
下载掌阅APP,畅读海量书库
立即打开



在密码学中,杂凑算法也称杂凑函数或哈希函数,是指将计算给定消息的摘要,用作检验数据的完整性的同一类密码算法。这类算法的主要特点是 把任意长的输入消息串变化成固定长的输出串 ,而对原消息的任何微小的修改都能造成完全不同的摘要值结果,找到两个生成完全一样摘要值的不同消息是非常困难的。
国际标准中常见的杂凑算法有MD5消息摘要算法、SHA-1安全哈希算法等。出于安全考虑,这两种算法现在已经不再被推荐使用,并逐步被SHA-2和SM3等更安全的算法替代。杂凑算法的设计原理和构造方式基本相同,目前很多信息系统还未完成新旧算法的更新替换,MD5等算法还在广泛使用。为便于读者了解并用好杂凑算法,下面对包括MD5、SHA-1等在内的杂凑算法的历史和原理进行介绍。
MD5和SHA-1、SHA-2算法都采用的M-D结构,其特点是先对数据进行分组,然后再压缩,由压缩函数进行一轮轮的循环,最后一个压缩结果就是最终杂凑值。我国商用密码算法推荐使用的SM3算法也采用的M-D结构,SM3算法在前文实践随机数的示例代码中已用到。
M-D架构是Merkle-Damgard结构的简称,它是非常常用的杂凑算法的构造方式。M-D架构首先对经过填充的信息进行均匀分组,然后把分组后的信息按照顺序进入压缩函数F。而压缩函数F先使用初始化向量进行初始化,结合第一个信息分组完成压缩,F的输出信息块和第二个信息块进行结合再输入F进行压缩,然后传递到下一次的分组信息,如此循环操作,最后一个压缩函数的结果将作为最终的杂凑值返回。杂凑原理示意如图3-1所示。
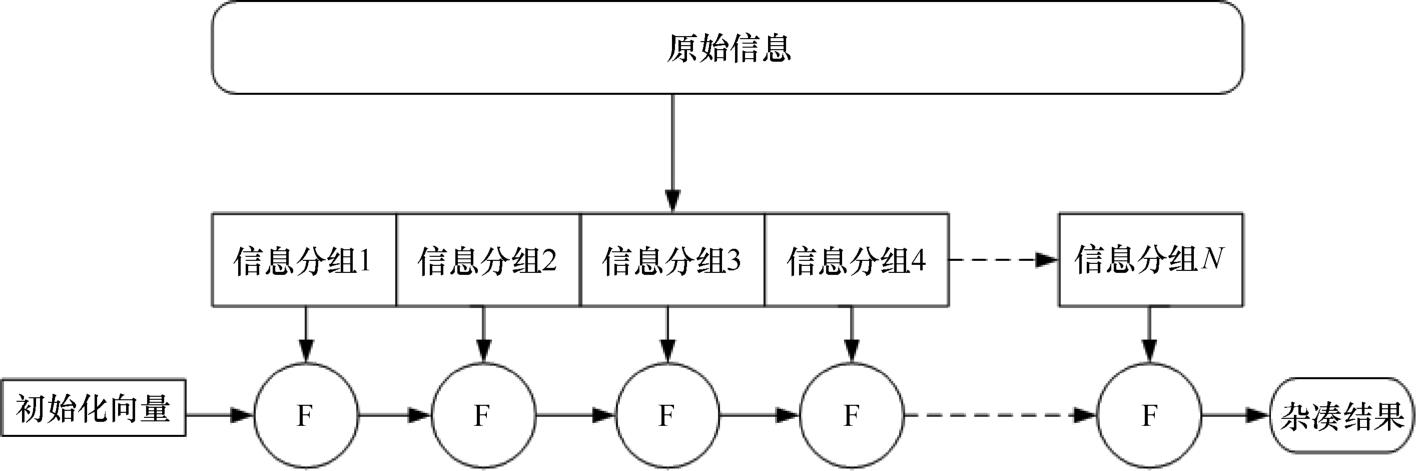
●图3-1 杂凑原理示意图
随着商用密码标准化和密评工作的推进,SM3算法必将成为我国应用系统中未来使用的主流杂凑算法。我们非常有必要深入了解SM3算法,并在项目的建设中用它实现完整性保护。由于第一个被广泛使用且影响面最大的是MD5算法,所以下面先从MD5算法开始分析。
MD5算法即消息摘要算法(Message-Digest Algorithm),是一种被广泛使用的密码杂凑函数,可以产生一个128位(16字节)的散列值(Hash Value),用于确保信息传输或存储的完整一致。MD5由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代MD4算法。这套算法的程序在RFC 1321标准中被加以规范。
MD5算法可以将不同长度的原始数据进行运算和压缩,生成统一的128位的散列结果,而且能保证原始数据的极小变化带来较大的散列结果的变化。MD5算法的原理可简要地叙述为:以512位分组来处理输入的信息,且每一分组又被划分为16个32位子信息分组,经过了一系列的处理后,算法的输出由4个32位分组组成,将这4个32位分组级联后生成一个128位的散列值。
MD5算法的杂凑函数原理上的确对应无数多个信息原文,但因为MD5杂凑结果是有限多个的,也就是说,杂凑一共有2 128 种可能结果,大概是3.4×10 38 个。读者可以思考,原文可以是无数多个,杂凑结果虽然很大但是有限多个,如果把世界上可以被用来进行杂凑的原文都杂凑一遍,肯定存在杂凑结果一样的原文,这就是杂凑的碰撞。但这同样是个根本不可能实现的任务,没有人能把所有的信息都杂凑一遍,计算和存储上均不可行。因此,以某种意义上来说,在算力和存储有限的情况下,想简单构建杂凑值与原文的一一对应关系也是不可能的任务。
但如果限制了MD5原文的长度和类别就会变得不一样。1996年后,MD5算法的缺陷在学术上被证实存在,而且可以针对其缺陷加以破解。2004年,我国著名密码学家王小云证实了MD5算法无法防止碰撞(Collision),并通过模差分比特分析法破解了该算法,因此它不再适用于安全性认证和完整性保证,SSL公开密钥认证或是数字签名等用途已经剔除了该算法。
在密评工作中如果发现有采用MD5杂凑算法来建设应用,将会被定为 高风险项 ,所以在项目建设中应该杜绝使用该算法。对于MD5算法只了解即可,对于需要杂凑算法保护的业务系统,一般建议使用其他杂凑算法。
安全散列算法(Secure Hash Algorithm,SHA)是被FIPS(联邦信息处理标准)认证的安全散列算法。作为美国的政府标准杂凑算法,SHA由美国国家安全局(NSA)所设计,由美国国家标准与技术研究院(NIST)发布。实际上,SHA是一个密码散列函数家族,目前包含5个算法实现,分别是SHA-1、SHA-224、SHA-256、SHA-384和SHA-512。通常将SHA-224、SHA-256、SHA-384和SHA-512并称为SHA-2系列算法。
SHA-1算法的杂凑结果比MD5算法的杂凑结果长32位,别小看这多出来的长度,它可以使得碰撞的概率下降为原来的几十亿分之一,是很惊人的。当然,SHA-1算法比MD5算法在性能上也有所下降,所以随后又推出几个杂凑值更长的变体算法,它们更安全。下面会给出更具体的介绍。
SHA-1在许多安全协定中被广泛使用,包括TLS、SSL、PGP、SSH、S/MIME和IPSec,曾被视为是MD5的后继者。但SHA-1的安全性被密码学家严重质疑,我国著名密码学家王小云于2005年公布了该算法的缺陷和攻击方法,宣布该算法已经不安全,SHA-1将要退出舞台。SHA-1可将一个最大2 64 位的信息原文转换成一串160位元的信息摘要。算法的架构采用的是M-D。SHA-1设计时基于和MD4相同的原理,并且模仿了MD4算法。2001年5月,NIST宣布FIPS180-2标准,SHA-1和SHA-2开始走入公众视野。
对于任意长度的原文,SHA-1首先对原文进行分组,使得每一组的长度为512位,然后对这些分组后的原文反复循环处理,使其通过32位的字操作。和MD5类似,SHA-1明文总长度是模512同余448,不足的则在明文后先填充一个1再填充足够的0,使得总长度达到448位,最后再串联上明文长度表示的64位,448+64=512位,即构造出512倍数的分组。具体原理细节这里不在展开,有兴趣的读者可以阅读密码学相关书籍。虽然算法名字叫作安全哈希算法,SHA-1却是密评中的 高风险算法 之一,在信息系统建设中,应该避免使用该算法。
SHA-2是SHA-1的升级版,该算法是由NSA和NIST两个机构在2001年提出的一个杂凑标准算法。虽然SHA-2和SHA -1都使用M-D架构,但SHA-2加入了很多的变化,增加了其安全性。SHA-2支持224、256、384、512四种密钥长度,目前还没有发现对SHA-2的有效攻击。在SHA-2四种杂凑长度的算法实现中,224长度算法并不在JCE内实现,但BC库已经提供了该长度算法的实现。2004年2月,NIST将SHA-224作为额外的算法加入到FIPS PUB 180-2的变更中,主要是为了符合双密钥DESEDE所需的密钥长度而专门定义,后面章节将会对DESEDE有更详细的讲解,这里读者只要知道DES算法密钥是56位,DESEDE密钥长度是112位即可,2×112=224,这并不是巧合,用哈希来产生安全密钥是很常用的做法。
SHA-256作为安全散列算法SHA-2算法的实现之一,其摘要长度为256位,即32字节。SHA-256算法在很多的数字证书应用中被采用,而且比特币挖矿算法中的杂凑算法也是SHA-256,研究区块链技术的人员更是无法避开SHA-256杂凑算法。
SHA-256与MD4、MD5以及SHA-1等杂凑算法的操作流程类似,原文在进行杂凑计算之前首先要进行两个步骤:首先对原文进行填充和分组,然后按顺序送入压缩函数中进行逐一运算。经过这两步之后输出定长的杂凑结果。
商用密码杂凑算法SM3标准于2012年被发布为行业标准,标准号是0004,具体名字为GM/T 0004—2012《SM3密码杂凑算法》,并于2016年升级为国家标准,具体名字为GB/T 32905—2016《信息安全技术SM3密码杂凑算法》。该算法于2018年10月被正式发布为国际标准算法。
SM3对输入的消息长度要求是不大于2 64 位。该算法的原文分组是512位,不足512位的,要在尾部根据一定的规则进行填充。分组之后要对每一个512位的分组进行扩展,经扩展后的数据再送入压缩函数中进行迭代。最后输出的一个压缩函数结果就是256位的杂凑值。
与MD5、SHA相同,SM3也是采用的M-D架构。但由于其设计更复杂,且新增了16步全异或操作、消息双字介入、对压缩函数也进行了安全提升、单次迭代过程中包含64轮压缩重复等特性,因此能够抵御目前已知的所有攻击方法,没有发现明显的安全弱点。在工程项目实现上,SM3具备算法效率高、使用灵活方便、跨平台实现兼容性好等特点,其安全强度和效率与SHA-256相当。特别是在PKI双证书要求支撑国密的情况下,SM3杂凑算法显得愈加重要。本书后面的实践中会重点讨论该算法。
在商用密码体系中,SM3主要用于数字签名及验证、消息认证码生成及验证、随机数生成等,其算法公开并国际化。建议在项目建设中采用杂凑算法SM3进行安全实现。
有关信息填充方法、初始化向量选择方法等SM3算法的原理细节,请参考GM/T 0004—2012《SM3密码杂凑算法》,本书不再展开。下面介绍杂凑算法实践。
本小节就通过编写代码来体现杂凑的结果。目前,主流的非密钥的杂凑算法有SHA-2和商用密码算法SM3,本节将对这两个算法进行实践。

作为目前使用最多、应用最广泛的杂凑算法,SHA-2系统在国际性的网站和跨国的电子证书系统等众多跨国性应用中使用。为了让读者在项目建设的过程中对密码算法的使用更加游刃有余,本书在此重点实践SHA-256算法。如果是跨境使用的信息化系统,可以继续采用SHA-256这类国际密码算法,但如果信息系统只在国内使用,建议用SM3算法进行替代。
(1)实现步骤
1)准备原始信息。先定义path字符串,选择一个文件路径;然后实例化一个FileInputStream对象,实例化对象后相当于打开了这个文件,进行读取准备;接下来构建DigestInputStream对象,包含两个参数,一个是前面的输入流对象,另一个是SHA-256的摘要对象。
2)输入原始信息。接下来的语句就是定义一个1024字节的缓存区(buffer),然后开始读取文件信息,正常情况下,read返回读取的字节数,当返回值是-1时表示文件的读取结束,退出读取循环操作,然后关闭流(dis)。
3)构建杂凑函数实例,执行杂凑运算。接下来通过调用dis对象的getMessageDigest()方法,返回实例化的对象MessageDigest。再通过它的digest()方法返回杂凑值的字节数组。
4)获取杂凑结果并输出。程序的最后三句在前面的示例实践过,就是把杂凑结果转换成十六进制并输出。
(2)实现代码

(3)结果输出

2014年,NIST发布了FIPS202的草案“SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions”。2015年8月5日,FIPS 202最终被NIST批准。所以SHA-3算法也已经正式推出。该系列有SHA3-224算法、SHA3-256算法、SHA3-384算法、SHA3-512算法、SHAKE128算法和SHAKE256算法等6个实现。和前面的SHA-1和SHA-2不同,SHA-3体系采用了“海绵”结构。
虽然SHA系列杂凑算法使用非常广泛,但其不是自主研发的算法。而SM3算法是由我国自主研发的商用密码杂凑算法。根据密评相关标准要求,建议我国信息化工程除了银行国际结算等有跨境互通需求的业务外,其余系统应采用SM3算法完成杂凑功能的实现与应用。下面实践商用密码杂凑SM3算法。

SM3算法是国家密码行业标准、国家标准和国际标准,目前已经在很多应用中开始使用。

SM3的实践示例代码与前面的SHA-256实践杂凑算法并没有太大的区别,这就是BC库封装的好处,少量修改代码就可以完成密码算法的替换。在JCA优秀的框架下,对算法细节进行了完美的封装,使得应用开发人员使用代码算法上能保持一致。
代码的开头两行是加载BC开源库到应用项目中。否则会出现不能发现算法SM3异常的情况。其他语句不再解释,和前面的例子语句一样。程序输出的结果如下。

从前面的运行结果输出可以看出,摘要的长度是32字节,即256位。由于SM3是我国推荐使用的算法之一,也是合规要求的标准算法。
在商用密码体系中,SM3被用于和SM2算法一起完成数字签名及验证签名、消息认证码生成及验证、随机数生成等,其算法是公开的,读者可以查找前面的标准文件了解细节。网络上也有不少算法代码实现,有C语言,也有Java语言。读者朋友有兴趣的可以下载代码研究。另外,GMSSL和BC都是非常好的学习的例子,强烈建议读者在有精力的情况下去阅读这两个开源加密包的代码,更能加深对算法的理解。
GMSSL是一个有历史来源的开源的密码工具集,使用C语言开发,从OpenSSL演变而来,支持商用密码的SM2/SM3/SM4/SM9/ZUC等算法,本部分的SM3算法在该开源库里面就有源码的实现。其网址是http://gmssl.org/。到2021年3月为止,OpenSSL 1.1.1版本之后也加入了SM2/SM3/SM4等算法。
本书并不想带领读者对算法本身进行深入分析,而重点在于带领读者使用密码算法完成项目建设中的安全需求,做到业务信息的机密性、完整性、真实性和不可否认性。下面再继续通过代码例子展示杂凑算法在HMAC等方面的实际应用。