
下载掌阅APP,畅读海量书库
立即打开



成功的科学家与其同事的区别究竟是什么?产出量、影响力和运气的紧密联系,使得我们难以探究他们取得成功的真正原因。如果职业生涯中的重大突破是随机发生的,那么机遇、天赋或者勤奋与成功又有什么关系呢?我们能够完全将科学家的天赋和能力与他的运气分开吗?要想弄清楚这些问题,先来试想一下:如果仅凭运气,爱因斯坦做出那些杰出成就的可能性有多大呢?
如果有无限多的时间,一只在打字机上随机敲打的黑猩猩将肯定会打出一篇莎士比亚戏剧。那么,世界上有足够多的科学家,我们难道不应该期待,仅靠运气,注定就会出现像爱因斯坦那样有影响力的人吗?
要想回答这个问题,可以借助我们在第5章讨论的随机影响规则,建立一个科学家职业生涯的“零模型”(null model)。我们暂时假设,对科学家来说,发表一篇论文就相当于抽一张彩票。换句话说,假定天赋不起作用,那么完全由运气决定的职业生涯会是什么情况?
如果在随机的职业生涯中,每一篇论文的影响力完全由运气决定,那么这意味着,我们只是从某一个特定的影响力分布中随机挑选一个数字,将它赋予科学家发表的论文。利用这一方法,我们生成一组纯粹由运气决定的人造职业生涯。为方便起见,我们将这一方法称作随机模型或 R 模型。
这些随机的职业生涯与真实的生涯在某些方面相似。比如,前者在职业生涯的影响力方面会表现出个体差异,一些科学家在选择随机数时,运气总是会比其他人好一点。而且每个人的职业生涯也将会遵循随机影响规则:由于每一篇论文的影响力是随机选择的,影响力最大的成果在每位科学家发表的论文序列中将是随机的。但这些人为虚拟出来的随机科学家与真正的科学家有什么区别吗?
如果每篇论文的影响力是从相同的影响力分布中随机抽到的,那么一位更高产的科学家将会抽到更多的彩票,因而将更有可能撞上高影响力论文。也就是说,
R
模型预测,更高产的科学家更有可能产出突破性成果。要检验这种效应,先来衡量一下某位科学家引用量最多的论文的影响力<
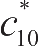 >,会受产出量
N
怎样的影响。结果确实证明,发表的论文越多,引用量最多的论文的影响力越大。但也不是足够大:测量结果表明,在真实的职业生涯当中,随着
N
的增长,影响力最大的论文,其引用量的增速比
R
模型预测的增速更快(见图6-1)。换句话说,如果影响力像彩票那样随机分配,那么当科学家多产时,他们最成功的论文比实际观测到的影响力要低。这说明我们的随机模型还缺少点什么。这也不难想象:科学家天生就各有不同,或者在天赋上,或者在能力上,或者在与产出高影响力论文相关的其他特点上。这表明高产的科学家并不只是在产出方面突出,他们还拥有一些低产出科学家所没有的东西。下面我们将对
R
模型进行调整,使它能反映这样的事实:并不是所有的科学家都是一模一样的。
>,会受产出量
N
怎样的影响。结果确实证明,发表的论文越多,引用量最多的论文的影响力越大。但也不是足够大:测量结果表明,在真实的职业生涯当中,随着
N
的增长,影响力最大的论文,其引用量的增速比
R
模型预测的增速更快(见图6-1)。换句话说,如果影响力像彩票那样随机分配,那么当科学家多产时,他们最成功的论文比实际观测到的影响力要低。这说明我们的随机模型还缺少点什么。这也不难想象:科学家天生就各有不同,或者在天赋上,或者在能力上,或者在与产出高影响力论文相关的其他特点上。这表明高产的科学家并不只是在产出方面突出,他们还拥有一些低产出科学家所没有的东西。下面我们将对
R
模型进行调整,使它能反映这样的事实:并不是所有的科学家都是一模一样的。
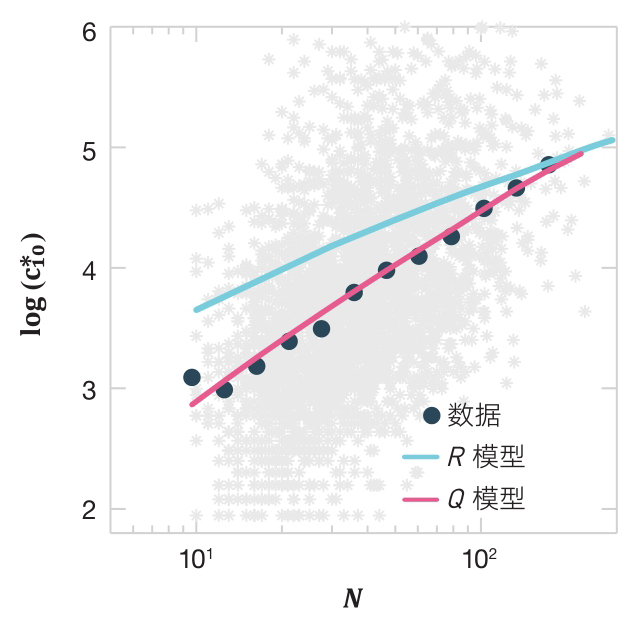
图6-1 科学生涯不是随机的
散点图表示在科学家职业生涯中,最高影响力论文的引用
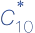 与发表论文的数量
N
之间的关系。每一个灰色点代表一位科学家。黑色小圆点是散点值的对数组合。青色曲线表示
R
模型的预测,它显示了与数据的系统性偏移。红色曲线代表
Q
模型的解析预测结果
[116]
。
与发表论文的数量
N
之间的关系。每一个灰色点代表一位科学家。黑色小圆点是散点值的对数组合。青色曲线表示
R
模型的预测,它显示了与数据的系统性偏移。红色曲线代表
Q
模型的解析预测结果
[116]
。
每个科研项目都始于一个构思。灵感促使科学家开始思考某种想法。但是我们很难提前判断一个想法内在的重要性和创新性。如果并不知道某个想法的真正价值,那就先假设它有某种随机价值 r 。有些想法带来的是增量式贡献,只有最相关领域内的少数人感兴趣,那么它的价值就比较一般。但是偶尔会突然出现一个好想法,如果能够完全实现的话可能具有革命性的意义。想法越好,其 r 值就越大,就越有可能具有高影响力。
但仅有好的主意还不够。项目的最终影响力还取决于科学家能否将构想转化为真正具有影响力的产品。人们可能最初有个奇思妙想,但是由于缺乏必要的专业知识、经验、资源,或者无法发挥这个构思的全部潜能,最终结果仍会不尽人意。然而,将构想转化为成果需要的能力因人而异,所以用一个参数 Q 来表示某个人将随机构想 r 转化为具有特定影响力的成果的能力。
换句话说,某位科学家论文的影响力 c 10 由两个因素决定:运气( r )和个人 i 所特有的 Q i 参数。这两者的组合可能涉及许多复杂的函数。为简单起见,我们假设有一个简单的线性函数,写作:

公式6-1背后具有多种假设。
· 当开始一个新项目时,我们从各种可能性中挑选出一个随机想法 r 。 科学家从相同的分布 P ( r )中挑选他们的 r ,因为我们都能阅读同样的文献,所以有着相同的知识。或者每位科学家也可以从他自己独有的 P ( r )中挑选 r ,就像某些科学家比其他科学家更善于选择好的构想。
· 科学家的 Q 参数各不相同。 也就是个人能力有所不同,即使是相同的构想,最终成果也可能产生不同的影响力。一方面,如果一位具有低 Q 因子的科学家有一个具有极高 r 值的构想,那么即使这个构想的潜力很好,项目的影响力也将趋于平庸,因为它所产出成果的 rQ 会因该科学家有限的 Q 而降低。另一方面,如果最初构想就很糟糕( r 值较低),一位 Q 值较高的科学家也只能产出一般或平庸的成果。真正能产生高影响力的论文是那些完美组合的结果,具有高 Q 因子的科学家又碰上了奇思妙想(高 r 值)。也就是说,该模型假设,一篇论文的最终影响力是两个因素的产物:构想的潜力以及将其真正实现的能力。
· 产出量也很重要。 即便 Q 和 P ( r )相同,具有更高 N 值的科学家更有可能碰上高 r 值的项目,并将其转化为能产生高影响力( c 10 )的论文。
问题在于,不能期待这些因素都相互独立存在: Q 值高的个人可能同时拥有发现高潜力项目的才能,因而他们的 P ( r )分布可能偏向较高的 r 值;那些发表较高影响力论文的人,可能同时拥有更多的资源去发表更多的论文,因而他们的产出量也会很高。也就是说,公式6-1的结果由联合概率 P ( r , Q , N )决定,但 r 、 Q 、 N 之间的相关性是未知的。要了解真实职业生涯的情况,我们需要计算这3个参数之间的相关性。我们最终得到了如下协方差矩阵 [116] 。
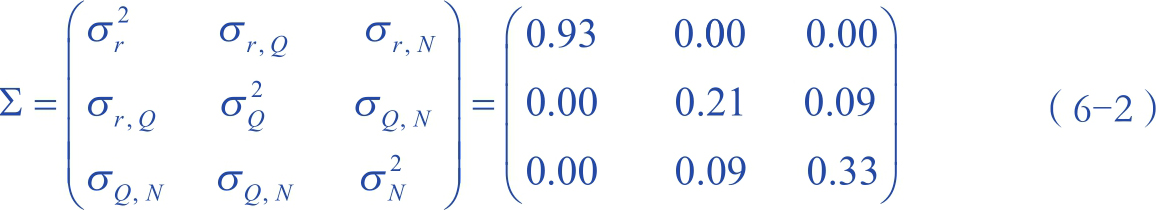
这产生了有关个人职业生涯的两个出人意料的预测。
· σ r,N =σ rQ ≈0表明,初始构想的值 r 很大程度上独立于科学家的产出量 N 或者他的 Q 因子。因此,科学家随机地从 P ( r )中寻求灵感,而这一分布对所有人都是相同的,代表着影响力背后普适的运气成分,而这是与科学家个人无关的。
· 非零的σ Q,N 表明,隐藏参数 Q 和产出量 N 确实相关,但σ Q,N 的值较小,说明高的 Q 值与高产出仅有很小的关联。
构想值
r
和(
Q
,
N
)之间缺少相关性,使我们可以进行解析计算,寻找最高影响力论文
 会怎样随着产出量的变化而变化。
Q
模型的预测与数据十分吻合,表明隐藏的
Q
因子和产出量
N
的个体差异,可以解释我们从实验中观察到的科学家之间影响力的不同,从而修正了
R
模型的缺陷(见图6-1)。
会怎样随着产出量的变化而变化。
Q
模型的预测与数据十分吻合,表明隐藏的
Q
因子和产出量
N
的个体差异,可以解释我们从实验中观察到的科学家之间影响力的不同,从而修正了
R
模型的缺陷(见图6-1)。
利用除运气之外的其他参数来描述科学家职业生涯的影响力,这种做法是有根据的。不难想象,科学家个体之间有差别,因此我们需要将其考虑在内,以便对真正的职业生涯有一个准确的描述。但奇怪的是,除了运气,我们似乎仅需要增加一个参数。单独引入 Q 因子一项,就足以解释为何科学家的影响力各不相同。
Q 模型究竟在哪一点上弥补了 R 模型的不足呢? R 模型的失败告诉我们,一个人职业生涯中的成功靠的不仅仅是运气。 Q 因子准确地指出了职业生涯的一个关键特征:优秀的科学家在所有的科研项目上都很优秀。每位科学家可能都有一篇使他们声名鹊起的重要论文,但那篇论文的出现并不是靠运气。一位卓越科学家的第二篇最佳或第三篇最佳乃至许多篇论文,通常都是引用量较高的论文。这也意味着,一位能够始终发表杰出论文的科学家,总有某些与众不同的特点。而 Q 所体现的正是这种特点。换句话说,虽然运气很重要,但仅凭它并不能带来长远发展。 Q 因子体现了如何将运气转化为具有持续高影响力的职业生涯。
Q 模型不仅有助于逐个分析高影响力职业生涯的各个关联因素,还使我们能够根据论文发表序列计算出每位科学家的 Q 因子。 Q 的精确表达式涉及一定程度的数学推导,但当某位科学家发表足够数量的论文以后,我们可以通过一个简单的公式大概估算出他的 Q [116] 。假定有这样一位科学家 i ,他发表的论文 j 在10年中总共获得了 c 10, ij 的引用量。对每一篇论文的引用量 c 10, ij 取对数,然后再对所有论文引用量的对数取平均数。 Q i 即是该平均数的指数值:

其中, μ p 是归一化因子,取决于所有科学家职业生涯中的产出。考虑到 Q 依赖于 c 10, ij 对数的平均值,因此它不会受到某个具有高(或低)影响力的成果的支配,而是反映某位科学家长期系统性地将研究项目转化为高(或低)影响力论文的能力。为了更好地理解 Q ,来看一个例子(见图6-2)。
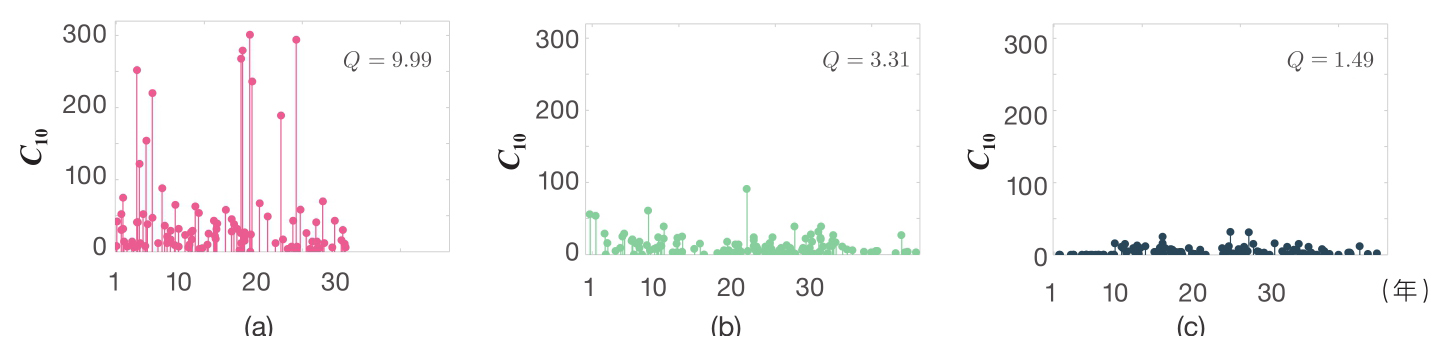
图6-2 具有不同
Q
因子的职业生涯
图6-2显示了论文产出量类似(
N
≈100)的3位科学家的职业发展。由于
Q
因子不同,他们发表的论文呈现出显著的差别。
图6-2中的3位科学家具有相似的产出量,他们都发表了大约100篇论文( N ≈100),但是他们职业生涯的影响力却明显不同。利用公式6-2,我们能够计算出他们每一位的 Q 因子,得到的结果分别是9.99、3.31和1.49。 Q 因子反映了科学家论文序列中的影响力的持续性差异: Q 为9.99的科学家一篇接一篇地产出具有高影响力的论文。而 Q 为1.49的研究人员获得的影响力一直都很有限。中间的那位如果运气好的话,偶尔会发表一篇稍好的论文,但与左边的那位科学家所获得的成就相比,就相形见绌了(见图6-2)。因此, Q 描述了科学家接手随机项目 r 并将其系统性地转化为高(或低)影响力论文的不同能力。每个项目都可能受运气的影响,但如果多个项目观察下来,科学家真正的 Q 值就会开始浮现出来。
公式6-3有许多优点。首先,我们可以通过它估算某位科学家职业生涯预期的影响力。例如,一位科学家需要发表多少篇论文,才能期望它们当中的某一篇获得某种程度的影响力?根据公式6-3,具有较低 Q 值(比如1.2)的科学家,如果希望某篇论文在10年中能获得30的引用量,则需要写出至少100篇论文,这与图6-2(c)所示内容类似。而同样多产的 Q= 10的科学家,在同样的10年时间内,可期待至少有一篇论文能达到250的引用量。
接下来再来考虑两位科学家的产出都有所增加的情况。不管 Q 值如何,产出的提升都会增加碰上绝妙构想的机会,也就是说,会有一个较高的 r 值。因此,他们的最高影响力论文的影响力就会相应增大。低 Q 值的科学家即便将产出增加1倍,他最好的论文的影响力提升也只是增加了7次引用而已。而同样在这种条件下,高 Q 值的科学家能将引用量增加超过50次。也就是说,对于 Q 值有限的科学家,产出的增加并不能在实质上改善他做出重大突破的机会,因此仅靠更加勤奋是不够的。
Q 因子会随年龄和经验的增加而增加吗?人们可能会想当然地认为,随着职业生涯的发展,科学家会更善于将构想转化为高影响力论文。要检验 Q 值在整个职业生涯中的稳定性,我们使用至少包含50篇论文的职业生涯数据,利用这些科学家职业生涯早期和后期的论文,由公式6-3分别计算出早期和后期的 Q 因子( Q early 和 Q late )。 Q late 与 Q early 是几乎相同的,说明 Q 值并不会在职业生涯中系统性地增加或减少(见图6-3)。换句话说,科学家的 Q 因子在职业生涯中相对稳定。这提出了一个很有诱惑力的问题: Q 因子能够预测科学家职业生涯的影响力吗?
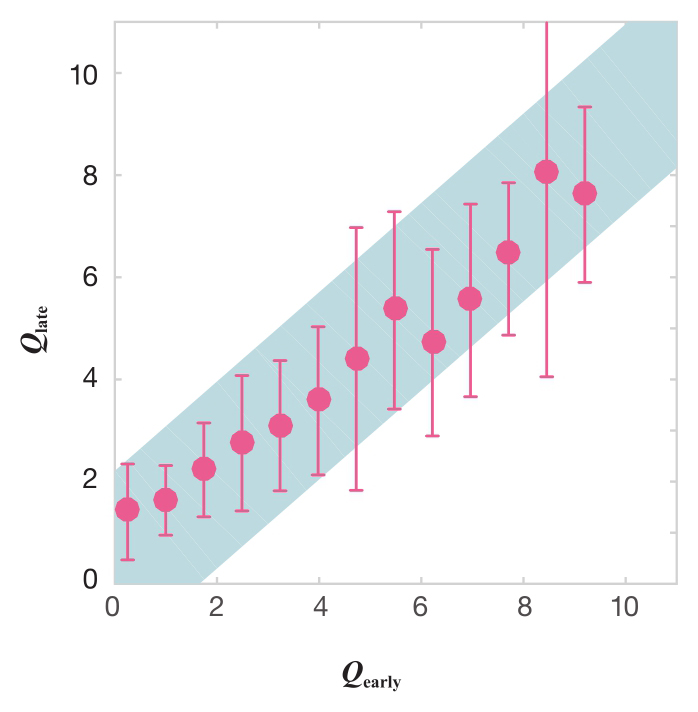
图6-3
Q
因子在职业发展中相对稳定
我们对至少发表50篇论文的823位科学家职业生涯早期(
Q
early
)和后期(
Q
late
)的
Q
因子进行比较,利用个人职业生涯的前一半和后一半论文来分别计算两个
Q
值。我们分别计算出真实数据(圆点)和论文的顺序被打乱的随机职业生涯(灰色阴影区域)所对应的值。对于95.1%的人来说,早期和后期阶段的变化出现在随机职业生涯预测的波动内,表明
Q
因子在整个职业生涯中相对稳定。
为了判断
Q
值在衡量个人整体的科研影响力方面是否更加有效,我们将其与本书讨论过的几个计量指标进行比较。首先,检验几个不同的指标在预测诺贝尔奖得主上的能力
[116]
。为此,我们根据物理学家的产出量
N
、引用总量
C
、最高影响力论文的引用量
 、
h
指数和
Q
值对他们进行排序。为了比较不同序列的表现,我们使用ROC曲线
(17)
测量每个排序中排名靠前的科学家成为诺奖得主的比例。图6-4表明,总体来说,基于累计引用量的指标,如某位科学家最高影响力论文所获得的引用量以及职业生涯的总引用量,都能做出不错的预测。而
h
指数的确比引用量更有效,对赢得诺贝尔奖的预测更加精确。有趣的是,最差的预测指标是产出量,即单位时间内科学家所发表的论文数量。换句话说,仅凭多发表论文不能赢得诺贝尔奖。
、
h
指数和
Q
值对他们进行排序。为了比较不同序列的表现,我们使用ROC曲线
(17)
测量每个排序中排名靠前的科学家成为诺奖得主的比例。图6-4表明,总体来说,基于累计引用量的指标,如某位科学家最高影响力论文所获得的引用量以及职业生涯的总引用量,都能做出不错的预测。而
h
指数的确比引用量更有效,对赢得诺贝尔奖的预测更加精确。有趣的是,最差的预测指标是产出量,即单位时间内科学家所发表的论文数量。换句话说,仅凭多发表论文不能赢得诺贝尔奖。
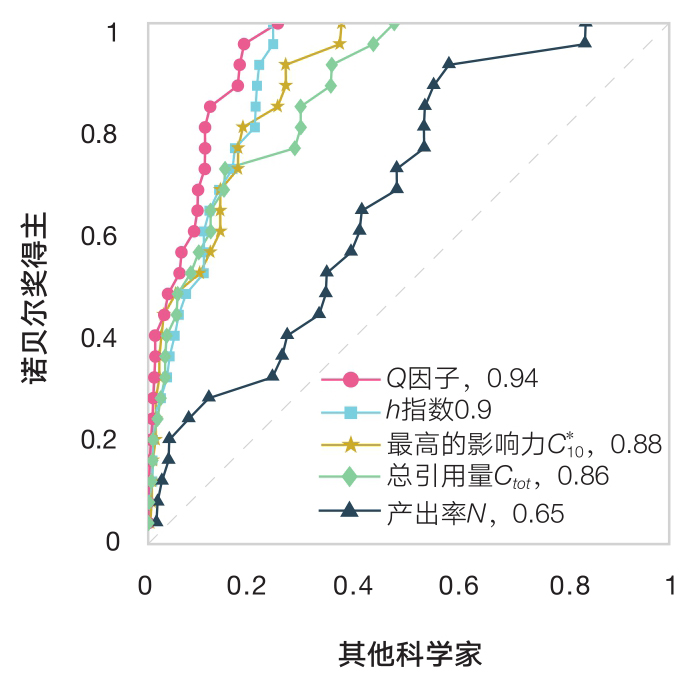
图6-4 预测诺贝尔奖获得者
ROC曲线图显示了根据多种因素对科学家进行的排序,这些因素包括:
Q
、产出量
N
、引用总量
C
、最高影响力论文的引用量
c
*
10
以及
h
指数。每一条曲线代表以某个给定的排名阈值选取科学家,其中包含了诺贝尔奖得主的比例与其他科学家的比例。对角斜线(也叫无识别率线)相当于随机排序;每一曲线下方的面积代表了对诺贝尔奖得主排序的精确性(在图例中给出,1为最大值)
[116]
。
尽管 h 指数以及其他基于引用量的指标有它们各自的优势,但基于职业生涯的 Q 因子则更胜一筹,对诺贝尔奖得主的预测比图6-4中的其他指标都更精确。因此,虽然 h 指数仍然是衡量科学家总体影响力的良好指标,但 Q 因子似乎表现出更好的预测能力。那么, Q 因子具有哪些 h 指数不具备的优点呢?
要理解 Q 因子和 h 指数的差别,可以参考一次实地实验,有关经济学家如何评价同行简历 [125] 。从44所全球排名前10%的研究性大学中随机选出一些教授,然后要求这些教授根据简历中列出的论文发表情况,对简历的所有者进行评价。这些简历包含了两种情况,一种是成果列表中仅列出了在高水平期刊上发表的论文,另一种是既有高水平论文,也有在较低水平的期刊上发表的其他论文。由于经济学领域中各类期刊的声望等级相当稳定,所以非常适合进行这种测试。换句话说,所有的经济学家都明白各个期刊的级别差异。那么,如果某份简历既有一些发表在较低水平期刊上的论文,同时又有一些发表在较高水平期刊上的论文,那么这份简历是否会有更强的说服力呢?如果是这样,会强多少?
此项调查的被试被要求按1~10分对简历打分,其中1分为最差,10分为最优。大体上,仅仅列出了顶级论文的短简历获得的评分为8.1。而长简历(注意,其中包含了与短简历中相同的顶级论文,只是同时又列出了其他较低水平的论文)所获得的平均得分为7.6。这意味着短简历比长简历更受大家喜欢,尽管它们都包含了同样的优秀论文。也就是说,那些来自较低水平刊物的其他论文,不但没有起到任何帮助作用,反而对专家们的评估产生了负面影响。
这些结果既可以理解,又令人困惑。一方面,它佐证了大家长期抱有的猜测:过于频繁地在较低水平的刊物上发表论文可能会带来负面影响。另一方面,如果我们从评估科研成就的计量指标这一角度考虑,这些结果完全说不通。我们讨论的所有指标,从产出量到引用总量,再到 h 指数,都是随论文数量单调递增的。从这个角度看,多发表一篇论文总是有意义的,即使它的影响力有限。首先,它无疑能增加你发表的论文总量。其次,即使论文没有发表在重要刊物上,但随着时间的推移,它的引用量也会累计,从而增加个人的总体影响力,甚至有可能增加 h 指数。最起码,它不会有任何坏处。
但上面这些结果表明,它确实有坏处。如果我们用 Q 因子来解释,那就说得通了。与其他测量方法不同, Q 因子并不是简单地随着论文数量的增长而增长,而是取决于新的论文是否比其他论文的平均水平更好或者更差。也就是说, Q 因子的作用是量化科学家在整个职业生涯中持续产出高影响力论文的能力。它考虑到了所有论文,而不仅是高影响力论文。因此,如果已经有了杰出的论文发表记录,然后又发表了几篇论文,新的论文会提升其他指标,但并不能保证一定能够提高 Q 值。事实上,除非新论文与通常发表的论文水平相当,否则这些新发表的论文反而会降低你的 Q 值。
Q 因子在预测职业生涯影响力方面具有超高的精确性,这说明在职业生涯中,一致性有多么重要。这一结论,连同图6-3反映出的 Q 值的稳定性,给我们描绘出一种有些单调的职业图景:我们的职业生涯都是从一个特定的 Q 开始,无论它是高还是低。 Q 因子控制着我们发表的每一篇论文的影响力,而且一直伴随我们直到退休。但这是真的吗?我们能够打破这种机器人似的单调吗?换句话说,我们的职业生涯中有过游刃有余的时期吗?