
下载掌阅APP,畅读海量书库
立即打开



CART回归树和CART分类树最大的区别在于输出:如果输出的是离散值,则它是一棵分类树;如果输出的是连续值,则它是一棵回归树。
对于回归树,每一个节点都可以被认为是一个回归值,只不过这个值不是最优回归值,只有最底层的节点回归值可能才是理想的回归值。一个节点有回归值,也有分割选择的属性。这样给定一组特征,就知道最终怎么去回归以及回归得到的值是多少了。
在本章中,介绍CART回归决策树时,使用最小二乘法。直觉上,回归树构建过程中,分割是为了最小化每个节点中样本实际观测值和平均值之间的残差平方和。
给定一个数据集D={(x 1 ,y 1 ),(x 2 ,y 2 ),…,(x i ,y i ),…,(x n ,y n )},其中x i 是一个m维的向量,即x i 含有k个特征,记为变量X,是自变量,每个特征记为x j (j=1,2,…,k),y是因变量。回归问题的目标就是构造一个函数f(X)以拟合数据集D中的样本,使得该函数的预测值与样本因变量实际值的均方误差最小,即

用CART进行回归,目标也是一样的,即最小化均方误差。假设一棵构建好的CART回归树有M个叶子节点,这意味着CART将m维输入空间X划分成了M个单元R 1 ,R 2 ,…,R M ,同时意味着CART至多会有M个不同的预测值。CART最小化均方误差公式如下:

其中,c m 表示第m个叶子节点的预测值。
想要最小化CART回归树总体的均方误差,只需要最小化每一个叶子节点的均方误差即可,而最小化一个叶子节点的均方误差,只需要将预测值设定为叶子中含有的训练集元素的均值,即

所以,在每一次分割时,需要选择分割特征变量(splitting variable)和分割点(splitting point),使得模型在训练集上的均方误差最小。
这里采用启发式的方法,遍历所有的分割特征变量和分割点,然后选出叶子节点均方误差之和最小的那种情况作为划分。选择第j个特征变量x j 和它的取值s,作为分割变量和分割点,则分割变量和分割点将父节点的输入空间一分为二:
R 1 {j,s}={x|x (j) ≤s}
R 2 {j,s}={x|x (j) >s}
CART选择分割特征变量x j 和分割点s的公式如下:
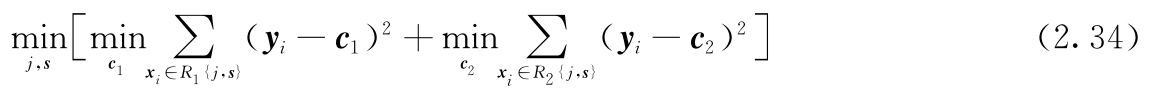
采取遍历的方式,我们可以求出j和s。先任意选择一个特征变量x
j
,再选出在该特征下的最佳划分s;对每一个特征变量都这样做,得到k个特征的最佳分割点,从这k个值中取最小值即可得到令全局最优的(j,s)。上式中,第一项
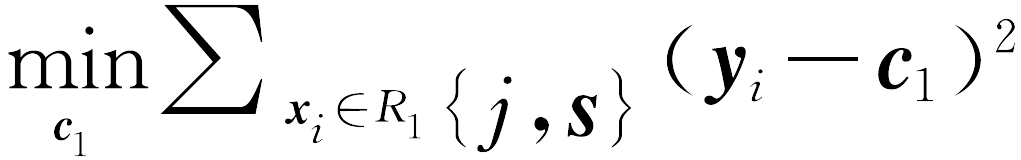 得到的c
1
值就是ave(y
i
|x
i
∈R
1
{j,s}),同理,第二项中c
2
=ave(y
i
|x
i
∈R
2
{j,s})。根据这个(j,s)就可以构建一个节点,然后形成两个子区间。之后分别对这两个子区间继续上述过程,就可以继续创建回归树的节点,直到满足结束条件才停止对区间的划分。
得到的c
1
值就是ave(y
i
|x
i
∈R
1
{j,s}),同理,第二项中c
2
=ave(y
i
|x
i
∈R
2
{j,s})。根据这个(j,s)就可以构建一个节点,然后形成两个子区间。之后分别对这两个子区间继续上述过程,就可以继续创建回归树的节点,直到满足结束条件才停止对区间的划分。
最小二乘回归树生成算法的主要思路为在训练数据集所在的输入空间中,递归地将每个区域划分为两个子区域并决定两个子区域上的输出值,构建二叉决策树。其输入为训练数据集D,输出为回归树f(x)。具体的算法流程如下:
1)选择最优切分变量j与切分点s,求解式(2.34)。遍历变量j,对固定的切分变量j扫描切分点s,选择使式(2.34)达到最小值的对(j,s)。
2)用选定的对(j,s)划分区域并决定相应的输出值。
3)继续对两个子区域调用步骤1和2直至满足停止条件。
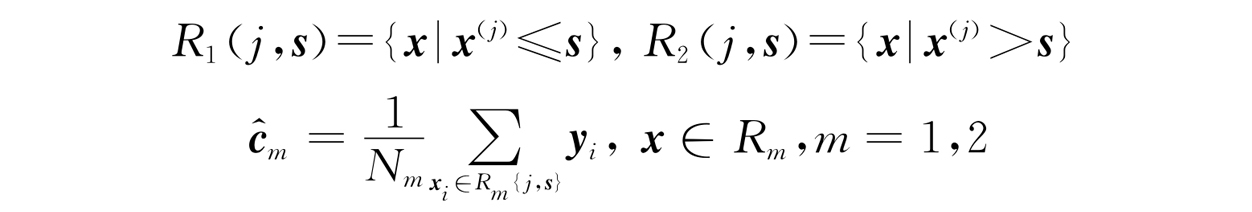
4)将输入空间划分为M个区域R 1 ,R 2 ,…,R M ,生成决策树:
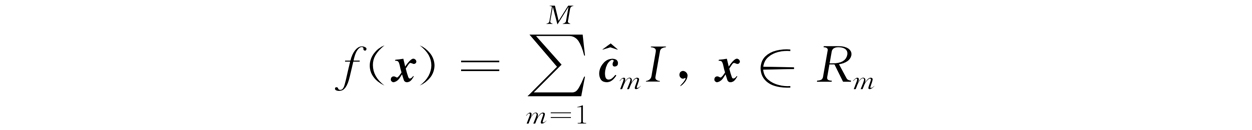
下面我们举一个例子,看看CART回归树的构建过程。假设有如表2.11所示的一个数据集,描述了几个不同年龄的人的性别和月支出情况,以及他们对流行歌手的喜好度(0~100的数值)。利用CART回归树建立决策树模型,并预测如果一个人26岁、男、月支出3000,那么他对流行歌手的喜好度应该是多少。
表2.11 流行歌手的喜好度调查表
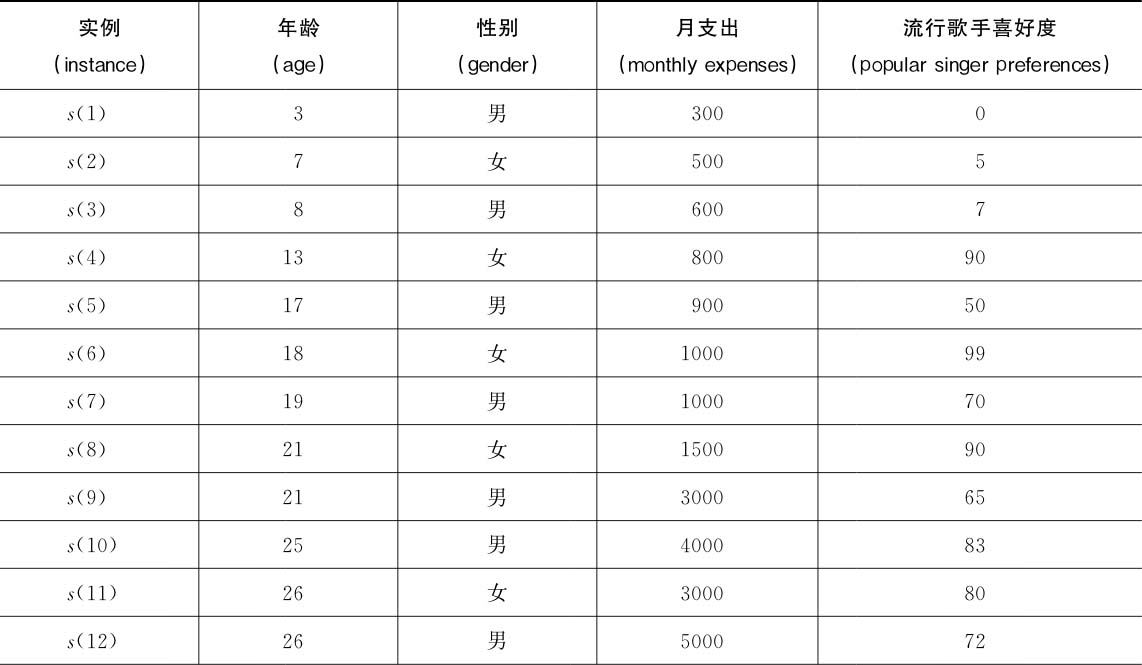
(续)
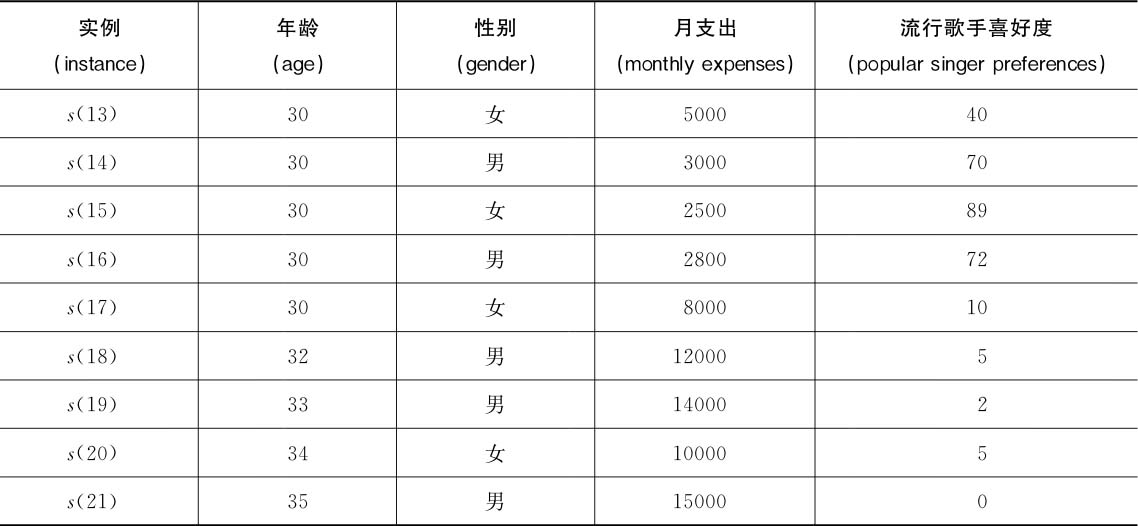
在该数据集中,年龄、性别、月支出为特征变量,流行歌手喜好度为标签值。首先我们考虑年龄特征,将年龄字段对应的属性值去重并进行升序排序得到属性集{3,7,8,13,17,18,19,21,25,26,30,32,33,34,35},计算相邻两个属性值的均值作为候选切分点,这样我们得到一个切分点候选集{5.0,7.5,10.5,15.0,17.5,18.5,20.0,23.0,25.5,28.0,31.0,32.5,33.5,34.5}。选取第一个取值(5.0)作为分割点,划分得到两个子区域R 1 和R 2 :
R 1 ={s(1)}
R 2 ={s(2),s(3),s(4),s(5),s(6),s(7),s(8),s(9),s(10),s(11),s(12),s(13),
s(14),s(15),s(16),s(17),s(18),s(19),s(20),s(21)}
接着我们计算各子区域的标签值均值c(left)和c(right):
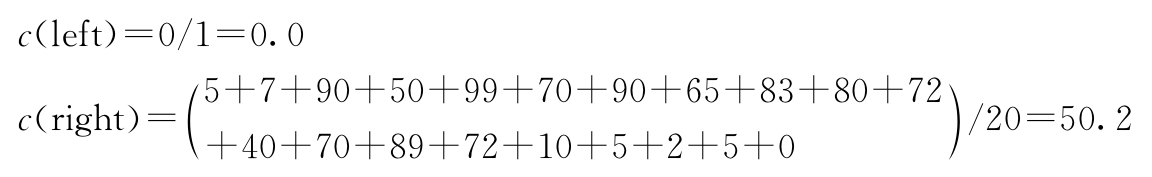
计算平方误差:
m(R 1 )=(0-0.0) 2 =0.0
m(R 1 )=(5-50.2) 2 +(7-50.2) 2 +(90-50.2) 2 +(50-50.2) 2
+(99-50.2) 2 +(70-50.2) 2 +(90-50.2) 2 +(65-50.2) 2
+(83-50.2) 2 +(80-50.2) 2 +(72-50.2) 2 +(40-50.2) 2
+(70-50.2) 2 +(89-50.2) 2 +(72-50.2) 2 +(10-50.2) 2
+(5-50.2) 2 +(2-50.2) 2 +(5-50.2) 2 +(0-50.2) 2
=25531.2
m(5.0)=m(R 1 )+m(R 2 )=0+25531.2=25531.2
考虑将年龄的第二个取值(7.5)作为分割点,划分得到子区域R 1 和R 2 :
R 1 ={s(1),s(2)}
R 2 ={s(3),s(4),s(5),s(6),s(7),s(8),s(9),s(10),s(11),s(12),
s(13),s(14),s(15),s(16),s(17),s(18),s(19),s(20),s(21)}
计算各子区域的标签值均值:
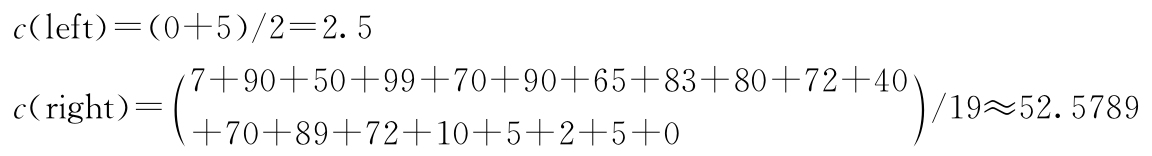
计算平方误差:
m(R 1 )=(0-2.5) 2 +(5-2.5) 2 =12.5
m(R 2 )=(7-52.5789) 2 +(90-52.5789) 2 +(50-52.5789) 2 +(99-52.5789) 2
+(70-52.5789) 2 +(90-52.5789) 2 +(65-52.5789) 2 +(83-52.5789) 2
+(80-52.5789) 2 +(72-52.5789) 2 +(40-52.5789) 2 +(70-52.5789) 2
+(89-52.5789) 2 +(72-52.5789) 2 +(10-52.5789) 2 +(5-52.5789) 2
+(2-52.5789) 2 +(5-52.5789) 2 +(0-52.5789) 2
≈23380.6316
m(7.5)=m(R 1 )+m(R 2 )=12.5+23380.6316=23393.1316
一直计算到最后一个取值(34.5)。其中,第11个取值(31.0)得到的平方误差最小,其计算过程为,选取31.0作为分割点,划分得到子区域R 1 :
R 1 ={s(1),s(2),s(3),s(4),s(5),s(6),s(7),s(8),s(9),s(10),s(11),s(12),
s(13),s(14),s(15),s(16),s(17)}
R 2 ={s(18),s(19),s(20),s(21)}
计算子区域的标签值均值以及平方误差:
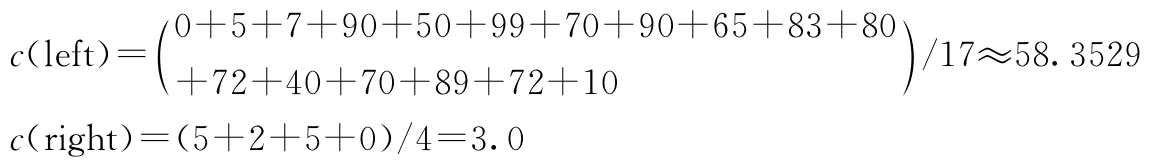
m(R 1 )=(0-58.3529) 2 +(5-58.3529) 2 +(7-58.3529) 2 +(90-58.3529) 2
+(50-58.3529) 2 +(99-58.3529) 2 +(70-58.3529) 2 +(90-58.3529) 2
+(65-58.3529) 2 +(83-58.3529) 2 +(80-58.3529) 2 +(72-58.3529) 2
+(40-58.3529) 2 +(70-58.3529) 2 +(89-58.3529) 2 +(72-58.3529) 2
+(10-58.3529) 2
≈17991.8824
m(R 2 )=(5-3.0) 2 +(2-3.0) 2 +(5-3.0) 2 +(0-3.0) 2 =18.0
m(31.0)=m(R 1 )+m(R 2 )=17991.8824+18.0=18009.8824
遍历了年龄特征之后,我们选择年龄特征的最优切分点“年龄=31.0”。同样,对于性别和月支出特征,我们用同样的步骤计算各分割点对应的平方误差,得到与之对应的最优切分点如下:
m(0.5)=m(R 1 )+m(R 2 )=13398.2222+13358.6667=26756.8889
m(6500.0)=m(R 1 )+m(R 2 )=15507.75+57.2=15564.95
比较以上对年龄、性别和月支出特征的计算,我们选取平方误差最小的特征——分割点对(j,s),即“月支出,6500.0”。由此将数据集分割为两区域R 1 和R 2 :
R 1 ={s(1),s(2),s(3),s(4),s(5),s(6),s(7),s(8),s(9),s(10),s(11),
s(12),s(13),s(14),s(15),s(16)}
R 2 ={s(17),s(18),s(19),s(20),s(21)}
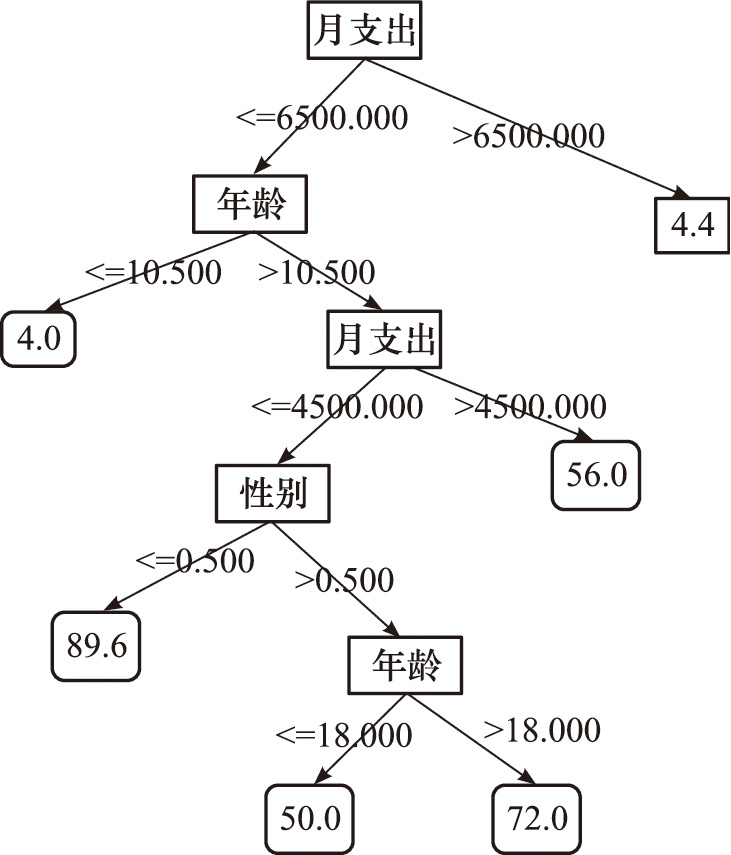
图2.18 CART回归决策树
接下来,我们继续对划分得到的R 1 和R 2 分别求解最优特征及其划分点,递归进行操作,直到满足结束条件。最终得到的决策树如图2.18所示。
通过上述例子可以发现,如果你在同一个时刻对某一个特征变量x j 选择两个分割点s1和s2来划分父节点,那么就将产生三个区间R 1 {j,s 1 }、R 2 {j,s 1 ,s 2 }、R 3 {j,s 2 },这种做法无疑增大了遍历的难度。如果选择更多个分割点,那么遍历的难度会指数上升。如果我们想要细分多个区域,让CART回归树更深即可,这样遍历的难度会小很多。所以,固然可以构建非CART回归树,但是不如CART回归树来得更简单。