
下载掌阅APP,畅读海量书库
立即打开



所谓训犬,就是教导狗狗的过程。
但是,正如琼·唐纳森在The Culture Clash一书中揭示的关于狗狗的十大真相之一:狗狗的大脑只有柠檬那么大,它们不会进行逻辑思考,它们听不懂人类的语言。那么它们如何学习呢?
和所有的动物一样,狗狗主要通过以下三个基本原理进行学习。
第一,经典条件反射。
第二,操作条件反射。
第三,孤立事件学习。
经典条件反射,就是我们所熟知的巴甫洛夫条件反射。
俄国生理学家巴甫洛夫发现,当饥饿的狗狗看见食物时,会不由自主地流口水。后来他开始在每次给狗狗提供食物前先摇铃。结果过了一段时间后,狗狗一听到铃声,即使没有看见食物,也会开始流口水,这与它们看见食物的反应一样!
食物是一种非条件刺激。狗狗看见食物流口水的本能反应,叫作非条件反射。铃声本来是一种中性的刺激,不会引起流口水这种反应。但多次重复先让狗狗听到铃声,然后立即提供食物的过程,狗狗的大脑里就建立了铃声和食物之间的联系,所以当狗狗一听到铃声,即使没有看见食物,也会产生和看见食物时相同的反应——流口水。这时候,铃声就成为一种条件刺激,而听见铃声流口水的反应就称为条件反射。
经典条件反射在训犬中主要用于让狗狗能对人类的指令产生反应。
例如当训犬师手拿食物在狗狗眼睛上方的位置逐渐向头顶移动的时候,狗狗为了看见食物会不由自主地由站姿变成坐姿。如果训犬师每次先发出“坐下”的口令,然后立即拿出食物诱导狗狗坐下,重复几次之后,即使不看见食物,听到“坐下”的口令,狗狗也能立即坐下。在这个例子中,食物是非条件刺激,看见食物坐下是非条件反射。经过训练之后,“坐下”这个口令就成为和食物相关联的条件刺激,听见“坐下”的口令就坐下的反应就是条件反射。
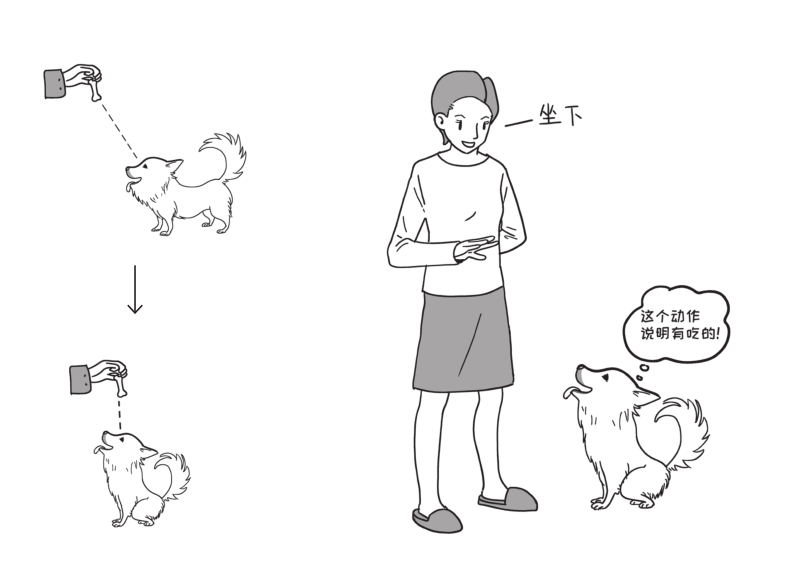
另外一个典型的例子就是每次在给狗狗食物奖励之前,先进行口头表扬,如“乖宝宝”。这样狗狗以后只要听到“乖宝宝”,即使没有食物奖励,狗狗也会产生和得到食物奖励相同的愉快反应。在这个例子中,食物是非条件刺激,得到食物产生愉快的反应是非条件反射。经过训练之后,“乖宝宝”这个口令就成为和食物相关联的条件刺激,听见“乖宝宝”的口令产生愉快的反应就是条件反射。
在运用经典条件反射的原理训犬时,最重要的是要注意非条件刺激要紧随条件刺激之后,条件刺激和非条件刺激之间有一段重叠的时间,这样才能迅速而稳固地建立起条件刺激和非条件刺激之间的联系。只有建立起了两者之间的联系,原本中性的刺激才能成为条件刺激,引起条件反射。
我在2013年4月收养了5只才十几天大的小猫。在给小猫喂食的时候,我总是先吹一下口哨,然后在口哨声中把食物放在它们面前,等它们吃了几秒钟后再停止吹口哨。结果只经过了4次,小猫无论身处何处,只要一听见我的口哨声就迅速在它们的饭桌上集合等待开饭,可爱极了!您现在能说出在这个案例中的条件刺激和条件反射分别是什么吗?对了!口哨声就是条件刺激。小猫听见口哨声立即到饭桌上集合的行为就是条件反射!
简单来说,通过经典条件反射,狗狗可以学会在接收到条件刺激的时候,预测即将发生的事情。狗狗听见“坐下”的时候,预测到主人会拿出食物来,所以做出了和看见食物一样的反应。狗狗在听见“乖宝宝”的时候,预测到自己马上会得到食物奖励,所以产生了和得到食物奖励相同的愉快反应。小猫在听见口哨声的时候,预测到马上要开饭了,所以产生了和开饭时相同的反应。很多狗主人觉得自家的狗很聪明,只要一看见主人拿起牵引绳,就高兴得活蹦乱跳,好像知道主人马上就会带自己去散步。这其实也是一个典型的条件反射的例子。
操作条件反射,也称为斯金纳条件反射。
美国心理学家B.F斯金纳(B.F Skinner)认为,如果一个操作发生后,紧接着给一个强化刺激,那么其强度就会增加。所谓操作条件反射,就是指我们做了某件事情就一定会产生某种后果,而通过这种后果,动物会认识到自己的行为和后果之间的关系。
如果后果是令人愉快的,则先前的行为再次发生的可能性就会增大;如果后果是令人不愉快的,则先前的行为再次发生的可能性就会减小。(美国心理学家桑代克(Thorndike)的效果律)
操作后果一共会有四种情况,其中两种情况会使行为重复发生的可能性增大,而另外两种情况则会使行为重复发生的可能性减小。
使行为重复发生的可能性增大的两种情况都是对先前行为的强化。
一种叫作正向强化。
正向强化是指当狗狗做出某种反应后使其得到一种好的后果。简而言之,就是让好事开始。例如在训练狗狗定点大小便时,每次狗狗在规定地点大小便后,立即给予零食奖励。这样就会提高下次狗狗在该地点大小便的可能性。正向强化也同样适用于人类:小孩子帮妈妈做了家务,就得到零用钱,以后小孩子做家务的积极性就会提高;员工工作认真,被评为先进,以后员工会更认真地工作。
另一种叫作负向强化。
负向强化是指当狗狗做出某种反应后使其免除某种坏的后果。简而言之,就是让坏事结束。例如在传统训犬中所运用的带齿项圈,项圈上的针齿会刺痛狗狗的颈部,而当狗狗按照口令做出训练员期望的动作时,项圈就会放松,疼痛消除。人类运用负向强化的例子有:楼下的人用拖把柄敲打天花板来抗议楼上发出的噪声,噪声消失就停止敲打;服刑的犯人如果表现好,可以获得减刑。
使行为重复发生的可能性减小的两种情况都是对先前行为的惩罚。
一种叫作正向惩罚。
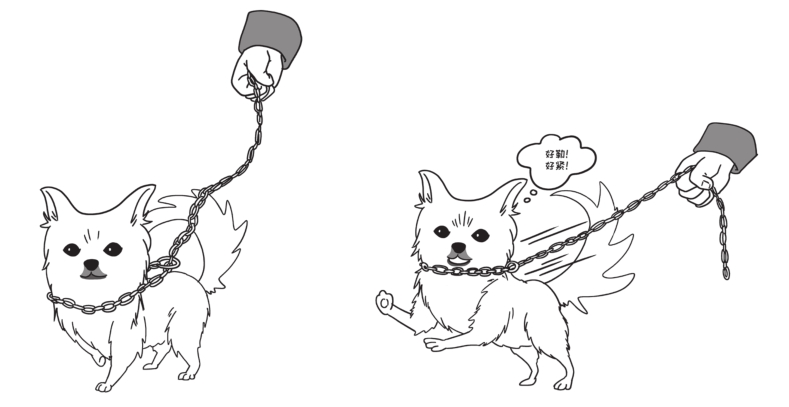
正向惩罚是指当狗狗做出某种反应时使其得到一种坏的后果。简而言之,就是让坏事开始。例如狗狗在地毯上大小便,主人将报纸卷成筒状打狗狗,这样会减小下次狗狗在地毯上大小便的可能性。又例如在传统训犬中所运用的P字链。当狗狗往前冲时,链条自动收紧,勒痛狗狗的喉部,从而减小下次狗狗往前冲的可能性。人类常使用正向惩罚:孩子不听话或犯错误,妈妈就会处罚孩子;员工违反规章制度,就被警告处分;驾驶员闯红灯,交警就过来开罚单。
另一种叫作负向惩罚。
负向惩罚是指当狗狗做出某种反应后取消某种好的后果。简而言之,就是让好事结束。例如在命令狗狗“坐下”的时候,它没有坐下,而是扑上来想要抢你手中的零食,你就取消本来要给它的零食,这样下次它扑上来抢零食的可能性就会减小。人类运用负向惩罚的例子有:小孩子不听话,就取消其晚上看动画片的奖励;员工工作不努力,就被扣发年终奖。
强化用于我们希望狗狗做出某种行为的时候。正向强化的训练方法对狗狗来说不但没有痛苦,而且会使其非常愉快,是真正的“寓教于乐”,效果也非常好,是目前训犬的流行趋势。本书中运用的强化方法都是正向强化。
惩罚用于我们不希望狗狗做出某种行为的时候。负向惩罚对狗狗的身体没有伤害,却能起到很好的惩罚效果。本书中运用的惩罚方法基本都是负向惩罚。
负向强化和正向惩罚都是运用体罚的方式,对狗狗的身心会造成很大伤害,已经逐渐被人们淘汰。此外,这两种方法运用不当时,很容易遭到狗狗的反抗,造成狗咬主人之类的情况。如果您正准备把自家的狗狗送到训犬学校去“深造”,请一定要搞清楚对方所采用的训练方法是正向强化还是负向强化,是正向惩罚还是负向惩罚。
操作条件反射在训犬中应用最为广泛。总的来说可以分为两大类:一是通过强化使狗狗做出我们希望狗狗做的各种动作(最普遍的就是在狗狗做出我们所希望的动作之后给予食物奖励);二是通过惩罚使狗狗不再做出我们所不希望的行为(最普遍的就是在狗狗做出我们不希望的行为之后取消食物奖励)。
有效强化和惩罚的关键是保证及时性,也就是在狗狗做出相应的行为之后,立即进行奖励或者惩罚,正所谓“赏不逾时,罚不迁列”;否则有可能会强化错误的行为。例如在我们发出“坐下”的口令之后,狗狗按照口令“坐下”了,但是我们身边没有奖励食品,等我们从厨房去拿了食物出来后,狗狗很有可能已经变成站姿并且盯着食物看。如果这时候我们把食物作为奖励给狗狗,其实就是强化了“站着盯着食物看”这个行为,而不是我们真正希望强化的“坐下”这个行为。又例如主人下班回家发现狗狗在家里搞了破坏,就把狗狗叫过来打了一顿。但是狗狗并不能理解主人是因为自己搞破坏而发怒(因为没有当场被阻止),而是会误认为主人回来,自己听从召唤走到主人身边就要挨揍了。于是第二天主人去上班后,狗狗继续搞破坏。等主人回来后,无论怎么叫,狗狗都躲在床下不出来。而主人还以为是狗狗“知错了”。
简单来说,通过操作条件反射,狗狗可以学到自己的某种行为会带来什么样的后果,从而根据后果的好坏来强化或者停止该种行为。记住,狗狗总是努力让好事开始、坏事结束,避免好事结束、坏事开始,即趋利避害。如果您能知道什么事情对狗狗来说是好事,什么是坏事,并且能控制这些事情,那么恭喜您,您一定能控制狗狗的行为!
所谓孤立事件,就是指某件发生的事情(一种刺激)不和任何其他事情相关联。如果某种刺激不会产生任何后果(相对于动物来说),动物就会停止对该刺激产生反应。这种现象称为“学习到的不相关性”。学习到的不相关性对动物来说能提高效率,因为动物应该学会忽略对自己不重要的刺激,而把注意力集中在对自己重要的刺激上。
在预防狗狗乞食的训练中,主人如果做到自己吃东西的时候从不跟狗狗分享,狗狗就会学习到主人吃东西和自己的不相关性,从而放弃乞食,宁愿到一边去睡觉。

另外一个关于学习到的不相关性的例子就是电话铃声。大部分狗狗会学习到电话铃响跟自己毫不相干。因为电话铃响后从来没有对狗狗产生任何相关的后果,于是狗狗就学会了自动屏蔽电话铃声,也就是在电话铃响时不做任何反应。
简单来说,通过孤立事件的学习,狗狗可以学到什么重要、什么不重要。
以上内容理论部分根据帕梅拉·J. 里德博士(Dr.Pamela J.Reid)的Excel-Erated Learning整理。