
下载掌阅APP,畅读海量书库
立即打开



Flink可以在Linux、macOS和Windows上运行。前提条件是集群各节点提前安装JDK 8以上版本,并配置好SSH免密登录,因为集群各节点之间需要相互通信,Flink主节点需要对其他节点进行远程管理和监控。
从Flink官网下载页面(https://flink.apache.org/downloads.html)下载二进制安装文件,并选择对应的Scala版本,此处选择Apache Flink 1.13.0 for Scala 2.11(Flink版本为1.13.0,使用的Scala版本为2.11)。
由于当前版本的Flink不包含Hadoop相关依赖库,如果需要结合Hadoop(例如读取HDFS中的数据),还需要下载预先捆绑的Hadoop JAR包,并将其放置在Flink安装目录的lib目录中。此处选择Pre-bundled Hadoop 2.8.3(适用于Hadoop 2.8.3),如图3-1所示。
图3-1 下载预先捆绑的Hadoop JAR包
接下来使用3个节点(主机名分别为centos01、centos02、centos03)讲解Flink各种运行模式的搭建。3个节点的主机名与IP的对应关系如表3-1所示。
表3-1 3个节点的主机名与IP的对应关系

本节讲解在CentOS 7操作系统中搭建Flink本地模式。
1.上传解压安装包
将下载的Flink安装包flink-1.13.0-bin-scala_2.11.tgz上传到centos01节点的/opt/softwares目录,然后进入该目录,执行以下命令将其解压到目录/opt/modules中。
$ tar -zxvf flink-1.13.0-bin-scala_2.11.tgz -C /opt/modules/
2.启动Flink
进入Flink安装目录,执行以下命令启动Flink:
$ bin/start-cluster.sh
启动时的输出日志如图3-2所示。

图3-2 Flink本地模式启动日志
启动后,使用jps命令查看Flink的JVM进程,命令如下:
$ jps
13309 StandaloneSessionClusterEntrypoint
13599 TaskManagerRunner
若出现上述进程,则代表启动成功。StandaloneSessionClusterEntrypoint为Flink主进程,即JobManager;TaskManagerRunner为Flink从进程,即TaskManager。
也可以通过检查Flink安装目录下的log目录中的日志文件来验证系统是否正在运行,命令如下:
$ tail log/flink-*-standalonesession-*.log
部分输出日志如下:

从上述日志可以看出,系统已正常运行。
3.查看WebUI
在浏览器中访问服务器8081端口即可查看Flink的WebUI,此处访问地址http://192.168.170.133:8081/,如图3-3所示。
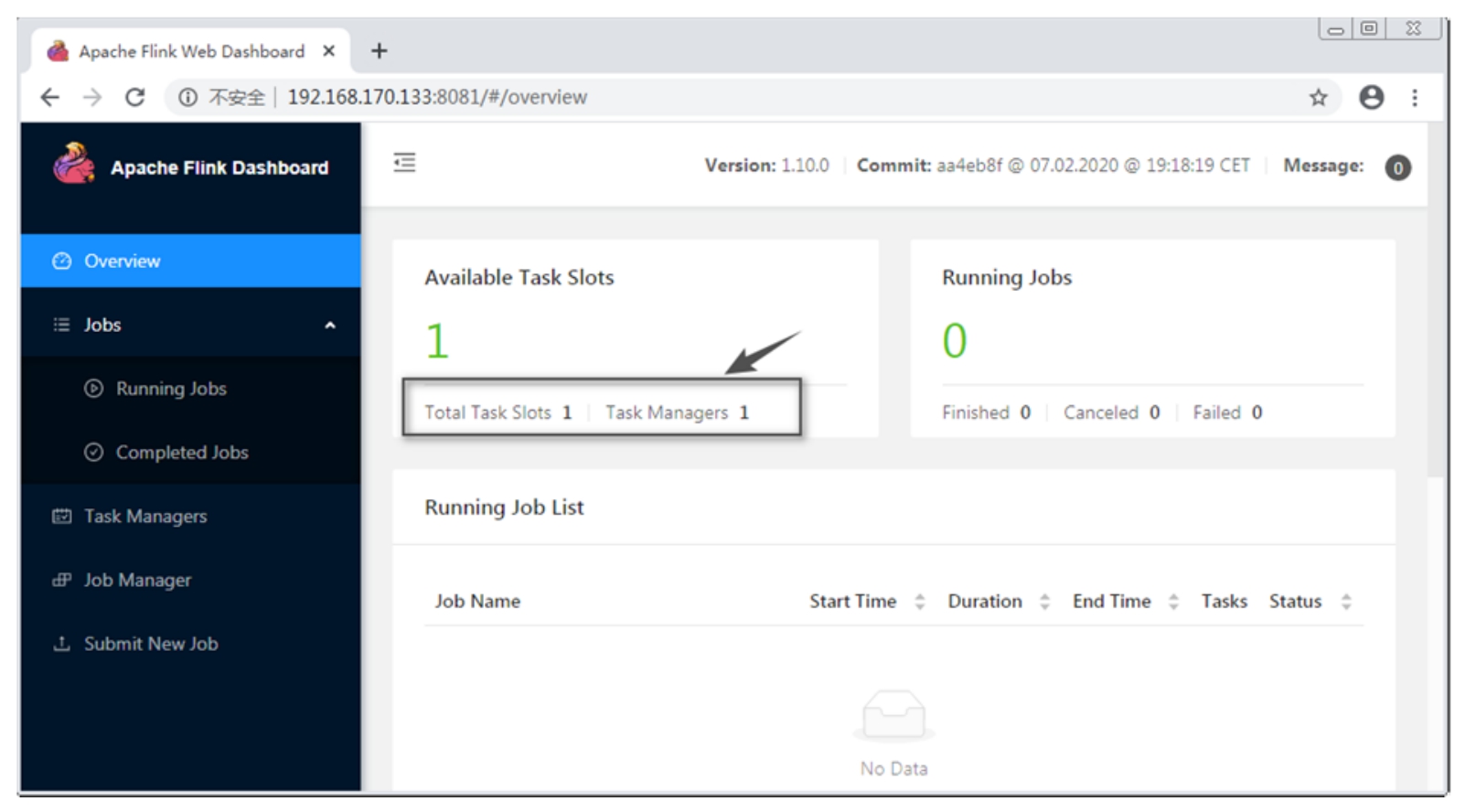
图3-3 Flink WebUI界面
从WebUI中可以看出,当前本地模式的Task Slot数量和TaskManager数量都为1(Task Slot数量默认为1)。
如果想停止Flink,执行bin/stop-cluster.sh命令即可;如果想通过主机名访问Flink WebUI(例如http://centos01:8081/),需要提前在Windows的hosts文件中配置好主机名和IP的映射关系。
Flink Standalone模式的搭建需要在集群的每个节点都安装Flink,集群角色分配如表3-2所示。
表3-2 Flink集群角色分配

集群搭建的操作步骤如下。
1.上传解压安装包
将下载的Flink安装包flink-1.13.0-bin-scala_2.11.tgz上传到centos01节点的/opt/softwares目录,然后进入该目录,执行以下命令将其解压到目录/opt/modules中。
$ tar -zxvf flink-1.13.0-bin-scala_2.11.tgz -C /opt/modules/
2.修改配置文件
Flink的配置文件都存放于安装目录下的conf目录,进入该目录,执行以下操作。
(1)修改flink-conf.yaml文件
$ vim conf/flink-conf.yaml
将文件中jobmanager.rpc.address属性的值改为centos01,命令如下:
jobmanager.rpc.address: centos01
上述配置表示指定集群主节点(JobManager)的主机名(或IP),此处为centos01。
flink-conf.yaml文件中的其他几个重要参数解析如下:
· jobmanager.rpc.port :JobManager的RPC访问端口,默认为6123。
· jobmanager.heap.size :JobManager JVM的堆内存大小,默认1024MB。可根据集群配置适当增加。
· taskmanager.heap.size :TaskManager JVM的堆内存大小,默认1024MB。可根据集群配置适当调整。
· taskmanager.numberOfTaskSlots :每个TaskManager提供的Task Slot数量(默认为1),Task Slot数量代表TaskManager的最大并行度,生产环境中建议将Task Slot的数量设置为节点CPU的核心数,以最大化利用资源。一个Task Slot可以运行整个作业管道。
· parallelism.default :系统级别的默认并行度(默认为1)。也可以在应用程序或提交命令时指定并行度。设置合适的并行度可以提高运行效率,但是不能超过集群CPU核心总数。
(2)修改workers文件
workers文件必须包含所有需要启动的TaskManager节点的主机名,且每个主机名占一行。
执行以下命令修改workers文件:
$ vim conf/workers
改为以下内容:
centos02
centos03
上述配置表示将centos02和centos03节点设置为集群的从节点(TaskManager节点)。
3.复制Flink安装文件到其他节点
在centos01节点中进入/opt/modules/目录执行以下命令,将Flink安装文件复制到其他节点:
$ scp -r flink-1.13.0/ centos02:/opt/modules/
$ scp -r flink-1.13.0/ centos03:/opt/modules/
4.启动Flink集群
在centos01节点上进入Flink安装目录,执行以下命令启动Flink集群:
$ bin/start-cluster.sh
集群启动时的输出日志如图3-4所示。
图3-4 Flink集群的启动日志
启动完毕后,分别在各节点执行jps命令,查看启动的Java进程。若各节点存在以下进程,则说明集群启动成功。
centos01节点:StandaloneSessionClusterEntrypoint
centos02节点:TaskManagerRunner
centos03节点:TaskManagerRunner
尽管在配置文件flink-conf.yaml中配置了集群JobManager节点为centos01,但实际上当前执行启动命令的节点即为JobManager节点,会产生JobManager进程。本例中,如果在centos02节点上执行start-cluster.sh命令启动Flink集群,则centos02节点为JobManager节点。同理,停止Flink集群时,需要在JobManager所在节点执行相关命令。
5.查看WebUI
集群启动后,在浏览器中访问JobManager节点的8081端口即可查看Flink的WebUI,此处访问地址http://192.168.170.133:8081/,如图3-5所示。
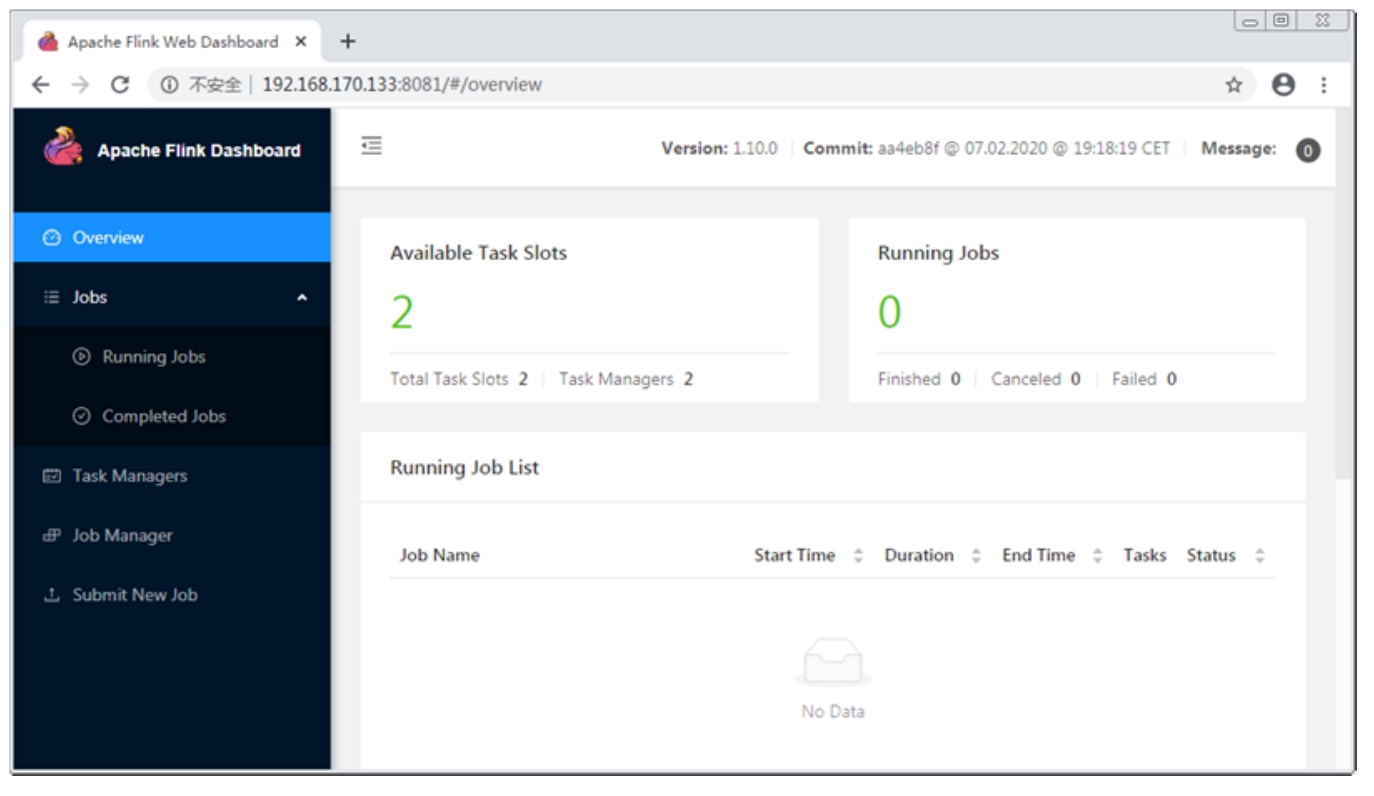
图3-5 Flink集群WebUI界面
从WebUI中可以看出,当前集群总的Task Slot数量(每个节点的Task Slot数量默认为1)和TaskManager数量都为2。
6.其他命令
停止Flink集群可以执行以下命令:
$ bin/stop-cluster.sh
如果集群中的JobManager进程意外停止了,可使用以下命令对其单独启动:
$ bin/jobmanager.sh start
同理,手动停止JobManager进程的命令如下:
$ bin/jobmanager.sh stop
如果集群中的TaskManager进程意外停止了,或需要向正在运行的集群中增加新的TaskManager节点,可使用以下命令对TaskManager进程单独启动:
$ bin/taskmanager.sh start
同理,手动停止TaskManager进程的命令如下:
$ bin/taskmanager.sh stop
Flink On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Flink即可,该节点可作为提交Flink应用程序到YARN集群的客户端。
若要在YARN上运行Flink应用,则需要注意以下几点:
1)Hadoop版本应在2.2以上。
2)必须事先确保环境变量文件中配置了HADOOP_CONF_DIR、YARN_CONF_DIR或者HADOOP_HOME,Flink客户端会通过该环境变量读取YARN和HDFS的配置信息,以便正确加载Hadoop配置以访问YARN,否则将启动失败。
3)需要下载预先捆绑的Hadoop JAR包,并将其放置在Flink安装目录的lib目录中,本例使用flink-shaded-hadoop-2-uber-2.8.3-10.0.jar。具体下载方式见3.1节的Flink集群搭建。
4)需要提前将HDFS和YARN集群启动。
本例使用的Hadoop集群各节点的角色分配如表3-3所示。
表3-3 Hadoop集群角色分配
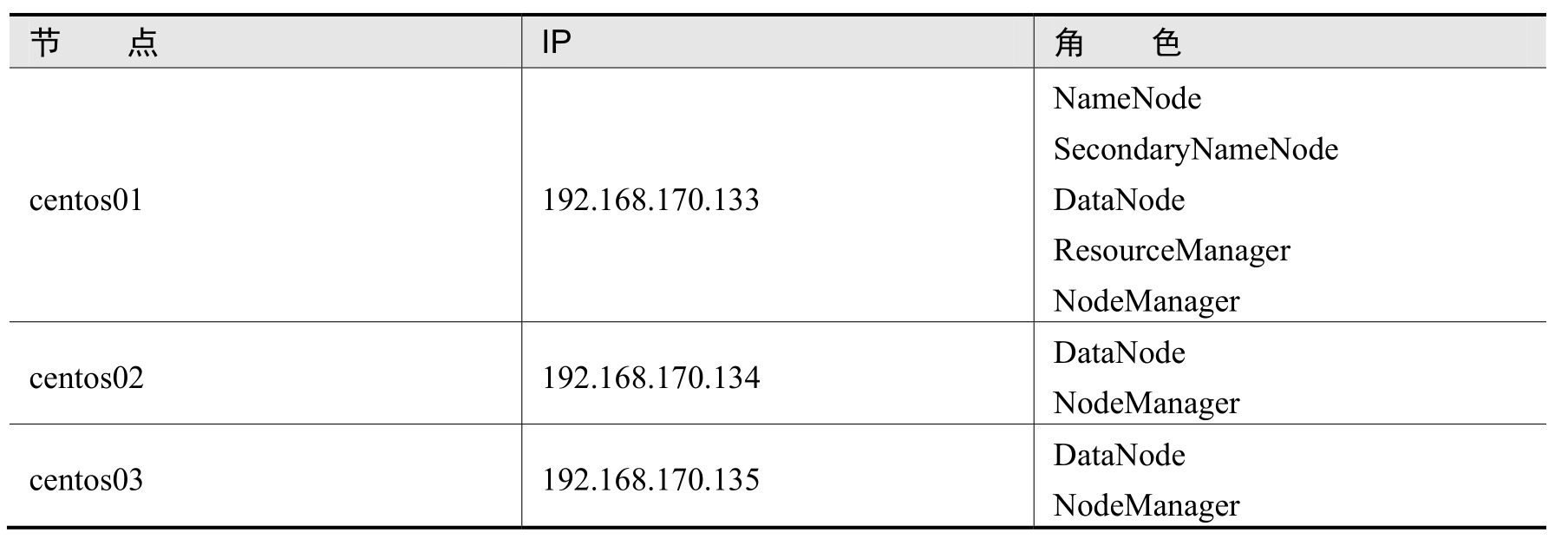
表3-3中的角色指的是Hadoop集群各节点所启动的守护进程,其中的NameNode、DataNode和SecondaryNameNode是HDFS集群所启动的进程,ResourceManager和NodeManager是YARN集群所启动的进程。
在Flink On YARN模式中,根据作业的运行方式不同,又分为两种模式:Flink YARN Session模式和Flink Single Job(独立作业)模式。
Flink YARN Session模式需要先在YARN中启动一个长时间运行的Flink集群,也称为Flink YARN Session集群,该集群会常驻在YARN集群中,除非手动停止。客户端向Flink YARN Session集群中提交作业时,相当于连接到一个预先存在的、长期运行的Flink集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和JobManager)仍将继续运行直到手动停止。该模式下,Flink会向YARN一次性申请足够多的资源,资源永久保持不变,如果资源被占满,则下一个作业无法提交,只能等其中一个作业执行完成后释放资源,如图3-6所示。
拥有一个预先存在的集群可以节省大量时间申请资源和启动TaskManager。作业可以使用现有资源快速执行计算是非常重要的。
Flink Single Job模式不需要提前启动Flink YARN Session集群,直接在YARN上提交Flink作业即可。每一个作业会根据自身情况向YARN申请资源,不会影响其他作业运行,除非整个YARN集群已无任何资源。并且每个作业都有自己的JobManager和TaskManager,相当于为每个作业提供了一个集群环境,当作业结束后,对应的组件也会同时释放。该模式不会额外占用资源,使资源利用率达到最大,在生产环境中推荐使用这种模式,如图3-7所示。
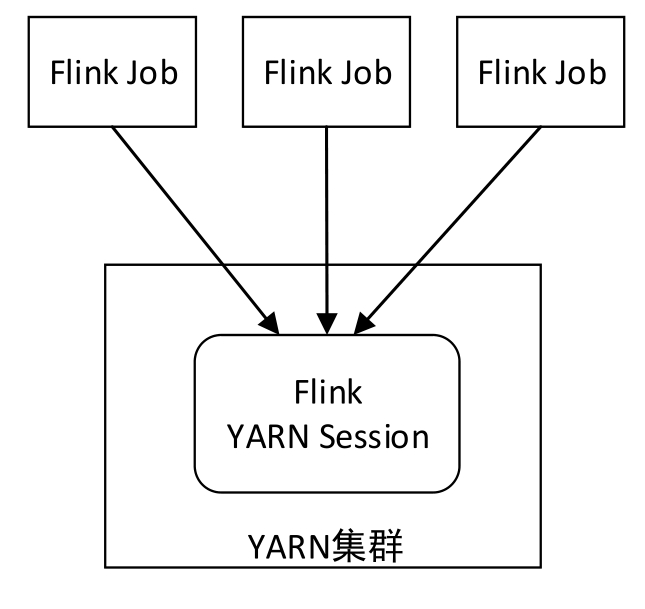
图3-6 Flink YARN Session模式
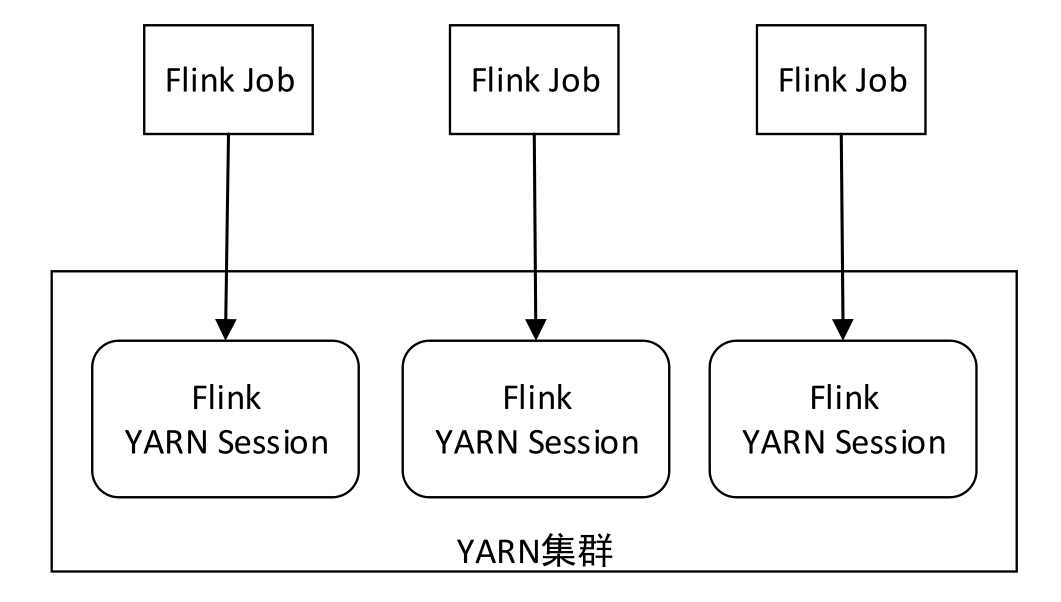
图3-7 Flink Single Job模式
Flink Single Job模式适合长期运行、具有高稳定性要求且对较长的启动时间不敏感的大型作业。
1.Flink YARN Session模式操作
(1)启动Flink YARN Session集群
在启动HDFS和YARN集群后,在YARN集群主节点(此处为centos01节点)安装好Flink,进入Flink主目录执行以下命令,即可启动Flink YARN Session集群:
$ bin/yarn-session.sh -jm 1024 -tm 2048
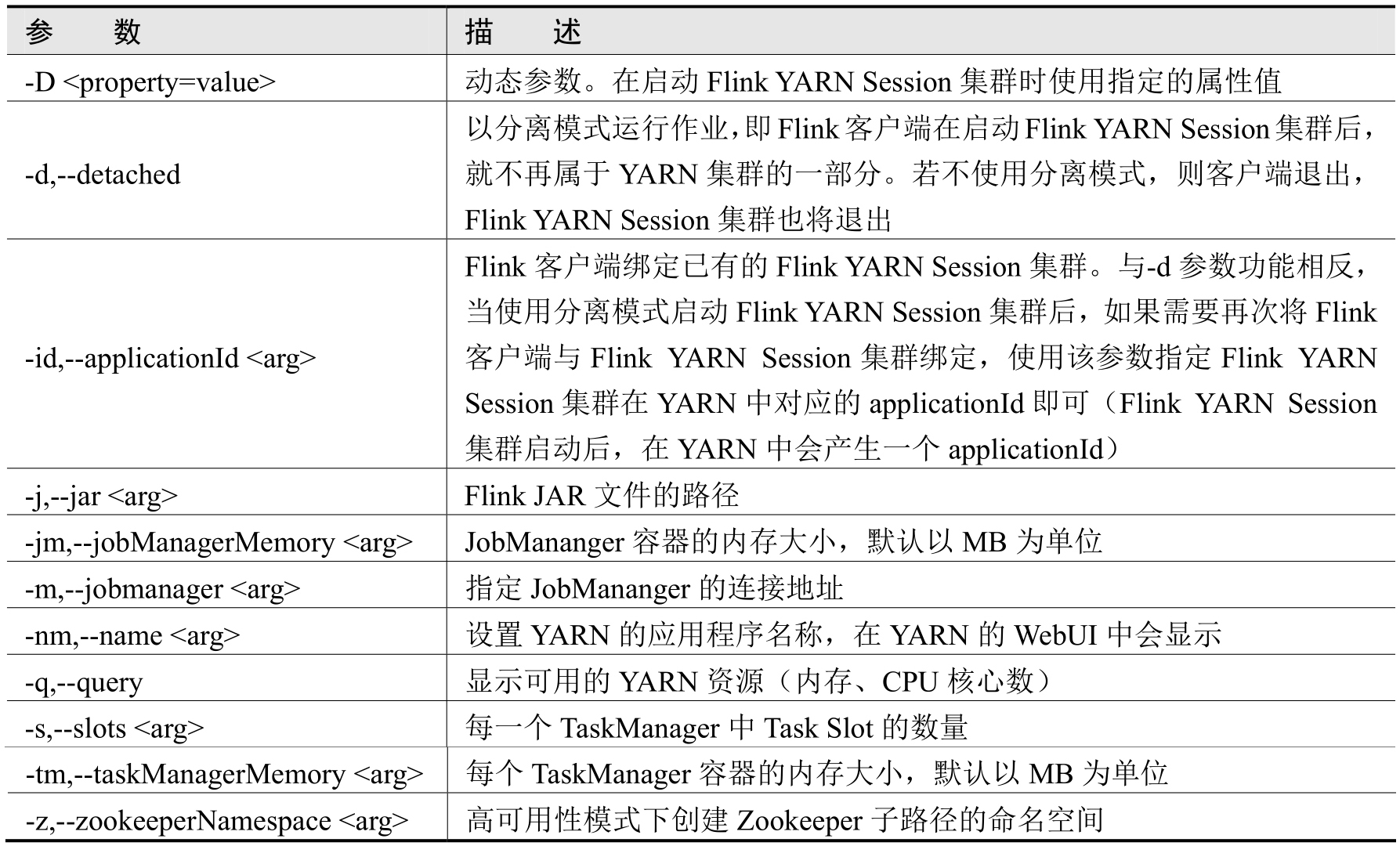
上述命令中的参数-jm表示指定JobManager容器的内存大小(单位为MB),参数-tm表示指定TaskManager容器的内存大小(单位为MB)。除此之外,还可以使用其他参数,如表3-4所示。
表3-4 yarn-session.sh的常用参数介绍
若启动过程中报如图3-8所示的错误,则原因是在Flink安装目录的lib目录中缺少预先捆绑的Hadoop JAR包,需要将相应JAR包放到该目录中。
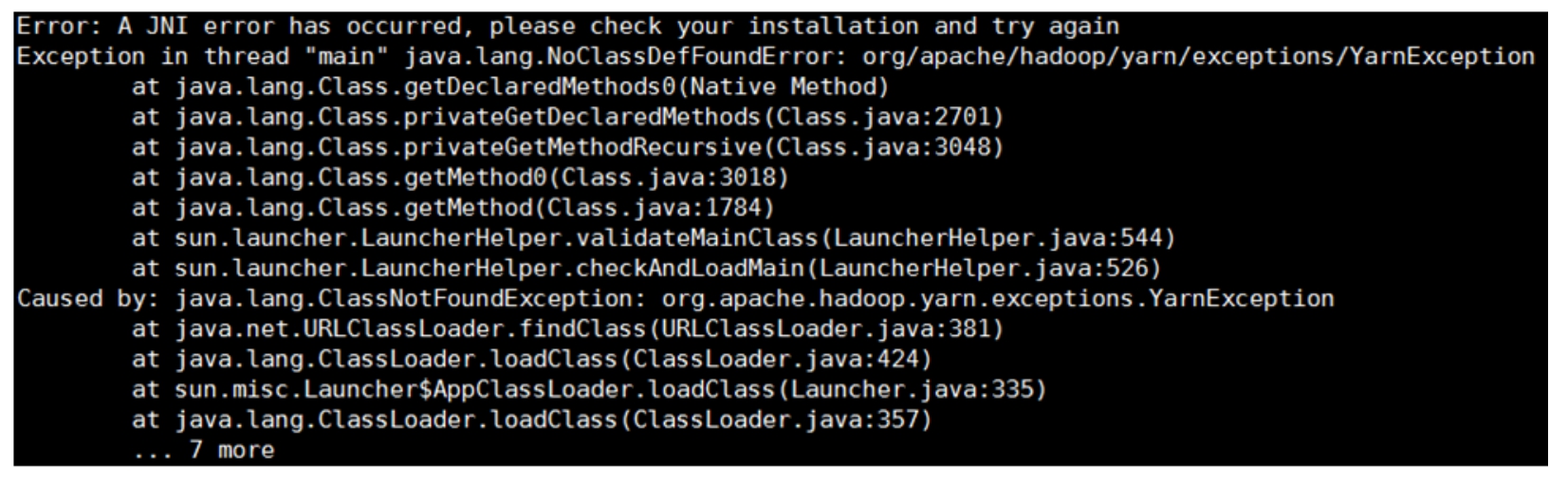
图3-8 Flink YARN Session集群启动错误信息
若启动过程中报如图3-9所示的错误,则原因是YARN Container试图使用过多的内存,但NodeManager内存不足,从而把Container杀掉了。

图3-9 Flink YARN Session集群启动错误信息
解决方法是在执行bin/yarn-session.sh命令时使用相应参数指定合适的内存(小量),但如果指定的内存太小,仍然会报错。可以修改Hadoop各个节点的配置文件yarn-site.xml,在其中添加以下内容:

上述配置属性解析如下:
· yarn.nodemanager.pmem-check-enabled :是否开启物理内存检查,默认为true。若开启,则NodeManager会启动一个线程检查每个Container中的Task任务使用的物理内存量,如果超出分配值,则直接将其杀掉。
· yarn.nodemanager.vmem-check-enabled :是否开启虚拟内存检查,默认为true。若开启,则NodeManager会启动一个线程检查每个Container中的Task任务使用的虚拟内存量,如果超出分配值,则直接将其杀掉。
需要注意的是,yarn-site.xml文件修改完毕后,记得将该文件同步到集群其他节点。
同步完毕后,重启YARN集群,然后使用bin/yarn-session.sh命令启动Flink YARN Session集群。启动完毕后,会在启动节点(此处为centos01节点)产生一个名为FlinkYarnSessionCli的进程,该进程是Flink客户端进程;在其中一个NodeManager节点产生一个名为YarnSessionClusterEntrypoint的进程,该进程是Flink JobManager进程。而Flink TaskManager进程不会启动,在后续向集群提交作业时才会启动。例如,启动完毕后查看centos01节点的进程可能如下:

Flink YARN Session集群可以启动多个,每一个都对应一个Flink JobManager进程。
此时可以在浏览器访问YARN ResourceManager节点的8088端口,此处地址为http://192.168.170.133:8088/,在YARN的WebUI中可以查看当前Flink应用程序(Flink YARN Session集群)的运行状态,如图3-10所示。

图3-10 YARN WebUI显示应用程序运行状态
从图3-10可以看出,一个Flink YARN Session集群实际上就是一个长时间在YARN中运行的应用程序(Application),后面的Flink作业也会提交到该应用程序中。
单击图3-10中的ApplicationMaster超链接即可进入Flink YARN Session集群的WebUI,如图3-11所示。
(2)提交Flink作业
接下来向Flink YARN Session集群提交Flink自带的单词计数程序。
首先在HDFS中准备/input/word.txt文件,内容如下:
hello hadoop
hello java
hello scala
java
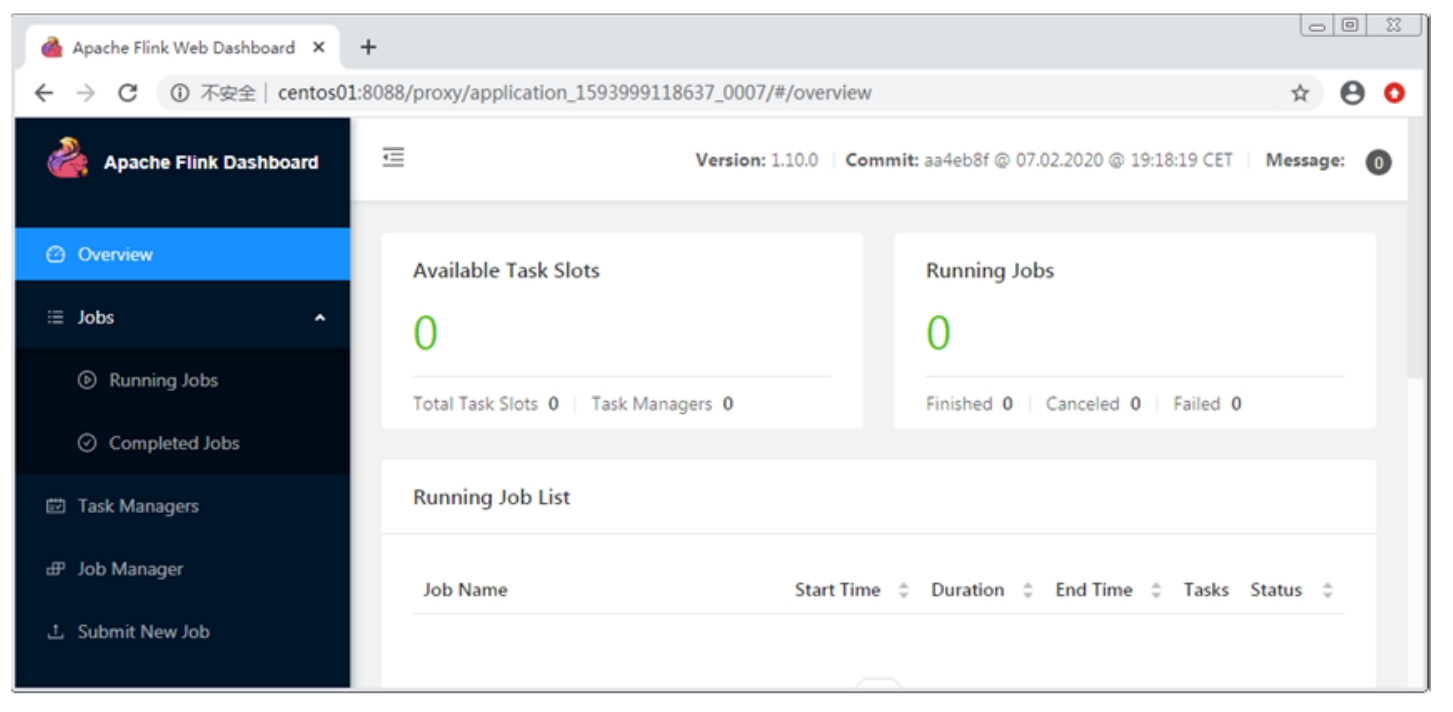
图3-11 Flink YARN Session集群的WebUI
然后在Flink客户端(centos01节点)中执行以下命令,提交单词计数程序到Flink YARN Session集群:
$ bin/flink run ./examples/batch/WordCount.jar \
-input hdfs://centos01:9000/input/word.txt \
-output hdfs://centos01:9000/result.txt
上述命令通过参数-input指定输入数据目录,-output指定输出数据目录。
在执行过程中,查看Flink YARN Session集群的WebUI,如图3-12所示。
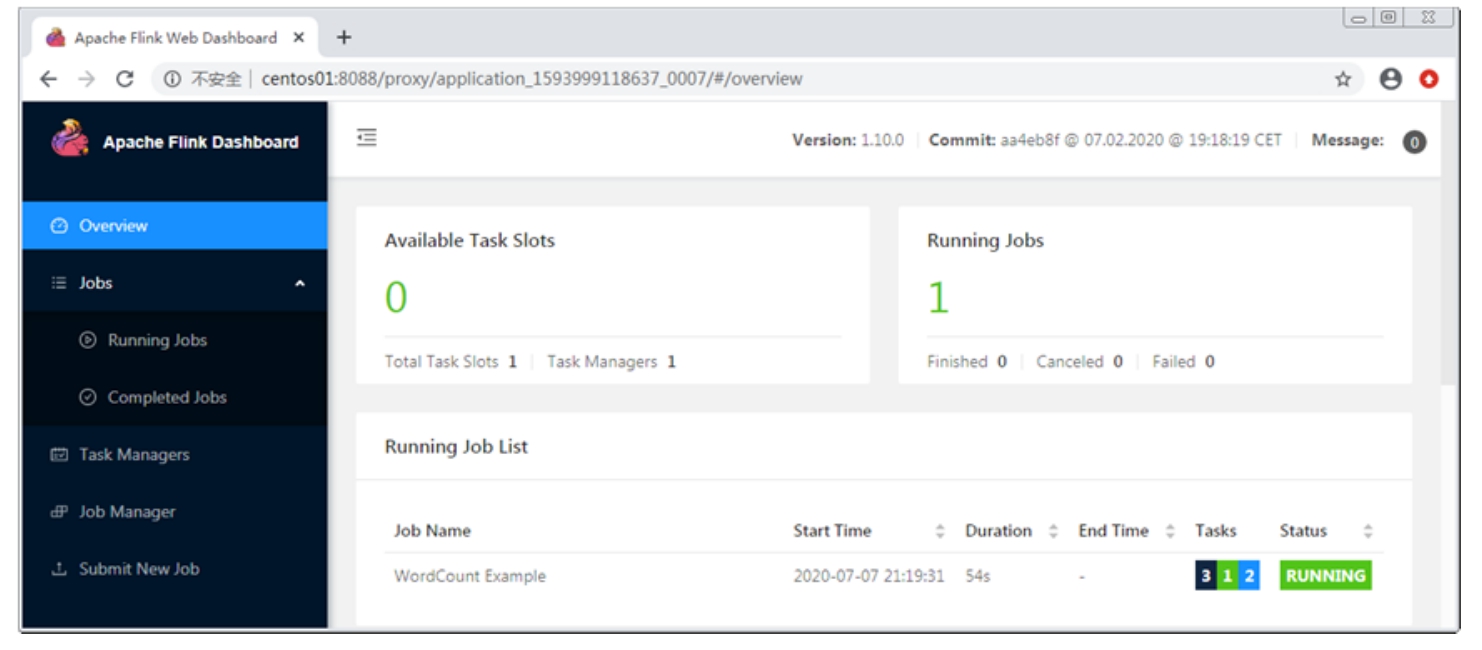
图3-12 Flink YARN Session集群的WebUI
从图3-12中可以看出,当前正在运行的作业数量为1,总Task Slot数量为1,TaskManager数量为1(默认每个TaskManager中的Task Slot数量为1)。此时在某个NodeManager节点上可以看到多了一个名为YarnTaskExecutorRunner的进程,该进程正是Flink TaskManager进程。这更加验证了Flink TaskManager在作业提交后任务执行时才会启动。
当作业执行完毕后,查看HDFS/result.txt文件中的结果,如图3-13所示。
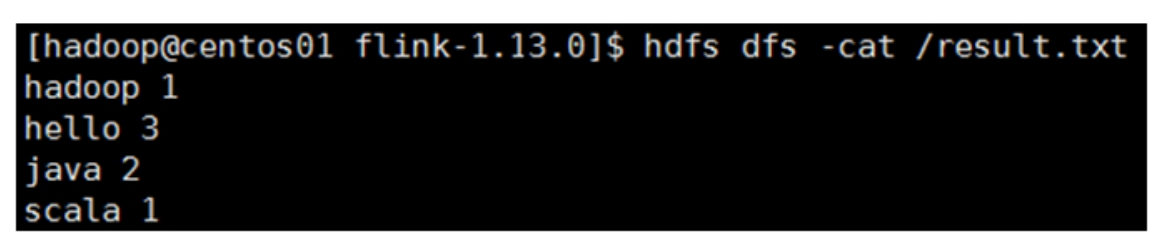
图3-13 查看单词计数的执行结果
说明向Flink YARN Session集群中提交Flink自带的单词计数程序执行成功。
此时再次查看Flink YARN Session集群的WebUI,如图3-14所示。
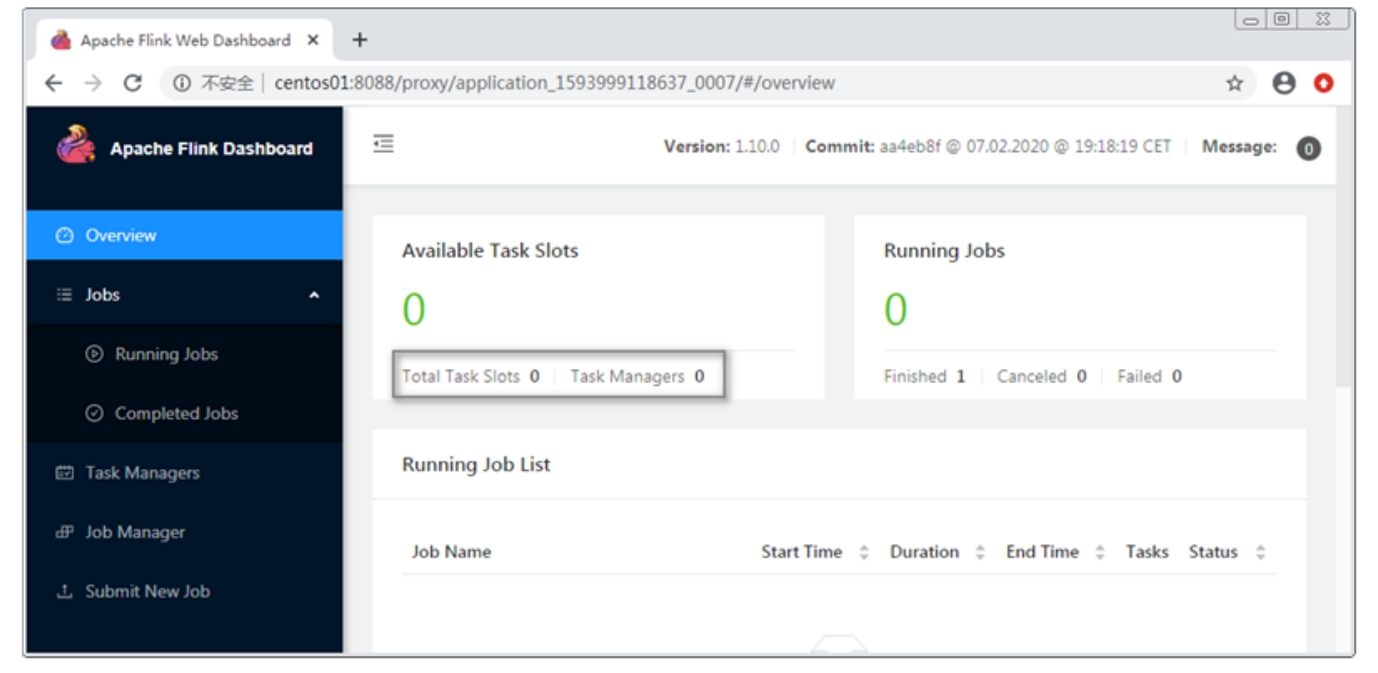
图3-14 Flink YARN Session集群的WebUI
发现总Task Slot数量和TaskManager数量都变为0,这说明在Flink作业执行完毕后,TaskManager将退出,以释放资源。
接下来单击WebUI中如图3-15所示的作业名称WordCount Example,可以查看单词计数作业的执行数据流图。

图3-15 已经执行完成的作业列表
执行数据流图如图3-16所示。
通过上面的操作可以发现一个问题,Flink YARN Session集群启动后,Flink客户端一直处于监听状态。若退出客户端连接,则Flink JobManager进程(YarnSessionClusterEntrypoint)和Flink客户端进程(FlinkYarnSessionCli)也将退出,Flink YARN Session集群将终止。
(3)分离模式
如果希望将启动的Flink YARN Session集群在后台独立运行,与Flink客户端进程脱离关系,可以在启动时添加-d或--detached参数,表示以分离模式运行作业,即Flink客户端在启动Flink YARN Session集群后,就不再属于YARN集群的一部分。例如以下代码:
$ bin/yarn-session.sh -jm 1024 -tm 2048 -d
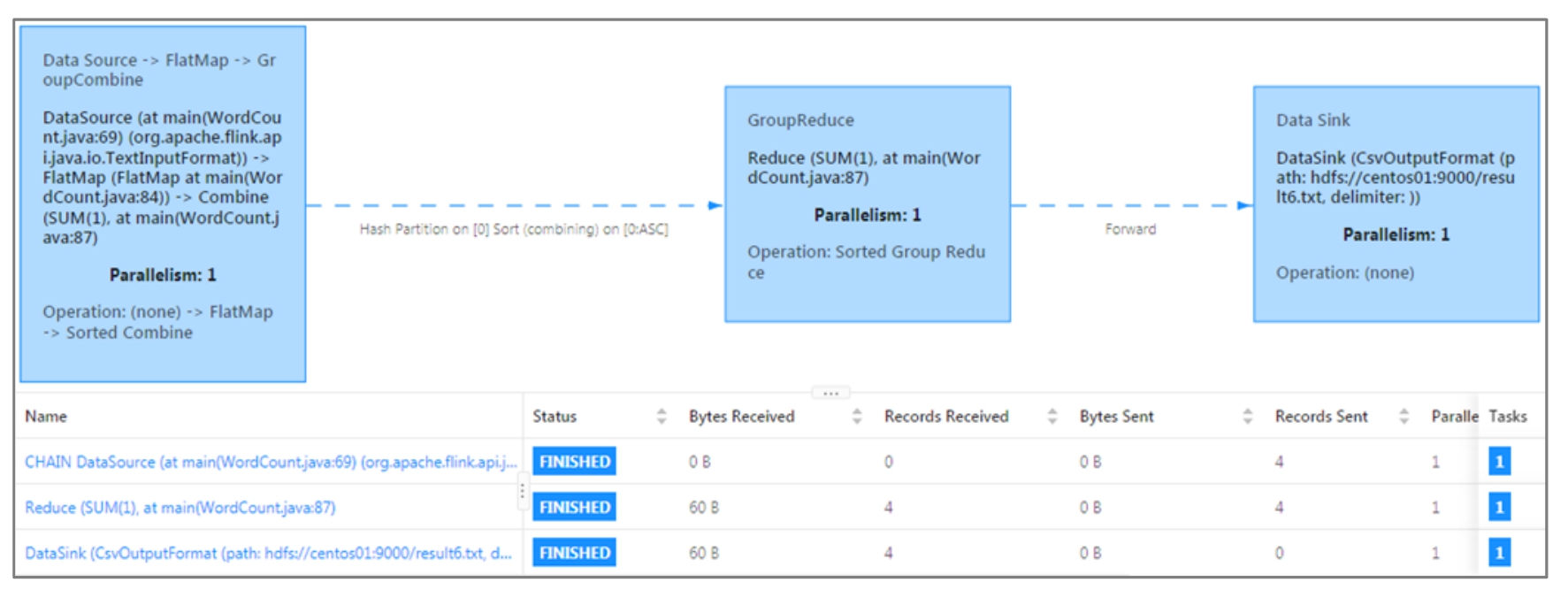
图3-16 单词计数作业的执行数据流图
在以上述方式启动Flink YARN Session集群后,若要停止集群,则需要使用YARN的操作命令将YARN中Flink YARN Session集群对应的应用程序杀掉(前面提到过,一个Flink YARN Session集群实际上就是一个长时间在YARN中运行的应用程序),命令格式如下:
$ yarn application -kill [applicationId]
例如,Flink YARN Session集群对应的applicationId为application_1593999118637_0009(Flink YARN Session集群启动后,在YARN中会产生一个applicationId),则停止Flink YARN Session集群的命令如下:
$ yarn application -kill application_1593999118637_0009
(4)进程绑定
与分离模式相反,当使用分离模式启动Flink YARN Session集群后,如果需要再次将Flink客户端与Flink YARN Session集群绑定,则使用-id或--applicationId参数指定Flink YARN Session集群在YARN中对应的applicationId即可,命令格式如下:
$ bin/yarn-session.sh –id [applicationId]
例如,将Flink客户端(执行绑定命令的本地客户端)与applicationId为application_1593999118637_0009的Flink YARN Session集群绑定,命令如下:
$ bin/yarn-session.sh -id application_1593999118637_0009
执行上述命令后,在Flink客户端会产生一个名为FlinkYarnSessionCli的客户端进程。此时就可以在Flink客户端对Flink YARN Session集群进行操作,包括执行停止命令等。例如执行Ctrl+C命令或输入stop命令即可停止Flink YARN Session集群。
一个Flink YARN Session集群可以绑定多个Flink客户端,每个Flink客户端都可以对Flink YARN Session集群进行操作。例如,在centos01节点和centos02节点都安装Flink,则在这两个节点上都可以执行绑定命令。
2.Flink Single Job模式操作
Flink Single Job模式可以将单个作业直接提交到YARN中,每次提交的Flink作业都是一个独立的YARN应用程序,应用程序运行完毕后释放资源,这种模式适合批处理应用。
例如,在Flink客户端(centos01节点)中执行以下命令,以Flink Single Job模式提交单词计数程序到YARN集群:
$ bin/flink run -m yarn-cluster examples/batch/WordCount.jar \
-input hdfs://centos01:9000/input/word.txt \
-output hdfs://centos01:9000/result.txt
上述命令通过参数-m指定使用YARN集群(即以Flink Single Job模式提交),-input指定输入数据目录,-output指定输出数据目录。
提交完毕后,可以在浏览器访问YARN ResourceManager节点的8088端口,此处地址为http://192.168.170.133:8088/,在YARN的WebUI中可以查看当前Flink应用程序的运行状态,如图3-17所示。

图3-17 YARN WebUI显示应用程序运行状态
与Flink YARN Session模式一样,单击ApplicationMaster超链接即可进入Flink集群的WebUI。但不同的是,在Flink Single Job模式下,若Flink应用程序在YARN中的运行状态为FINISHED(已完成),则无法查看Flink集群的WebUI,因为此时Flink集群已经退出。
使用yarn-session.sh命令启动Flink YARN Session集群时,需要在YARN的ResourceManager所在节点执行,否则可能产生找不到ResourceManager的错误。同理,向YARN中提交Flink作业时,无论是Flink YARN Session模式还是Flink Single Job模式,都需要在YARN的ResourceManager所在节点执行。