
下载掌阅APP,畅读海量书库
立即打开



基于ARMv8体系结构设计的处理器内核有很多,例如常见的Cortex-A53、Cortex-A55、Cortex-A72、Cortex-A77以及Cortex-A78等。本书的实验环境采用树莓派4B开发板,内置了4个Cortex-A72处理器内核,因此我们重点介绍Cortex-A72处理器内核。
Cortex-A72是2015年发布的一个高性能处理器内核。它最多可以支持4个内核,内置L1和L2高速缓存,如图1.6所示。
Cortex-A72处理器支持如下特性。
●采用ARMv8体系结构规范来设计,兼容ARMv8.0协议。
●超标量处理器设计,支持乱序执行的流水线。
●基于分支目标缓冲区(BTB)和全局历史缓冲区(GHB)的动态分支预测,返回栈缓冲器以及间接预测器。
●支持48个表项的全相连指令TLB,可以支持4 KB、64 KB以及1 MB大小的页面。
●支持32个表项的全相连数据TLB,可以支持4 KB、64 KB以及1 MB大小的页面。
●每个处理器内核支持4路组相连的L2 TLB。
●48 KB的L1指令高速缓存以及32 KB的L1数据高速缓存。
●可配置大小的L2高速缓存,可以配置为512 KB、1 MB、2 MB以及4 MB大小。
●基于AMBA4总线协议的ACE(AXI Coherency Extension)或者CHI(CoherentHubInterface)。
●支持PMUv3体系结构的性能监视单元。
●支持多处理器调试的CTI(Cross Trigger Interface)。
●支持GIC(可选)。
●支持多电源域(power domain)的电源管理。
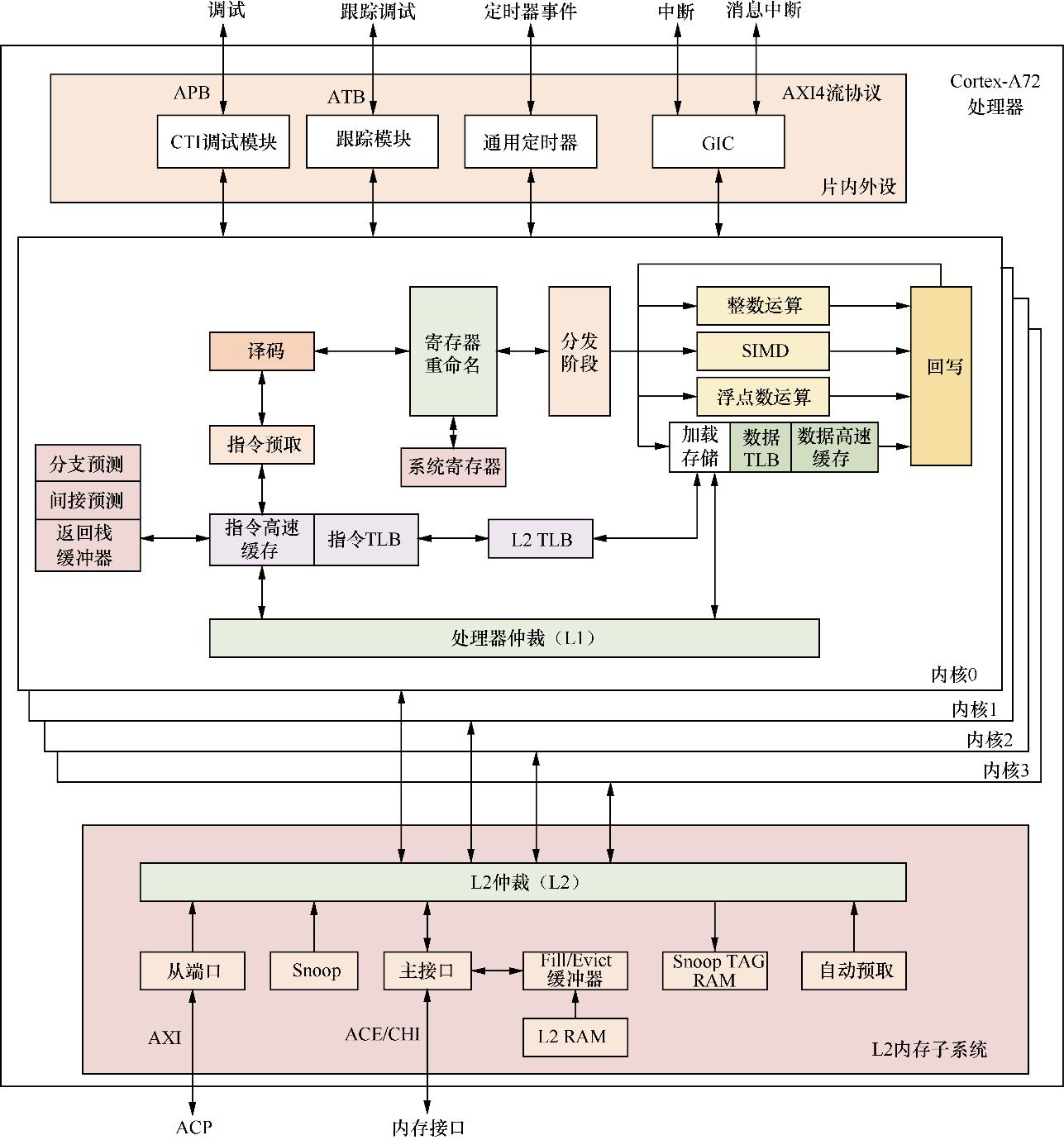
▲图1.6 Cortex-A72处理器内部体系结构
指令预取单元用来从L1指令高速缓存中获取指令,并在每个周期向指令译码单元最多发送3条指令。它支持动态和静态分支预测。指令预取单元包括如下功能。
●L1指令高速缓存是一个48 KB大小、3路组相连的高速缓存,每个缓存行的大小为64字节。
●支持48个表项的全相连指令TLB,可以支持4 KB、64 KB以及1 MB大小的页面。
●带有分支目标缓冲器的2级动态预测器,用于快速生成目标。
●支持静态分支预测。
●支持间接预测。
●返回栈缓冲器。
指令译码单元对以下指令集进行译码:
●A32指令集;
●T32指令集;
●A64指令集。
指令译码单元会执行寄存器重命名,通过消除写后写(WAW)和读后写(WAR)的冲突来实现乱序执行。
指令分派单元控制译码后的指令何时被分派到执行管道以及返回的结果何时终止。它包括以下部分:
●ARM核心通用寄存器;
●SIMD和浮点寄存器集;
●AArch32 CP15和AArch64系统寄存器。
加载/存储单元(LSU)执行加载和存储指令,包含L1数据存储系统。另外,它还处理来自L2内存子系统的一致性等服务请求。加载/存储单元的特性如下。
●具有32 KB的L1数据高速缓存,两路组相连,缓存行大小为64字节。
●支持32个表项的全相连数据TLB,可以支持4 KB、64 KB以及1 MB大小的页面。
●支持自动硬件预取器,生成针对L1数据高速缓存和L2缓存的预取。
L1内存子系统包括指令内存系统和数据内存系统。
L1指令内存系统包括如下特性。
●具有48 KB的指令高速缓存,3路组相连映射。
●缓存行的大小为64字节。
●支持物理索引物理标记(PIPT)。
●高速缓存行的替换算法为LRU(Least Recently Used)算法。
L1数据内存系统包括如下特性。
●具有32 KB的数据高速缓存,两路组相连映射。
●缓存行的大小为64字节。
●支持物理索引物理标记。
●对于普通内存,支持乱序发射、预测以及非阻塞的加载请求访问;对于设备内存,支持非预测以及非阻塞的加载请求访问。
●高速缓存行的替换算法为LRU算法。
●支持硬件预取。
MMU用来实现虚拟地址到物理地址的转换。在AArch64状态下支持长描述符的页表格式,支持不同的页面粒度,例如4 KB、16 KB以及64 KB页面。
MMU包括以下部分:
●48表项的全相连的L1指令TLB;
●32表项的全相连的L1数据TLB;
●4路组相连的L2 TLB;
TLB不仅支持8位或者16位的ASID,还支持VMID(用于虚拟化)。
L2内存子系统不仅负责处理每个处理器内核的L1指令和数据高速缓存未命中的情况,还通过ACE或者CHI连接到内存系统。其特性如下。
●可配置L2高速缓存的大小,大小可以是512 KB、1 MB、2 MB、4 MB。
●缓存行大小为64字节。
●支持物理索引物理标记。
●具有16路组相连高速缓存。
●缓存一致性监听控制单元(Snoop Control Unit,SCU)。
●具有可配置的128位宽的ACE或者CHI。
●具有可选的128位宽的ACP接口。
●支持硬件预取。