
下载掌阅APP,畅读海量书库
立即打开



处理器依靠机器指令工作,但机器指令从形式上看都是一些没有规律的数字,难以书写、阅读和理解,这样就发明了汇编语言。本章的目标是:
1.进一步了解汇编语言的特点和“汇编”一词的由来;
2.学习如何创建汇编语言源程序;
3.下载NASM编译器,并学会用它来编译汇编语言源程序。
前面的章节里已经简单介绍过汇编语言及其产生的背景,所以我们知道,汇编语言提供了机器指令的人工可读形式,或者说助记形式,而且与机器指令是一一对应的。
另外,不同的处理器具有不同的指令集和指令的操作方式,并因此形成了不同的处理器架构,比如英特尔的x86架构和摩托罗拉68K架构。
因此,针对不同的处理器架构,汇编语言将提供不同的助记形式。实际上,即使是针对同一种处理器架构,也可能会有人使用本质上一样,但风格不同的助记形式。比如说,针对英特尔x86架构的处理器,就有AT&T和INTEL公司自己的风格。在本书中,我们将采用英特尔风格的汇编语言助记形式。
下面来看一下英特尔风格的汇编语言助记形式有什么特点。首先假设下面这些十六进制数字就是存放在内存中的8086机器指令:

对于大多数人来说,他们很难想象上面那一排数字对应着下面几条8086指令:

这就体现了使用汇编语言的好处。使用汇编语言,以上指令就可以写成:

对于那些有点英语基础的人来说,理解这些汇编语言指令并不困难。比如这句

首先,mov是move的简化形式,意思是“移动”或者“传送”。至于“ax”,很明显,指的就是寄存器AX。传送指令需要两个操作数,分别是目的操作数和源操作数,它们之间要用逗号隔开。在这里,AX是目的操作数,源操作数是3FH。汇编语言对指令的大小写没有特别的要求。所以,你完全可以这样写:

在很多高级语言中,如果要指示一个数是十六进制数,通常不采用在后面加“H”的做法,而是为它添加一个“0x”前缀,如

你可能想问一下,为什么会是这样,为什么会是“0x”?答案是不知道,不知道在什么时候,为什么就这样用了。这不得不让人怀疑,它肯定是一个非常随意的决定,并在以后形成了惯例。如果你知道确切的答案,不妨写封电子邮件告诉我。注意,为了方便,我们将在本书中采用这种形式。
在汇编语言中,使用十进制数是最自然的。因为3FH等于十进制数63,所以你可以直接这样写:

当然,如果你喜欢,也可以使用二进制数来这样写:

一定要看清楚,在那串“0”和“1”的组合后面,跟着字母“B”,以表明它是一个二进制数。
至于这句:

情况也是一样。add的意思是把一个数和另一个数相加。在这里,是把寄存器BX的内容和寄存器AX的内容相加。相加的结果在BX中,但AX的内容并不改变。
像上面那样,用汇编语言提供的符号书写的文本,叫作汇编语言源程序。为此,你需要一个字处理器软件,比如Windows记事本,来编辑这些内容。如图4-1所示,相信这些软件的使用都是你非常熟悉的。
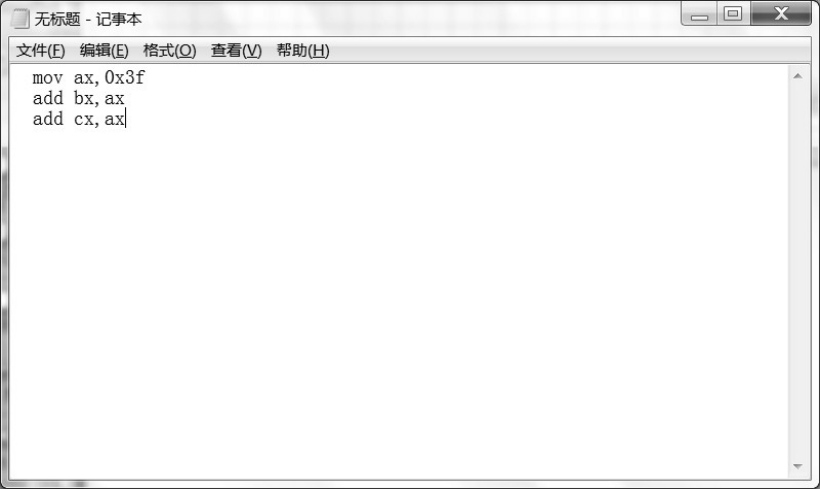
图4-1 用Windows记事本来书写汇编语言源程序
有了汇编语言所提供的符号,这只是方便了你自己。相反地,对人类来说通俗易懂的东西,处理器是无法识别的。所以,还需要将汇编语言源程序转换成机器指令,这个过程叫作编译(Compile)。在编译的时候,汇编语言编译器的作用是将mov、add、ax、bx等这些符号组合起来,转换成类似于数值的机器指令,这个过程叫作汇编,这就是汇编语言的由来,也有人称之为组合语言。
编译肯定还需要依靠一个软件,称为编译器,或编译软件。因为如果需要人类自己去做,还费这周折干嘛。另外,想想看,一个帮助人类生产软件的工具,自己居然也是一个软件,这很有意思。
从字处理器软件生成的是汇编语言源程序文件。编译软件的任务是读取这些文件,将那些符号转变成二进制形式的机器指令代码。它把这些机器指令代码存放到另一个文件中,叫作二进制文件或者可执行文件,比如Windows里以“.exe”为扩展名的文件,就是可执行文件。当需要用处理器执行的时候,再加载到内存里。
因为汇编语言的助记形式取决于处理器架构及不同的风格,这就需要与之配套的汇编语言编译器。同时,就算是同一款编译器,由于需要运行在不同的平台(比如Windows和Linux)上,也会有不同的版本。
现存的汇编语言编译器有多种,用得比较多的有MASM、FASM、TASM、AS86、GASM等,每种汇编器都有自己的特色和局限性,特别是有些还需要付费才能使用。不同于前面所列举的这些,在本书中,我们用的是另一款叫作NASM的汇编语言编译器。
NASM的全称是Netwide Assembler,它是可免费使用的开源软件。下面是它的官方网站,从这里可以找到它的帮助和开发文档、源代码,以及DOS、Linux、MacOS、32位Windows、64位Windows下的安装包:

需要说明的是,你应该下载与自己平台相适应的版本,而且最好是下载最新版本。如果你是一个Linux用户,应该下载Linux版本;如果是Windows用户,应该下载Windows版本,而且还要区分是32位还是64位。
如图4-2所示,这是在笔者的机器上下载并安装NASM的截图。笔者的机器使用64位的INTEL x86处理器,操作系统是64位的Windows 10,所以选择/2.15.05/win64目录下的安装程序,即下载并执行nasm-2.15.05-installer-x64.exe这个可安装包。
如图4-2所示,在出现的安装界面中,可供选择的组件包括NASM汇编(编译)器和反汇编器模块、完整的NASM手册和用于将NASM集成到Visual Studio 2008的配置文件。
安装好NASM之后,还需要将其添加到系统默认的搜索路径中去,这样就可以在任何目录下使用它来编译汇编语言程序,否则只能在NASM的安装目录中运行汇编(编译)器来编译你的汇编语言程序。以Windows平台为例,如图4-3所示,可以在桌面上右击“此电脑”,然后在“高级”选项中单击“环境变量”,并对“Path”进行编辑,将NASM的安装目录添加进来。
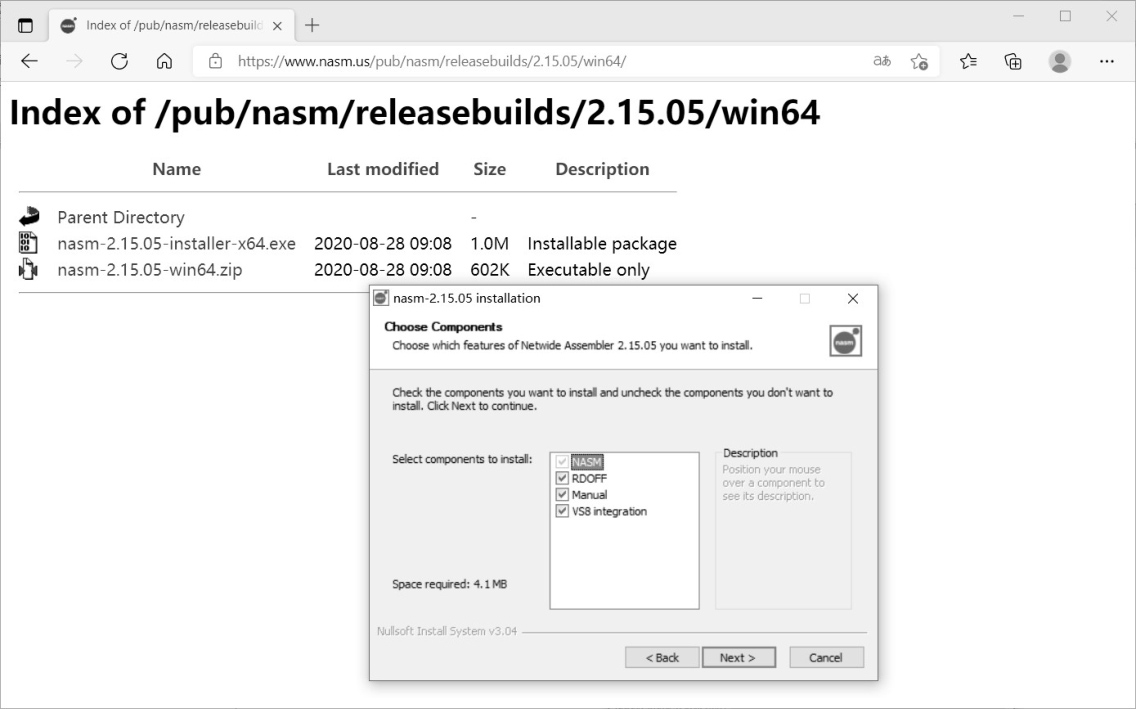
图4-2 下载并安装NASM
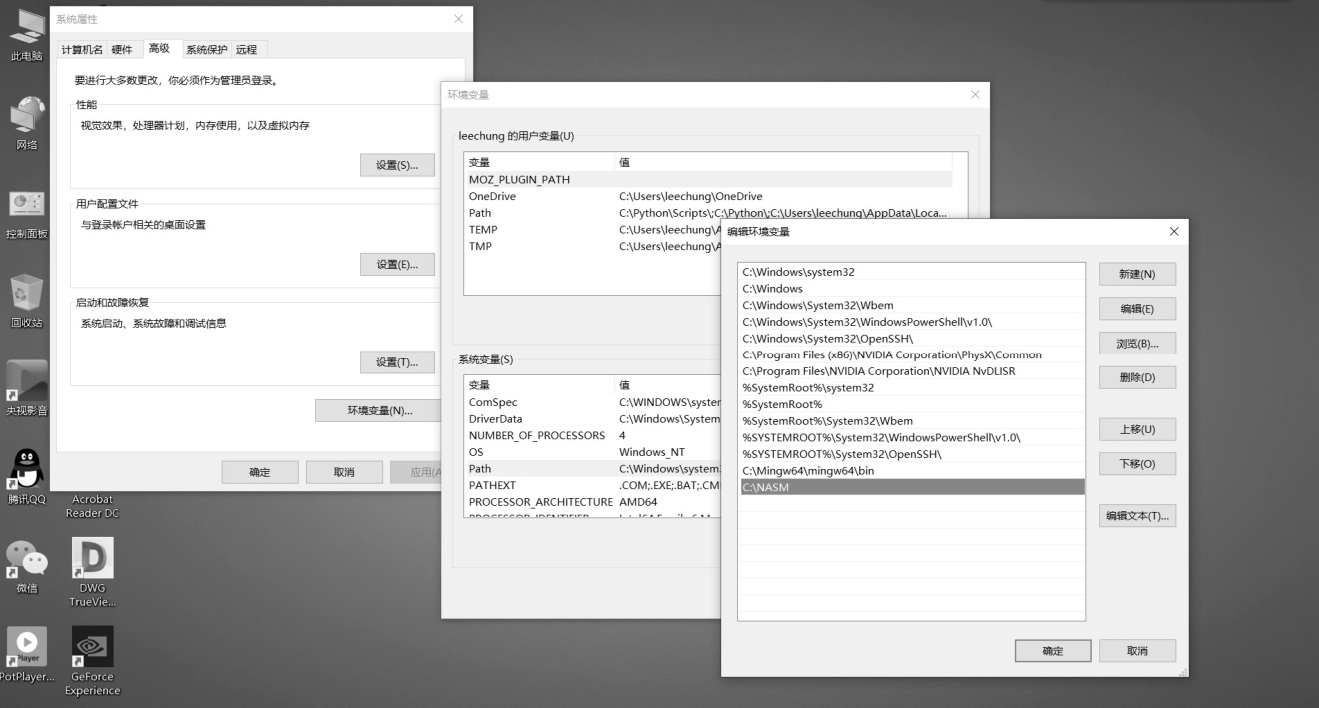
图4-3 在Windows中编辑环境变量Path的内容
因为NASM可以运行在不同的操作系统平台上,但这本书的讲解无法兼顾所有平台,所以只能以用户较多的Windows平台为例来介绍。对于其他操作系统平台,其实也都大同小异,可以自行参考相关的资料。
在Windows平台上,和你已经司空见惯的其他应用程序不同,NASM在运行之后并不会显示一个图形用户界面。相反地,它只能通过命令行使用。
比如,我们可以用Windows记事本编写一个汇编语言源程序并予以保存,假定保存在D盘的MyAsm目录下,文件名为exam.asm。作为惯例,汇编语言源程序文件的扩展名是“.asm”,不过,你当然可以使用其他扩展名。
一旦有了一个源程序,下一步就是将它的内容编译成机器代码。为此你需要打开一个命令行窗口。比如在Windows 10中,你需要从启动菜单中选择“Windows系统”→“命令提示符”,或者直接按Windows徽标键+R,在弹出的“运行”对话框中输入cmd并回车。
接着,切换到你的工作目录(汇编语言程序所在的目录)。如图4-4所示,我们刚才是把源文件exam.asm保存在D盘的MyAsm目录下的,那么,编译这个文件的方法很简单,就是切换到这个目录,然后在命令行提示符后输入“nasm-f bin exam.asm-o exam.bin”并按下Enter键。
如图4-4所示,在编译之后我们用DIR命令查看文件,发现多一个“exam.bin”,这就是编译器生成的文件,它包含了处理器可以识别和执行的机器指令。
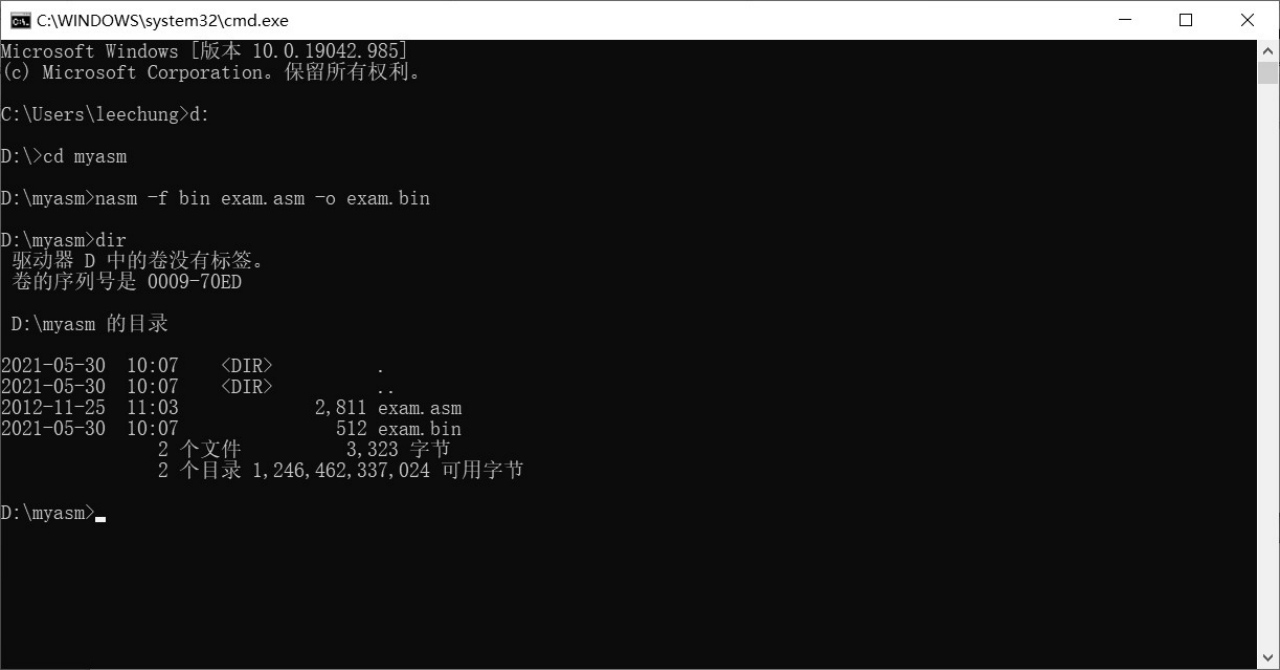
图4-4 在Windows命令行编译汇编语言程序
NASM需要一系列参数才能正常工作。-f参数的作用是指定输出文件的格式(Format)。这样,-f bin就是要求NASM生成的文件只包含“纯二进制”的内容。换句话说,除了处理器能够识别的机器代码,别的任何东西都不包含。这样一来,因为缺少操作系统所需要的加载和重定位信息,它就很难在Windows、DOS和Linux上作为一个普通的应用程序运行。不过,这正是本书所需要的。
紧接着,exam.asm是源程序的文件名,它是将要被编译的对象。
-o参数指定编译后输出(Output)的文件名。在这里,我们要求NASM生成输出文件exam.bin。
用来编写汇编语言源程序,Windows记事本并不是一个好工具。同时,在命令行编译源程序也令很多人迷糊。毕竟,很多年轻的朋友都是用着Windows成长起来的,他们缺少在DOS和UNIX下工作的经历。
为了写这本书,我一直想找一个自己中意的汇编语言编辑软件。互联网是个大宝库,上面有很多这样的工具软件,但大多都包含了太多的功能,用起来自然也很复杂。我的愿望很简单,能够方便地书写汇编指令即可,同时还具有编译功能。毕竟我自己也不喜欢在命令行和图形用户界面之间来回切换。
在经历了一系列的失望之后,我决定自己写一个。在本书第一版中,这个小程序叫Nasmide,但很多读者反映在Windows 10下不能运行,于是2020年重新编写了两个版本,一个是32位版本,名字叫Nasmide32,专为32位Windows而设计;一个是64版本,名字叫Nasmide64,专为64位Windows而设计。可以在64位的Windows上运行32位和64位版本,但32位版本只能运行在32位Windows上。这两个版本的程序已在配书文件包中更新,不过遗憾的是,它们并非是用汇编语言书写的。
现在,你可以双击Nasmide32.exe或者Nasmide64.exe来运行它(方便起见,我们以后统称为Nasmide软件)。如图4-5所示,这是新版的Nasmide软件,它的界面分为三个部分。顶端是菜单,可以用来新建文件、打开文件、保存文件或者调用NASM来编译当前文档。
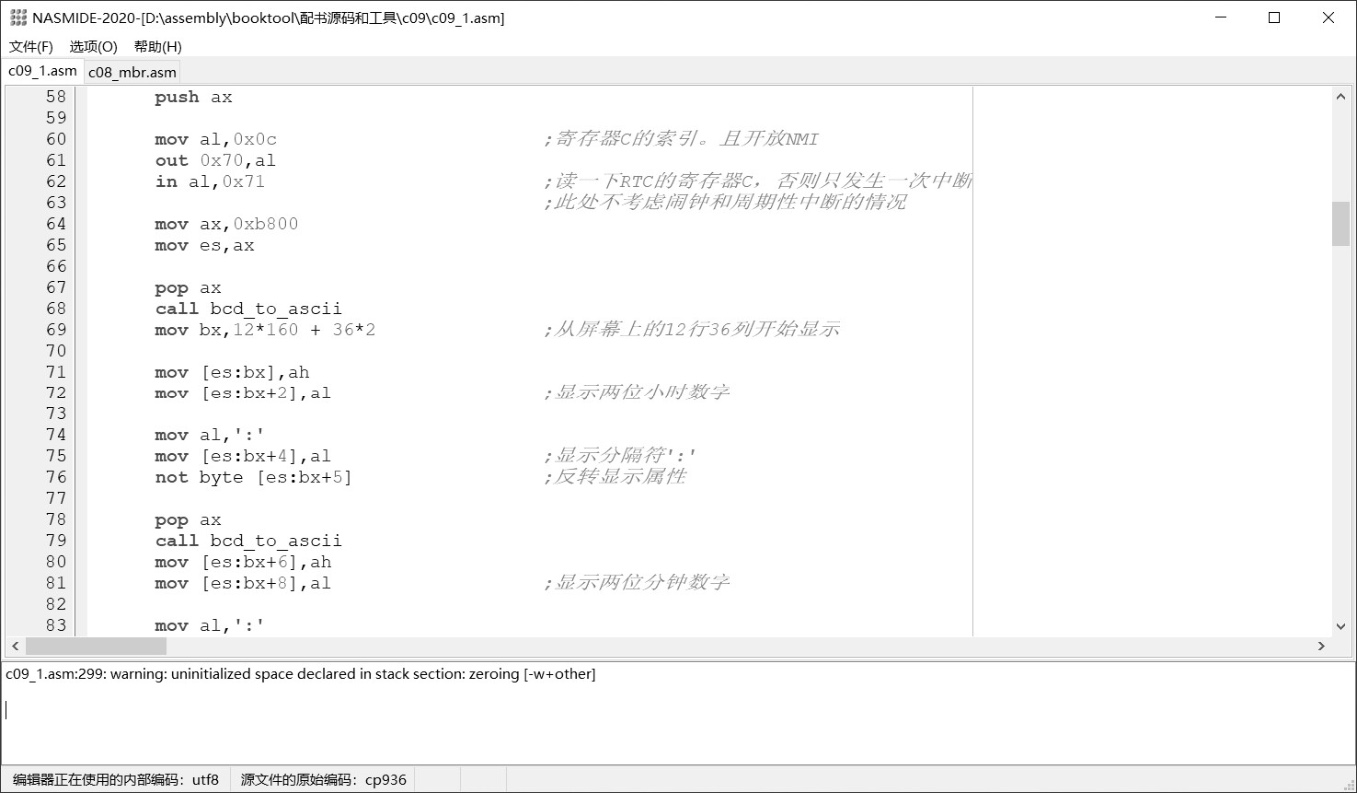
图4-5 Nasmide程序的基本界面
中间最大的空白区域是编辑区,用来书写汇编语言源代码。原来的版本只能编辑一个文件,新版可以同时编辑多个文件。
窗口底部那个窄的区域是消息显示区。在编译当前文档时,不管是编译成功,还是发现了文档中的错误,都会显示在这里。
基本上,你现在已经可以在Nasmide里书写汇编语句了。不过,在此之前你最好先做一件事情。Nasmide只是一个文本编辑工具,它自己没有编译能力。不过不要紧,它可以在后台调用NASM来编译当前文档,前提是它必须知道NASM安装在什么地方。
为此,你需要在菜单上选择“选项”→“编译器路径名设置”来打开“选项设置”窗口。如图4-6所示,你需要指定NASM汇编器所在的路径,这个路径就是你在前面安装NASM时,指定的安装路径,包括可执行文件名nasm.exe。
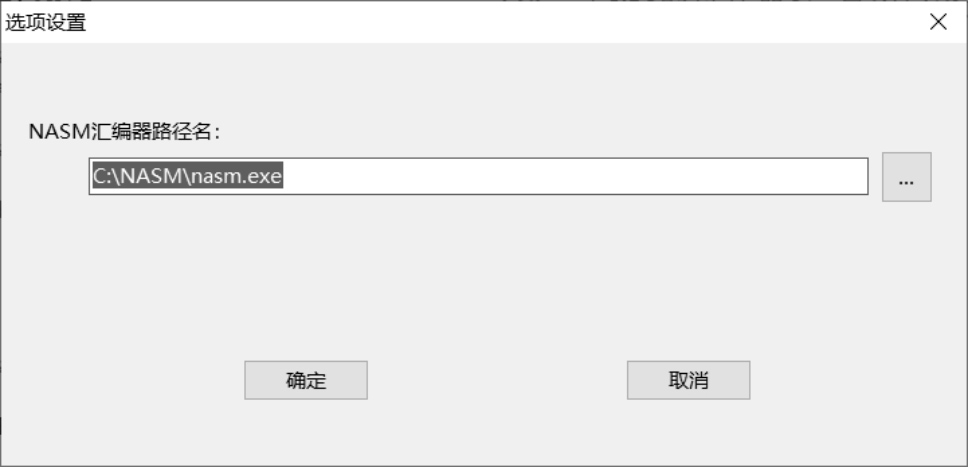
图4-6 为Nasmide指定NASM编译器所在路径
不同于其他汇编语言编译器,NASM最让我喜欢的一个特点是允许在源程序中只包含指令,如图4-7所示。用过微软公司MASM的人都知道,在真正开始书写汇编指令前,先要穿靴戴帽,在源程序中定义很多东西,比如代码段和数据段等,弄了半天,实际上连一条指令还没开始写呢。
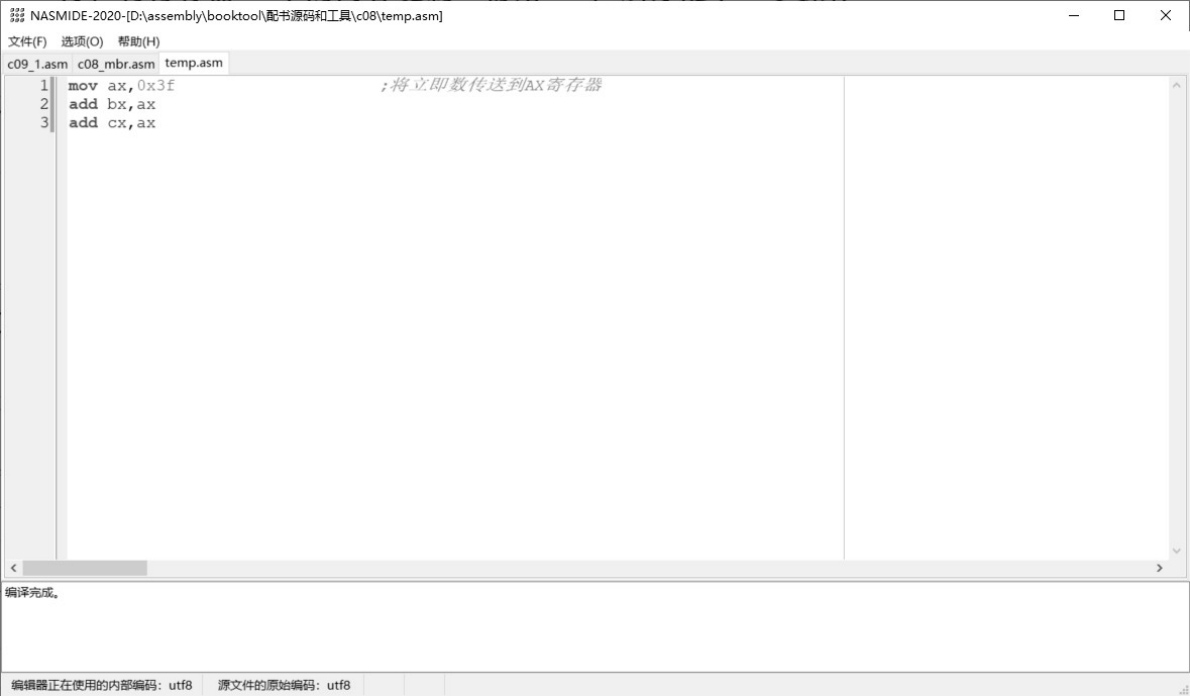
图4-7 NASM允许在源文件中只包含指令
如图4-7所示,用Nasmide程序编辑源程序时,它会自动在每行内容的左边显示行号。对于初学者来说,一开始可能会误以为行号也会出现在源程序中。不要误会,行号并非源程序的一部分,当保存源程序的时候,也不会出现在文件内容中。
让Nasmide显示行号,这是一个聪明的决定。一方面,我在书中讲解源程序时,可以说第几行到第几行是做什么用的;另一方面,当编译源程序的时候,如果发现了错误,错误信息中也会说明是第几行有错。这样,因为Nasmide显示了行号,所以就很容易快速找到出错的那一行。
在汇编源程序中,可以为每行添加注释。注释的作用是说明某条指令或者某个符号的含义和作用。注释也是源程序的组成部分,但在编译的时候会被编译器忽略。如图4-7所示,为了告诉编译器注释是从哪里开始的,注释需要以英文字母的分号“;”开始。
当源程序书写完毕之后,就可以进行编译了,方法是在Nasmide中选择菜单“文件”→“编译源文件”。这时,Nasmide将会在后台调用NASM来完成整个编译过程,不需要你额外操心。如图4-7所示,即使只有三行的程序也能通过编译。编译完成后,会在窗口底部显示一条消息。
◆ 检测点4.1
1.在你的计算机中启动Nasmide程序,输入图4-1中的三行代码,然后编译它们。看看消息显示区是否有编译成功的提示。
2.选择填空:指令mov ax,0xf 5fc中,“mov”指示这是一条( )指令,0xf 5fc是( )。指令执行后,寄存器AX中的内容是( )。
A.立即数 B.传送 C.0xf 5fc D.加法 E.0xfcf 5 F.寄存器
编译成功完成之后,将生成对应的二进制文件。尽管我们强调源文件和编译之后的文件具有不同的内容,但如果能用工具看一看,相信印象更为深刻。在前面下载的配书源码和工具里,有一个名为HexView的小程序,可以实现这个愿望。HexView用于打开任意一个文件,以十六进制的形式从头到尾显示它每字节的内容。
双击启动HexView,然后选择菜单“文件”→“打开文件以显示”,在文件选择对话框里找到你在4.1节里编辑并保存的源程序文件。如图4-8所示,文件选择之后,HexView程序将以十六进制的形式显示刚刚选择的文件。
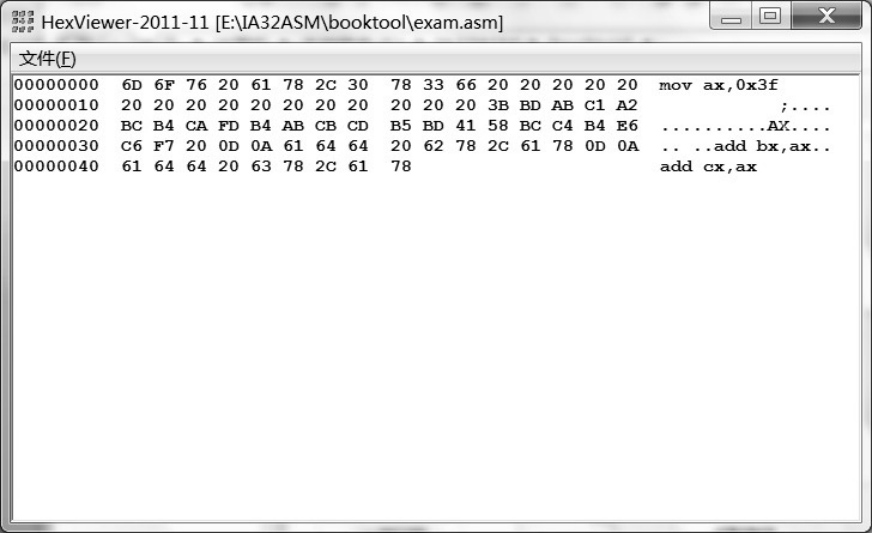
图4-8 用HexView程序显示源程序文件的内容
在HexView中,文件的内容以十六进制的形式显示在窗口中间,以16字节为一行,字节之间以空白分隔,所以看起来很稀疏。如果文件较大的话,则会分成很多行。
作为对照,每字节还会以字符的形式显示在窗口右侧,如果它确实可显示为一个字符的话。如果该字节并非一个可以显示的字符,则显示一个替代的字符“.”。因为源程序中还有汉字注释,所以,如果细心的话,从图中可以算出每个汉字的编码是2字节,比如“将”字的编码是0xBD 0xAB。由于HexView是以单字节的形式来显示每个字符的,所以无法显示汉字。
左边的数字,是每行第一字节相对于文件头部的距离(偏移),也是以十六进制数显示的。字母“m”是整个源程序文件内的第1个字符,因此,它的偏移量是00000000(H),其他字符依次类推,最后一个字符“x”的偏移量是00000048(H)。
源程序很长,但是,编译之后的机器指令却很简短。如图4-9所示,编译之后的文件只有7字节,这才是处理器可以识别并执行的机器指令。
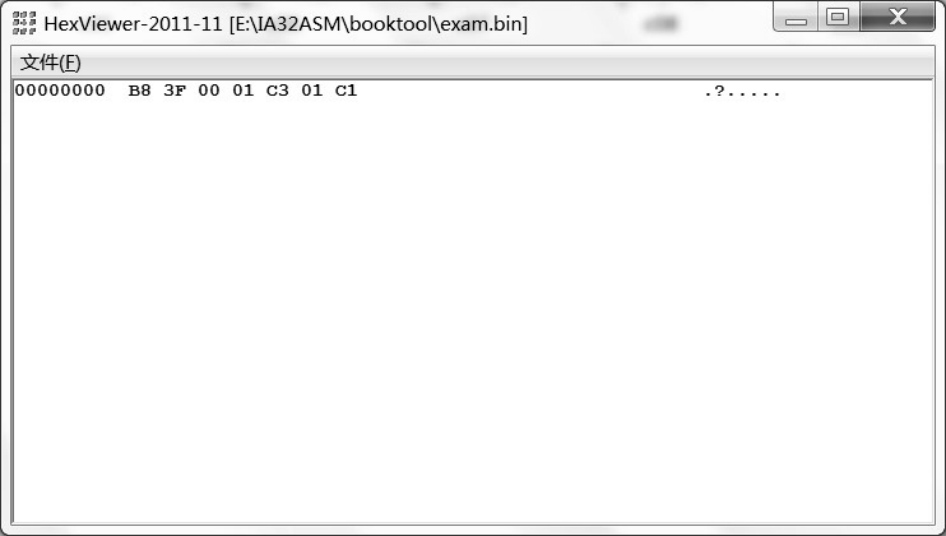
图4-9 用HexView显示编译之后的文件内容
就像前言里说的,这本书以汇编语言为主,但实际上蕴含了硬件体系和操作系统方面的内容。无论如何,学习这些内容,一靠理论,二靠实例,三靠实践。“理论”是印在这本书上的文字内容;“实例”是本书提供的配套源码,以及本书对源码的讲解;“实践”就要靠读者自己在读书的过程中把理解的知识灵活运用,举一反三。
本书不配光盘,书中用到的源代码及相关的小工具,都需要从我的个人网站中下载,网站的地址是

进入网站后,按照说明下载配书文件包即可。本书第1版的文件包是x86pkg1.rar,本版(也就是第2版)的文件包是x86pkg2.rar,请注意鉴别,别弄错了。
文件包的内容包括各章的汇编语言程序、工具软件、相关教程及辅助的软硬件资料,另外还包括一个没有加到实体书中的章节,即“原稿第10章内容”。按最初的计划,它是本书第1版的第10章,讲的是如何用汇编语言来控制老的Sound Blaster 16声卡播放声音,但是因为内容太老,决定去掉。
如图4-8所示,请问:
(1)源程序共有3行,每行第一个字符在文件内的偏移量分别是多少?
(2)该源程序文件的大小是多少字节?