
下载掌阅APP,畅读海量书库
立即打开



原子操作是指利用硬件提供的锁内存总线的能力,使得一条指令可以无竞态地访问一个内存位置。在Intel的架构下,有两种锁总线指令:一种是lock前缀的指令,另一种是指令自带的锁总线的语义。无论是哪一种锁总线指令,在本质上都是硬件锁总线指令。lock前缀能修饰的指令数量有限,包含:ADD、ADC、AND、BTC、BTR、BTS、CMPXCHG、CMPXCH8B、CMPXCHG16B、DEC、INC、NEG、NOT、OR、SBB、SUB、XOR、XADD和XCHG。其中XCHG指令自带锁总线语义,无论是否有lock前缀修饰,XCHG都会锁总线。
原子操作可以使用上述任何满足语义的指令进行实现。以下是x86下的原子递增操作。

在以上代码中,asm是GCC的C代码内嵌汇编的关键字,volatile代表内嵌的汇编代码不需要GCC来进行优化,而是按原样生成。上述汇编包括四部分,内嵌汇编语法是:汇编语句模板、输出部分、输入部分、破坏描述部分(clobber list),后面的三部分是可选的。
x86下原子操作的支持位于arch/x86/include/asm/atomic.h中,原子加法指令使用add锁总线指令,原子递增、原子递减、原子减法等也使用类似的实现方式。x86下的原子加法示例如下。


为了进一步表达该汇编写法的意义,上述示例程序使用64位进行编译,编译结果如图3-1所示。
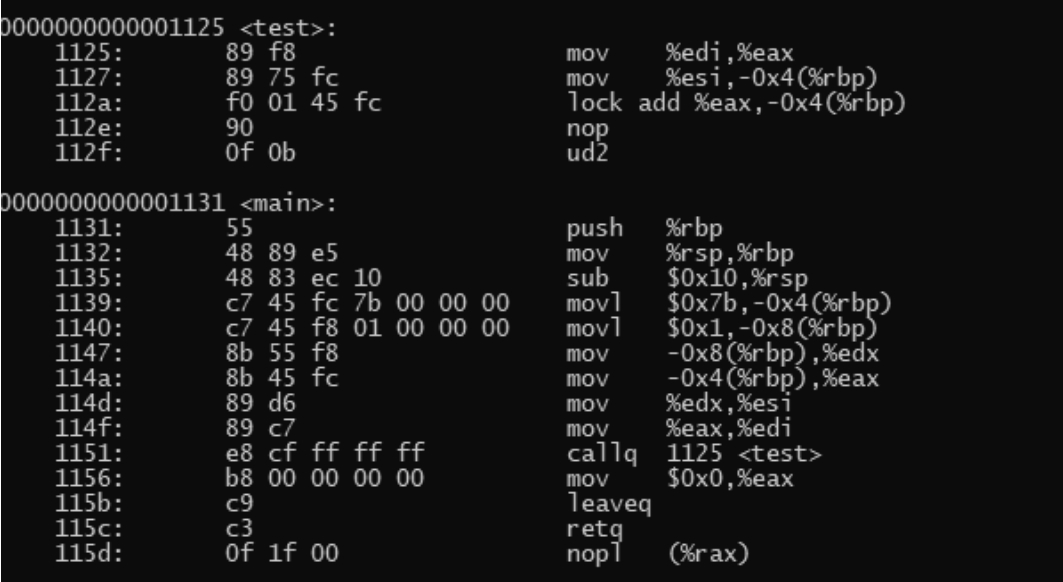
图3-1 编译结果
为了演示特定的编译结果,这里使用GCC的naked语法让test不产生函数的入口和出口。test函数的两个64位的参数分别通过edi和esi寄存器传入,按照内联汇编中所描述的,第一个参数i(也就是edi中的值)是放在寄存器中的立即数,因此GCC产生了“mov %edi,%eax”这个汇编,将%edi中的值放入%eax中;第二个参数counter(也就是esi中的值)一定要在内存中,于是GCC生成了“mov %esi,-0x4(%rbp)”这条指令。将esi寄存器中的值入栈,放入内存,而锁总线的操作生成了“lock add %eax,-0x4(%rbp)”,即完成了原子将i累加到counter内存中的操作。
在main函数中,i和counter变量被放入栈上,counter变量在栈上位于-0x8(%rbp),i变量在栈上位于-0x4(%rbp),为了进行函数调用,需要准备调用约定的上下文,将前两个参数分别放入edi和esi寄存器。因此32位宽度的i变量会进入edi,32位宽度的counter变量会进入esi,只是上面代码的进入顺序是从右往左进行设置的。
在64位下,add指令操作的仍然是32位的eax寄存器,而不是64位的rax寄存器。
在Linux内核中对原子操作定义了一个专门的类型,如下所示。

在原子操作中,分为Non-RMW操作和RMW(Read-Modify-Write)操作。Non-RMW操作包括读和写,主要是atomic_read()和 atomic_set()两个函数。这两个函数的特点是对内存的访问只是简单的读/写。加、减、自增、自减等都需要先将值从内存中读取到寄存器,再修改寄存器的内容,然后将寄存器中的值写回到内存,其中包含读、修改和写三个操作。对于Non-RMW操作,不需要进行锁总线。原子读/写操作的定义就是一个volatile类型的读/写操作,定义如下。

volatile的行为就是GCC的控制范畴了,在GCC中,volatile关键字保证对变量的访问不会被编译器进行顺序优化。编译器会利用现代CPU流水线的指令重排的技术,重新安排指令的执行顺序,以充分利用流水线将多条指令并行执行。volatile并不是内存栅,也不会起到内存栅的作用,volatile是写给GCC看的,而不是写给CPU看的,其作用仅限于限制GCC的指令重排优化,而不限制CPU流水线的预读,即使限制GCC不进行重排,CPU流水线也仍然会进行重排。内存栅引起的问题主要出现在并发线程访问的时候,而GCC的指令重排会引起逻辑上的问题,在单线程条件下也可能会出现问题。
RMW类型的操作比较多,分为数学运算、位运算、交换运算、引用计数、带内存栅的原子操作等,分别对应x86下的可以加lock前缀的指令,具体如下。

其中,带内存栅的原子操作在x86下就是简单的标准内存栅。

在x86下,lock前缀的指令自带内存栅语义,所以简单地使用原子操作即可。barrier()函数的语义是在通知GCC前后内存已经发生变化,使得GCC不进行激进的内存缓存优化。这个函数在x86下只有控制GCC优化的能力,而没有控制CPU指令乱序预读的能力。
在Linux内核中区分acquire、release、relaxed三种原子操作的内存一致性语义,除非特殊实现,否则都会使用通用的/include/linux/atomic-fallback.h定义的回退实现,最典型的三个API是:
#define atomic_cmpxchg_acquire atomic_cmpxchg
#define atomic_cmpxchg_release atomic_cmpxchg
#define atomic_cmpxchg_relaxed atomic_cmpxchg
x86的内存一致性模型是强一致的,在一般情况下,并发编程只需要关注GCC层面的指令重排即可,而不用像弱一致的ARM那样需要关心很多内存顺序的问题。
比较新的CPU已经支持锁总线的性能优化机制,即当访问的内存位于cache中时,即使使用了lock前缀,在硬件上也不会真实地锁总线,而只是锁cache。这样相当于通过利用CPU的cache一致性协议提供的保证来替代对内存总线的锁操作。锁总线的实际效果是对所有内存访问都上锁(虽然语义上lock前缀只保证对操作内存位置上锁),而锁cache的效果是只对操作的cache行进行上锁。两者性能差别巨大,所以在原子操作之前保证其位于cache中是比较恰当的。使用lock前缀对性能的影响是CPU顺序错乱引起强同步,使用了lock前缀相当于在该指令的前后完全关闭了内存I/O乱序执行的能力,使得前后的读/写都完全串行。在更新页表的时候也会自动触发lock前缀,内存在频繁发生page fault时也会产生一定的性能影响。
在内存一致性模型上,理论上单个CPU应该按顺序执行所有指令,但是现代CPU的每条指令执行都有很多步骤,这些步骤会串起来组成流水线,CPU为了充分利用流水线,允许在不同的步骤并发执行不同的指令,但是保证最后的执行是按照编码的顺序完成的,这叫作乱序执行,也就是说,CPU并不保证指令执行的顺序,但是对于内存读/写的指令顺序,CPU单核会给出一定的保证。假设没有任何内存I/O乱序,且x86在不保证顺序乱序的情况下,仍然会给出内存I/O一定程度的保证,如下所示。
(1)读与读之间是顺序的。
(2)读与之前的相同内存的写是顺序的。
(3)写与之前的读是顺序的。
(4)写与写之间是顺序的。特殊的写指令除外,例如绕过cache的写和字符串指令操作。
(5)特殊的刷缓存指令遵照指令的语义乱序。
当存在多核时,单核的顺序仍然是由单核流水线保证的,但是核心之间的读/写顺序则需要单核流水线之外的保证。x86的保证如下所示。
(1)一个CPU中的多个顺序写操作,在其他的CPU看来顺序是一样的。
(2)多个CPU的多个顺序写操作在内存排序时按照发生的顺序逐个排序,所有CPU看到的排序后的结果是一样的。
(3)lock前缀的指令前后的读/写不会乱序。
(4)因果关系成立。例如一个CPU观察到另外一个CPU的A写生效了,那么另外一个CPU的A写之前的写就一定生效。
上述的保证看起来很容易实现,但是在硬件上为了制造保证,需要付出很大代价。x86的这种保证叫作强顺序模型(又叫作TSO,全称为Total Store Order),CPU需要浪费大量的执行资源来保证这个顺序约定。
ARM则是弱同步的,对乱序的规定非常宽泛,几乎不做特定条件的顺序保证,这样如果要保证顺序的话,就只能依靠程序员自己来保证,所以在ARM下实现高并发编程是非常有挑战性的。
从上述内容可以看出,lock前缀不会乱序,说明x86下RWN类型的原子操作本身就有内存栅的作用。而x86下的Non-RMW操作只是简单的读/写,也只继承了x86的TSO中的诸多一致性保证。其中,最明显的就是写与之后不同内存位置的读操作是不保证的,这在高层语义代表的就是acquire/release操作。
在Linux内核的高层内存一致性模型中,acquire操作代表之后的读/写不能向前乱序,搭配release操作。release操作代表之前的读/写不能向后乱序,搭配acquire操作。Linux内核的acquire和release语义不限定数据依赖,也就是说,无论是不是同一个内存位置的操作,都遵循一样的操作方法。release代表写操作,写操作之前的读/写不能向后乱序,acquire代表读操作,读操作之后的读/写不能向前乱序。
在实现锁时,acquire操作可以被用于lock,release操作可以被用于unlock,它们一起避免了临界区内的共享存储器的读/写被乱序到临界区外,从而避免了多核乱序执行带来的不一致。由于TSO中的load、store分别等效于acquire、release,所以在x86等系统中实现锁是不需要barrier指令的。
CPU内部I/O的结构简图如图3-2所示。
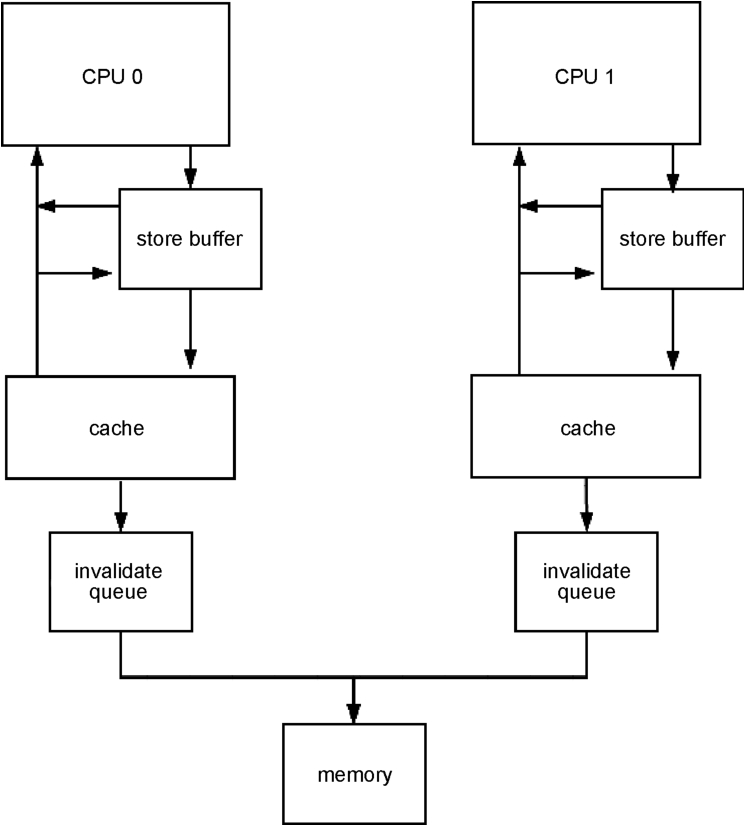
图3-2 CPU内部I/O图
在图3-2中,因为cache要保证不同CPU数据一致,所以CPU 0对一个内存进行写操作,需要让CPU 1的cache中的同样内存位置变为不可用,这包括一个跨核的cache操作,这个操作是需要时间的,如果没有store buffer阻塞的过程,则整个CPU不能往下执行。store buffer的作用就是在写入cache的时候,先将cache写入到store buffer,从而CPU可以立刻返回继续执行,由store buffer继续完成cache一致性。这显然会因为CPU 0立刻返回而执行其他内存读/写的操作,从而导致乱序。
invalidate queue代表的是cache一致性协议保证的、让另外一个CPU中的对应行失效的加速队列。如果没有这个队列,CPU 0要通知CPU 1一个行的失效需要的时间,主要的延时是cache一致性的通信。CPU 1需要回复CPU 0“已经将对应的cache行失效”,才能让CPU 0继续执行。invalidate queue起到的加速效果是:CPU 1一收到cache失效的消息就立刻响应CPU 0,这时CPU 0就可以继续执行。这个加速效果会带来一个副作用,就是CPU 1从回复收到失效特定行到实际发生失效操作中间是有时间差的,在这个时间差中如果读取cache行的内容,就会读取到没有更新的内容,违反了cache的一致性协议。
CPU内部I/O结构整个链条中的任何一个地方卡住都会导致CPU暂停,引入store buffer和invalidate queue就是为了防止CPU暂停带来的性能损耗。上述问题在x86下的解决方法就是使用TCP分段卸载,这很大程度地解决了看起来难解的操作。
内核并不只是支持x86,因此在内核的代码编码中,除了与架构相关的代码,其他地方都不能假设内存一致性,例如顺序锁的读取部分在原子读之后也要添加一个smp_rmb()函数。
atomic_long_try_cmpxchg_acquire和atomic_long_cmpxchg_acquire这种高层的API除具有内存一致性外,还包含对操作数大小的限定,这里使用long数据类型对操作数大小进行限定。long数据类型的特点是可以自动适应不同的平台,所以atomic_long_系列的API在高层代码希望自动适配32位和64位长度的原子类型时采用,对应的原子类型是atomic_long_t。如果是固定的32位长度的原子类型就是atomic_t,如果是固定的64位长度的原子类型就是atomic64_t,这三者的关系如下。

原子数只是简单的32位或者64位的整数。原子操作与硬件平台的相关性比较大,所以比较常见的平台的原子操作定义一般位于arch下,内核整体的头文件是include/linux/atomic.h,在该文件的开头部分就有#include <asm/atomic.h>语句表明直接使用平台相关的定义,在这个文件的结尾,还有平台没有定义时的回退定义。


如果一个平台定义了与平台相关的atomic的实现,就会同时定义ARCH_ATOMIC宏,表示平台定义了一系列以arch_开头的原子操作的API。例如,在arch/x86/include/asm/atomic.h中定义了一系列以arch_开头的函数后,就定义了#define ARCH_ATOMIC宏。这个宏可以用来控制上层通用的atomic.h头文件包含什么样的回退文件。x86平台也分为32位版本和64位版本,在这个文件的最后包括如下的头文件。

asm目录下同时存在atomic.h、atomic64_32.h和atomic64_64.h三个头文件。atomic.h文件在32位和64位不同情况下分别包含atomic64_32.h、atomic64_64.h,这是为了处理不同宽度下64位原子操作的不同实现的问题。
arch目录下平台相关文件的正文定义的就是各个以arch_开头的原子操作的API通用入口。这里的回退定义有两种情况:一种是指硬件平台虽然没有提供直接的API实现,但是提供了以arch_开头的API;另外一种是平台没有提供以arch_开头的API,但是可能会零星地提供一部分函数直接实现。
我们可以以自适应的atomic_long_t类型的原子变量来说明cmpxchg的高层API,代码如下。


上述内容形成了atomic_long_try_cmpxchg_acquire这个高层API的定义路径,在64位下atomic_long_try_cmpxchg_acquire会直接调用atomic64_try_cmpxchg_acquire函数,atomic64_try_cmpxchg_acquire会调用带有arch_前缀的函数arch_atomic64_try_cmpxchg_acquire,在x86下不需要做额外的acquire处理,最后会直接调用到arch_atomic64_try_cmpxchg函数。
在RMW类操作中最常用并且比较复杂的当属cmpxchg操作,流行的CPU都会直接提供指令层面的实现。内核会定义类似cmpxchg(ptr,old,new)这种包含三个参数的函数。将ptr指向的内存的值与old值进行对比,如果两者相等就将ptr指向的内存值设置为new,整个过程是原子的。
指令本身是没有返回值的,但是函数有。Linux的高层程序通常会使用带有内存一致性语义的API,例如atomic_long_try_cmpxchg_acquire。
在内核中与平台相关的实现通常以arch_开头。arch_cmpxchg和try_cmpxchg都是使用cmpxchg指令的功能,cmpxchg也是一个单独的模块,在x86下位于arch/x86/include/asm/cmpxchg.h,该文件的实现也使用了包含不同架构的头文件的做法,具体如下。

在这种组织结构下,可以看出Linux内核将x86同时指代x86的32位版本和64位版本。在64位的平台下,不需要额外模拟32位版本的cmpxchg,因为通常在指令集上都会直接包含,而在32位平台下,对于64位版本的cmpxchg则需要进行模拟实现。
通用的cmpxchg的实现是一个基于不同操作数宽度的switch结构,代码如下。


由于atomic_long_try_cmpxchg_acquire高层API实际调用的是try_cmpxchg函数,这里就直接在arch目录下找到try_cmpxchg函数定义的入口,与原子操作的定义相衔接。
try_cmpxchg函数是一个宏,返回值相当于最后一个声明值,这里就是success的值,即是否成功的布尔值。atomic_long_try_cmpxchg_acquire的返回值也是一个布尔值,代表try操作是否成功,从上述的调用链条可以看到,返回值是直接传递的。最终的success的值就是atomic_long_try_cmpxchg_acquire的返回值。
我们需要了解CPU的cmpxchg指令的定义,该指令接受两个指定输入,同时依赖EAX的值。下面以32位为例:CMPXCHG r/m32,r32指令的作用是对比EAX的值与r/m32的值,如果值相等,则ZF标志被设置,r32的值被设置到r/m32中,如果值不相等,则ZF标志被清除,并且r/m32的值被设置到EAX中。用伪指令表达如下。

其中OP1可以是内存数,几乎只有当OP1是内存值时r32指令才有意义。当OP1是一个内存值的时候,整个语义可以理解为OP1内存中的值在发生变化之前应该是EAX中的值。
Linux在将指令转换为函数的时候,需要考虑是否设置成功,如果设置不成功,那么不管当前内存中的值是多少,都要返回。在try_cmpxchg(ptr,pold,new)的三个参数中,ptr和pold都是指针,ptr代表的是OP1,new代表的是OP2,pold代表的则是要加载到EAX中的原来的值和承载设置失败情况下的原来的值。pold代表旧值的指针,如果设置失败,旧值就会被更新为当前内存中的值。
锁总线的指令前缀在cmpxchg指令上是默认存在的,不需要进行额外的设置。__raw_try_cmpxchg函数的最后三行则说明:如果设置失败,success就为false,就需要通过*_old=__old将old指针设置为当前内存中的值。由ZF状态得到success的值是通过CC_SET和CC_OUT宏做到的。cmpxchg指令输入的是__old放入EAX寄存器中的立即数,并不是指针,这个过程是通过[old] "+a"(__old)指定的,a代表限定使用EAX寄存器来存放__old变量,+代表EAX寄存器在汇编过程同时输入和输出。[new] "r"(__new)则代表__new任选一个寄存器存放,[ptr] "+m"(*__ptr)代表__ptr是一个输入/输出的内存变量。整个过程:在函数的开头使用__typeof__(*(_ptr))__old=*_old;语句,将old指针中的值提取到__old中,然后将__old放入EAX。汇编执行失败会直接修改_old变量的值,所以如果最后失败了,则进行*_old=__old操作。
try_cmpxchg会返回布尔类型的值代表操作是否成功,而arch_cmpxchg(ptr,old,new)函数不是try的语义,返回值是int,这个函数与try_cmpxchg的区别有两个:(1)try_cmpxchg的输入值是pold,而arch_cmpxchg的输入值是old;(2)try_cmpxchg的返回值是布尔值,而arch_cmpxchg的返回值永远是ptr指向的内存的设置值。当返回值与old值不相等时,则代表arch_cmpxchg失败,返回值就是失败时ptr中的当前值,如果成功了,则返回值与old值相等。
Linux从上往下的锁语义同时提供了尝试加锁和直接加锁两个API,主要的区别就在于返回值不同。Windows针对原子操作的定义是直接设置一个API,定义如下。

锁总线进行不同位宽度的计算这种行为比较常见,Linux内核x86的cmpxchg模块还同时提供了其他锁总线的指令计算,做法是将上述cmpxchg的逻辑抽象成一个宏函数定义:#define __xchg_op(ptr,arg,op,lock),将op参数换成xadd就是带锁的不同宽度的累加操作。