
下载掌阅APP,畅读海量书库
立即打开



Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。目前市场上主流的流式计算框架有Apache Storm、Spark Streaming、Apache Flink等,但能够同时支持低延迟、高吞吐、Exactly-Once(收到的消息仅处理一次)的框架只有Apache Flink。
Flink是原生的流处理系统,但也提供了批处理API,拥有基于流式计算引擎处理批量数据的计算能力,真正实现了批流统一。与Spark批处理不同的是,Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
Flink在2015年9月发布了第一个稳定版本0.9,编写本书时已经发布到了1.13,随着国内社区的不断推动,越来越多的公司开始选择使用Flink作为实时数据处理技术。
Flink的主要优势如下。
1.同时支持高吞吐、低延迟
Flink是目前开源社区中唯一同时支持高吞吐、低延迟的分布式流式数据处理框架,在每秒处理数百万条事件的同时能够保持毫秒级延迟。而同类框架Spark Streaming在流式计算中无法做到低延迟保障。Apache Storm可以做到低延迟,但无法满足高吞吐的要求。同时满足高吞吐、低延迟对流式数据处理框架是非常重要的,可以大大提高数据处理的性能。
2.支持有状态计算
所谓状态,就是在流式计算过程中将算子(Flink提供了丰富的用于数据处理的函数,这些函数称为算子)的中间结果(需要持续聚合计算,依赖后续的数据记录)保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果,以便计算当前的结果(当前结果的计算可能依赖于之前的中间结果),从而无须每次都基于全部的原始数据来统计结果,极大地提升了系统性能。
每一个具有一定复杂度的流处理应用都是有状态的,任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理,如图1-3所示。
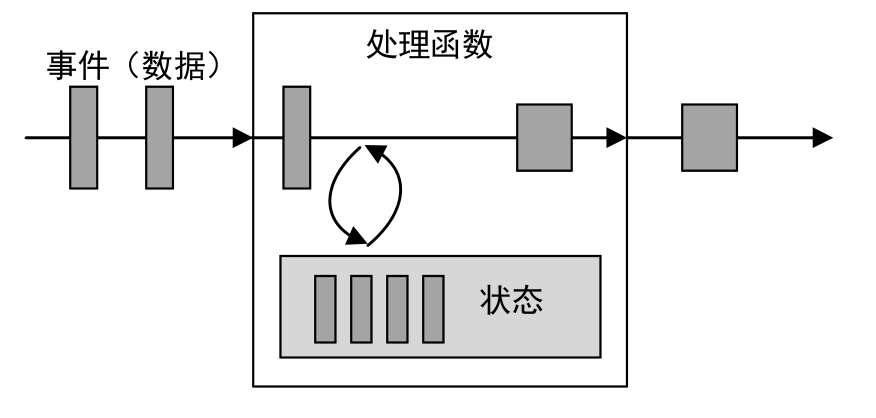
图1-3 状态计算过程
Flink是一个针对数据流进行有状态计算的框架,其提供了许多状态管理相关的特性,为多种不同的数据结构提供了相对应的状态基础类型。
3.支持事件时间
时间是流处理框架的一个重要组成部分。目前大多数框架计算采用的都是系统处理时间(Process Time),也就是事件传输到计算框架处理时,系统主机的当前时间。Flink除了支持处理时间外,还支持事件时间(Event Time),根据事件本身自带的时间戳(事件的产生时间)进行结果的计算,例如窗口聚合、会话计算、模式检测和基于时间的聚合等。这种基于事件驱动的机制使得事件即使乱序到达,Flink也能够计算出精确的结果,保证了结果的准确性和一致性。
4.支持高可用性配置
Flink可以与YARN、HDFS、ZooKeeper等紧密集成,配置高可用,从而可以实现快速故障恢复、动态扩容、7×24小时运行流式应用等作业。Flink可以将任务执行的快照保存在存储介质上,当需要停机运维等操作时,下次启动可以直接从事先保存的快照恢复原有的计算状态,使得任务继续按照停机之前的状态运行。此外,Flink还支持在不丢失应用状态的前提下更新作业的程序代码,或进行跨集群的作业迁移。
5.提供了不同层级的API
Flink为流处理和批处理提供了不同层级的API,每一种API在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景,不同层级的API降低了系统耦合度,也为用户构建Flink应用程序提供了丰富且友好的接口。