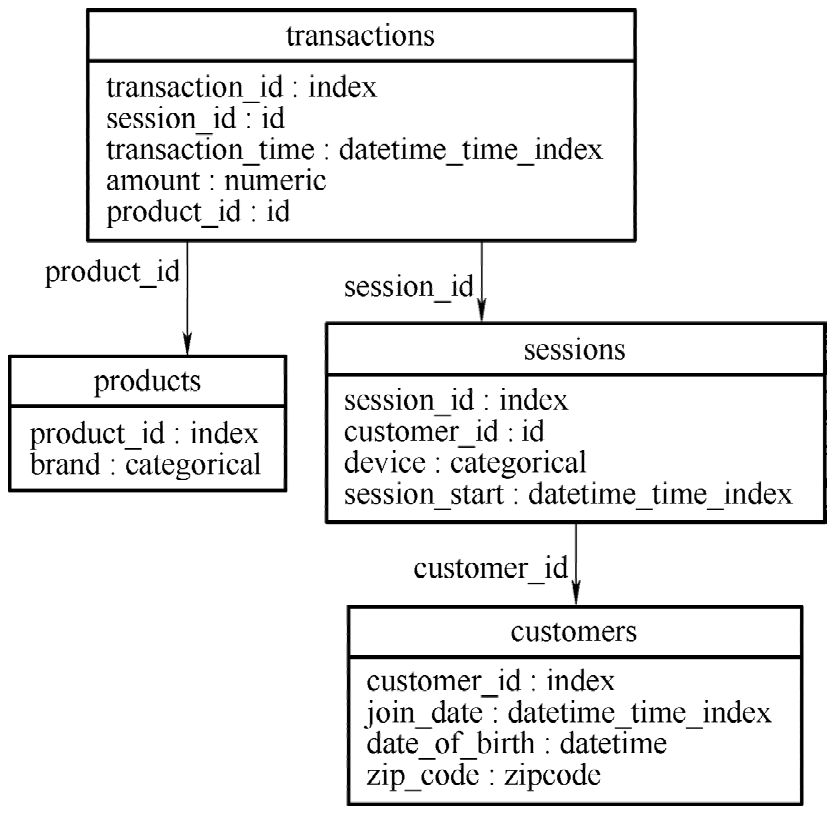
图2-17 客户订单模型示例
除了数据表之间的关系,记录间的关系也可以用来提取特征。记录间的关系主要包括集合(set)关系(记录间是独立的)、序(sequence)关系(需要指定sequence字段)、层次关系(如地理区域)等。通过这些关系,可以自动生成跨对象特征(如3个给水回路中平均压力最高的回路的水流量趋势)或数据结构特征(如对于水流量等时序变量,加工不同时间粒度的趋势特征)。这样可以把很多结构性先验知识(并且在其他领域存在了很多年)以半自动化形式融入机器学习,加速机器学习的效率。
在工业应用中,有不少分析问题需要考虑多个变量间的交互,而这些可能的交互方式由先验知识提供。通过上下文无关语法树(Context-Free Grammars,CFG)描述可能的组合关系,采用遗传算法进行语法树的推导和演化。
R里面有gramEvol包 [26] 提供了语法树的定义方法,以及根据语法树生成表达式的能力,还提供了每个表达式适应度评价函数的接口,这样以实现了语法演化(Grammatical Evolution,GE)。在遗传算法中,语法树的每条推导路径(即衍生特征变量)对应着一个基因,其适应度评价和一般的特征选择相同,有3种方式:①根据评价指标(如相关性、信息增益、Relief Score等)直接筛选;②根据学习算法的最终性能进行选择;③由学习算法的内嵌式特征选择机制决定,如SVM算法本身就会惩罚特征复杂度。
CFG限定了可能的变量组合形式和深度。例如对于时序变量,CFG表达式由基础变量、表达式和操作符3部分组成,时序特征变量生成框架如图2-18所示。基础变量为原始变量或特征库提供的领域特征变量,表达式是层次性的,是基础变量或表达式通过操作符运算的结果。操作符分为3类:①针对单个变量的操作符,如log等非线性操作;②单变量的序列特征操作符,如滑动平滑;③变量间组合操作符,如风电机组3个桨距角的相对误差。
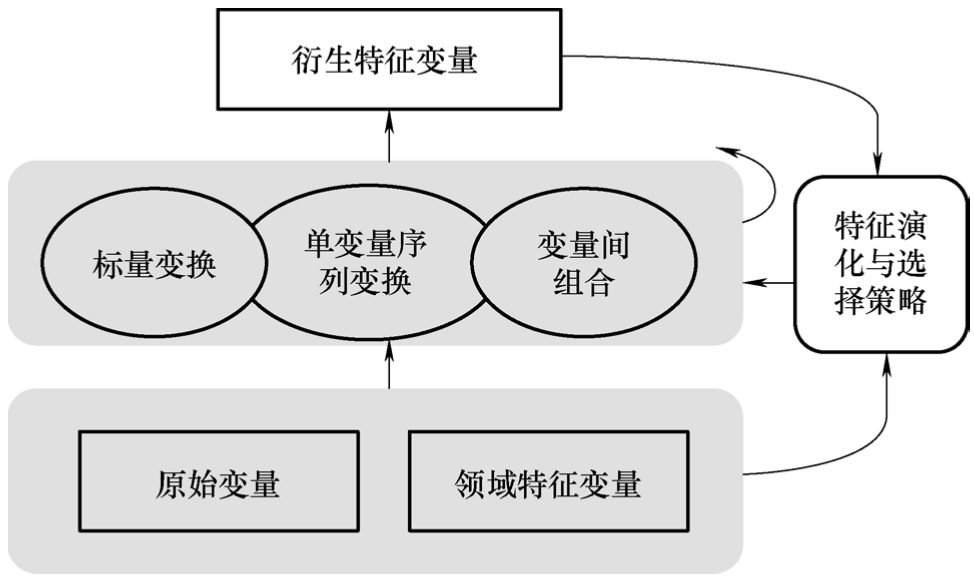
图2-18 时序特征变量生成框架
以压缩机能耗计算为例,根据领域经验,能耗可能与进出口压力差(绝对值、相对值)、进出口温度差、工作强度(压力与工作时间乘积)等衍生变量密切相关,构建特征语法树如下所示。
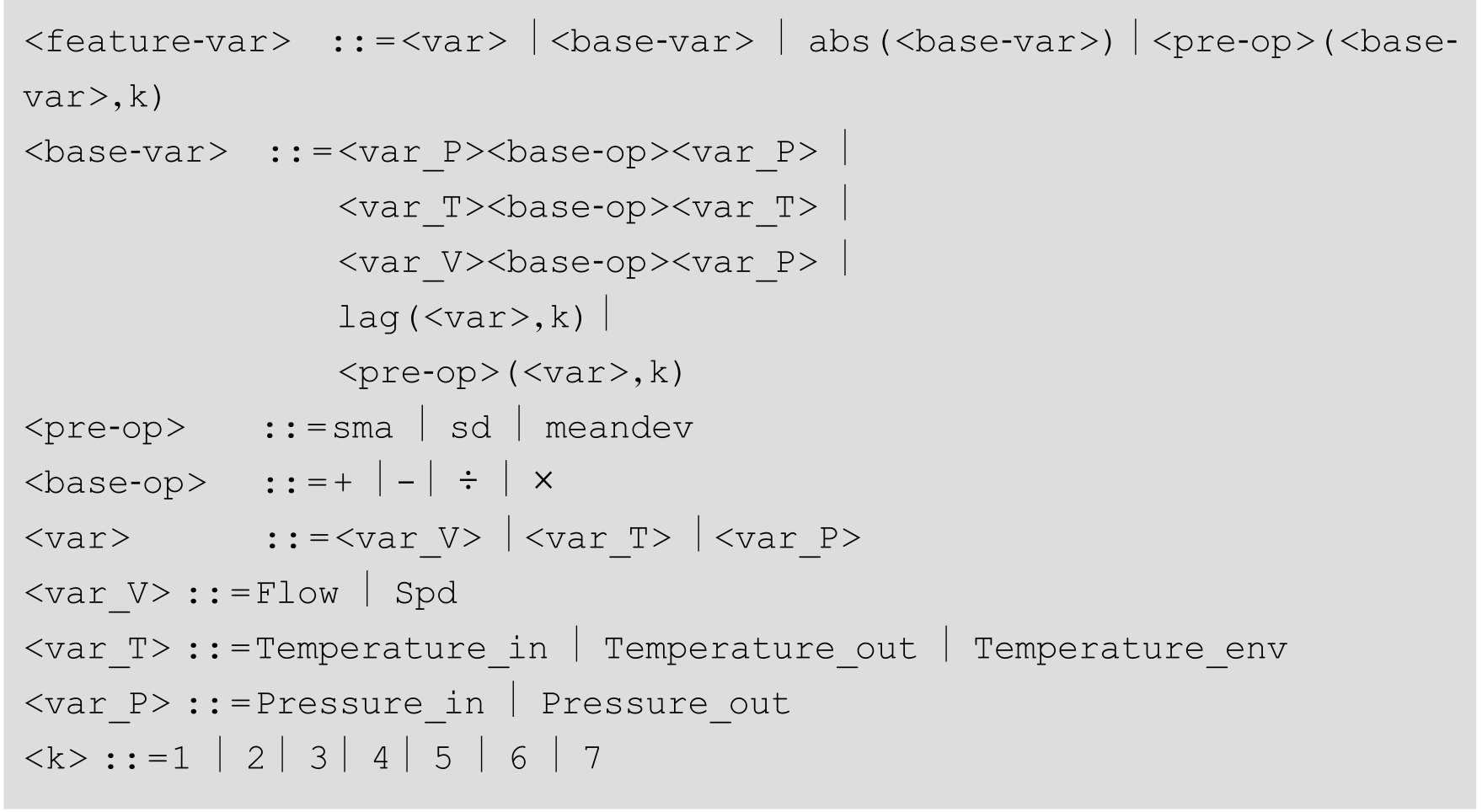
基于此语法,可以生成很多特征变量,例如,进口压力的5阶平滑sma(Pressure_in,5)、进出口压力的方差sd(Pressure_out-Pressure_in)、Flow/Pressure_in等特征量,基于历史数据集,可以挑选与能耗相关度高的特征表达式。