下载掌阅APP,畅读海量书库
立即打开



百科全书(Encyclopaedia或Encyclopedia)是指一种大型参考书,常采用词典的形式编排,收录各科专门名词、术语、分列条目、详细解说,比较完备地介绍文化科学知识,是对人类过去积累知识的书面概要。百科全书按种类可分为包罗万象的综合性的百科全书和专科性的百科全书,专科性的百科全书有医学百科全书、工程技术百科全书等。
网络百科全书是百科全书的网络版,通过集中式或分布式的架构,将百科全书的内容存储在互联网平台上,并基于检索和索引算法,将网络百科全书以网页的形式展现给用户。
可以确定地说,没有任何一部百科全书能够收录人类过去积累的所有知识,任何百科全书所收录的内容都只是人类全体知识的真子集,而网络百科全书相对于实物百科全书的最大优点就是它天然具备的即时可拓展性。作为特定网络百科全书的创建者,可以为了实现其即时可拓展性,通过预先设定更新和拓展策略,使网络百科全书记录的内容能够不断增长和保持最新,不断提高其可用性和有效性。
网络百科全书和搜索引擎的相同之处:主流的搜索引擎和网络百科全书在用户检索方式上是相同的,都是用户通过输入关键词或关键词的组合表达检索需求,具体体现在网络百科全书和搜索引擎具有类似的用户界面和输入内容形态。
网络百科全书和搜索引擎的不同之处如下。
(1)二者对自身存储内容的管理方式不同。网络百科全书对于知识信息的生成方式是直接编辑式的,所有的知识信息存储在网络百科全书中时,都要适应其统一的格式,这意味着遇见源内容与网络百科全书的词条内容格式不匹配时,需要先对源内容进行转换,然后才能生成对应词条异进入网络百科全书的存储系统,大部分网络百科全书的词条内容甚至是直接基于其内容框架进行创建的;虽然搜索引擎在爬取互联网内容时,搜索器也会进行格式的转换,但这种转换的目的不是为了统一内容格式,而是为了对索引器进行更好的内容分析。
(2)由于对内容的管理方式不同,二者的用户界面对用户提供知识服务的方式也不同。网络百科全书将检索词条的具体相关内容直接提供给用户,而搜索引擎则将与检索内容相关的互联网连接列表提供给用户,并进行相关性排序。简单地说,网络百科全书为用户提供编辑后的检索内容本身,而搜索引擎为用户提供未编辑的内容列表。
(3)二者服务的领域和置信度不同。根据知识的定义,网络百科全书所提供的检索内容的真实可靠性、正确性是有保障的,网络百科全书的管理者会通过一些机制和规则来确保所有在网络百科全书中存在的内容有相对较高的置信度,从这个角度来看,相比于搜索引擎,网络百科全书更加配得上称为真正的知识系统。而搜索引擎由于只是单纯地为用户提供互联网内容,并未进行进一步编辑,对于互联网内容本身也没有相应的机制和规则去确保其真实性和可靠性,因此无法确保其所提供的内容的置信度。
但由于二者的这种不同,导致了网络百科全书的管理者必须对其所提供的所有内容进行正确性验证,对于非开放的网络百科全书来说,这种人工验证是非常消耗人力资源的,因此网络百科全书的涵盖内容远远不及搜索引擎的涵盖内容广泛,这导致二者的服务领域有很大差距。网络百科全书能够提供的知识服务仅限于词条解释,而无法提供与检索内容相关的其他内容的服务,其内容本身的涵盖范围也远不及搜索引擎的涵盖范围广泛(虽然存在大量的相关性非常差的内容和重复内容,但搜索引擎对单个检索需求所提供的检索内容往往多达几十上百个列表项,内容浩如烟海,而网络百科全书对一个特定词条的解释通常只有一个页面,有时甚至只有寥寥几句话)。所以网络百科全书通常提供的知识服务是偏专业领域的。
网络百科全书的发展历程可以概括为以下几个阶段。
(1)第一阶段:基于定点联机模式软硬件基础上的百科全书,即百科全书的电子化阶段。1966年,美国洛克希德飞机公司建立了第一个联机情报服务系统Dialog,并建立了世界上第一个以数据库为主体进行联机服务的信息检索系统。1973年,总部设在纽约州的美国书目检索服务社(Bibliographic Retrieval Services,BRS)成立,专门开展书目文献数据库的联机检索服务。1980年4月,BRS推出了由1000篇文献组成的全文数据库,这个数据库不仅提供标题、文摘,而且可以进行全文检索。同年,《美国学术百科全书》出版,它是第一部以数据库为介质,通过网络向读者提供声像资料的百科全书,也是世界上第一部网络百科全书。不久,该百科全书的出版商Grolier又推出了CD-ROM版学术百科,它也是世界上第一张百科全书只读光盘。继学术百科的创举之后,专业百科《基尔克—奥斯默化学技术百科全书》也纳入了BRS的检索体系。1981年,不列颠百科全书公司建立《不列颠百科全书》(Encyclopedia Britannica)全文数据库,不久又与著名的法律咨询公司Mead Data Central合作,通过该中心的联机检索系统向用户提供联机检索服务。在成功收购康普顿百科之后,1989年,不列颠百科全书公司出版了《康普顿多媒体百科全书》(Compton's Multimedia Encyclopedia),即光盘版康普顿百科。不列颠百科光盘版则出版于1994年 [12] 。
第一阶段的网络百科全书形态表现为“百科全书的电子化”,并依托当时可用的数据库技术,将当时可用的百科全书内容存储在电子媒介的数据库中,并以定点联机模式来访问和编辑。在这个阶段,网络百科全书并未以互联网访问的形式呈现出来。
(2)第二阶段:基于互联网的网络百科全书。互联网的开放性、交互式、超文本、超媒体的特性更适合于以服务为宗旨的文献信息检索服务。而且,网络数据库的更新和管理也使得信息管理者们拥有了更多的主动性。因此,百科全书正式“上网”,开启了基于互联网访问模式的网络百科全书时代。1994年,不列颠百科全书公司推出了面向互联网的第一部百科全书,即不列颠百科在线。1999年10月,不列颠百科在线首个版本的网站Britannica.com在互联网上发布,这开辟了网络百科全书的新时代。在它之后,世界图书百科全书、康普顿百科全书等相继在互联网上筑巢。Grolier更是不甘人后,将美国百科全书、美国学术百科全书、知识新书等六部百科捆绑在一起,在互联网上推出集成式的Grolier在线,以单卷本知识浓缩著称的哥伦比亚百科全书在线则成为综合性参考工具检索引擎Bartleby.com的一员(该检索引擎也称工具书在线Great Books Online,是互联网上屈指可数的几家参考工具书专业检索站点之一) [12] 。
这个阶段的网络百科全书,是在前一阶段电子百科全书的基础上,集成互联网技术,遵循一系列的互联网访问协议,将电子化的内容搬上互联网,以使其能够通过互联网被全球的互联网用户访问,在数据规模和访问规模上都有了大幅增加。
(3)第三阶段:自由内容、自由编纂、动态更新及多语版本的网络百科全书。传统的网络百科全书,其内容由网络百科全书的发布者进行定期更新和维护,而随着网络百科全书的内容规模不断扩大,边界不断拓展,对网络百科全书内容的维护所需要的人力资源也不断提高;同时,各种分门别类的网络百科全书也存在着语言的局限性,导致非母语的用户在使用网络百科全书时存在一定困难,整个项目无法达到创建者的初衷。
基于解决上述问题的思路,自由内容、自由编纂、动态更新及多语言版本的网络百科全书系统诞生了,其典型代表为维基百科(Wikipedia)。
由美国人Wales J和Sanger L创建的维基百科 [13] 于2001年1月15日正式上线,截至2016年12月底,维基百科拥有295种语言(及方言)版本,总条目数超过4312万。其中英语板块是最丰富的语言板块,现有逾532万条条目,拥有1276名管理员,全球注册用户兼内容编辑达到2986万,其中逾12万人是活跃的内容编辑。维基百科是全球访问量最高的十大网站之一,已经成为当前世界最大、发展最快的网络百科全书。
从简单的百科全书内容电子化,到将其搬上互联网,再到公共版权、开放编纂、动态更新和多语言,网络百科全书及相关的技术不断发展,在实现和优化这种知识系统过程中涉及的相关技术在其他领域也必将得到很好的应用。
维基百科的技术基础是一款叫作维基(Wiki)的应用软件。其概念源于1995年在美国普渡大学计算机中心(Purdue University Computing Center)工作的Ward Cunningham开发的波兰特模式知识库(Portland Pattern Repository),并在建立这一工具库的过程中提出了维基的概念和名称。维基是一种基于Web 2.0模式的超文本协作式写作工具,为社群提供“协同创作”的环境 [14] ,也就是说它容许和接纳任何人自由地共同参与对同一个文本内容的编辑和书写。这种操作的代价远比具备同样功能的HTML文本要小 [13] 。
这种技术使得维基百科突破了传统的百科全书的集中式组织编纂模式,解构了百科全书的编者和读者的二元对立关系 [15] ,其内容的编纂模式对传统百科全书的编纂理念也具有颠覆性的影响:彻底改变了过去专家和权威为百科全书编纂主题的金字塔式,通过自由编纂将话语权由“精英阶层”完全下放到“平民阶层”,形成了去权威性的、扁平式的维基模式 [16] 。
正是其自由内容、自由编纂的特点,使得维基百科不同于之前版本的网络百科全书,其最重要的区别在于,传统的网络百科全书的内容维护以整个百科全书的权威发布者为主,因此权威发布者需要对百科全书的内容真实性和准确性负责,这种负责通过商业信誉的形式保证。而对于维基百科来说,由于对百科全书内容的编辑权利分发给了绝大部分普通网民,因此很难保证所有人对所有条目编辑内容的真实性和准确性,这使得维基百科在内容置信度上饱受诟病。好在其在创立之初就考虑到了这个问题,从这个网络百科全书项目发布之初到现在,维基百科通过设计各种规则、引用各种内容/用户识别方法对用户编辑内容的真实性和准确性进行保证,不断完善其内容质量。在这个过程中,维基百科逐渐形成了一套纷繁复杂的内容审核、用户识别规则和发布体系。
维基百科的软硬件体系架构如图1.4所示。
维基百科的软硬件体系架构的功能如下。
GeoDNS模块:原理很简单,GeoDNS模块是一个为BIND写的40行的小程序,可以让DNS解析的时候考虑地域因素——让用户能够访问离他所在地域最近的Web服务器。
LVS模块:一个开源的软件,可以实现Linux平台下的简单负载均衡。LVS模块主要由负载调度器、服务器池和共享存储构成。可喜的是,这是一款为数不多的中国人自己编写的开源软件(由章文嵩发起);可惜的是,LVS模块目前仅支持Linux。
Squid缓存层:一种用来缓冲Internet数据的软件。尤其适合像维基百科这样的遍布全球、数据中心却很集中的站点使用。在维基百科中,Squid缓存层分为两组,一组是文档内容(多为压缩的HTML页面),另一组为媒体内容,主要包括图片等大一点的静态文件。目前总计有55台Squid服务器在维基百科运行,维基百科正在准备添加另外的20台。根据维基百科披露的资料,其中每台Squid服务器每秒要处理1000~2500个http请求,每台Squid服务器承受100~250Mbit/s的流量,每台Squid服务器负责1.4万~3.2万个连接,每台Squid服务器分配出40GB作为缓存空间。硬件方面,这些Squid服务器每台都有4块硬盘,8GB的内存。
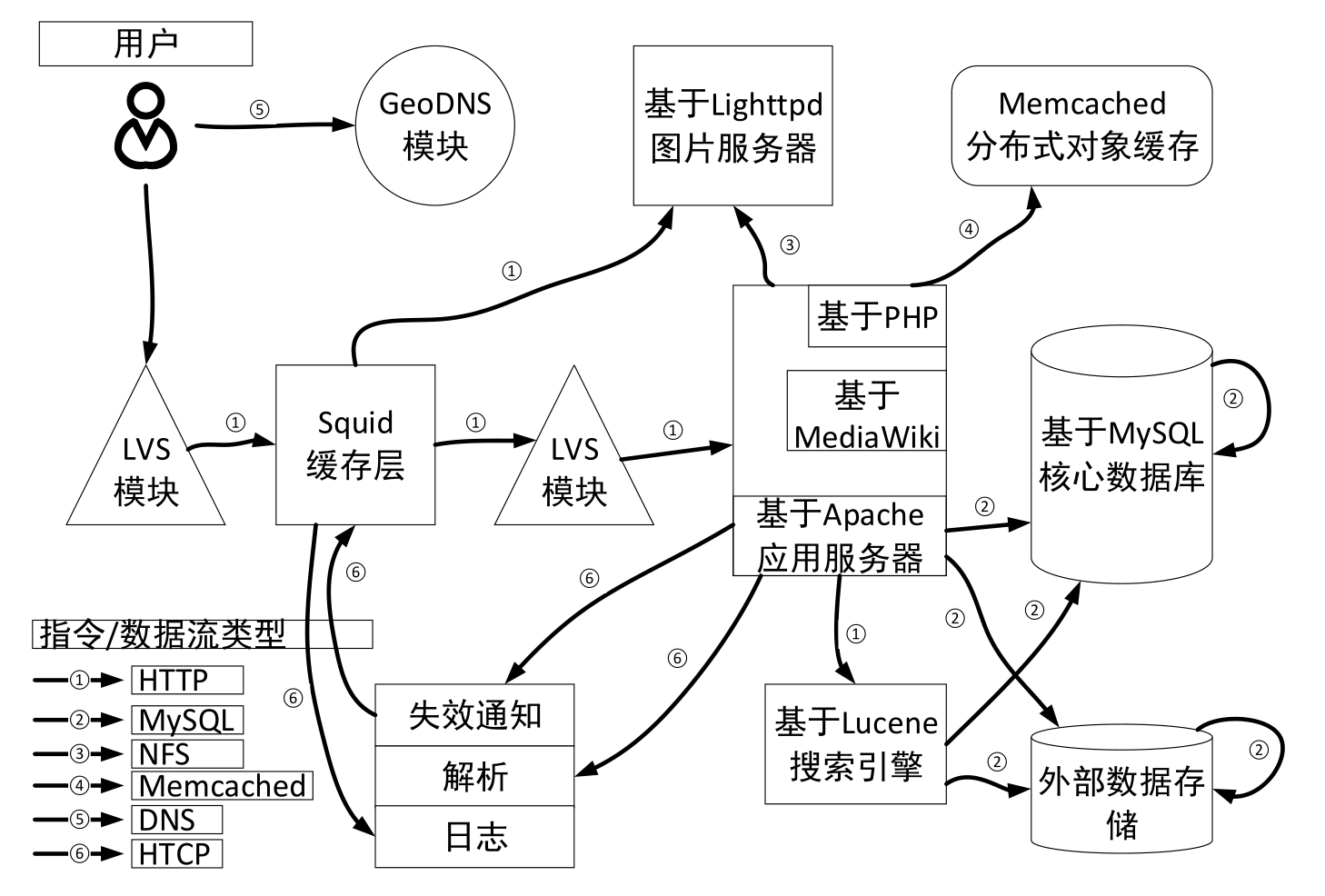
图1.4 维基百科的软硬件体系架构
数据存储(基于MySQL核心数据库、外部数据存储、基于Lighttpd图片存储):元数据,如文章修改历史、文章的链接和用户资料等内容被存放于基于MySQL核心数据库;正文存于外部数据存储;用户上传的图片等信息则单独存放于基于Lighttpd图片存储(图片服务器)。
维基媒体平台(基于Apache应用服务器、Memcached分布式对象缓存):维基百科所有的项目都运行在维基媒体平台上,这是一个遵守通用公共许可证(General Public License,GPL)的开源软件,以PHP语言写成。维基百科本身在使用,但很多别的机构也使用了该软件平台。在所有125台应用服务器上都安装了维基媒体平台,还有40台应用服务器马上就要上线,这些应用服务器都采用了两颗四核的CPU。这些媒体平台都由一个中心控制台控制,维基百科可以通过该平台部署某个应用到数百台机器上,非常方便。维基媒体平台非常注重缓存,多数缓存都放在Memcached分布式对象缓存中 [17] 。
相对于搜索引擎高度复杂的运行流程,网络百科全书的架构和流程则简单得多,在大多数情况下我们可以将其看作一种扁平化的架构:由用户根据书写规则和代码范例进行内容编辑,添加必要的多媒体(图片、音像等)上传并由Squid服务器进行保管,维基媒体平台根据事先设计好的内容审核和分类规则将上传内容审核、分类并存储到不同的数据存储单元中去,针对内容更新的情况,同时将历史数据转存。其他用户在访问维基百科的时候,GeoDNS模块和LVS模块负责协调访问负载和目标服务器,将用户访问请求疏导到不同地区的不同目标服务器。
维基百科是任何人都可以编辑的网页。在每个正常显示的页面下面都有一个编辑按钮,单击这个按钮就可以对页面的词条内容进行编辑,这体现了其内容的开放性。与此同时,为了维持网站的正确性,维基百科在技术上和运行规则上做了一些规范,做到既保持面向大众公开参与的原则又尽量降低众多参与者带来的风险。这些技术和规范包括 [17] :
(1)保留网页每一次更动的版本:即使参与者将整个页面删掉,管理者也会很方便地从记录中恢复最正确的页面版本。
(2)页面锁定:一些主要页面可以用锁定技术将内容锁定,其他人就不可再编辑了。
(3)版本对比:维基百科站点的每个页面都有更新记录,任意两个版本之间都可以进行对比,维基百科会自动找出它们的差别。
(4)更新描述:参与者在更新一个页面的时候可以在描述栏中写上几句话,如参与者更新内容的依据或是跟管理员的对话等。这样,管理员就知道参与者更新页面的情况。
(5)IP禁止:尽管维基百科倡导“人之初,性本善”,人人都可参与,但破坏者、恶作剧者总是存在的,维基百科有记录和封存IP的功能,将破坏者的IP记录下来他就不能再胡作非为了。
(6)沙箱测试:一般的维基百科词条都建有一个沙箱的页面,这个页面就是让初次参与的人先到沙箱页面做测试,沙箱页面与普通页面是一样的,这里参考者可以任意涂鸦、随意测试。
(7)编辑规则:任何一个开放的维基百科页面都有一个编辑规则,上面写明了大家建设维护维基百科站点的规则。没有规矩不成方圆的道理在任何地方都是适用的。
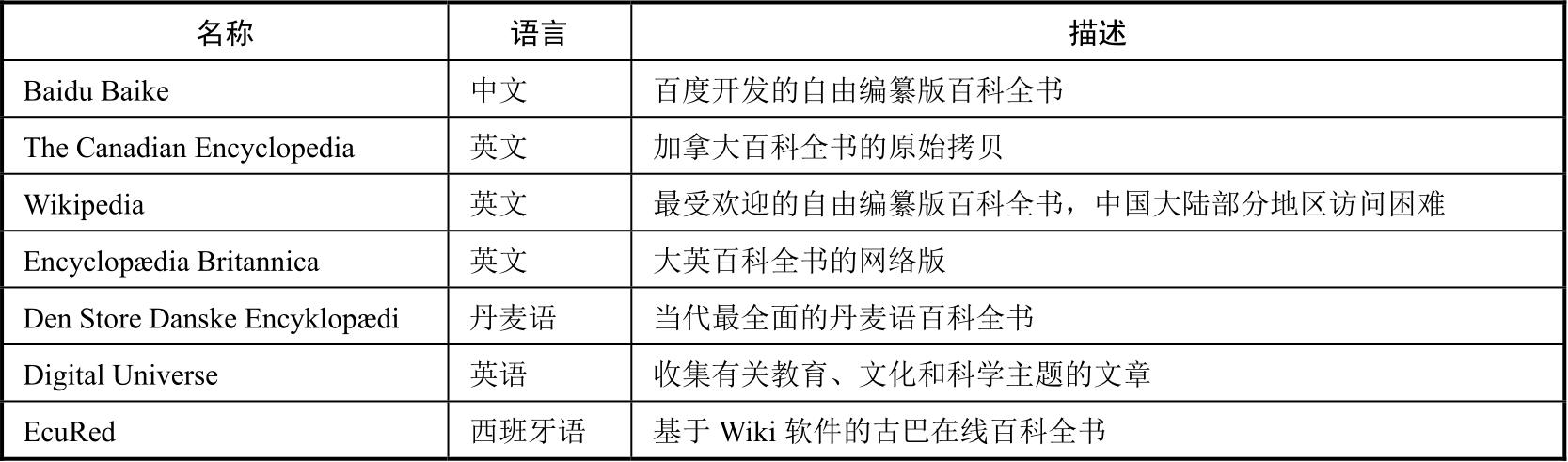
几种有代表性的网络百科全书如表1.3所示。
表1.3 几种有代表性的网络百科全书 [18]