
下载掌阅APP,畅读海量书库
立即打开



双向链表的缺点是如果有很多特别短的链表(比如只有一个节点或者空链表),双向链表的next和prev的头部就非常占用空间。哈希表使用哈希函数计算得到一个地址,然后直接访问该地址的机制实现快速访问,但是哈希算法不可避免地会有哈希冲突(多个输入产生了同一个地址输出),此时解决哈希冲突的方法就是使用哈希桶,开链哈希表是哈希桶的常见实现方式,原理是在同一个计算地址的位置实现一个链表,该链表链出所有哈希结果为本地址的值。
在通常情况下,哈希表大部分的域都是空白的,哈希表所需要的空间大小要提前分配。一个双向链表的头部有两个指针的大小,这两个指针全部放入哈希表所分配的空间,会比单链表的头部所占用的内存空间多一倍。所以内核专门设计了hlist,即只有一个指针大小的头部的双向链表。hlist的结构如图2-3所示。
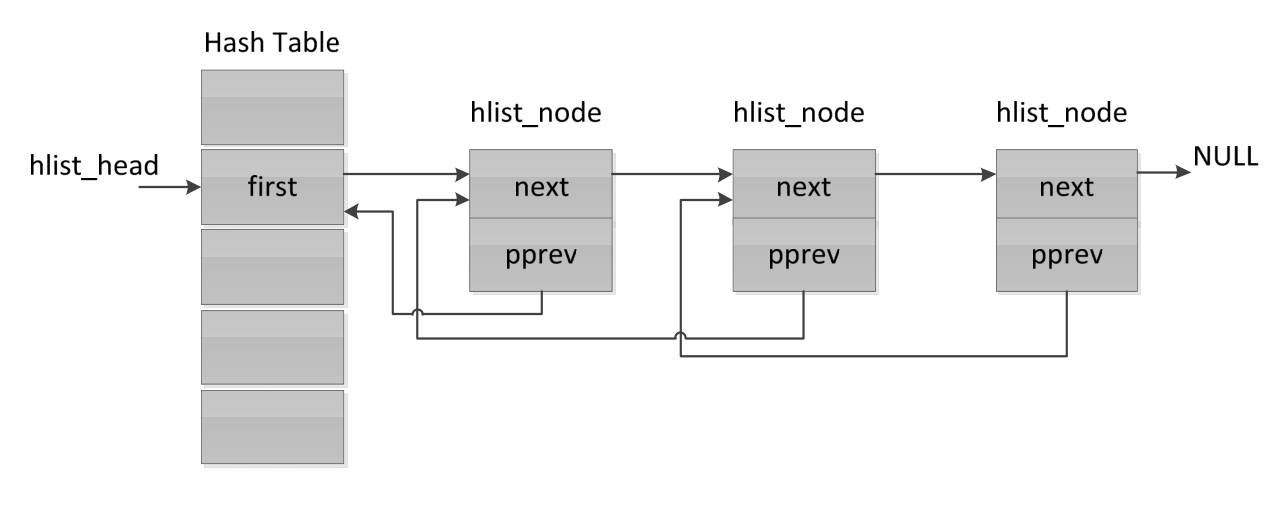
图2-3 hlist的结构
哈希链表在组织方式上的第一个节点与普通双向链表的不一样。节点定义如下。

Linux双向链表是环形的,而hlist有特定的头部结构,其头部(hlist_head)只有一个first域,用来指向第一个节点(一个头部只有一个整数大小)。首先hlist_head的first域指向一个双向链表,相当于在原来的双向链表上提取了一个钩子指针指向开头的list_head位置,然后将第一个节点的pprev指向hlist_head,牺牲了从第一个节点直接访问最后一个节点的能力,最后一个节点的next是NULL,相当于去掉了双向链表从最后一个节点访问第一个节点的能力。在hlist的开头位置添加一个节点,代码如下。


这么做其实是为了适应头部设计而引入的带“副作用”的解决方法。之所以要设计头部为一个指针大小是因为提高哈希桶的空间利用率,而这个头部的引入导致了第一个节点与后面节点的不同,因此,在理论上,所有相关的操作(添加、删除、遍历等)都得特别照顾第一个节点(多一个特殊情况判断)。如果能从数据结构设计上将这种特殊情况去掉无疑是最好的,而hlist的设计做到了这一点。其pprev(对应于双向链表的prev)并不是指向上一个节点的数据结构,而是指向上一个节点的next域。这对于头部节点来说,struct hlist_head结构体的first域既是指向下一个节点的指针,也是下一个节点指向上一个节点的指针,如此就能让所有节点对所有操作都展现出几乎一样的接口了。
hlist的最后一个节点的next的值是NULL,这个位置是固定的,而且是被浪费掉的。这个节点的指针大小为8字节(64位),任何一个节点的指针值的最后一位都必然是0。Linux利用了对齐特性实现了hlist的变种hlist_nulls。hlist_nulls与普通hlist的区别就在于NULL的表示方式是最后一位,但是hlist_nulls带来了更多有趣的使用方式。例如当需要暂时截断这个hlist_nulls的时候,可以不用将链表从hlist_nulls中摘下来,而只是简单地在要截断的位置将next的最后一位设置为1即可,具体代码如下。

从数据结构上看,hlist_nulls和hlist有一样的数据结构,在内存布局上也是一样的。
Linux的网络管理子系统使用哈希表来管理所有的TCP连接,所使用的链表就是hlist_nulls,我们以net/ipv4/tcp_ipv4.c中的ipv4的TCP连接管理为例,来说明hlist在哈希表中的应用。在net/ipv4/tcp_ipv4.c文件的开头有定义struct inet_hashinfo tcp_hashinfo结构体,具体代码如下。

在以上struct inet_hashinfo tcp_hashinfo结构体中定义了三个哈希表:ehash代表已经建立的TCP连接对应的哈希表,bhash代表bind状态的哈希表,lhash2和listening_hash代表listen状态的哈希表。下面我们以ehash为例进行说明。TCP的哈希表被单独定义成一个文件,位于net/ipv4/inet_hashtables.c,里面包含了大部分struct inet_hashinfo 结构体的定义和操作函数的实现。TCP在使用struct inet_hashinfo结构体的时候,除了定义该结构体的全局变量,还需要对该结构体进行初始化。初始化代码位于net/ipv4.c:tcp_init()函数,ehash的初始化代码如下。


由上述可见,struct inet_hashinfo结构体的ehash指针只简单地申请了一大块内存作为哈希表空间,每一个bucket entry的大小都是sizeof(struct inet_ehash_bucket),具体代码如下。

一个简单的hlist_nulls头部的封装,其大小是一个指针的大小,一共有thash_entries个,这里的个数是这个哈希表中一共可以存储的元素个数。哈希表可以根据元素总数和发生冲突的概率来计算得到bucket数,就是分配的内存数。这种计算方式在理论上要不同情况不同对待,但是在内核中统一使用log2(numentries)来进行计算。对哈希表所需内存的估算可直接在alloc_large_system_hash()这个内存分配函数中完成,该函数位于mm/page_alloc.c,是直接对外提供内存分配服务的接口函数。
alloc_large_system_hash()函数在分配内存的时候,只有当第三个参数(thash_entries)是0的时候,才会使用第四个参数(ehash初始化代码中的“17,”)来确定bucket的个数。thash_entries是一个内核启动参数,可以在启动内核的时候手动指定。对于未指定entry数目情况下的bucket的计算,alloc_large_system_hash()函数会根据scale得到的结果有一个通用的算法。最后得到的哈希表内存大小的计算方式是:bucketsize<<17,就是输入的scale的大小一共是128KB,这就是TCP的ehash的bucket数组的bucket数量,再乘以sizeof(struct inet_ehash_bucket)就是bucket内存的大小。每个bucket在使用的时候都会对应一个hlist_nulls的哈希链表,当该bucket没有被用到的时候,bucket上的值就是NULL,也相当于head->first的值是NULL,即空链表。
这个内存申请函数还传入了tcp_hashinfo.ehash_mask函数,alloc_large_system_hash返回的bucket数量一定是2的整数倍,1<<17-1就相当于这个bucket数量的最大值,这个最大值在计算哈希索引的时候特别有用,代码如下。

当从一个哈希值选择bucket的索引的时候,直接使用hash & hashinfo-> ehash_mask就可以得到一个小于最大bucket数的索引值,从而将哈希结果规约在数组的索引范围内,定位到具体的bucket。向ehash的哈希表中添加一个元素,代码如下。


上述代码中的参数osk代表要删除的条目。首先使用sk->sk_hash=sk_ehashfn(sk)计算出sk的哈希值,然后由head=inet_ehash_bucket(hashinfo,sk->sk_hash)得到该哈希值对应的bucket,再对这个链表上锁,最后调用hlist_nulls的添加函数将sk的链表添加到bucket的链表中。
这里添加函数调用的是__sk_nulls_add_node_rcu,而不是hlist_nulls_add_head,因为在include/linux/rculist_nulls.h这个头文件中,对普通的hlist_nulls进行了方法扩充,使用的还是hlist_nulls的数据结构,只是增加了RCU相关的方法。RCU是指内核的RCU锁,只有在修改链表的时候需要加锁,在遍历访问链表时不需要加锁。
哈希表的多级哈希就是为了可以高性能所以不加锁或者加小锁。在用户模式实现的开链哈希表,无论是遍历还是修改都需要对整个链表进行加锁,这也是开链的方式在高性能哈希表中不被经常使用的原因。但是Linux内核提出了使用小锁的方案,该方案可以极大地增强并行能力。
llist的全称是Lock-less NULL terminated single linked list,意思是不需要加锁的list。在“生产者-消费者”模型下,如果有多个生产者和多个消费者,则生产者意味着链表添加操作,消费者意味着链表删除操作。如果有多个生产者或者多个消费者一起操作,就需要加锁,但加锁是高耗费的操作,为这个需求诞生的就是llist。
Linux内核实现的无锁llist并不是在所有的情况下都无锁,可以使用的组合如下。
● 当多个生产者和多个消费者参与的时候,llist_add和llist_del_all可以无须加锁并发使用。
● 当多个生产者和一个消费者参与的时候,llist_add和llist_del_first可以无须加锁并发使用。
● 遍历只可以发生在llist_del_all之后,也就是遍历不是无锁的。
从上述使用场景可以看出,llist的使用场景是多个生产者对应一个或多个消费者的情况。并且由于遍历不是无锁的,所以在设计上遍历属于消费者,先调用llist_del_all一次性地将列表中的元素全部摘下,再进行遍历处理。从这个意义上看,该链表更多起到队列的作用。
Linux中断分为上半部分和下半部分。上半部分会关闭所有中断,使系统失去响应,为了减少失去响应的时间,上半部分不能休眠,复杂的操作也得放到下半部分执行。这意味着上半部分的代码不能使用加锁操作,否则容易发生中断重入,所以就又产生了加锁的需求。提高Linux中断上半部分使用list数据结构能力的最好方式是使用无锁llist,数据结构如下。

内核实现的方法是使用cmpxchg宏。cmpxchg宏也是Intel平台的一个汇编指令,其作用是让读取、比较、改变这三个操作都是原子的。cmpxchg宏有3个参数,如果第一个参数和第二个参数相等,则将第三个参数写入第一个参数指向的地址。如果第一个参数和第二个参数不相等,则返回第三个参数,本意是将第三个参数写入第一个参数指向的地址,所以cmpxchg宏先读出head->next,将head->first作为第一个参数,紧接着读出的head->first作为第二个参数,要添加的新节点作为第三个参数,代码如下。

在调度系统中,每一个CPU都会有一个运行队列叫struct rq,当前CPU的任务调度的信息大都存储在这个结构体中。在struct rq中,有一个struct llist_head wake_list域,这个域是llist的无锁单链表,其作用是接受其他的CPU核心送过来的任务,并且在本CPU可以调度的时候进行调度执行,这个机制整体上叫作ttwu(try to wake up)。下面是ttwu的一个函数的代码。


当一个CPU认为自己没有足够的精力处理一个任务的时候,ttwu_queue_remote函数就唤醒一个相对空闲的CPU来代替它进行处理。这种唤醒另外一个CPU来处理问题的操作是通过IPI(Inter Process Interrupt,核间中断)进行的。从一个CPU插入另外一个CPU的唤醒队列的方式是ttwu_queue_remote函数,即无锁地将一个任务插入另外一个CPU运行队列的wake_llist中,然后通过IPI唤醒目标CPU。
当目标CPU被唤醒的时候会检查自己运行队列的wake_llist,通过struct rq *rq=this_rq()得到自己的运行队列,然后将运行队列中wake_list的所有任务都一次性摘下:struct llist_node *llist=llist_del_all(&rq->wake_list)。这一步就是将无锁链表的多消费者全部摘取。在将无锁链表的多消费者全部摘取之后,llist_for_each_entry_safe(p,t,llist,wake_entry)对已经摘下来的链表进行遍历,带有safe后缀的遍历函数则代表在遍历的过程中其可以被删除。
树是管理大型复杂结构最常用的数据结构类型。在内核中比较常见的是用于内存线性地址空间管理的红黑树(rbtree)和用于文件系统文件组织的B+树(btree)(一些文件系统也会实现自己的B+树),以及用于组建整数查找的基树(radix tree)。Linux基树与trie树非常类似,只是Linux基树一般用来定位整数,trie树一般用来定位字符串。
IDR(Integer ID Management)机制在Linux内核中指的是整数ID管理机制,大部分需要申请释放整数资源的操作,在Linux内核中最终都会转换为对一个IDR组件的使用。在常见的硬件驱动中,由于设备地址和设备编号一直都是强对应的关系,所以对设备编号和设备地址的处理属于同一类问题。当需要从PID找到对应的进程结构体时,可以向IDR输入PID,以快速得到对应的结构体指针,这就是一个从ID值快速搜索得到对应的结构体指针的需求。搜索的频率总是高的,所以IDR会采用搜索树,也就是被优化过的基树。
trie树是数据结构中常见的字典树,常被用于搜索字符串。Linux基树是一种压缩的trie树,简单说就是trie树中只有一个子节点被压缩成一个单独的节点。
最新的Linux内核在实现基树的时候,只保留了原来基树的API,Matthew Wilcox设计了xarray,在API上刻意与原来的基树保持类似的设计,使得基树的应用可以很容易就过渡到xarray。之所以要设计xarray,有很大一部分原因是基树的API设计不能让人满意,因此xarray通过观察已有的类似的使用方式,提供了一个新的API设计方式:一套是简单的基础API,在内部自动进行了锁和内存管理;另外一套是高级的API,可以深入到数据结构体的内部。IDR直接使用基树,但是基树的实现已经变成了使用xarray的封装。
xarray相当于一个树形数组,从外部看,这是一个可以容纳64位整数的数组,其实现并不是真的使用一个大数组,而是在内部组织了层次的结构,当需要用到对应数的时候,才会产生该数所对应的内部树的节点。
1.xarray对比红黑树与哈希表
xarray是内核比较新的用于取代基树的数据结构,也叫作动态数组,从本质上来看,xarray延续了基树的思路并对基树进行了改良。基树以前存在的主要问题如下。
(1)内核的基树在本质上是一个动态数组,但是并不是一棵树,所以其对应的API对使用者不是很友好。
(2)基树的实现需要用户进行锁处理。
新的xarray增加了默认的锁处理,并且提供了高级API,使得用户可以更好地控制锁的行为。
内核面临的一个大问题是对内存页的管理。每个进程所有映射的页面都需要被划分成很多个内存块,有的内存块是文件映射,有的内存块是内存映射和brk,这些内存空间并不一定是连续的。在大部分情况下,在进程可见的地址空间内,每个内存块都被组成一棵红黑树,树中的每个节点都有开始和结束的内存位置。当需要申请一个新的映射的时候,就可以从这棵树中快速找到可用的位置,或者当操作一个内存位置的时候,可以快速找到这个内存位置属于什么映射。
整个过程都需要一个能够管理内存不规则使用且又需要快速查找的数据结构。类似的需求还有用于管理文件在内存中缓存的address_space中的页,该需求使用基树来组织,因为有的文件内容需要映射缓存,有的则不需要,是否需要映射缓存在本质上是由用户的使用情况决定的。
Linux的文件缓存是基于文件块序号的,而进程的内存映射是由连续内存块组成的entry管理的,管理的粒度是不一样的,这也反映出红黑树与基树在使用选型上的区别。
对于内存空间的内存映射这种功能,从内存资源占用上来看,最适合选择按照节点为管理单位的红黑树的方式。而对文件缓存(page cache)的管理最适合选择以基树为单位的管理方式。这两种管理方式在单核查找性能上类似,但是如果数据稀疏,基树的内存浪费就会远大于以节点为管理单位的红黑树,反之,如果数据比较密集,红黑树的管理成本就会很高。这两者还有一个巨大的区别,就是在多核性能上,红黑树的操作需要对整棵树加锁,涉及变色与旋转,一个节点的改变可能会带来父节点、子节点和兄弟节点的同步变动。而基树由于具有从上而下的确定性,完全没有变色选择这种操作,在并发上可以做到很轻量级的锁。在内核中直接使用RCU锁。
在使用方式上,红黑树的节点可以嵌入其他数据结构,而基树的节点不可以嵌入其他数据结构,只可以由基树直接保存整数或者由指针来指向其他数据结构。这种使用上的区别就决定了使用基树的场景必定是相对独立的功能模块,这与内核中的大部分数据结构可以灵活地嵌入其他数据结构中的做法有区别。
像基树和红黑树这种用来加速查找的数据结构,链表是比较早期被选择用于解决这个需求问题的,因为链表具有简单性,其在早期比较容易验证想法,然后就是红黑树。
xarray旨在对使用者提供一个类似动态数组的使用体验。哈希表的性能是极高的,但是缺陷也很明显,因为元素之间没有顺序性,或者说无法按照特定的顺序进行元素定位。要同时做到可遍历和高效查找,一般需要在哈希表之外同步维护一个外部的链表或其他有序数据结构,这样可以综合哈希表的定位性能和外部数据结构的顺序能力。但是这仍然无法解决顺序元素之间的离散问题,当遍历顺序元素的时候,通常希望顺序元素都尽可能地落在同一个cache行中,以得到cache加速的优势,但是链表和红黑树等顺序数据结构并不具备该能力。在文件系统上广泛使用的B+树具备这种连续性能力,但是B+树在提高CPU效率上比红黑树差很多,只适合使用在层次敏感的查找场景。这并不是说哈希表相比xarray就一无是处,布谷鸟哈希表出色的内存稳定占用的表现就是xarray不具备的。
可以说,xarray是哈希函数固定的多级哈希表,最适用的场景是整数域。xarray继承了多级哈希的节约空间、快速索引、局部锁的高性能特性。
2.xarray的主要数据结构
xarray的整体结构图如图2-4所示。
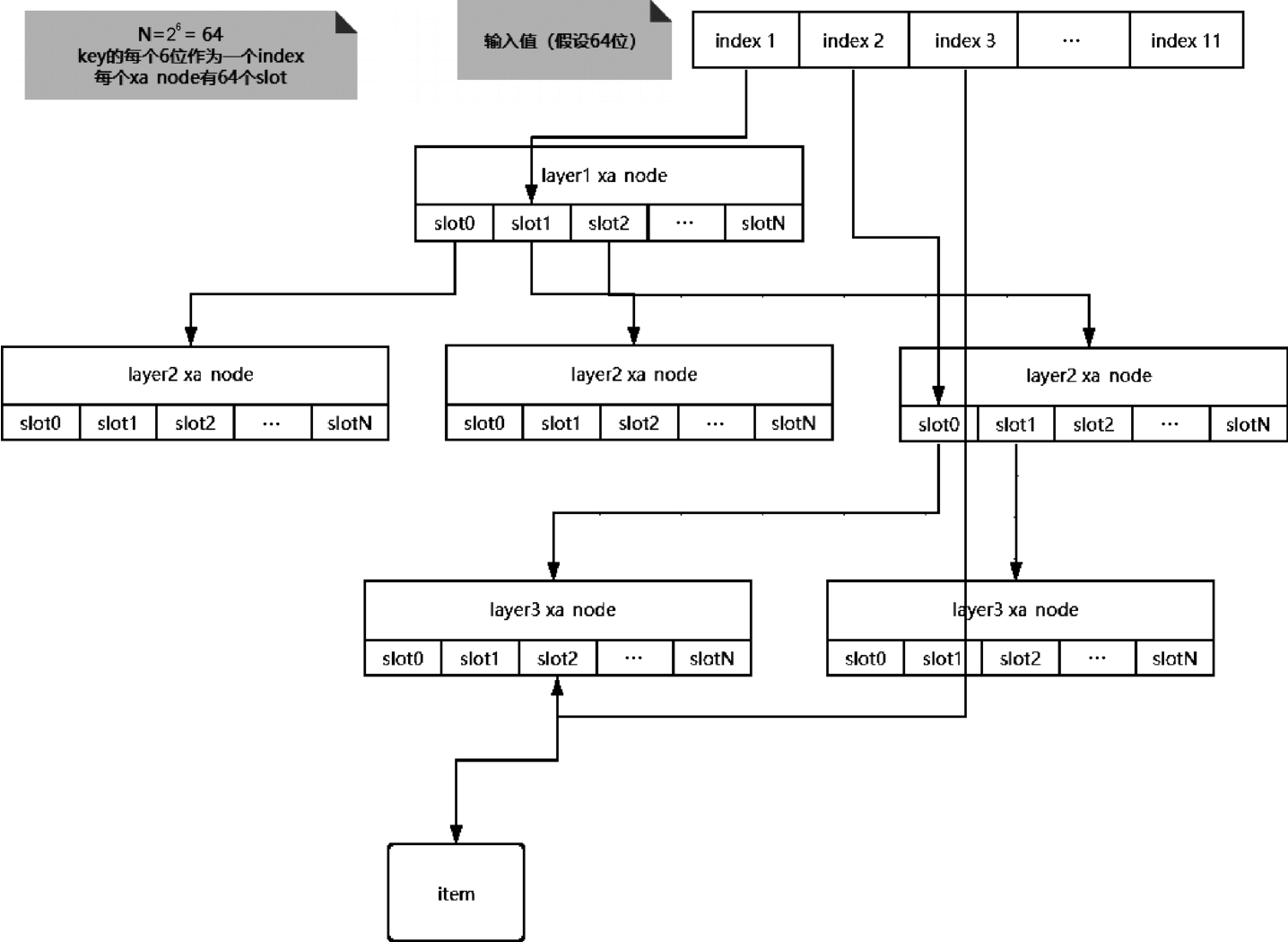
图2-4 xarray的整体结构图
xarray的整体数据结构是struct xarray,这个数据结构非常简单,具体代码如下。

xarray只是一个数据结构的整体头部,可以被其他数据结构直接内嵌。但是xarray存储的是整数值,且直接存储在xarray内部。被存储的整数值可以是指针,但要求是4字节对齐的指针。xa_head是指向第一个节点的指针,在xarray没有实际存储内容的时候,该值为NULL。整个xarray相当于一个由xa_node组成的多叉树,具体代码如下。

一个xa_node就是xarray中的一个节点,在每个节点中都可以包含多个值和下一级节点的指针。整体的思路就是,在slots数组中,如果slot只代表一个值,就直接存储在slot对应的索引中,如果代表多个值,在该slot偏移中就会存储下一级xa_node的指针,下一级xa_node的slots数组可以继续存储数据。slots数组的大小是XA_CHUNK_SIZE的值,该值是一个宏定义,默认是2 6 个,xarray模块给出了一个可以改为2 4 个的内核配置选项CONFIG_BASE_SMALL。slots数组的个数反映了树的扁平程度,因为一个整数最大也才只有64位,每一级6位,最大11级,就能达到66位的表达能力。如果每一级只有4位,那么64位的整数理论上需要16级才能表达。
slots数组中存储的虽然是void*类型的指针数据,代表的只是数据的长度,但数据的意义是多样的。可以存放在slots数组中的内容叫作entry,entry可以是用户要存储的整数或者指针,也可以是内部特殊节点或者内部指针。nr_values代表slots数组中存储的用户数据的个数。count代表slots数组中存储的所有可能的entry类型的个数。
3.数据entry和指针entry
entry的定义并不那么直白,例如用户存储的数据是4,但是entry的值实际上是9;用户存储的数据是0,entry的值实际上是1。entry的特点是整数的最后一位被专门设置为1,然后整数左移了1位。将用户存储的整数变为entry值的转换函数如下。

xarray可以存储整数或者指针,但是同一个xarray要么存储整数,要么存储指针。对于指针类型或者整数类型,xarray的entry表示是不同的。如果存储的是整数类型,则使用最低位置1的方式;如果存储的是指针类型,xarray要求指针的最低二位必须是0,也就是要求4字节对齐,因为最低二位用来表示指针的tag。最低二位有四种值:00、01、10、11,xarray使用00、01、11三种值作为tag值,也就是tag有三种可能的取值,10作为内部entry的表示。这个设计需要综合来看,如果存储的是数据,则最后一位是1,如果最后一位是0,那么倒数第二位是1(也同样表示内部entry)。这样相当于在存储整数的时候,使用1和10两种二进制表示方法来区分值entry和内部entry,使得值entry可以使用剩下的63位。如果存储的是指针,则内部entry的表达方式仍然一样,指针可以加三种tag,即00、01和11,也可以不加tag,就相当于00种类的tag,也就是最后两位为0。为指针制作的tag可以取值0、1或3,其函数如下。

4.内部entry
内部entry就是最低二位是10的entry,其制作函数如下。

相当于将v左移两位,最低二位设置为0。一共有三种内部entry,256号的retry entry、257号的zero entry、0~62号的sibling entry。三种内部entry的定义如下。

sibling entry通过输入0~62号的offset值来制作,sibling entry用于多索引节点功能,由于xarray对外展现的是数组的形态,所以在存储时也需要输入一个数组的序号和要存储的内容。多索引可以将一片连续的索引合并成一个,对其中一个进行操作相当于其他的索引位置也进行了同样的操作,作用是将具有相同内容的连续值进行统一管理,以减少属性重叠带来的存储支出。整个xarray工作在位数下降的层次,能进行合并的slot都是连续的2的指数幂的跨度,例如64~127可以被合并,但是2~6不可以。合并的跨度越大就越节省内存,因为高层次的xa_node的slot下面都是有子树的,xarray被设计为在最上面一级进行sibling实现就能做到全部子树的合并,不用真实创建具体的子树。
retry entry代表一个并发的中间状态,即该entry正在被持锁操作,其所在的xa_node有可能在释放锁后被释放,所以如果在查找操作过程中遇到这种节点,就需要重新进行查找。
zero entry代表空的entry,相当于该entry目前处于预留状态,通常是在xa_reserve()预留的slot位置放置这种zero entry。
5.xarray的对外接口
由于一个数组的操作接口是比较简单的,所以xarray对外呈现的操作接口也是很简单的,主要就是读/写操作,读操作使用xa_load,写操作使用xa_store,定义如下。

xa代表的是要操作的xarray,index代表数组的索引序号,gfp代表申请内存时所需要提供的标志。作为一个足够复杂的数据结构,xarray的基本API中还涵盖了很多的变种。例如,xa_erase用于删除一个值,相当于调用xa_store,存一个NULL值进去;xa_insert相当于存放但不覆盖已有的值;xa_cmpxchg相当于已有的值和指定值必须匹配才会设置;xa_find用于查找一个满足条件的index。
6.xarray操作的中间状态:xa_state
在xarray中常出现的术语有:shift,一般表示一级node的偏移位数;offset,一般表示当前node的slot中的偏移值(0~63);index,一般表示整个数组的索引序号。xarray在实现的时候设计了一个专门的xa_state用来在中间的函数层级间进行状态传递,xa_state并不会直接对用户暴露,是笔者为了代码质量专门抽象的中间表达,主要包括当前操作的节点的状态。xa_state只存在于函数的栈变量上,也就是进入了xarray的函数中定义的局部变量。xa_state的内容与函数当前操作的位置有关系,如果对应到普通数组,就相当于当前正在处理的索引值,其定义如下。


xarray的代码比较难以理解,因为其是由多个组件组成的,每个组件都有单独的操作函数。xa_打头的函数是外部使用的函数,在内部会使用xa_state来表示,所以最后实际上大部分会调用到对应的xas_开头的函数。xas_开头的函数属于高级函数,用户可以自己调用xas_开头的函数,这就是xarray的高级API用法。这种用法需要自己管理锁,并且处理xa_state的状态。