
下载掌阅APP,畅读海量书库
立即打开



在2.2节中,我们介绍了基于词向量的离散表示方法,这些都是基于统计的模型实现词向量的表示。词向量离散表示的优点是实现简单,缺点是无法衡量词向量之间的关系,同时词表维度也会随着语料库的增加而膨胀,进而导致数据稀疏问题。
我们希望相似的词和词在数据分布上也是相似的。“橘子”“香蕉”“苹果”都是水果,它们的向量表示应该相似。在自然语言处理的研究中,研究人员通常有一个共识:可以使用一个单词的上下文来了解这个单词的语义,比如:
(1)“苹果手机质量很好,但是价格太贵了。”
(2)“这个苹果很好吃,又脆又甜。”
(3)“黑莓质量也还行,但是不如苹果支持的应用多。”
在上面的三个句子中,我们通过上下文可以推断出第一个“苹果”指的是手机品牌,第二个“苹果”指的是水果,而第三个“苹果”指的应该也是手机品牌。
事实上,在自然语言处理领域,使用上下文描述一个词语或元素的语义是一个常见且有效的做法。我们可以使用同样的方式训练词向量,让这些词向量具备表示语义信息的能力。这是词向量分布式表示的核心思想,常见的算法有神经网络语言模型、连续词袋模型和Skip-Gram模型。
语言模型(Language Model,LM)旨在为语句的联合概率函数 p ( w 1 , w 2 ,…, w T )建模,其中 w T 表示句子中的第 T 个词。语言模型的目标是计算某个句子出现的概率。对语言模型的目标概率来说,假设文本中每个词都是相互独立的,则整句话的联合概率可以表示其中所有词语条件概率的乘积,即:

然而在实际情况中,每个词语出现的概率都与其前面的词紧密相关,所以实际上通常用条件概率表示语言模型,对于一个由 T 个词按顺序构成的句子,其联合概率可以表示为:
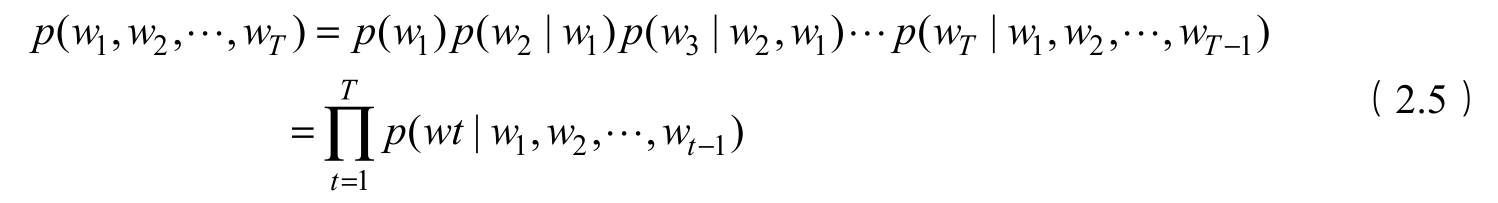
神经网络语言模型(Nerual Network Language Model,NNLM)直接从语言模型出发,NNLM直接通过一个神经网络结构对 n 元条件概率进行评估,NNLM的网络结构如图2.4所示。
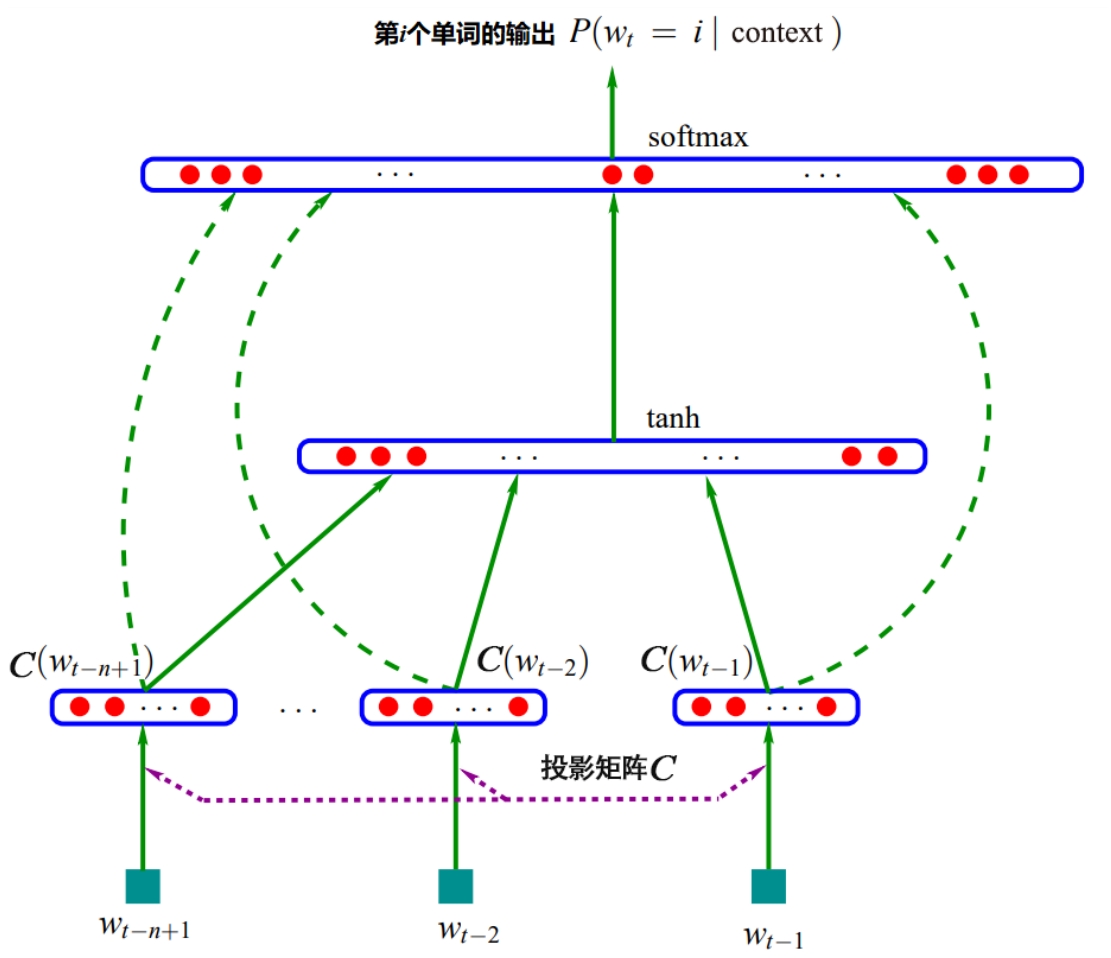
图2.4 NNLM的网络结构
从图2.4中可以看出,NNLM的网络结构包括输入层、投影层、隐藏层和输出层。输入层是前 t -1个单词的索引表示,通常可以用独热编码表示;投影层用 V × D 的投影矩阵 C 表示, V 表示语料库中单词的个数, D 表示稠密词向量的维度;隐藏层用tanh激活函数表示;输出层使用softmax激活函数表示,NNLM的目标是根据前面 t -1个单词预测第 t 个单词的概率。通过对NNLM进行训练,我们可以得到投影矩阵 C ,它就是语料库中每个单词的稠密向量表示,其中稠密词向量的维度 D 是一个超参数,训练时可以自行设置。
Mikolov等人在2013年提出的Word2vec算法就是通过上下文来学习语义信息。Word2vec包含两个经典的模型,即CBOW(Continuous Bag-Of-Words)和Skip-Gram,CBOW和Skip-Gram语义学习示意图如图2.5所示。
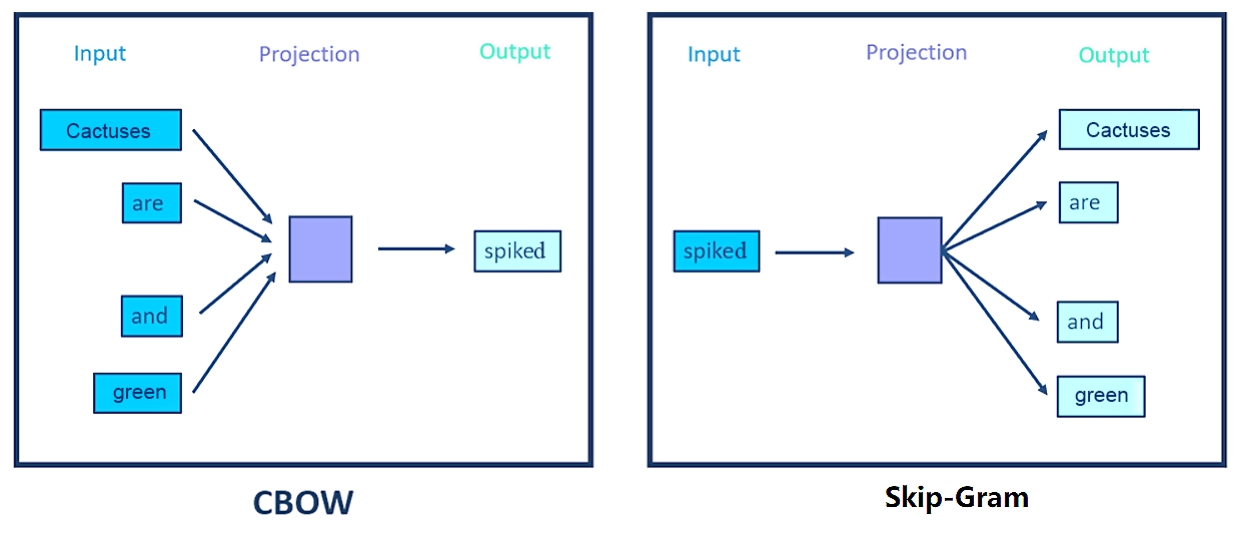
图2.5 CBOW和Skip-Gram语义学习示意图
(1)CBOW通过上下文的词向量预测中心词。
(2)Skip-Gram根据中心词预测上下文。
假设有一个句子“Cactuses are spiked and green”,上述两个模型对此句的预测方式如下。
(1)在CBOW中,首先需要在句子中选定一个中心词,并把其他词作为这个中心词的上下文。如图2.5中的CBOW所示,把“spiked”作为中心词,则“Cactuses are and green”就作为中心词的上下文。在学习过程中,使用上下文的词向量去预测中心词,这样中心词的语义信息就被记录到上下文的词向量中,如“spiked→cactuses”,从而达到学习语义信息的目的。
(2)在Skip-Gram中,同样先选定一个中心词,并把其他词作为这个中心词的上下文。如图2.5中的Skip-Gram所示,把“spiked”作为中心词,把“Cactuses are and green”作为中心词的上下文。与CBOW不同的是,Skip-Gram在学习过程中,是使用中心词去预测上下文的内容的,从而达到学习语义信息的目的。
CBOW和Skip-Gram本质上是一种神经网络,包括输入层、隐含层和输出层3层网络结构。接下来我们对它们的网络结构进行详细介绍。
假设指定一个句子:“Cactuses are spiked and green, C =4, V =5000, N =128”。CBOW的网络结构图如图2.6所示,CBOW是一个具有3层结构的神经网络,它们分别如下。
(1)输入层:一个形状为 C × V 的独热矩阵,其中 C 代表上下文中词的个数,通常是一个偶数; V 表示词表大小,该矩阵的每一行都是一个上下文词的独热向量表示,比如“Cactuses,are,and,green”。
(2)隐藏层:一个形状为 V × N 的参数矩阵 W ,一般称为词向量, N 表示每个词的向量表示长度。输入矩阵和参数矩阵 W 相乘就会得到一个形状为 C × N 的矩阵。综合考虑上下文中所有词的信息去预测中心词,因此将上下文中 C 个词相加得一个1× N 的向量,这是整个上下文的一个隐含表示。
图2.6 CBOW的网络结构图
(3)输出层:创建另一个形状为 N × V 的参数矩阵,将隐藏层得到的1× N 的向量乘以该 N × V 的参数矩阵,得到了一个形状为1× V 的向量。最终,1× V 的向量代表了使用上下文去预测中心词,每个候选词的打分,再经过softmax函数的归一化,即得到了对中心词的预测概率:
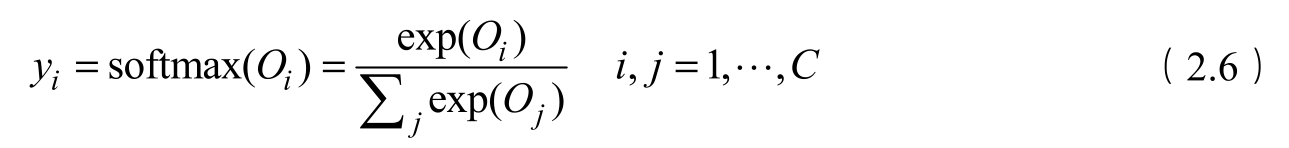
式(2.6)中 O i 表示第 i 个节点的输出值; O j 表示第 j 个节点的输出值; C 表示类别的个数; y i 表示预测对象属于第 C 类的概率,这是CBOW算法的实现过程。
接下来我们看Skip-Gram的算法实现。Skip-Gram同样是一个具有3层结构的神经网络,其网络结构图如图2.7所示。
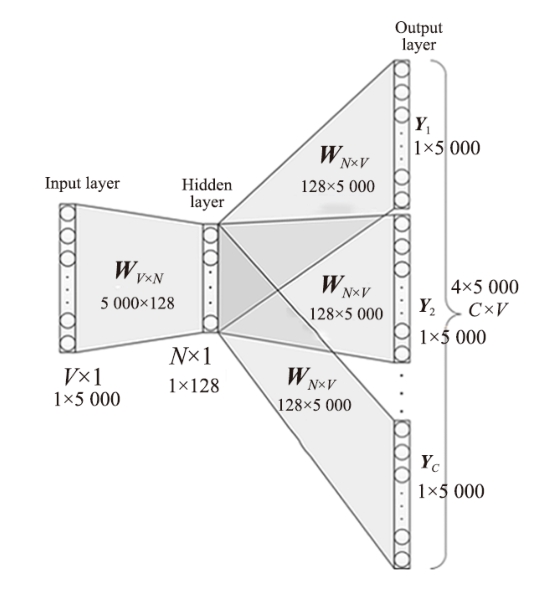
图2.7 Skip-Gram的网络结构图
(1)输入层:接收一个独热矩阵 V ∈ R 1× V 作为网络的输入,里面存储着当前句子中心词的独热表示,其中 V 表示词表的大小。
(2)隐藏层:将张量 V 乘以一个词向量矩阵 W 1 ∈ R V × N ,并把结果作为隐藏层输出,得到一个形状为 R 1× N 的矩阵,里面存储着当前句子中心词的词向量。
(3)输出层:将隐藏层的结果乘以另一个词向量矩阵 W 2 ∈ R N × V ,得到一个形状为 R 1× V 的矩阵。这个矩阵经过softmax函数归一化后,就得到了用当前中心词对上下文的预测结果。根据这个softmax函数归一化的结果,我们就可以去训练词向量模型。
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右依次扫描当前的句子。每个扫描出来的片段都被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
1.实验目标
(1)了解中文词向量数据预处理的步骤。
(2)理解中文词向量的训练过程。
(3)掌握gensim训练中文词向量的方法。
2.实验环境
中文词向量的实验环境如表2.5所示。
表2.5 中文词向量的实验环境

3.实验步骤
该项目主要由4个代码文件组成,分别为process_wiki_data.py、seg.py、train_word2vec_model.py和gensim_test.py,它们的具体功能如下。
(1)process_wiki_data.py:数据预处理,解析XML文件,将XML的维基数据转换为文本文件。
(2)seg.py:分词文件,将解析后的文本文件进行分词。
(3)train_word2vec_model.py:模型训练,调用gensim工具训练词向量。
(4)gensim_test.py:使用模型,查看训练词向量的结果。
首先创建项目工程目录Word2vec_model,在Word2vec_model目录下创建process_wiki_data.py、seg.py、train_word2vec_model.py和gensim_test.py源码文件。中文词向量训练目录结构如图2.8所示。

图2.8 中文词向量训练目录结构
按照如下步骤分别编写代码。
(1)编写process_wiki_data.py,将数据集articles.xml.bz2解析为wiki.zh.text文本分文件。
步骤一:导入模块

步骤二:XML文件解析及主函数处理

步骤三:运行代码
使用如下命令运行实验代码。

通过执行上述代码,文件夹下会生成wiki.zh.text文本文件(见图2.9)。

图2.9 生成wiki.zh.text文本文件
(2)编写seg.py,将生成的wiki.zh.text文本文件进行分词,生成wiki.zh.text.seg文件。
步骤一:导入模块

步骤二:编写process_wikt_text函数实现分词,并将分词结果保存
步骤三:主函数处理

步骤四:运行代码
使用如下命令运行实验代码。

通过执行上述代码,文件夹下会生成wiki.zh.text.seg文本文件(见图2.10)。
图2.10 生成分词文件wiki.zh.text.seg文件
(3)编写train_word2vec_model.py,训练中文词向量。
步骤一:导入模块

步骤二:训练词向量及处理主函数
步骤三:运行代码
使用如下命令运行实验代码。

通过执行上述代码,文件夹下会生成模型文件wiki.zh.text.model和权重文件wiki.zh.text.vector(见图2.11)。
(4)编写gensim_test.py,查看词向量结果。

图2.11 模型文件wiki.zh.text.model和权重文件wiki.zh.text.vector
步骤一:导入模块,加载训练好的模型

步骤二:查看前5个单词的词向量

步骤三:查看“语言学”最接近的10个单词

步骤四:运行代码
使用如下命令运行实验代码。

通过执行上述代码,在控制台输出内容如下所示:
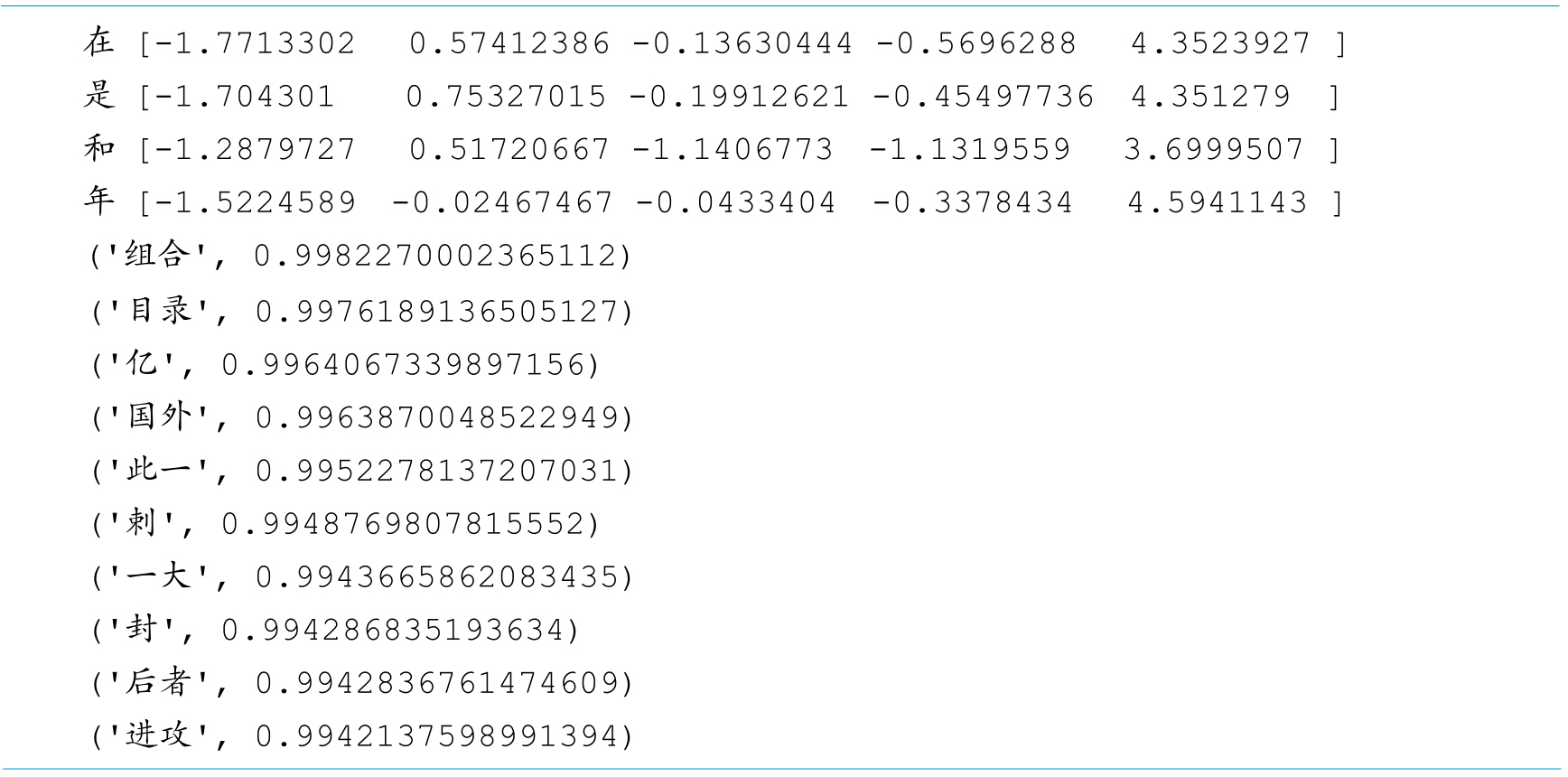
4.实验小结
从运行结果可以看出,我们使用gensim可以很方便地训练中文词向量,并且可以通过Word2vec的load函数加载训练好的词向量,并查看词向量的结果。