1.1 什么是可用性
1.1.1 SLA与可用性
当我们谈到高可用(High Availability,HA)时,都会聊到可用性。那么,什么是可用性?如何来定义可用性呢?我们知道,任何东西都有不可用的时候,比如,再好的汽车(兰博基尼、法拉利、特斯拉等)都会有抛锚或者刹车失灵的时候;身体特别健康的人,也难免会感冒生病;即使是地球,也会有毁灭消失的一天;更何况是服务器/线上应用,除非把服务器搬到火星去,搬离太阳系。可见,我们没办法做到东西的100%可用性,只能做到高可用(<100%),越高的可用性,付出的代价越高。要防止汽车爆胎,车上可放置备胎,要防止多个车轮同时发生爆胎,需要准备多个备胎;要保证人一直保持健康,需要加强锻炼,养成良好的生活习惯,还要定期体检等。记住一句话:高可用必定带来高成本、高付出。
我们如何来量化服务/系统的高可用呢?“高”字不具体,甚至有些模糊。所以,就有了SLA(Service-Level Agreement,服务级别协议,也称服务等级协议、服务水平协议)的概念。SLA是服务提供商与客户之间定义的正式承诺。服务提供商与受服务用户之间具体达成了承诺的服务指标——质量、可用性、责任。SLA常见的组成部分是以合同约定向客户提供的服务,感兴趣的读者可以自行学习。
概念总是抽象的,我们举一个具体的例子来说明。相信很多人都购买过云产品(阿里云、腾讯云、华为云等),比如阿里云的ECS服务器,在ECS服务器相关的文档中,可以找到云服务器服务等级协议等内容,这是阿里云服务提供商与客户定义的正式承诺,具体如图1-1所示。
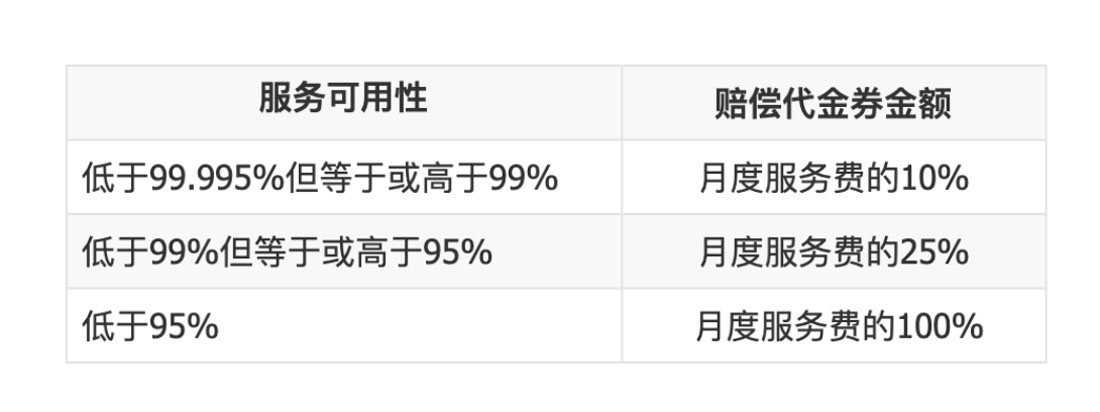
图1-1 阿里云服务等级协议
那么,SLA该如何计算呢?
-
通俗的定义:SLA =可用时长/(可用时长+不可用时长)。
-
不通俗的定义:SLA =f(MTBF,MTTR)。
这里我们又引入了两个概念:MTBF(Mean Time Between Failures,平均故障间隔)和MTTR(Mean Time To Repair or Mean Time To Recovery,平均修复时间)。
-
MTBF:平均故障间隔,通俗一点就是一个东西多长时间坏一次。
-
MTTR:平均修复时间,意思是一旦东西坏了,需要多长时间去修复或者恢复它。
可见,提高SLA只有两个方法:一是提高系统的可用时长,二是降低系统的不可用时长。或者说,提高MTBF,降低MTTR。
SLA又可以分为年SLA、季度SLA、月SLA及周SLA等,说实话,年SLA除了客户赔款外,本身没有太大的实际意义,在项目中我们更加看中季度SLA、月SLA甚至周SLA。图1-2是分别计算不同的SLA在不同的时间周期所允许的宕机时间。
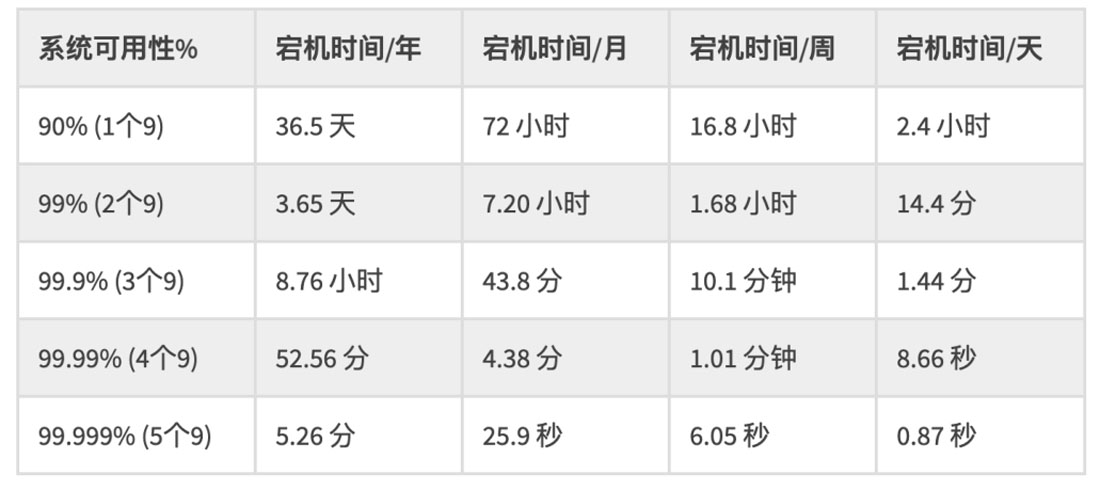
图1-2 SLA计算表格
比如3个9,即99.9%,按照年统计,一年只能有0.01%的时间出现故障,即3.65天;按照月统计,一个月有30×24 = 720小时,一个月只能有0.01%的时间出现故障,即7.20小时。
读者可能会问,系统的SLA阈值设置为多少合适呢?
我们可以回过头来看看阿里云定义的SLA协议,具体如图1-3所示。

图1-3 阿里云ECS赔偿方案
从图1-3中可以看出,如果服务可用性低于99.975%,阿里云就要向客户提供具体的代金劵金额赔偿,可见系统的SLA要达到4个9是非常难的。因此,系统的SLA阈值设置为4个9是一个比较合理的值。
1.1.2 影响高可用的因素
上一小节主要讲解了可用性以及如何去度量可用性,本小节主要讲解影响高可用的因素是什么,或者说是什么原因导致系统可用性差。导致系统不可用的因素有很多,如表1-1所示。
表1-1 非高可用因素

可以简单地将原因分为两种:外在因素和内在因素。
外在因素即系统以外的因素,比如机房发生火灾、光缆被挖断、地球毁灭等。
内在因素即系统本身的原因,包括系统依赖的资源(数据库、缓存、硬件资源等),比如服务器硬件故障、系统本身故障/Bug、系统依赖的中间件存在问题、数据库/缓存等宕机、发布新应用等,这里以具体实例进行分析。
-
服务器硬件故障:硬件故障导致服务宕机是必然会发生的事情,尤其是网站规模不断扩大,网站后台的服务器越来越多,硬件故障概率必然变大。
-
应用发布:应用发布新功能时,需要重新部署新的应用程序版本,这个过程需要重启应用,如果应用重启更新的过程中没做到无损发布,必然导致短暂的服务不可用。这种形式的不可用相比硬件故障更为常见。从可用性指标来看,这种频繁出现的停机升级过程大大增加了网站的不可用时间。因此,高可用设计必须提供可行的方案,将这种停机升级的影响降到最低。
-
应用程序问题:比如测试力度不够,导致存在Bug应用发布到线上。
由此可见,要保证系统完全高可用几乎是不可能的,只能尽力为之。
1.1.3 高可用策略
高可用策略实在太多,随随便便都可以说出几个:冗余备份、限流/熔断/降级、监控等。为了让读者更好地理解这些策略,将高可用策略按照时间维度分为3个阶段:事故前、事故中、事故后(不是很准确,主要是希望把高可用策略串起来),具体如图1-4所示。

图1-4 高可用策略划分
在系统出现异常之前,需要未雨绸缪,例如:
-
冗余备份:汽车容易爆胎,就多准备几个备胎在车上;单行道道路容易堵车,就改成两车道、三车道甚至更多;体现在系统上,就是保证系统的各个节点都要做冗余备份。单节点的应用改成多节点集群,单实例的数据库/缓存改成多实例数据库以及集群(多实例的数据库/缓存需要进行数据备份),当某个节点出现故障时,其他节点可以快速接管。
-
监控:当道路出现堵车时,如果交警不在现场,是没办法提前感知路况的,也不可能每条路都安排一个交警,所以需要在道路上安装摄像头,或者利用先进的监控技术来监控路况。重要的系统在上线之前,也需要提前搭建监控体系,收集监控指标,针对监控指标阈值设置相关的告警(短信、邮件等)。
-
安全防护:道路堵车不仅是因为车辆太多、车道太少等,还有可能是因为恐怖分子恶意制造混乱、地面塌陷等。类似的,系统也可能遭受黑客攻击、光缆被挖断等情况,因此需要网络应用防火墙(Web Application Firewall,WAF)来保护我们的系统。WAF是一种HTTP入侵检测和防御系统,工作在OSI七层模型中的应用层,为Web服务提供全面的防护,例如ModSecurity生产级的WAF产品。
-
运维值班:如果某个道路有重要领导人要通过,就需要提前安排警察等人员进行安全巡查,防止出现突发情况。类似的,对于系统中重要的服务,在重要的时间段也需要提前安排运维,开发人员三班制24小时不间断地看护。
-
硬件资源:道路也会坏掉,太久的道路多少会出现坑坑洼洼的现象,因此需要定期检查维护和保养。对于系统的硬件资源,比如磁盘、服务器、电源,也需要定期检查。
该提前准备的事项都准备了,系统也该上线了,流量慢慢进来,系统有条不紊地运行着。只要上线之前做好充足的测试(功能测试、性能测试、压力测试等),正常情况下,系统是不会出现什么大问题的。我们讲的高可用策略都是针对系统在突发情况下的一些应对措施,对应的策略有:
-
限流:每条路都有一个最大承重,超过路面所能承受的重量,道路就会凹陷,路面会受到破坏。类似的,每个系统/服务也有一个最大的承受能力,当流量太大,超过系统的承受能力时,就要进行一定的限制,这就是限流。很明显,限流是一种有损操作,是系统为了保护自己不得已才做出的动作。
-
降级:一般情况下,道路面前人人平等,但是当车流量很大,而救护车、110警车、消防车等重要的车辆需要通过时,我们都要优先让出车道,保证这些车辆的通行。同样,当系统有大量的请求流量进入(大促、秒杀、双十一活动、双十二活动),往往需要保证重要的服务而舍弃非重要的服务。例如,优先保证商品下单的完整流程,下单完成后通知用户消息可以先关闭。又比如日志降级,重要服务的日志打印功能保留,暂时关掉非重要服务的日志打印功能等。很明显,降级也是一种有损操作。
-
熔断:当高速公路并非堵车,而是出现道路坍塌或者山体滑坡等问题时,如果在高速入口没有及时通知,源源不断的车辆进入高速公路,就会让道路越来越堵,最后瘫痪,交警车辆也进不来,堵车车辆也出不去。同样,一个应用依赖多个服务是非常常见的,如果其中一个依赖由于延迟过高发生阻塞,调用该依赖服务的线程就会阻塞,如果相关业务的QPS较高,就可能产生大量阻塞,从而导致该应用/服务由于服务器资源被耗尽而拖垮。另外,故障也会在服务之间传递,如果故障服务的上游依赖较多,可能会引起服务的雪崩效应。
-
自动水平扩容:如果说限流/降级是一种有损操作,那么水平扩容就是一种比较积极正面的保障措施。普通时间高速路只开通两个车道进行车辆通行,因为车流量少,剩下的通道暂时关闭。而节假日车流量大,就放开剩下的车道,保障道路畅通。同样,如果流量暴增,就需要服务有自动扩容的能力,自动增加服务实例。对于容器化部署的服务,可以使用容器编排技术(比如k8s)对容器进行快速扩容和缩容。如果服务不是容器化部署,就需要运维人员手工创建新的服务实例,等流量降下来再手工回收服务实例,当然手工操作是非常麻烦的。
最后是事后阶段,具体包括:
-
人工接入:道路出现多起交通事故,实在太堵,整条路处于崩溃状态,甚至还出现吵架、打架流血等现象,实在难以恢复时,就只能由交警、警察介入处理。同样,服务出现难以恢复的故障时,就不得不让运维人员、开发人员介入,手工去重启或者排查原因。
-
自动恢复:道路堵车,有时仅仅是因为路面积水或者出现小障碍物,只需要把小障碍物移开或者把堵住下水道的杂物拿掉即可。同理,当服务出现一些小的问题,比如内存/CPU开始吃紧,服务能够自动检测,自动进行内存扩容,不需要人工介入。又比如服务超时,当服务请求变忙,出现超时情况的,服务可以自动延长超时时间,让慢请求可以正常执行。
最后需要注意的是,系统可用性越高,投入成本越大。所以,高可用是费钱的。
1.1.4 高可用和高可靠
可靠性和可用性这两者之间有一定的区别和联系,定义如下:
-
可用性(Availability):被定义为系统的一个属性,它说明系统已准备好,马上就可以使用。换句话说,高度可用的系统在任何给定的时刻都能及时地工作。关注的是服务总体的持续时间,系统在给定时间内总体的运行时间越长,可用性越高。
-
可靠性(Reliability):指系统可以无故障地持续运行。与可用性相反,可靠性是根据时间间隔而不是任何时刻来进行定义的。一个服务连续无故障运行的时间越长,可靠性就越高。
可靠性、可用性相关的指标如下:
-
MTBF(Mean Time Between Failure,平均无故障时间)是指系统在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。MTBF越长表示可靠性越高,正确工作能力越强。
-
MTTF(Mean Time To Failure,平均故障前时间)是指系统平均能够正常运行多长时间才发生一次故障。系统的可靠性越高,平均无故障时间越长。
-
MTTR(Mean Time To Repair,平均修复时间)是指可修复产品的平均时间,就是从出现故障到修复中间的这段时间。MTTR越短表示易恢复性越好。
在《分布式系统原理与范型》(第2版)一书中提到的以下例子比较准确地解释了两者的区别:
如果系统每小时崩溃1ms,那么它的可用性就超过99.9999%,但是它还是高度不可靠,因为它只能无故障运行1小时。与之类似,如果一个系统从来不崩溃,但是每年要停机两个星期,那么它是高度可靠的,但是可用性只有96%。
clv5OezoUaWiBtF1Hlcxt85+ugUFegQd6shJjI+XbKcCbSv9HzJBA2ISZgAT2jcE



