
下载掌阅APP,畅读海量书库
立即打开



一个高可用的集群中,一般都会存在主节点的选举机制,主节点用来协调和管理其他节点,以保证集群有序运行和节点间数据的一致性。本节介绍常用的选举算法:霸道选举算法(Bully Algorithm)、Raft选举算法、ZAB选举算法。
霸道选举算法是一种分布式选举算法,每次都会选出存活的进程中ID最大的候选者。在霸道选举算法中,节点的角色只有两种:普通节点和主节点。霸道选举算法在选举过程中会发送以下3种消息类型:
霸道选举算法假设每个进程知道自己和其他进程的ID以及地址,进程之间消息传递是可靠的,当且仅当主节点故障或与其他节点失去联系后,才会重新选主。其选举流程如下:
具体示例如下:
(1)假设开始有6个节点,即P0~P6,P6进程ID最大,P0进程ID最小,集群启动的时候,因为P6进程知道其他节点的进程ID以及地址,所以P6为主节点,其他为普通节点,具体如图1-13所示。
(2)由于某种原因,P6节点宕机,具体如图1-14所示。
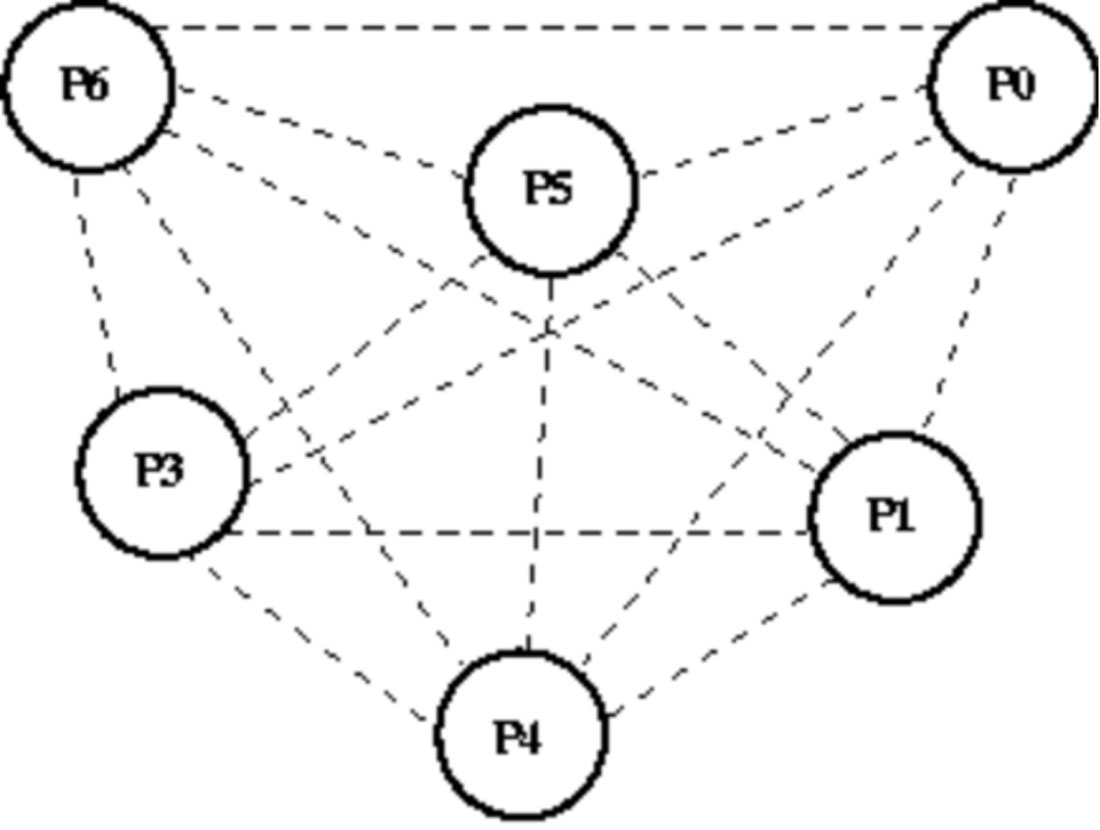
图1-13 霸道选举算法-step0
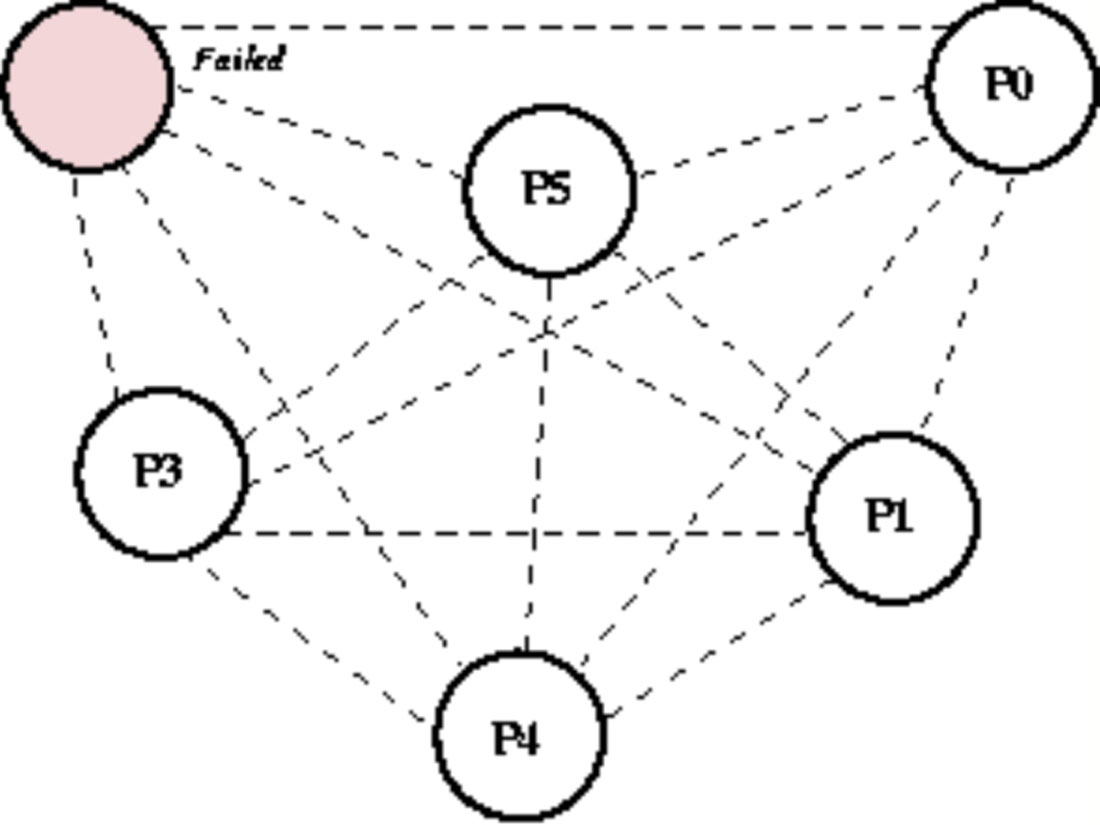
图1-14 霸道选举算法-step1
(3)P3节点注意到P6节点宕机没响应,所以P3节点开始选举,发送Election消息通知那些进程ID比P3大的节点P4、P5、P6,具体如图1-15所示。
(4)由于P4节点和P5节点的进程ID比P3节点大,因此回复Answer(Alive)消息。因为节点P3收到了从比自己ID还要大的进程发来的Alive消息,P3停止发送任何消息,等待Victory消息(如果过了一段时间没有等到Victory消息,重新开始选举流程),具体如图1-16所示。
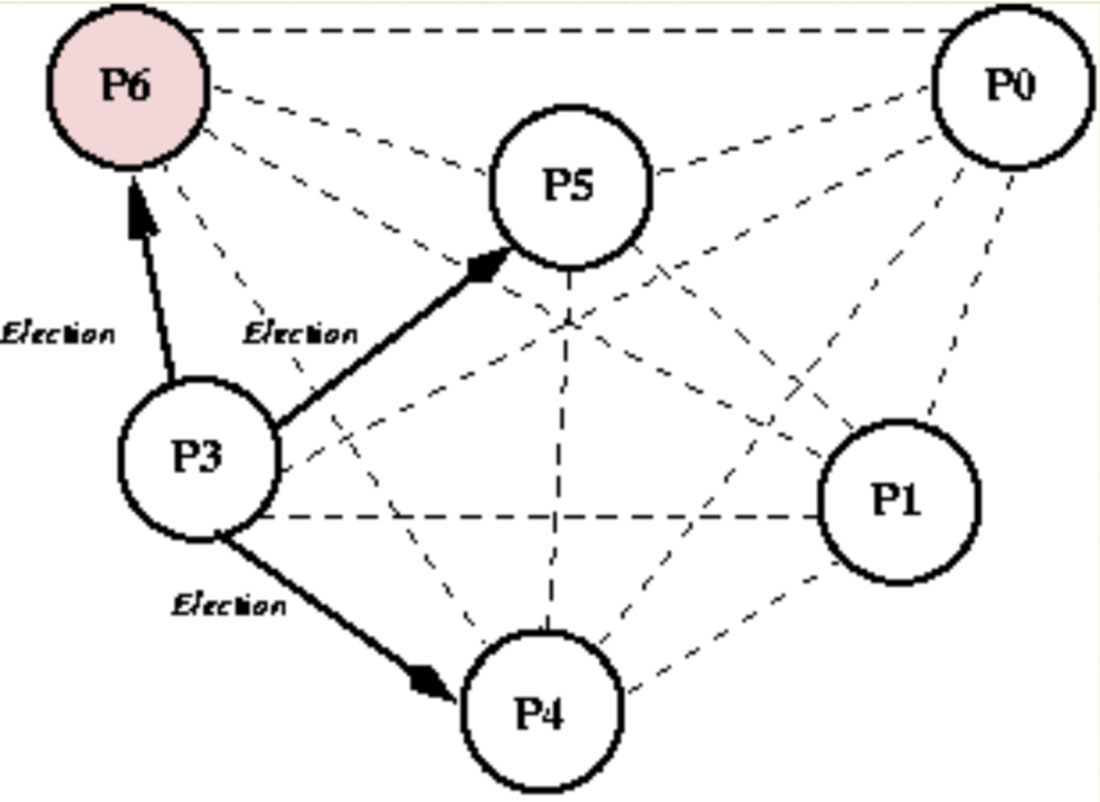
图1-15 霸道选举算法-step2
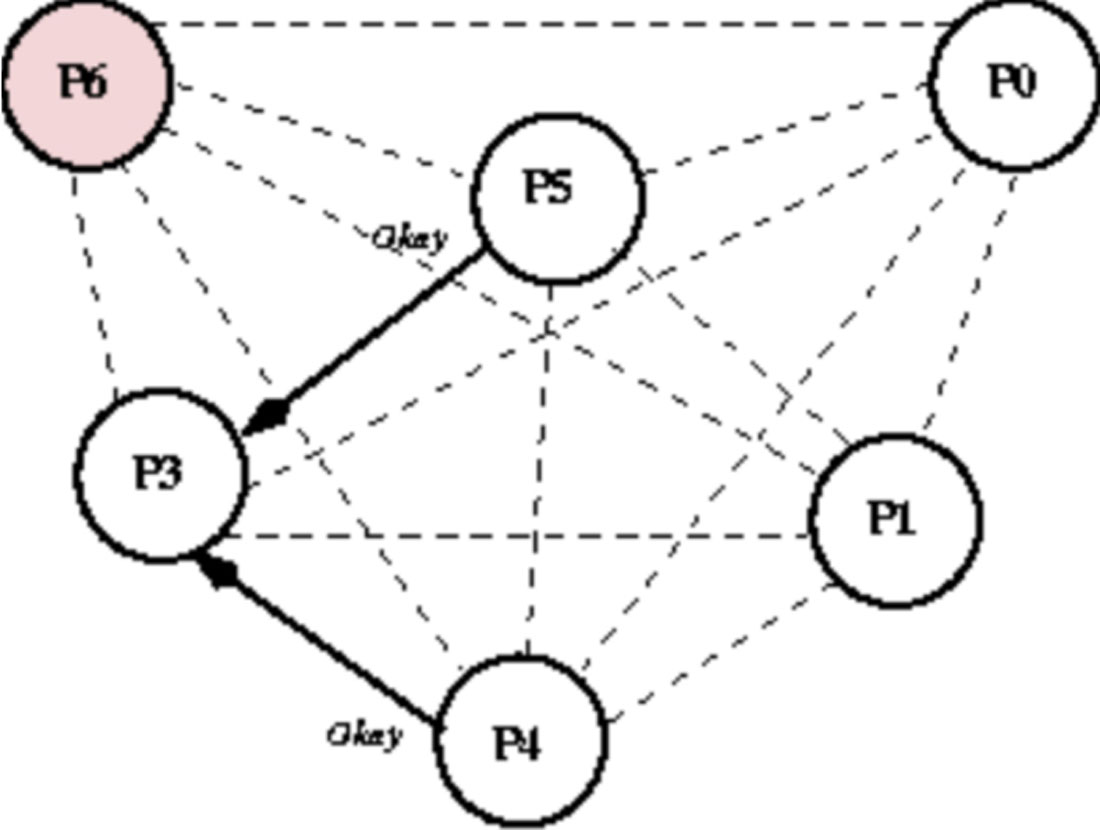
图1-16 霸道选举算法-step3
(5)P4节点发送Election消息通知那些进程ID比P4大的节点P5、P6。只有P5节点回复Alive消息。同理,P4停止发送任何消息,等待Victory消息,具体如图1-17和图1-18所示。
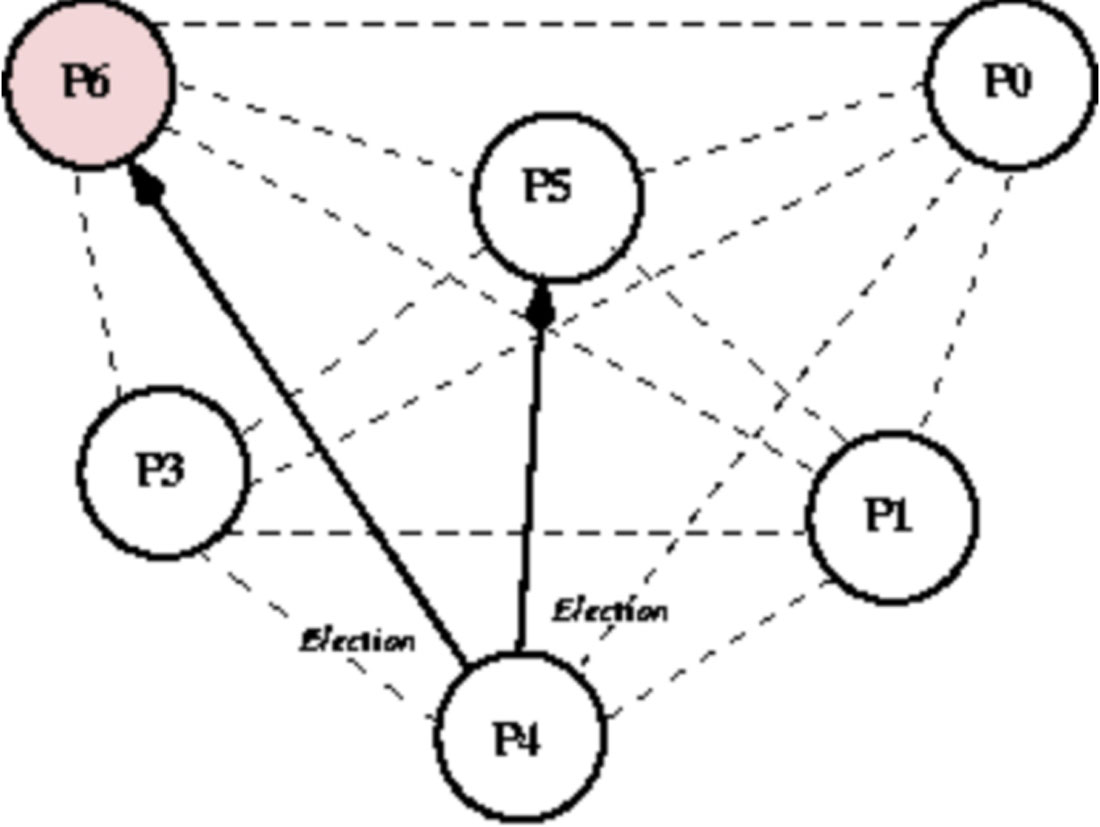
图1-17 霸道选举算法-step4
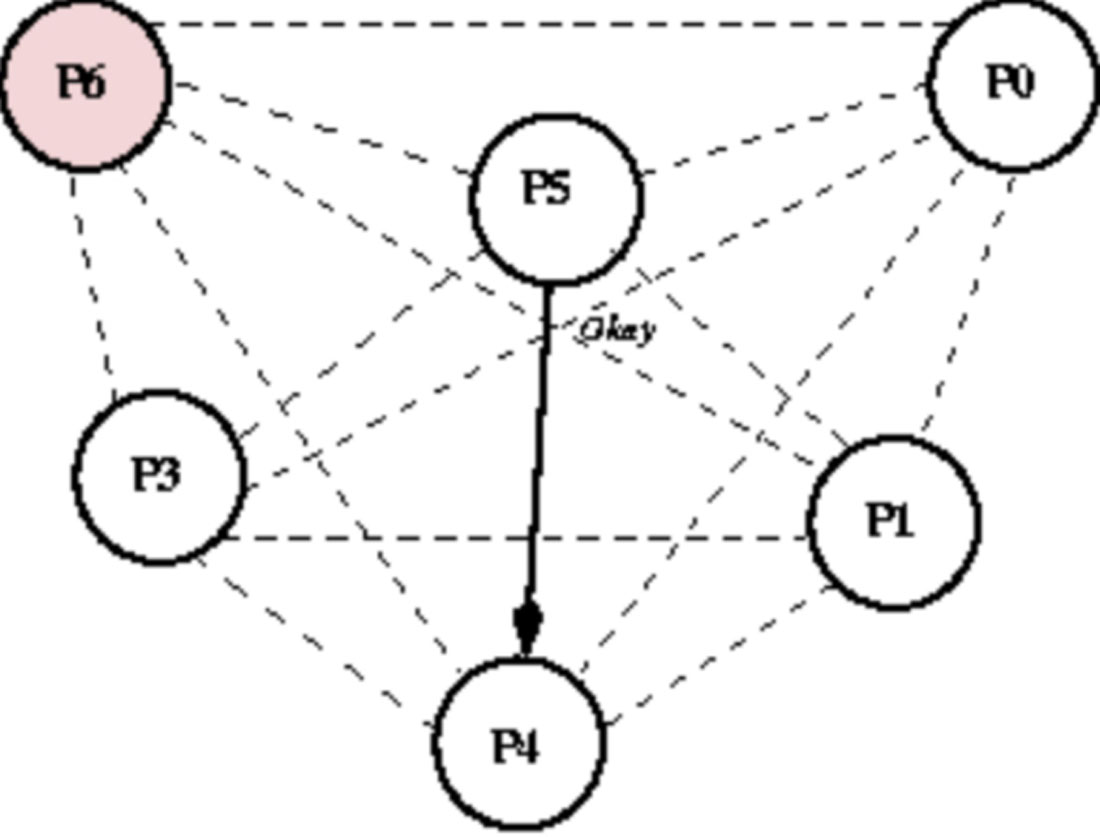
图1-18 霸道选举算法-step5
(6)P5发送Election消息给P6,节点5在发送Election消息后没有收到Alive消息,则P5向所有人发送Victory消息,成为新的Leader,具体如图1-19和图1-20所示。
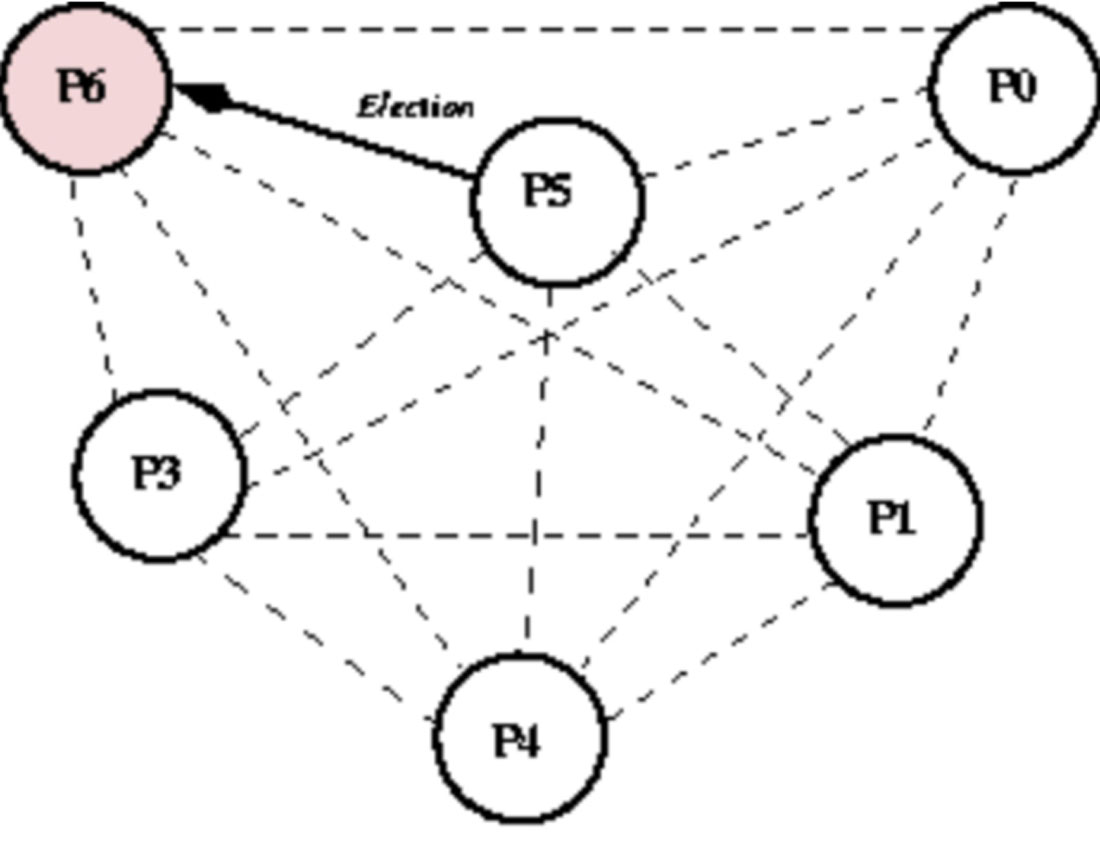
图1-19 霸道选举算法-step6
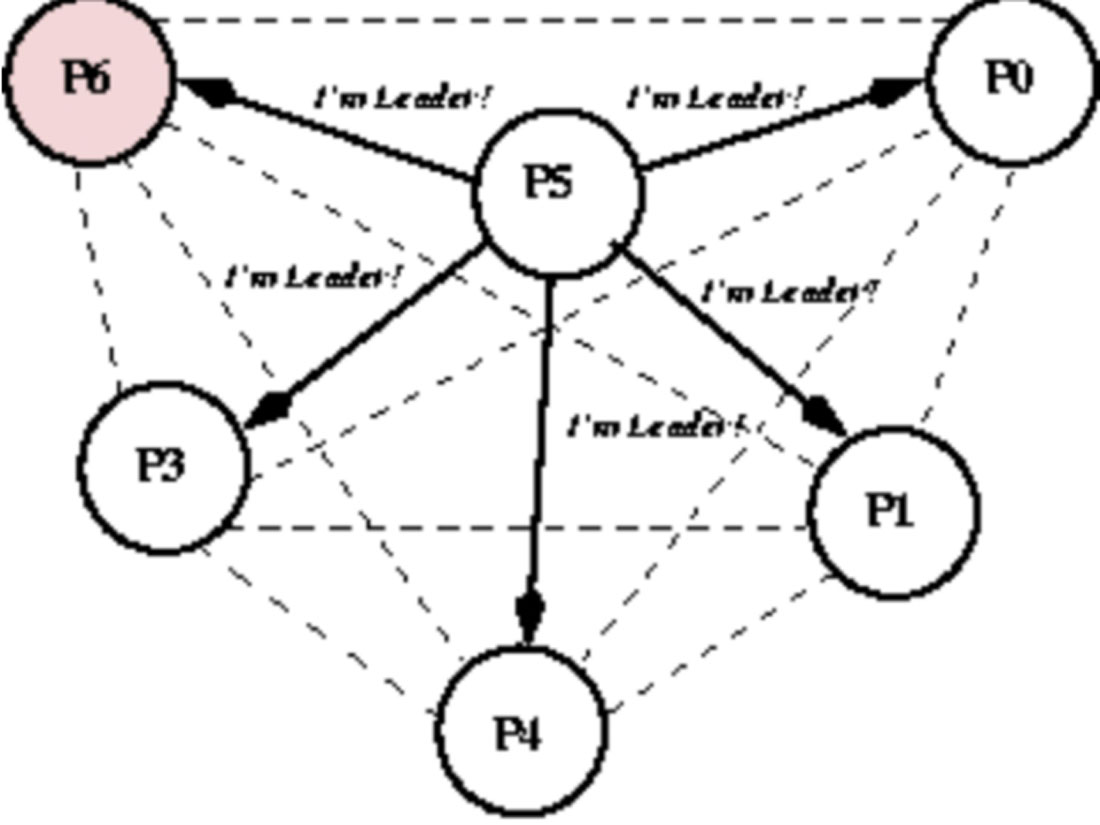
图1-20 霸道选举算法-step7
有以下几种情况会触发选举:
(1)检测到主节点异常。
(2)当节点从错误中恢复。
霸道选举算法霸道且简单,谁活着且谁的ID最大谁就是主节点,其他节点必须无条件服从。霸道选举算法的优点是:选举速度快、算法复杂度低、简单易实现。霸道选举算法的缺点是,需要每个节点有全局的节点信息,因此额外信息存储较多;其次,会导致频繁切主,例如任意一个比当前主节点ID大的新节点或节点故障后恢复加入集群的时候,该节点频繁退出、加入集群都可能会触发重新选举。
Elasticsearch的Master选举采用的就是霸道选举算法,MongoDB的副本集选举采用的也是霸道选举算法。
Raft这一名字来源于Reliable, Replicated, Redundant, And Fault-Tolerant(可靠、可复制、可冗余、可容错)的首字母缩写,是一种用于替代Paxos的共识算法(Paxos算法在1.6.1节会讲述)。
Raft通过选举Leader的方式做共识算法(一切以领导者为准)。在Raft集群(Raft Cluster)中,有3种类型的节点:
(1)领导着(Leader)。
(2)追随者(Follower)。
(3)候选人(Candidate)。
在正常情况下只会有一个领袖,其他都是追随者。领袖会负责所有外部的读和写请求,如果不是领袖的机器收到请求,则请求会被导到领袖。
通常领导会固定时间发送消息,也就是“心跳”,让追随者知道集群的领导还在正常运行。而每个追随者都会设计超时机制,如果超过一定时间没有收到心跳(通常是150 ms或300 ms),集群就会进入选举状态。在Raft算法中,服务器节点间的沟通联络采用的是远程过程调用(RPC)。
Raft将问题拆成数个子问题分开解决,让人更容易理解,分别是:
(1)领导选举(Leader Election)。
(2)日志复制(Log Replication)。
(3)安全性(Safety)。
接下来主要针对Raft的领导选举进行描述,其他内容不在讨论范围内。
Raft领导选举流程如下:
步骤01 在初始状态下,集群中所有的节点N1(超时时间为100ms)、N2(超时时间为200ms)以及N3(超时时间为300ms)都是跟随者的状态,具体如图1-21所示。
步骤02 每个节点等待领导者节点心跳信息的超时时间间隔是随机的。刚开始集群没有领导者,所以超时时间最短的节点N1增加自己的任期编号(Term),并推举自己为候选人,先给自己投上一张选票,然后向其他节点发送请求投票消息,请它们选举自己为领导者,具体如图1-22所示。
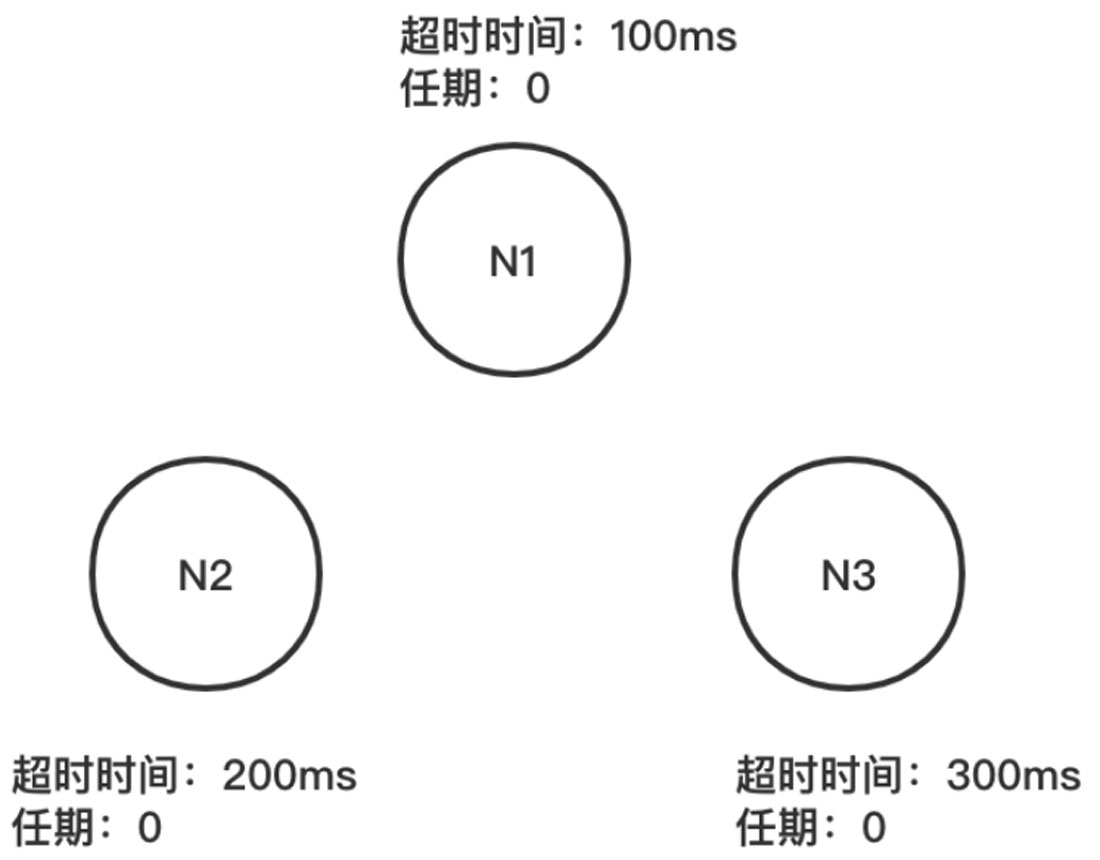
图1-21 Raft选举算法1
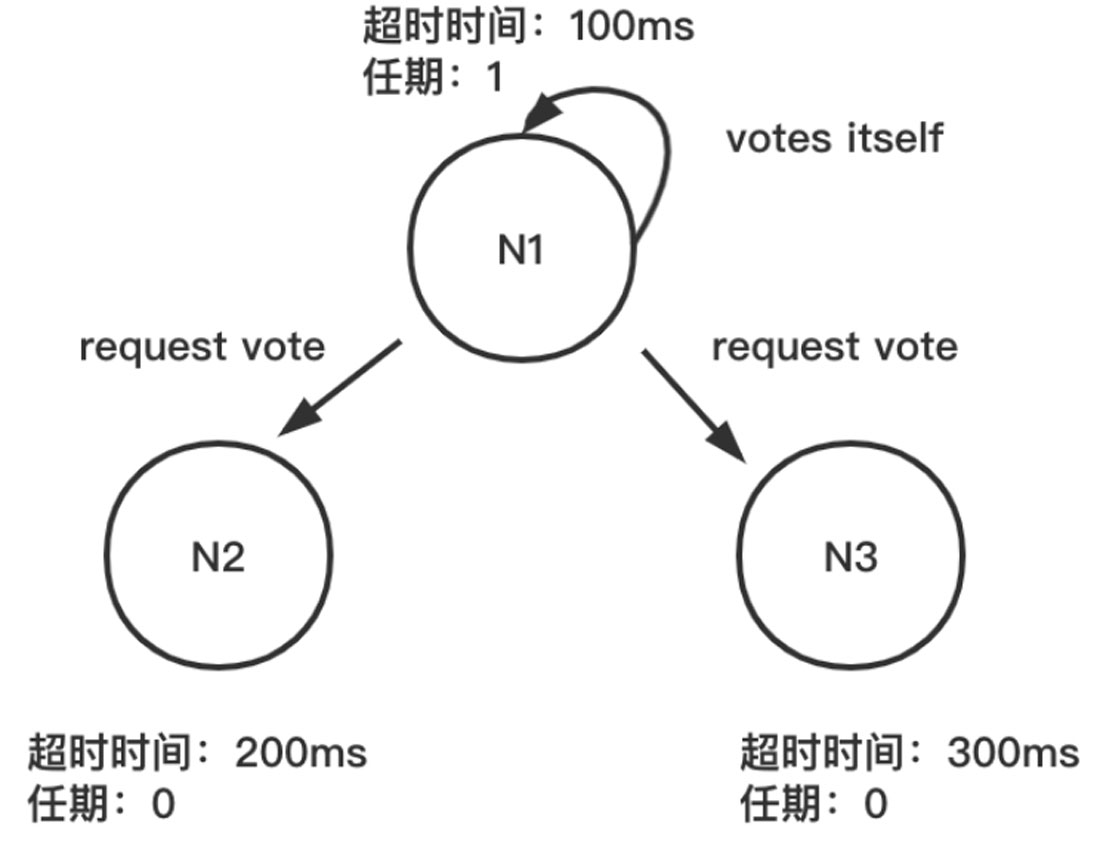
图1-22 Raft选举算法2
步骤03 如果其他节点接收到候选人的请求投票消息,在这届任期内还没有进行过投票,那么将把选票投给节点N1,并增加自己的任期编号,具体如图1-23所示。
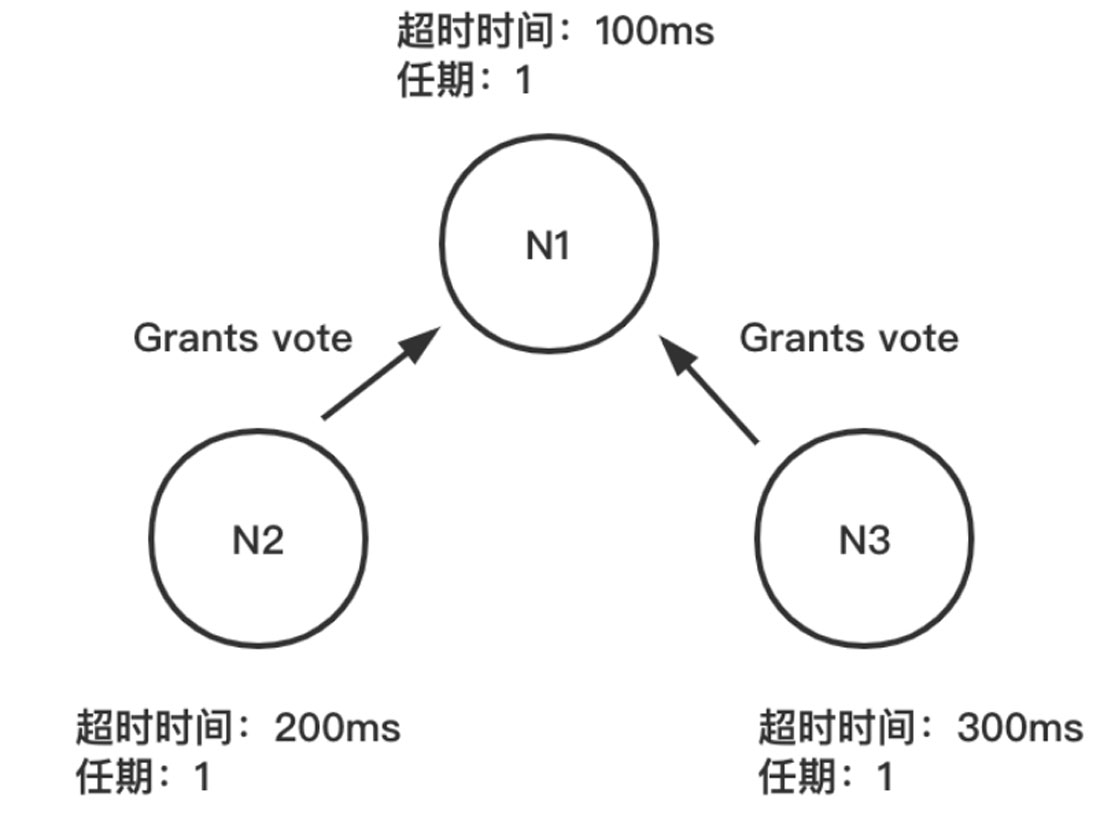
图1-23 Raft选举算法3
步骤04 如果候选人N1在选举超时时间内赢得了大多数的选票,它就会成为本届任期内新的领导者。N1成功当选领导者后,将周期性地发送心跳消息,通知其他服务器自己是领导者,阻止跟随者发起新的选举。
步骤05 每个服务器在每个任期只会投一票,固定投给最早拉票的服务器。选举是由候选人发动的,当领袖的心跳超时的时候,追随者就会把自己的任期编号加一,宣告竞选,投自己一票,并向其他服务器拉票。如果候选人收到其他候选人的拉票,而且拉票的任期编号不小于自己的任期编号,就会自认落选,成为追随者,并认定来拉票的候选人为领袖。如果有候选人收到过半的选票就当选为新的领袖。如果超时仍没有选出新领袖,此任期自动终止,开始新的任期并开始下一场选举。
从上述流程中可以看到,导致任期发生改变主要有以下几种情况:
(1)跟随者在等待领导者心跳信息超时后,推举自己为候选人时,会增加自己的任期号,比如节点N的当前任期编号为0,那么在推举自己为候选人时,会将自己的任期编号增加为1。
(2)如果一个服务器节点发现自己的任期编号比其他节点小,那么它会更新自己的编号到较大的编号值。比如节点B的任期编号是0,当收到来自节点A的请求投票RPC消息时,因为消息中包含节点A的任期编号,且编号为1,所以节点B将把自己的任期编号更新为1。
Raft算法的优点:选举速度快,算法复杂度低,易于实现。
Raft算法的缺点:它要求系统内每个节点都可以相互通信,且需要获得过半的投票数才能选主成功,因此通信量大。
Raft选举算法稳定性比Bully算法好,因为当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非节点获得投票数过半,才会导致切主。
读者可通过https://raft.github.io/链接查看Raft算法的动画演示,加深对Raft算法的理解。
Raft每个服务器的超时期限是随机的,这降低了服务同时竞选的概率,也降低了因两个竞选人得票都不过半而选举失败的概率。集群内的节点都对选举出的领袖采取信任,因此Raft不是一种拜占庭容错算法。
ZAB(ZooKeeper Atomic Broadcast)选举算法是为ZooKeeper实现分布式协调功能而设计的。相较于Raft算法的投票机制,ZAB算法增加了通过节点ID和数据ID作为参考进行选主,节点ID和数据ID越大,表示数据越新,优先成为主。相比较于Raft算法,ZAB算法尽可能保证数据的最新性。所以,ZAB算法可以说是对Raft算法的改进。
ZAB算法选举时,集群节点包含3种角色:
所有的写请求都必须在领导者节点上执行。
跟随者可以直接处理并响应来自客户端的读请求,但对于写请求,跟随者需要将它转发给领导者处理。
在选举过程中,集群中的节点有以下4种状态:
在投票过程中,每个节点都有一个唯一的三元组(server_id, server_zxID, epoch):
ZAB算法选主的原则是server_zxID最大者成为Leader,若server_zxID相同,则server_id最大者成为Leader。具体选举流程如下:
步骤01 有集群节点A(server_id=1)、B(server_id=2)、C(server_id=3),系统刚启动时,集群中所有的节点都为Following状态,3个节点当前投票均为第一轮投票,即epoch=1,且数据zxID均为0。此时每个节点都推选自己,并将选票信息<epoch, zxID,server_id, vote_id,>广播出去,具体如图1-24和图1-25所示。
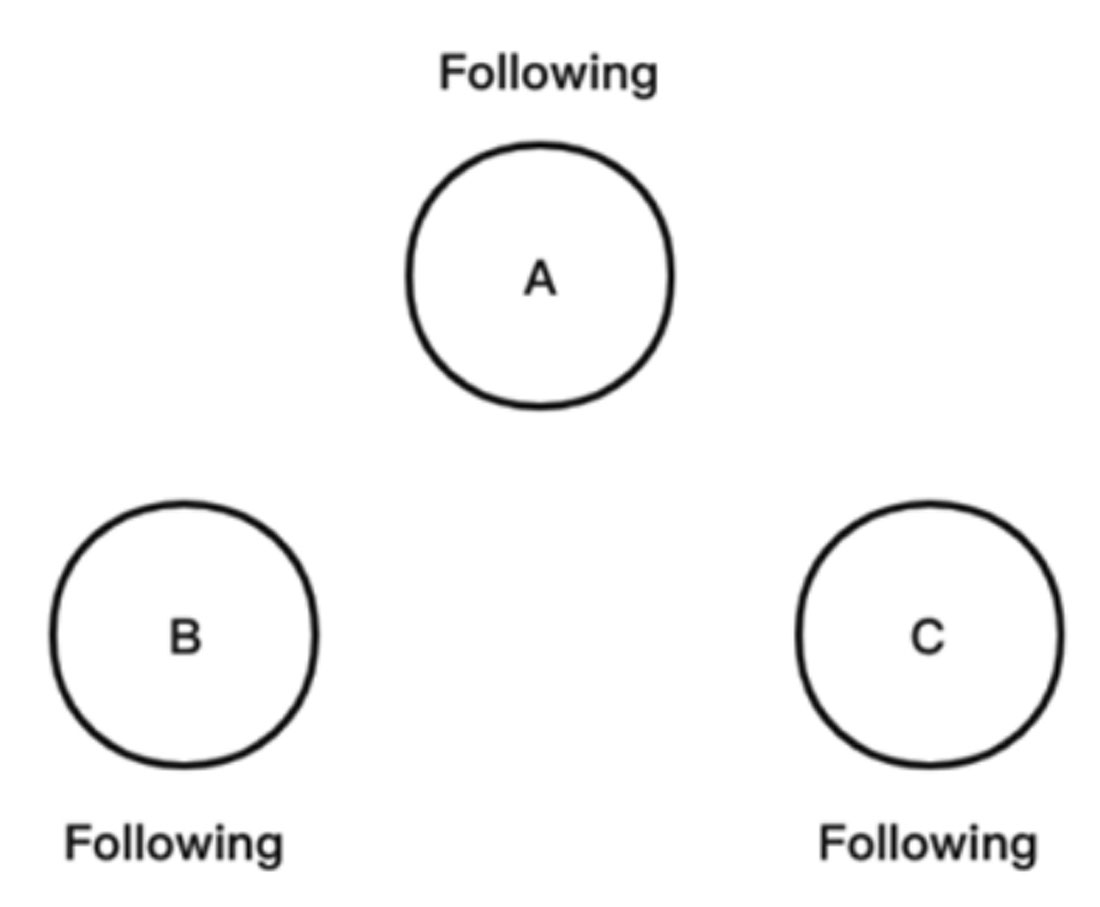
图1-24 ZAB选举算法1
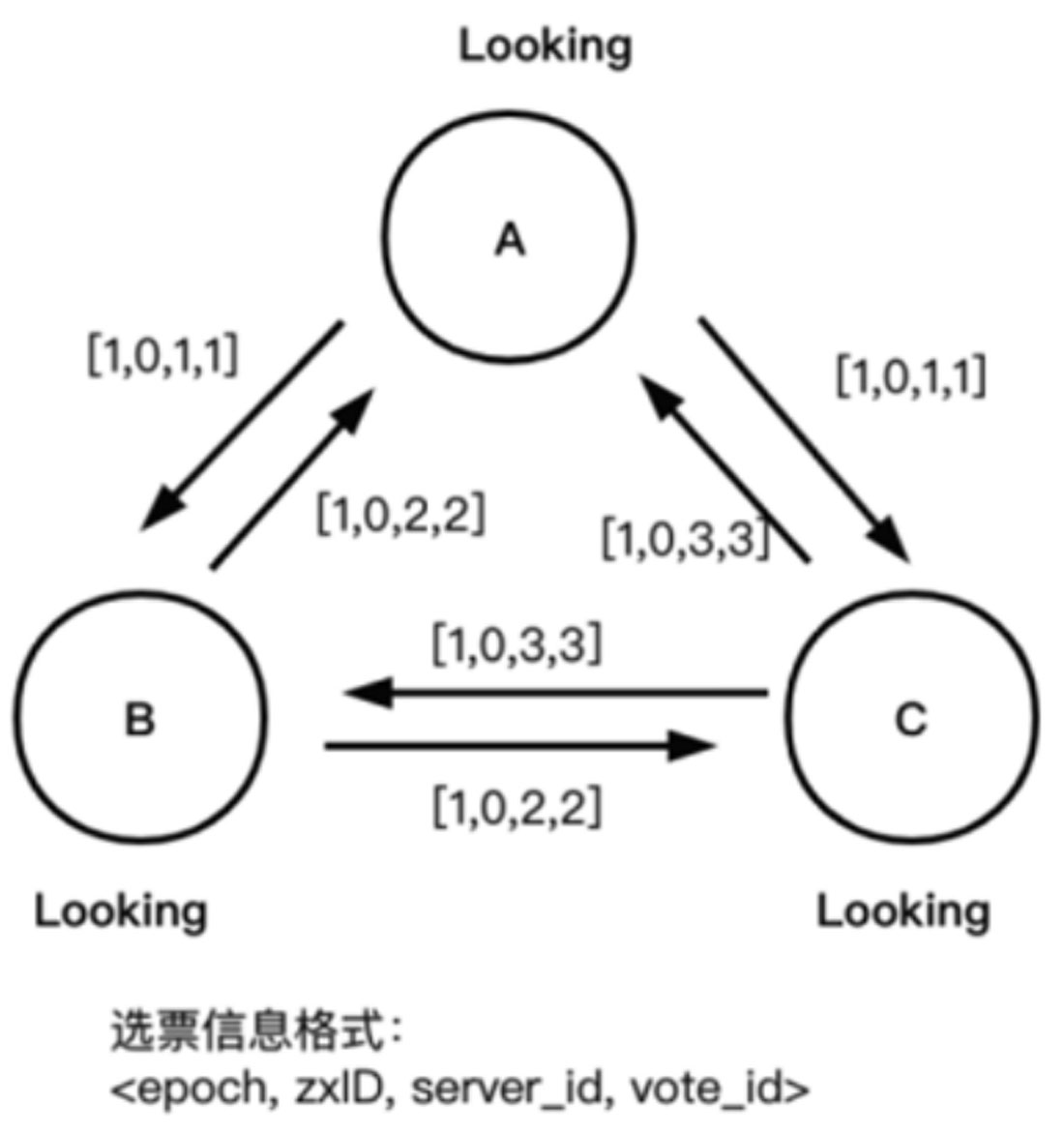
图1-25 ZAB选举算法2
步骤02 由于3个节点的epoch、zxID都相同,节点收到其他节点的投票消息后,比较zxID和server_id,较大者即为推选对象,因此节点A和节点B将vote_id改为3,更新自己的投票箱并重新广播自己的投票,具体如图1-26所示。
步骤03 此时所有节点都推选节点C,因此节点C计算得票数,如果超过集群中节点的半数就当选Leader,处于Leading状态,向其他节点发送心跳包并维护连接。此时节点A和节点B切换为Following状态,具体如图1-27所示。
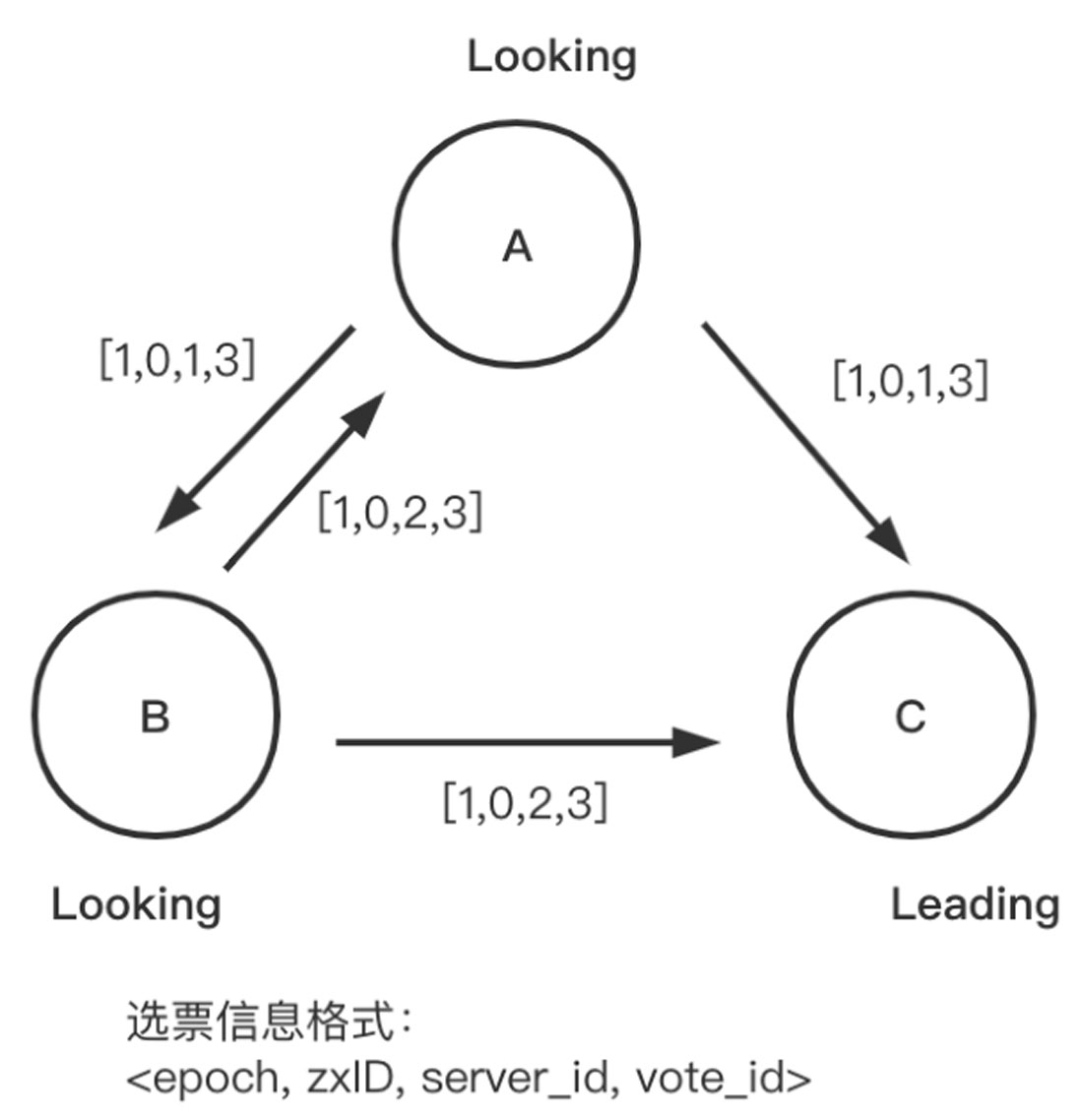
图1-26 ZAB选举算法3
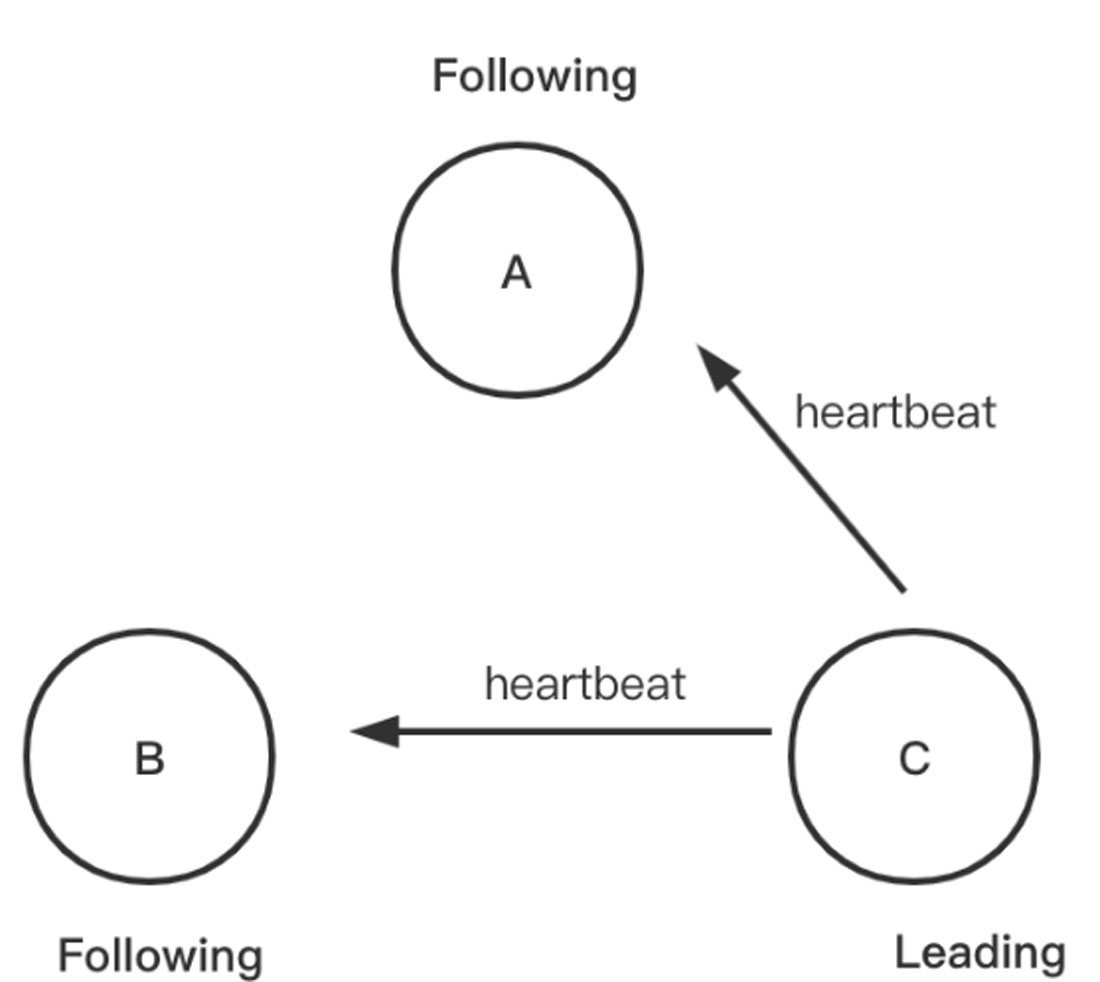
图1-27 ZAB选举算法4
步骤04 当跟随者A、B检测到连接领导者节点C的读操作等待超时时,跟随者会变更节点状态,将自己的节点状态变更成Looking,然后发起领导者选举。
步骤05 每个节点会创建一张选票,这张选票是投给自己的,也就是说,节点A、B推荐自己为领导者,并创建选票,然后各自将选票发送给集群中的所有节点,也就是说,A发送给A、B,B也发送给A、B。
步骤06 A和B节点按照如下规则操作:
步骤07 最后,因为此时节点A、B提议的领导者(节点B)赢得了大多数选票(2张选票),所以节点A、B将根据投票结果变更节点状态并退出选举。比如,因为当选的领导者是节点B,所以节点A将变更状态为Following并退出选举,而节点B将变更状态为Leading并退出选举。