
下载掌阅APP,畅读海量书库
立即打开



我们都知道高可用的通用办法是冗余设计(或者说集群无单点),多个节点形成集群,一旦形成集群,必定涉及一致性、可用性以及分区容错性等问题,这就涉及CAP理论。因此,CAP理论是学习高可用必须掌握的理论。
由于对系统或者数据进行了拆分,因此我们的系统不再是单机系统,而是分布式系统,针对分布式系统的CAP原理包含如下3个元素(见图1-11):
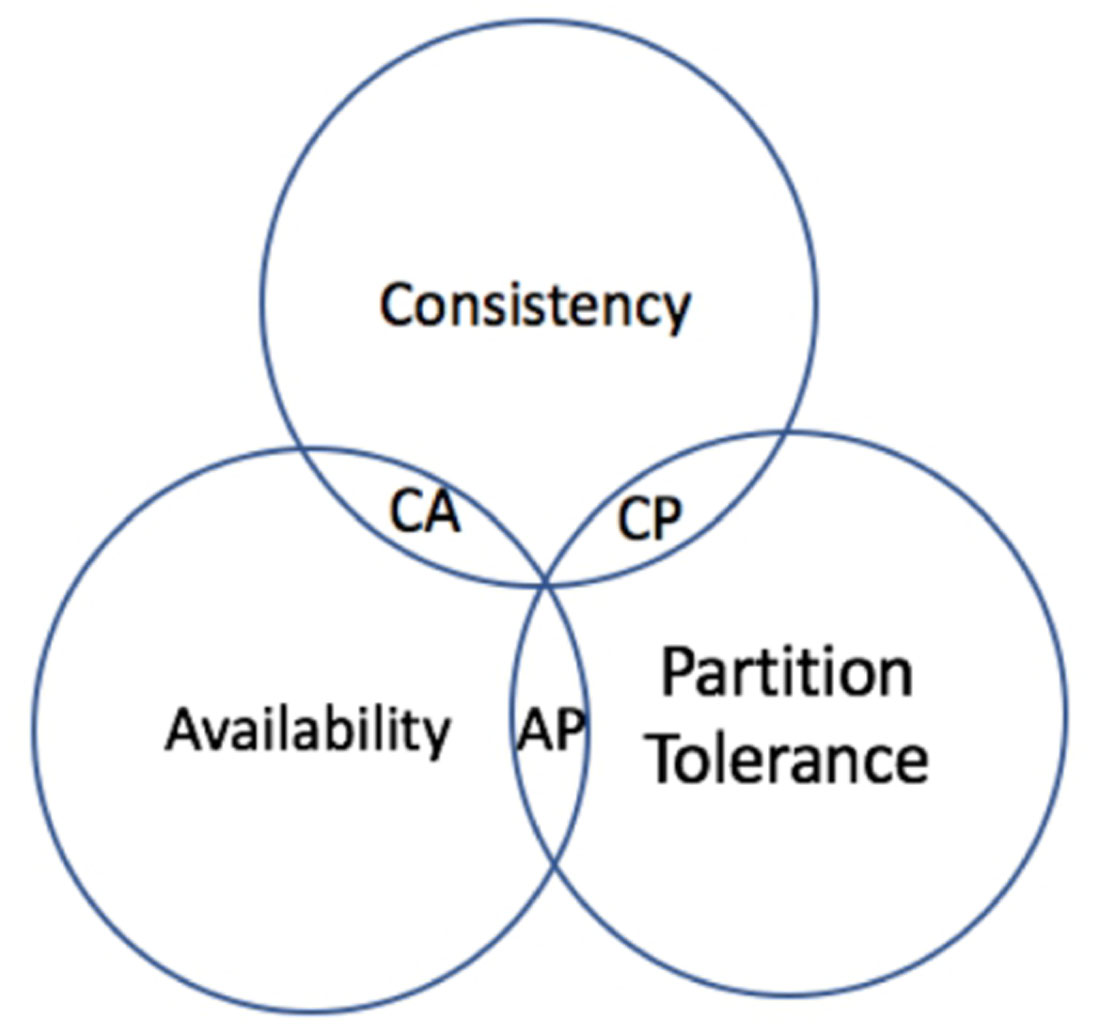
图1-11 CAP理论
CAP原理证明,任何分布式系统只可以同时满足以上两点,无法三者兼顾。在分布式系统中,网络无法100%可靠,分区其实是一个必然现象。也就是说,分区容错性(P)是前提,是必须要保证的。
现在就只剩下一致性(C)和可用性(A)可以选择了,要么选择一致性,保证数据正确;要么选择可用性,保证服务可用。那么CP和AP的含义是什么呢?
对于CP来说,放弃可用性,追求一致性和分区容错性,ZooKeeper其实追求的就是强一致。对于AP来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择。
顺便一提,CAP理论中是忽略网络延迟的,也就是当事务提交时,从节点A复制到节点B没有延迟,但是在现实中这明显是不可能的,所以总会有一定的时间是不一致的。同时,CAP中选择两个,比如你选择了CP,并不是叫你放弃A。
在不存在网络分区的情况下,也就是分布式系统正常运行时(这也是系统在绝大部分时候所处的状态),也就是说在不需要P时,C和A能够同时保证。只有当发生分区故障的时候,也就是说在需要P时,才会在C和A之间做出选择。
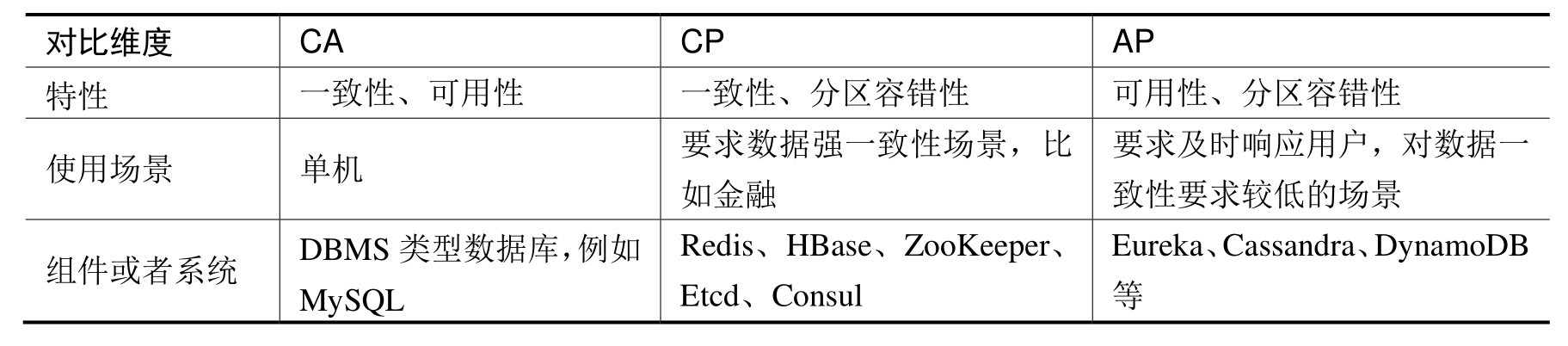
最后我们来对比分析一下CA、CP以及AP这3种策略,以方便读者记忆和理解,具体如表1-4所示。
表1-4 CA、CP以及AP三种策略对比
ACID理论是数据库为了保证事务正确性而提出的一种理论,它包含4个约束:
ACID理论是对事务特性的抽象和总结,方便我们实现事务。也就是说,如果我们使得一组操作具有ACID特性,那么这组操作就可以称为事务。ACID理论是传统数据库常用的设计理念,追求强一致性模型。在单机上实现ACID也不难,但是一旦涉及分布式系统的ACID特性,就需要用到分布式事务协议,比如两阶段提交(Two Phase Commit,2PC)。
在分布式环境下,每个节点都可以知晓自己的操作的成功或者失败,却无法知道其他节点操作的成功或失败。当一个分布式事务跨多个节点时,保持事务的原子性与一致性是非常困难的。
两阶段提交是一种在分布式环境下,所有节点进行事务提交,保持一致性的算法。它通过引入一个协调者(Coordinator)来统一掌控所有参与者(Participant)的操作结果,并指示它们是否要把操作结果进行真正的提交(Commit)或者回滚(Rollback)。
两阶段提交分为两个阶段:
(1)投票阶段(Voting Phase):协调者通知参与者,参与者反馈结果。
(2)提交阶段(Commit Phase):收到参与者的反馈后,协调者再向参与者发出通知,根据反馈情况决定各参与者是提交还是回滚。
例如,甲、乙、丙、丁4人要组织一个会议,需要确定会议时间,甲是协调者,乙、丙、丁是参与者。
第一阶段:投票阶段
(1)甲发邮件给乙、丙、丁,通知明天10点开会,询问是否有时间。
(2)乙回复有时间。
(3)丙回复有时间。
(4)丁迟迟不回复,此时对于这个事务,甲、乙、丙均处于阻塞状态,算法无法继续进行。
第二阶段:提交阶段
(1)协调者甲将收集到的结果通知给乙、丙、丁。
(2)乙收到通知,并发送ACK消息给协调者。
(3)丙收到通知,并发送ACK消息给协调者。
(4)丁收到通知,并发送ACK消息给协调者。
如果丁回复有时间,则通知提交;如果丁回复没有时间,则通知回滚。
需要注意的是,在第一个阶段,每个参与者投票表决事务是放弃还是提交。一旦参与者投票要求提交事务,那么就不允许放弃事务。也就是说,在一个参与者投票要求提交事务之前,它必须保证能够执行提交协议中它自己那一部分,即使参与者出现故障或者中途被替换掉。这个特性是我们需要在代码实现时保障的。
两阶段提交在执行过程中,所有节点都处于阻塞状态,所有节点所持有的资源(例如数据库数据、本地文件等)都处于封锁状态。如果有协调者或者某个参与者出现了崩溃,为了避免整个算法处于完全阻塞状态,往往需要借助超时机制来将算法继续向前推进。
两阶段提交这种解决方案属于牺牲了一部分可用性来换取一致性,对性能的影响较大,不适合高并发、高性能的场景。
最后需要注意的是,二阶段提交协议不仅仅是协议,也是一种非常经典的思想。两阶段提交协议是一个原子提交协议,能实现事务,保证所有操作,要么全部执行,要么全部不执行。两阶段提交在达成提交操作共识的算法中应用广泛,比如XA协议、TCC、Paxos、Raft等。
TCC其实就是采用的补偿机制,其核心思想是:针对每个操作都要注册一个与其对应的确认和补偿(撤销)操作。TCC分为3个阶段:
我们来看一个具体的例子,仍然以用户购物为例,如图1-12所示。
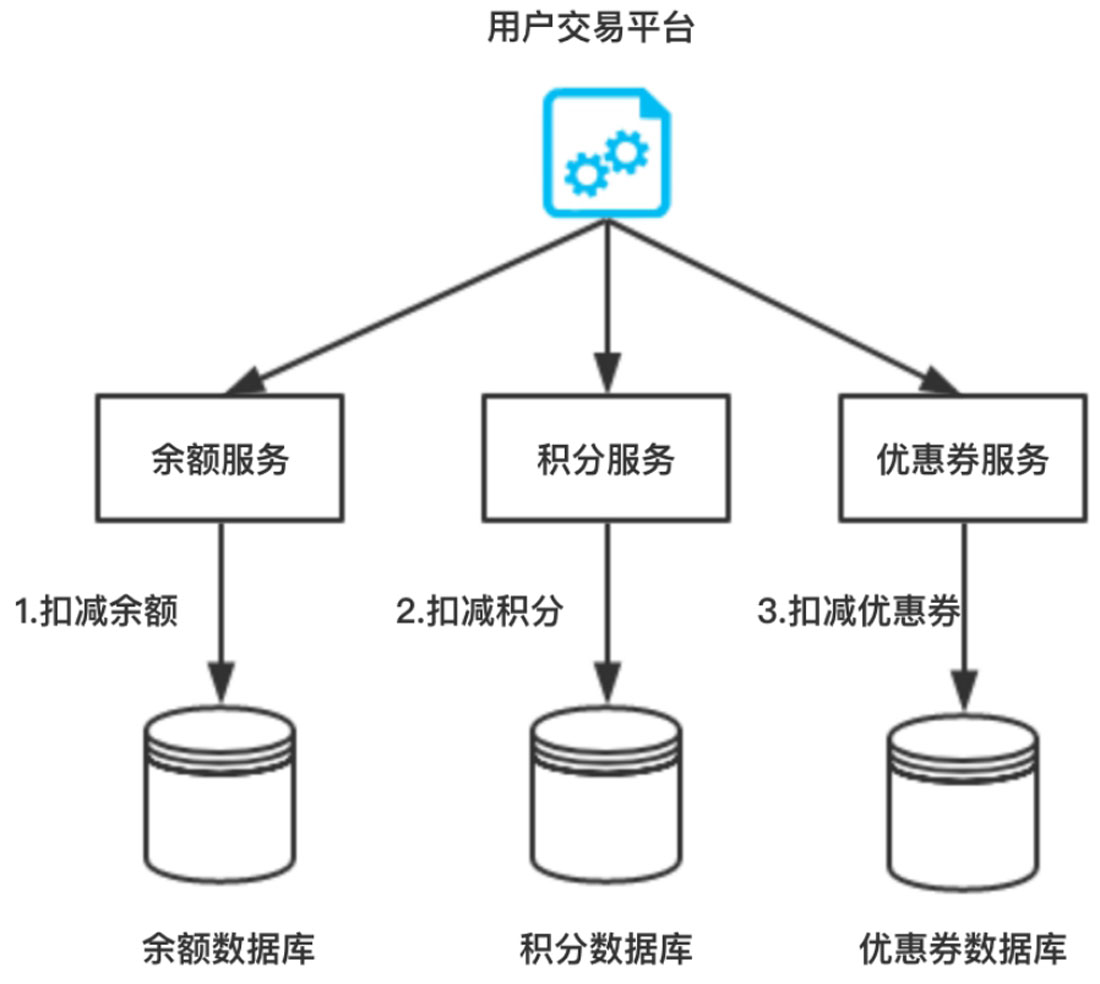
图1-12 用户交易流程图
比如修改余额,伪代码如下:
//修改余额,事务如下
int updateAccountT(uid, money){
start transaction;
//操作数据库
CURD table t_account with money for uid;
any exception rollback return NO;
commit;
return YES;
}
//修改余额,补偿事务
int rollbackAccountT(uid, money){
//做一个money的反向操作
return updateAccountT(uid, -1 * money){
}
同理,修改积分方法updateShoppingPointsT(uid,point),对应的补偿事务是updateShoppingPointsT(uid, point)。
要保证余额与积分的一致性,伪代码如下:
//执行第一个事务,扣减余额
int flag = updateAccountT();
if(flag=YES){
//若第一个事务成功,则执行第二个事务,扣减积分
flag= updateShoppingPointsT();
if(flag=YES){
//若第二个事务成功,则成功
return YES;
} else {
//若第二个事务失败,则执行第一个事务的补偿事务
rollbackAccountT();
}
}
从上面的伪代码可以看出,补偿事务的业务流程比较复杂,if/else嵌套非常多层,同时还需要考虑补偿事务失败的情况。
TCC的核心思想:针对每个操作都要注册与其对应的确认操作和补偿操作(也就是撤销操作)。它是一个业务层面的协议,也可将TCC理解为编程模型(本质上而言,TCC是一种设计模式,也就是一种理念,它没有与任何技术(或实现)耦合,也不受限于任何技术,对所有的技术方案都是适用的),TCC的3个操作需要在业务代码中编码实现,为了实现一致性,确认操作和补偿操作必须是幂等的,因为这两个操作可能会失败重试。
另外,TCC不依赖于数据库的事务,而是在业务中实现了分布式事务,这样能减轻数据库的压力,但对业务代码的入侵性也更强,实现的复杂度也更高。所以,推荐在需要分布式事务能力时,优先考虑现成的事务型数据库(比如MySQL XA),当现有的事务型数据库不能满足业务的需求时,再考虑基于TCC实现分布式事务。
在分布式系统中,我们往往追求的是可用性,它的重要程度比一致性要高,那么如何实现高可用性呢?前人已经给我们提出了另一个理论——BASE理论。BASE理论是CAP理论中AP的延伸。BASE理论指的是:
(1)Basically Available(基本可用)。
(2)Soft State(软状态)。
(3)Eventually Consistent(最终一致性)。
BASE理论是对CAP中的一致性和可用性进行权衡的结果,理论的核心思想是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
基本可用在本质上是一种妥协,也就是在出现节点故障或系统过载的时候,通过牺牲非核心功能的可用性,保障核心功能的稳定运行。
那么如何实现基本可用呢?
主要办法有流量削峰、延迟响应、降级、过载保护。
关于流量削峰、降级等内容会在后续的章节详细介绍。
软状态描述的是实现服务可用性的时候系统数据的一种过渡状态,也就是说不同节点间,数据副本存在短暂的不一致。软状态是实现BASE思想的方法,基本可用和最终一致是目标。
以BASE思想实现的系统由于不保证强一致性,因此系统在处理请求的过程中可以存在短暂的不一致,在短暂不一致的时间窗口内,请求处理处于临时状态,系统在进行每步操作时,通过记录每个临时状态,在系统出现故障时,可以从这些中间状态继续处理未完成的请求或者退回到原始状态,最终达到一致状态。可以将强一致性理解为最终一致性的特例,也就是说,可以把强一致性看作不存在延迟的一致性。
以转账为例,我们将用户A向用户B转账分成4个阶段:第l个阶段,用户A准备转账;第2个阶段,从用户A账户扣减余额;第3个阶段,对用户B增加余额;第4个阶段,完成转账。系统需要记录操作过程中每个步骤的状态,一旦出现故障,系统便能够自动发现没有完成的任务,然后根据任务所处的状态继续执行任务,最终彻底完成任务,资金从用户A的账户转账到用户B的账户,达到最终的一致状态。