
下载掌阅APP,畅读海量书库
立即打开



ID3算法的全称是Iterative Dichotomiser,这是一个迭代二分算法。为了使分支尽快到达叶节点,在对落入某个节点的样本进行分割的时候,应该力求分割得到的两个集合具有较高的纯度。这个算法利用了信息熵来衡量分割的纯度,p表示正样本(分类为是)的比例,n表示负样本(分类为否)的比例,一组样本的熵H(p,n)定义如下。
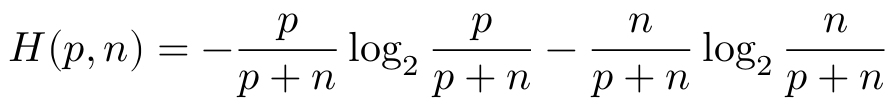
熵是不确定性的度量,如果一组样本大都属于同一类别,纯度高,那么它们的不确定性就低,熵就小。反之,样本纯度低,熵就大。假设某个分割A将样本分为两组,两组正负样本数量分别为(p1,n1)和(p2,n2),分割后的熵就是两组熵的加权和。
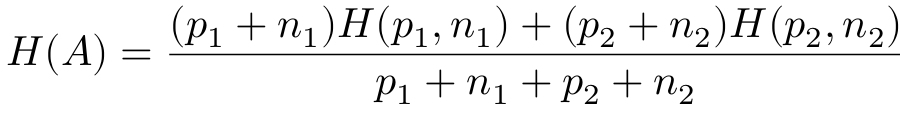
好的分割应该能够让熵减小更多。由于熵减小的过程对应着信息量的增加(信息可以消除系统的不确定性,因此信息使得熵减小),因此算法把减小的熵叫作“信息增益”gain。选择节点分支条件时,我们要选取信息增益最大的分支条件。gain(A)越大越好。
我们回到天气数据集,数据集中有9个正样本和5个负样本,它的熵是H(9,5)=0.940。如果选择天气晴作为分支条件,可以得到信息增益如下:
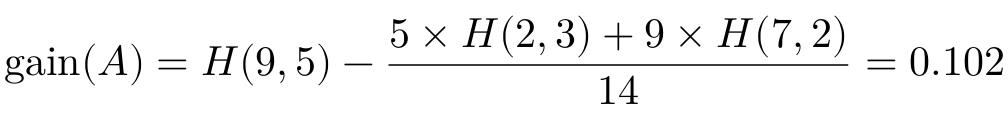
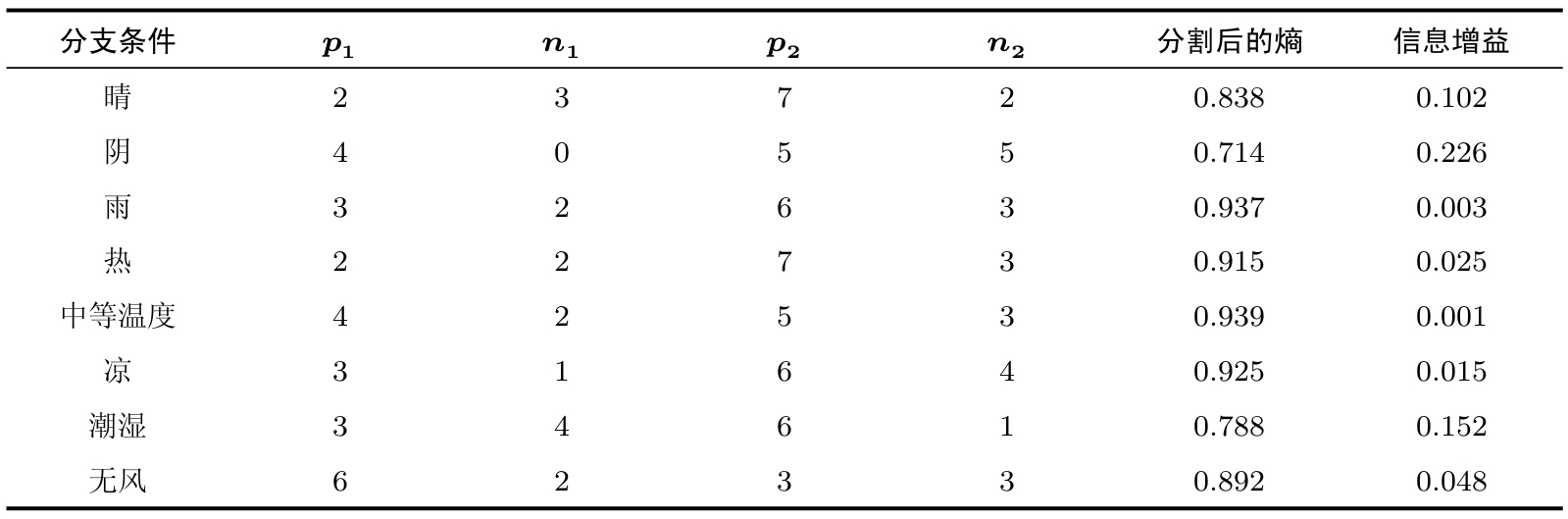
表2.2计算了所有不同分支条件的信息增益。从数据中可以看出,我们应该选择天气阴作为分割条件,它的熵最小或者说信息增益最大。
表2.2 选择不同条件分割数据集的信息增益
这样我们就把数据集分成了两部分,并且形成了决策树的根节点和第一层分支。其中,“是”分支得到了一个叶节点,我们需要继续对“否”分支进行递归的操作。最终我们会得到一棵决策树,如图2.2所示。
值得注意的是,ID3算法是一个贪心算法。每次选取分支条件的时候,它只关注局部最优,也就是如何对落入当前节点的数据子集进行分割,因此并不能保证得到全局最优的决策树。比如,对于上述天气分类问题,其实可以构造更精简的决策树。然而,这不妨碍ID3成为一个简洁有效的算法。一些后续的树生成算法采用了回溯和剪枝等方法,进一步改进了生成的决策树的结构。
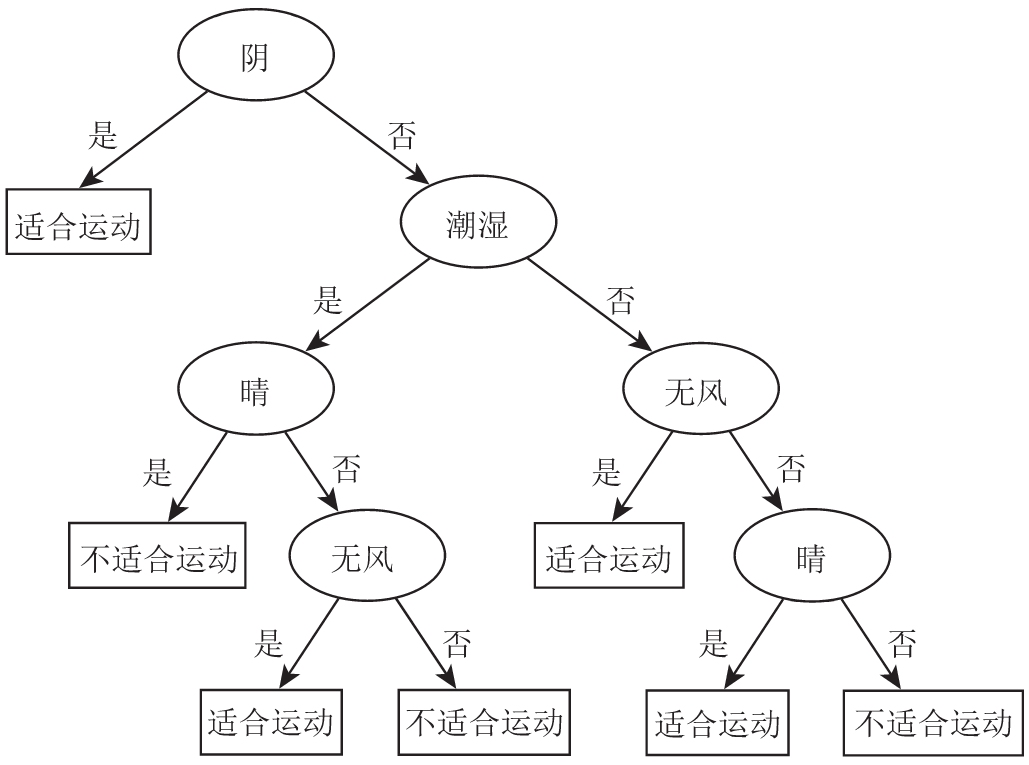
图2.2 ID3算法得到的天气分类决策树