
下载掌阅APP,畅读海量书库
立即打开



对于知识系统的广义定义:广义的知识系统,即对知识进行生成、管理、存储、转换、扩充及删减、表达、传递等操作的系统,具有确定的实体和可以提供的知识服务。
宏观上,知识系统可以是任何具有物质属性的客观实体。最广泛的,我们所属的宇宙就是一个宏大的知识系统,它向我们提供广袤的知识,以信息的形式表达出来。而作为用户的我们——人类,具备得到它提供的知识服务的能力,这种能力的大小取决于我们人类能够感知信息能力的大小。这种知识系统所能提供的最基本的几项信息和服务方式,包括光线所代表的光波的频率振幅,对应视觉服务;声音所代表的声波的频率振幅,对应听觉服务;周边客观存在的物质与身体皮肤细胞的生化反应,代表触觉;气体分子与鼻腔感觉细胞的生化反应,代表嗅觉等。在此基础之上,人类还可以通过各种工具,向宇宙这个知识系统获取更高级的知识服务。比如,汽车的移动速度可通过观察速度仪表盘得来,周边温度可通过观察温度计得来等。
微观上,即使简单到一张纸,也可以自成一个知识系统,具体表现在有关其颜色和尺寸的简单知识,韧性和可书写性等复杂知识,这些都是这个知识系统能够提供给用户的知识服务。所谓“一粒沙中见世界”,这种浪漫的表述方式,某种程度上与知识系统的属性有着相通之处。这种对于知识系统的广义定义的介绍,目的是使读者对于知识系统有一个相对准确和客观的认知。
狭义的知识系统,即本书接下来的全部内容涉及的知识系统,又称知识管理系统,指以计算机硬件、软件和算法为基础,面向计算机用户、为计算机用户提供知识服务的信息管理系统,对其的研究是计算机科学领域的一项重要分支。知识数据、知识系统和用户的大致关系如图1.2所示。
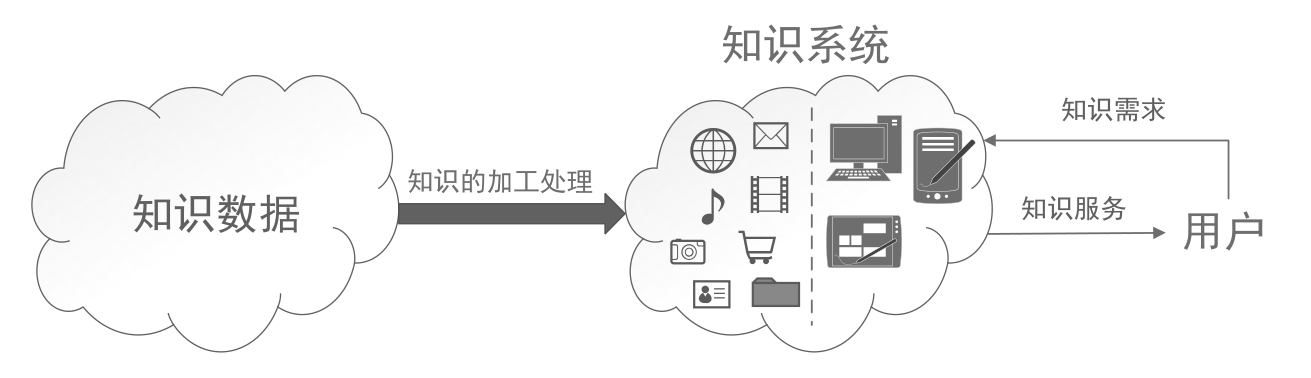
图1.2 知识数据、知识系统和用户的大致关系
知识系统所管理的最基本的知识数据,是存储在计算机存储设备当中的,以物理上所描述的电压高低为区分特征的高低电平,经过初步的转换,变成机器所能够理解处理的数字信号“0”和数字信号“1”,进一步将各种“0”和“1”及其组合根据一定的规则转换成我们人类所能够理解的数字,包括整数、浮点数、复数等,再进一步转换成文字、图片、音频和视频以至于更高级的知识数据,并通过显示器、音箱等硬件媒体传递给用户。
目前,最贴近我们日常生活的知识系统,就是以搜索引擎为代表的互联网信息检索系统。我们几乎每天都要跟这些知识系统打交道,享受这些知识系统为我们提供的知识服务。比如,在浏览某个网站的时候,我们需要通过搜索引擎输入网站名称得到这个网站的链接(或者对于常用的网站直接在浏览器中输入其地址);进行网上购物的时候,我们需要查询某样商品的外观、价格、送货周期;在户外的时候,我们需要查询自己的当前位置和到要去的地方的路线等,这些都是我们的知识需求。同样,对于前述的各种知识系统来讲,针对用户的这些知识需求,它们能够以什么样的方式、提供什么样的知识服务,这是这些知识系统的重要特征,某种程度上也可以被看作知识系统提供知识服务的能力。
知识需求,具体来说是指知识系统的用户的知识需求,是相对于知识系统和其所能提供的知识服务来说的,指用户从知识系统获得知识的需要。知识系统对于知识需求的分析和理解,是其面向用户的最重要特征。
人类的知识需求的表达形式可以很简单,也可以很复杂。针对同一个知识需求,知识系统可以不断完善其知识服务,不断提高其知识服务的质量,因而满足人类知识需求的行为永远有进一步的优化空间。比如,针对一项很简单的检索需求——“明天某地是否下雨”。我们将这个问题分解,就会发现这个简单的检索需求实际上并不简单,更加准确的表述是“以某个名字命名的行政地区全境在明天的24小时之内是否会有降雨现象”。对于一个简单知识系统来说,这个问题就是一个“会”与“不会”的二元判定问题,相对来说简单一些,只需要搜索到“这个地区在明天24小时之内的天气预报信息”这个信息并经过分析后,将“会”或“不会”的判断反馈给用户,就算满足这次检索需求了。但对于用户来说,在输入“明天某地是否下雨”的检索需求之后,用户真的是需要知道“这个地区全境在明天24小时之内的天气预报信息”及“会”或“不会”的判定信息吗?可能他只是在其中的某一个特定时间要从某个地点前往另外一个地点,而“这个地区在明天24小时之内的天气预报信息”对他来说就具有很高的冗余度,有相当大的概率使得“这个地区在明天24小时之内的天气预报信息”不能满足其需求,也许反而会误事,使原本不需要带伞的情况变得需要带伞。在这种情况下,用户的知识需求就需要被进一步满足。而假设知识系统已经提供了能够满足用户“未来的某一特定时间从某个地点前往另外一个地点,这个过程中是否需要携带雨伞以避免被雨淋湿”的知识需求的服务,有没有进一步提供知识服务满足这个需求的可能呢?有!如果知识系统具备对用户检索需求上下文进行分析的能力,那么就有可能判断出用户对于“携带雨伞与否”的需求实际上是“某时前往某地需要做什么样的准备(其中包括是否带伞)”的需求;进一步地讲,防雨计划、交通计划、目的地人流量状况等信息都可以被当作知识服务提供给用户而满足这个需求,而这些服务很明显都会被用户接受和欢迎。
更加宏观地来讲,“希望能够享受更加美好的生活”是我们每个人的终极目标,是人类的终极需求,人们其他所有的需求都是这个需求的外在表现,对知识系统所提出的知识需求也是这个需求的表现之一。由“明天会不会下雨”细化到“明天14:00—14:30及16:00—16:30这两个时间段一个半径为五米的圆从地图坐标 X 移动到地图坐标 Y 这一段,其间这个圆内会不会发生降雨行为”,或者宽泛到“明天某地是否开放,是否值得前往”,或者联系上下文推断“某地好不好玩”,或者进一步推导出“明天想去某地玩,有没有更好的推荐”,知识系统分析用户知识需求的道路是没有终点的。
因此,如何对用户的知识需求进行分析和理解,以期从外至内、由浅入深地满足用户的知识需求,是任何知识系统所应具有的最重要的特征之一,也是其不断优化、不断提高服务能力的前进方向之一。
知识服务的定义:针对用户的知识需求,知识系统提供相应的知识服务。与用户的知识需求的简单抽象程度相对应,知识服务也可以是简单的或者抽象的。进而,不同的知识系统对同样的知识需求,可以提供不同种类、不同形式、不同内容的知识服务,而这些不同的知识服务的质量,就可以用来衡量对应知识系统的能力。
举一个简单的例子,用户的知识需求为“天安门的地址”,对于这个知识需求,很明显我们知道天安门不是一个准确的位置,而是一个具有多个具体地点的地区。知识系统A所提供的知识服务为“天安门位于中国北京市长安街,故宫南门南侧”,这个系统并不知道天安门具体指的是哪个位置,所以给出了其所在的大致位置,这种知识服务能够满足用户的需求吗?也许能,有些用户提出这个知识需求可能真的只是想知道天安门的大致位置在哪儿,而这个知识服务就能满足他们的需求。知识系统B所提供的知识服务为“搜索到的与天安门有关的前10个相关地点的地址分别为1……2……3……”,同系统A一样,系统B不知道用户的具体知识需求,因此它进行了遍历,将所有用户可能需要的有关知识罗列给用户以便其进行进一步选择,相比于系统A,系统B就在知识服务的质量上更进了一步,可以说单单这一个服务就能够说明系统B的知识服务质量比系统A的要更好。知识系统C所提供的知识服务为“天安门广场的具体地址为……,从当前位置前往这里需要……”,并把行程列表列出来,系统C与系统A、系统B最大的不同在于它具备了结合用户的知识需求上下文来细化当前知识需求领域的能力。比如,在此之前用户可能在同一个知识系统上搜索过“升国旗仪式”或者“瞻仰毛主席遗像”等相关的内容,系统C会根据此前的内容判定用户当前的知识需求的真实值为“如何去天安门广场”,相对应地就向用户提供了从用户目前位置到达天安门广场的具体路线行程推荐。显而易见,知识系统C比系统A和系统B都更加能够为用户提供高水平的知识服务。
准确地来说,衡量一个知识系统为用户提供知识服务能力高低的标准有三个。
(1)对用户的知识需求的理解水平。用户的知识需求往往是多元化、多层次、多个方面的,如何从一个简短抽象的知识需求入手,通过对问题的分析和对上下文的引入,能够得到最准确的知识需求,是衡量一个知识系统提供知识服务能力高低的重要标准。能够从“天安门的地址”这个知识需求,理解到“如何去天安门广场”这个层面,可以说是比较深刻和准确地理解了用户的知识需求,而理解到“天安门大致在什么位置”这种层面显然是不够的。
(2)对知识的管理能力。对知识的管理能力,具体就是知识系统对知识的存储、表达、再加工能力。通俗地来讲,就是能否使用尽量小的存储空间存储尽量多的数据,能否使用尽量少的时间按要求处理尽量多的数据,能否在尽量短的时间内对用户的知识需求进行响应,并提供相应的知识服务。以上三个部分的表现,决定着知识系统对知识的管理能力的高低。
(3)对知识的后续处理能力。对知识的后续处理能力不同于第二条中对知识的管理能力,对知识的管理能力主要从时间开销和空间开销上来衡量,而对知识的后续处理能力主要从后续处理的知识的效果上来衡量,比如对知识的归纳和演绎,从“1个苹果加1个苹果就是2个苹果”到“1+1=2”,再根据“苹果和橘子是不同的东西”和“1+1=2”演绎到“1个橘子加1个橘子就是2个橘子”。
知识系统服务的对象,可以是普通用户,也可以是另外一个知识系统,甚至可以是自身。比如,作为搜索引擎的知识系统,其知识服务的对象就是普通的互联网用户,而作为对图书馆的图书资源进行管理的图书管理系统,其知识服务的对象就可能是图书馆的另外若干系统:图书订阅系统、图书租赁系统、图书采购销毁系统和图书交换系统等,而当这些系统作为不同功能的子模块被整合到同一个图书管理系统中时,就相当于图书管理系统既作为知识系统,又作为用户,在执行某些功能时,它为自己服务。
对于狭义的知识系统来说,用户的知识需求多种多样,有文字图像等表达形式之分,也有视觉、听觉等接受形式之分,因此不同的知识系统提供不同的知识服务,满足用户不同的知识需求,就是知识系统的运行生态。
本章接下来将会针对知识系统运行生态现状,介绍几种比较流行也比较常见的知识系统应用案例。
作为普通用户来说,当我们打开计算机想要在互联网上浏览内容,或者目的明确地想要在互联网上查找某项信息时,多半需要搜索引擎的帮助,小到某个汉字该怎读,中到怎样做一盘西红柿炒蛋,大到查找去年某个月的国内生产总值,不管什么样的信息,搜索引擎都能够帮助我们找到非常接近我们需求的内容。如前文所说,搜索引擎作为一种典型的知识系统,其功能非常强大,我们生活在这个世界上所需要的几乎所有知识都能够在浩如烟海的互联网内容中找到。但如果没有搜索引擎所提供的知识服务,那么作为普通用户的我们,想要寻找到这些特定的知识就会变得非常困难,搜索引擎使我们与互联网世界的距离前所未有地接近。因此在1.3节,我们将介绍狭义的知识系统与互联网结合的最优秀成果:搜索引擎的定义、历史与发展历程、种类划分、关键技术、体系结构和工作流程、代表性的搜索引擎等内容。
搜索引擎的功能固然强大,但其提供的内容有一个很大的局限性,就是搜索引擎只提供与检索信息相似度最高的内容,搜索引擎本身并不能从语义上确保其所提供内容的准确性与真实性,所以从这个角度来说,其并不能严格被称为真正的知识系统,其知识系统的特征,更多体现在其功能的强大程度、所提供内容的全面性、使用的方便程度和应用范围上。相比之下,另外一种知识系统:网络百科全书,就既能够提供相对于搜索引擎更加准确和真实的信息,也能够提供相对于搜索引擎更加规范化、标准化的信息。从获取知识的方式上来说,网络百科全书是一种限定搜索方式和搜索内容的搜索引擎,其所提供的知识服务相对于搜索引擎来说涵盖领域更加狭窄、专业性更强。如果要搜索类似“某个名人”“某个数学概念”等这种指向性明确、语义准确的内容,那么网络百科全书能够提供给我们更好的知识服务。在1.4节,我们将介绍网络百科全书的定义和主要特征、历史与发展历程,以及其中最出色的产品——维基百科的相关内容。
作为应用范围更加专业、提供的知识服务更加深刻、服务质量更好的重要应用之一——网络文献共享平台,其在科研和专业性强的工作领域也有着非常重要的地位,目前的科研工作和专业性生产活动都离不开网络文献共享平台所提供的知识服务。科研人员撰写论文,前期需要对相关研究领域的文献进行论文梳理,中期需要对相关文章中的理论和实践细节进行分析和复现,后期需要引用相关文献中的研究,甚至生成参考文献的格式,这些工作都需要通过网络文献共享平台所提供的知识服务才能进行。随着我国相关产业在国际产业链体系中的地位不断升高,对于科研工作及对应生产工作的需求将会越来越大,可以预见的是,网络文献共享平台一定会在国家、社会,乃至个人的日常生产生活中扮演越来越重要的角色。因此在1.5节,我们将对有关网络文献共享平台的定义、主要特征、历史与发展历程、典型功能等内容进行介绍。
无论搜索引擎、网络百科全书还是网络文献共享平台,它们的主要共同点就是它们所处理的最主要知识数据是文字,无论搜索引擎所处理的网页所包含的内容,还是网络百科全书中的内容,乃至网络文献共享平台中所提供的网络文献知识,都以文字为主要载体,因此它们所使用的相关技术,包括存储、管理、传输等操作涉及的相关算法和理念都是面向文字数据的。与之不同的是,有一种知识系统所面对的知识数据并不是以文字为主的,而是以空间坐标、环境参数(温度、湿度、压力等)、资源信息等内容为主的,这些数据与文字没有太大关系,因此这种知识系统涉及的相关技术与之前的几种知识系统有很大不同。这种知识系统就是我们将要在1.6节中介绍的地理信息系统,我们会介绍其定义、所处理数据的特征、历史与发展现状,以及目前的最重要的应用之一——全球卫星导航系统的结构和功能等相关内容。