
下载掌阅APP,畅读海量书库
立即打开



Flink应用程序的开发IDE主要有Eclipse和IntelliJ IDEA,由于IntelliJ IDEA对Scala语言的支持更好,因此建议读者使用IntelliJ IDEA进行开发。
本节讲解在IntelliJ IDEA中新建Maven管理的Flink项目,并在该项目中使用Scala语言编写Flink的批处理WordCount程序和流处理WordCount程序。
使用Scala语言进行开发首先要在IDEA中安装Scala插件,操作步骤如下。
1.下载安装IDEA
访问IDEA官网(https://www.jetbrains.com/idea/download),选择开源免费的Windows版进行下载,如图1-17所示。
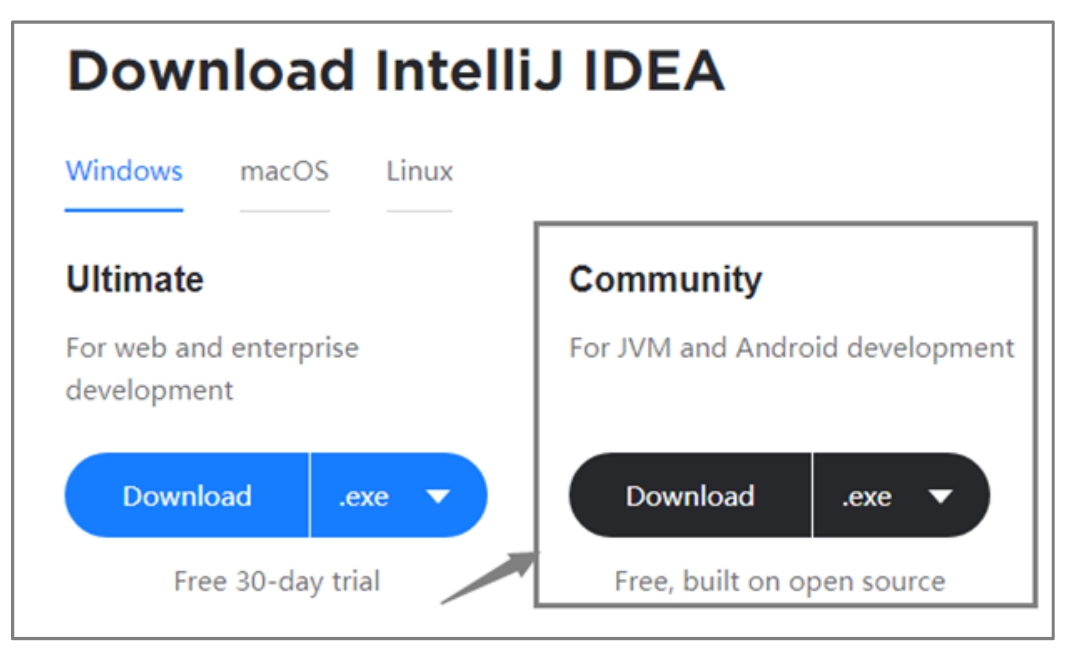
图1-17 IDEA下载主界面
下载完成后,双击下载的安装文件,安装过程与一般Windows软件安装过程相同,根据提示安装到指定的路径即可。
2.安装Scala插件
Scala插件的安装有两种方式:在线和离线。此处讲解在线安装方式。
启动IDEA,在欢迎界面中选择Configure→Plugins命令,如图1-18所示。
在弹出的窗口中单击下方的Install JetBrains plugin...按钮,如图1-19所示。

图1-18 IDEA欢迎界面
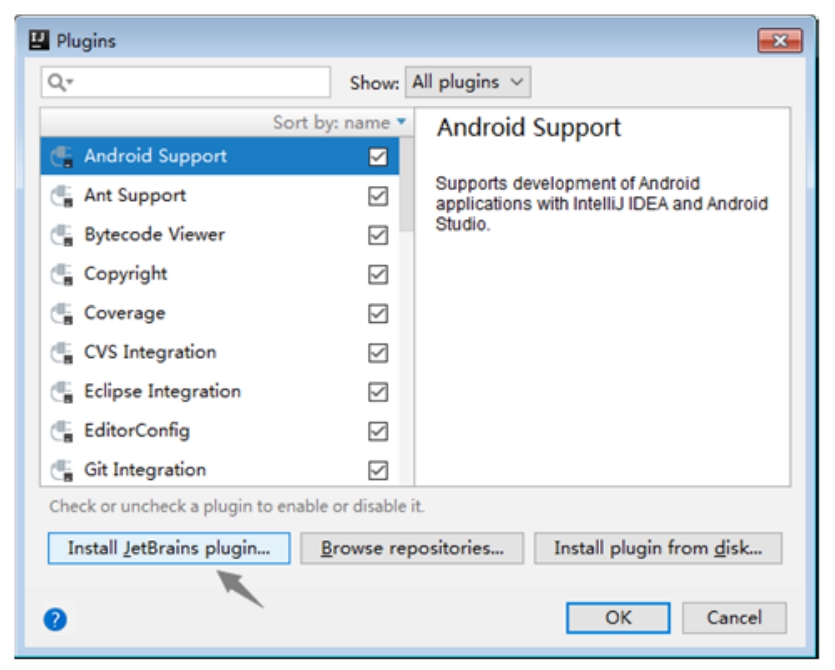
图1-19 IDEA插件选择窗口
在弹出窗口的左侧选择Scala插件(或者在上方的搜索框中搜索“Scala”关键字,然后选择搜索结果中的Scala插件),然后单击窗口右侧的Install按钮进行安装,如图1-20所示。
安装成功后,重启IDEA使其生效。
3.配置IDEA使用的默认JDK
启动IDEA后,选择欢迎界面下方的Configure→Project Defaults→Project Structure命令,如图1-21所示。
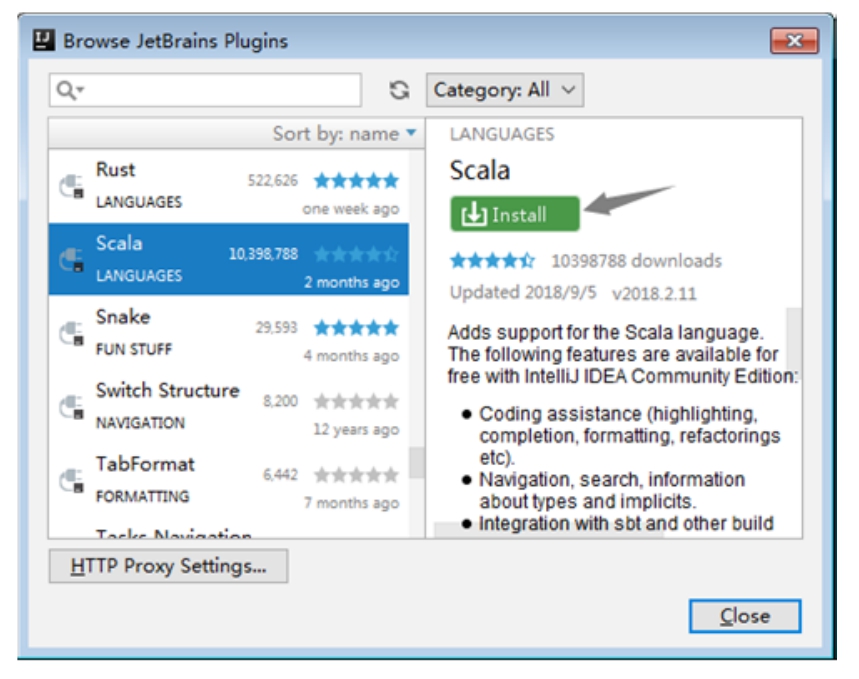
图1-20 选择Scala插件并安装
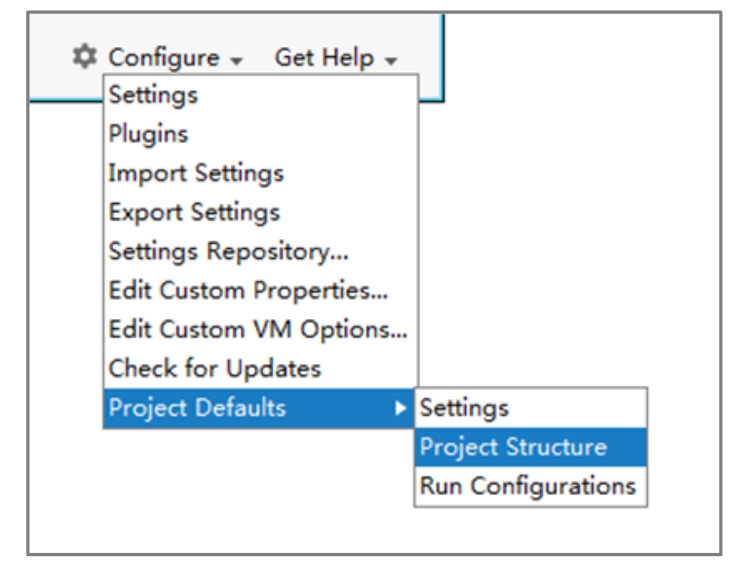
图1-21 配置项目默认环境
在弹出的窗口中选择左侧的Project项,然后单击窗口右侧的New...按钮,选择JDK项,设置项目使用的默认JDK,如图1-22所示。
在弹出的窗口中选择本地JDK的安装主目录,此处选择JDK1.8版本,如图1-23所示。
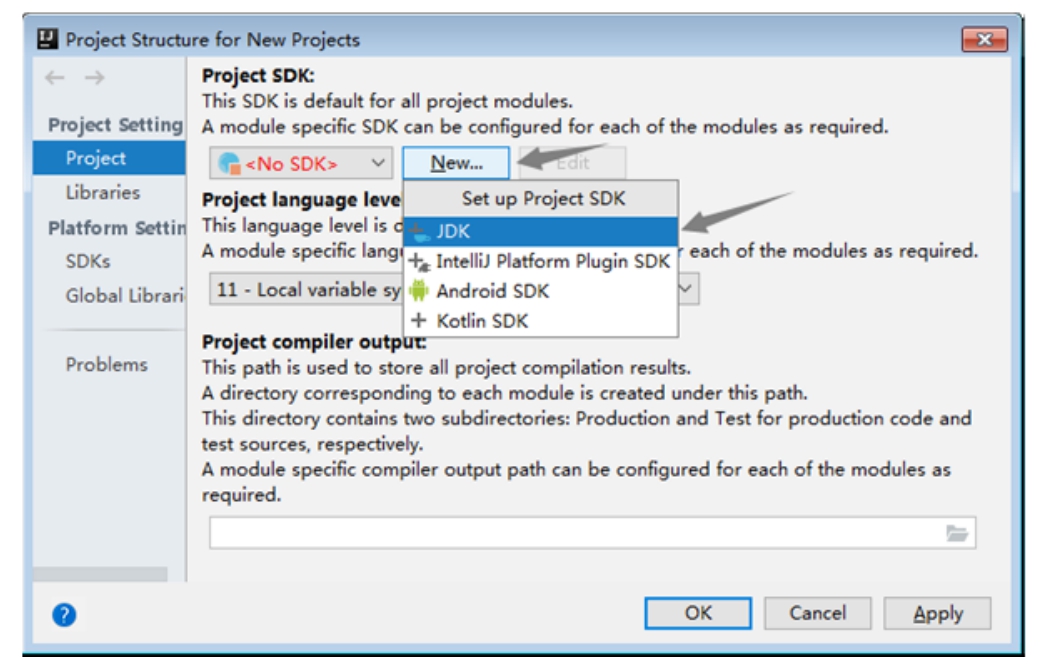
图1-22 设置项目默认JDK
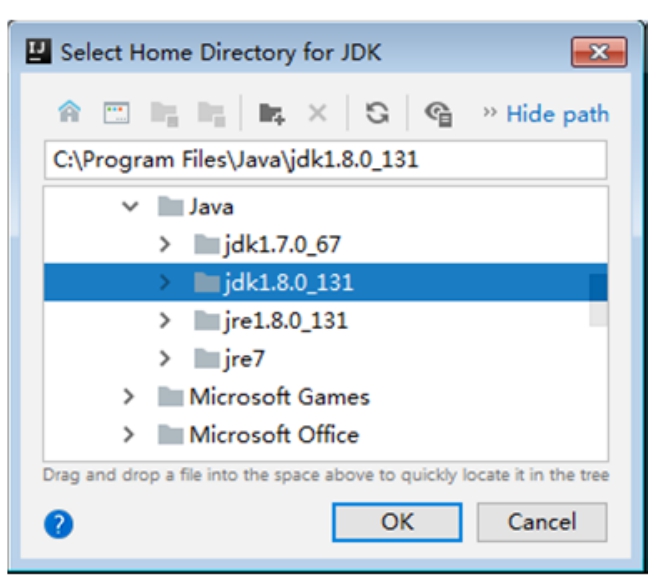
图1-23 选择JDK安装主目录
然后连续单击OK按钮返回欢迎界面。
至此,IDEA中的Scala插件安装完成。接下来就可以在IDEA中创建Flink项目了。
在IDEA中选择File→new→Project...,在弹出的窗口中选择左侧的Maven项,然后在右侧勾选Create from archetype并选择下方出现的scala-archetype-simple项(表示使用scala-archetype-simple模板构建Maven项目)。注意上方的Project SDK应为默认的JDK1.8,若不存在,则需要单击右侧的New...按钮关联JDK。最后单击Next按钮,如图1-24所示。
在弹出的窗口中填写GroupId与ArtifactId,Version保持默认即可。然后单击Next按钮,如图1-25所示。
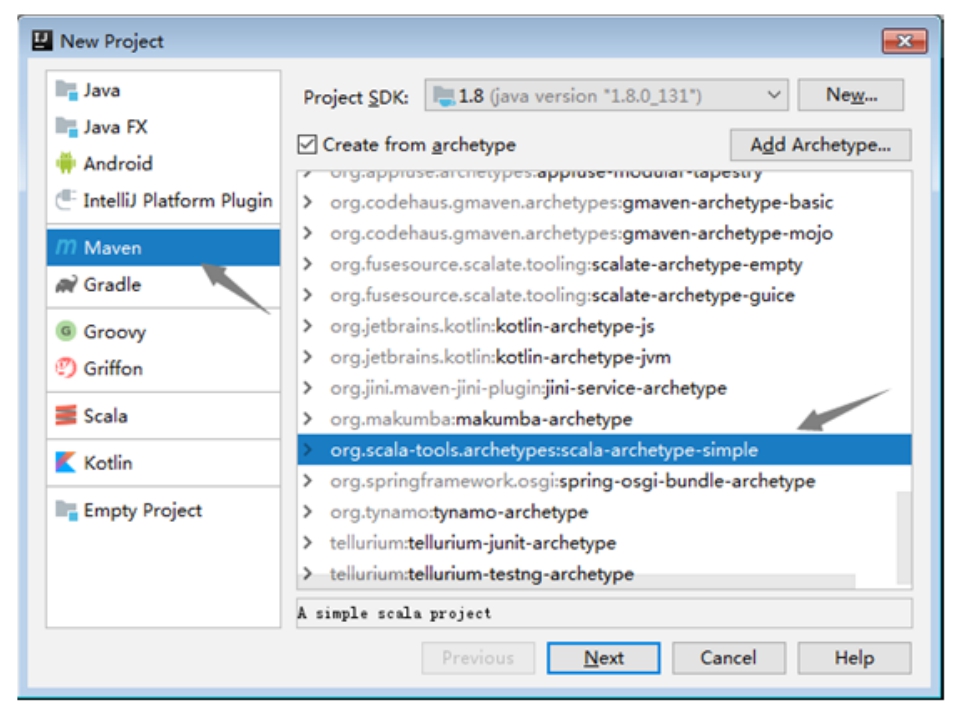
图1-24 选择Maven项目
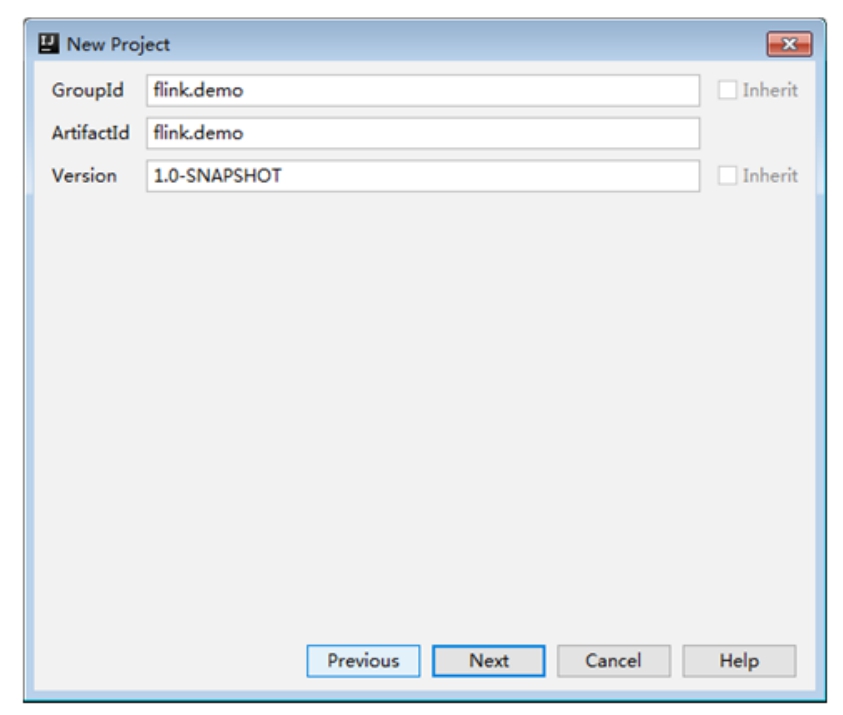
图1-25 填写GroupId与ArtifactId
在弹出的窗口中从本地系统选择Maven安装的主目录的路径、Maven的配置文件settings.xml的路径以及Maven仓库的路径。然后单击Next按钮,如图1-26所示。
在弹出的窗口中填写项目名称FlinkWordCount,然后单击Finish按钮,如图1-27所示。
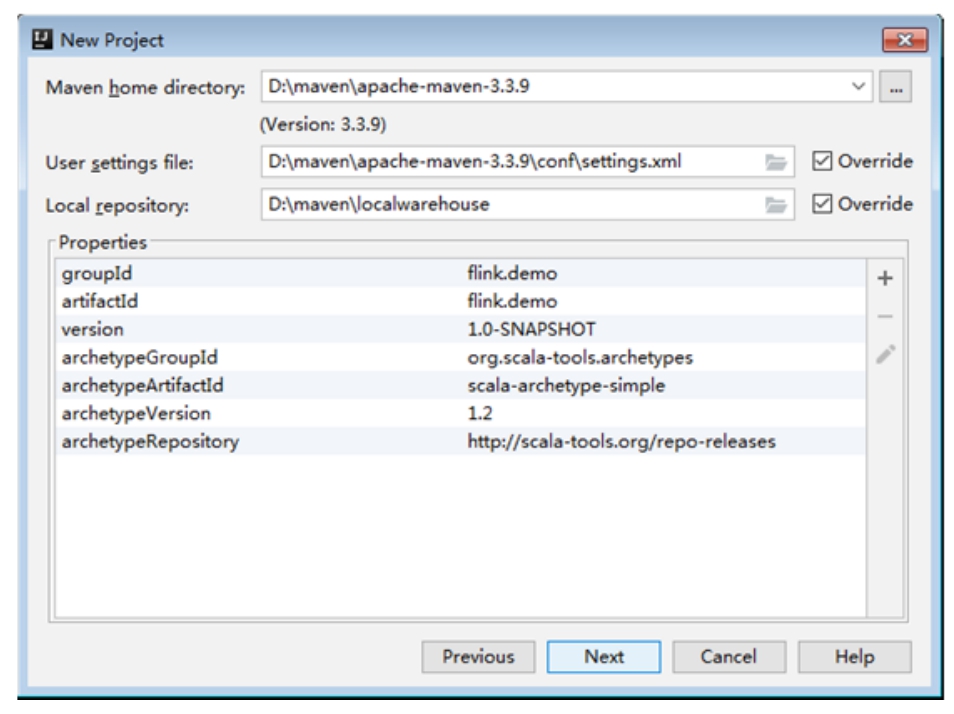
图1-26 选择Maven主目录、配置文件以及仓库的路径
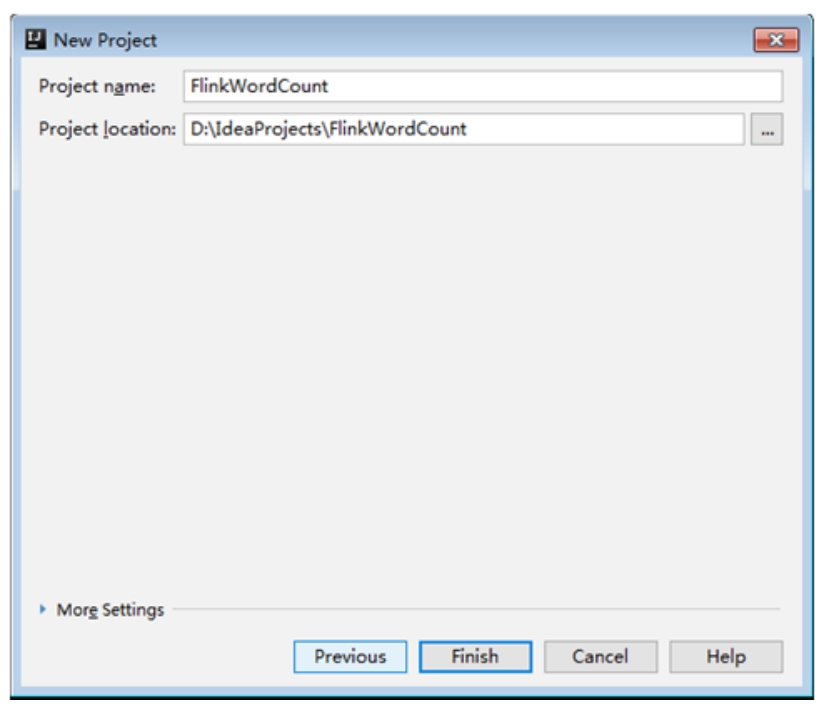
图1-27 填写项目名称
接下来在生成的Maven项目中的pom.xml中添加以下内容,引入Scala和Flink的依赖库。若该文件中默认引用了Scala库,则将其修改为需要使用的版本(本例使用的Scala版本为2.11)。

需要注意的是,Flink依赖库flink-scala_2.11和flink-streaming-scala_2.11中的2.11代表使用的Scala版本,必须与引入的Scala库的版本一致。
至此,基于Maven管理的Flink项目就搭建完成了。项目默认结构如图1-28所示。
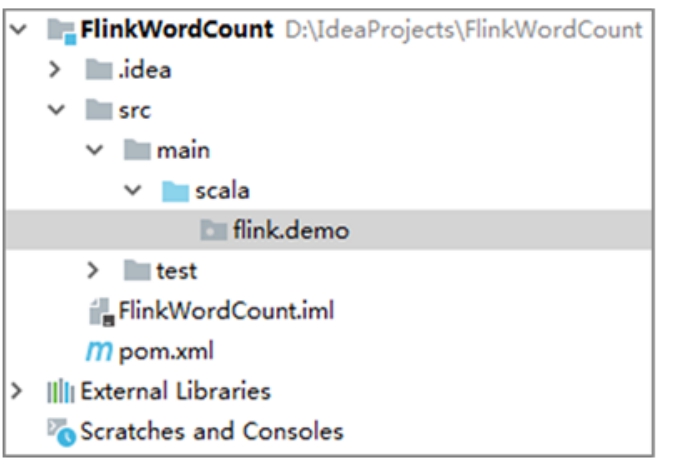
图1-28 基于Maven管理的Flink项目
单词计数(WordCount)是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce,而使用Flink提供的操作算子可以更加轻松地实现单词计数。
在项目的flink.demo包中新建一个WordCount.scala类,然后向其写入批处理单词计数的程序,程序编写步骤如下。
首先创建一个执行环境对象ExecutionEnvironment,然后使用该对象提供的readTextFile()方法读取外部单词数据,同时将数据转为DataSet数据集,代码如下:
val env=ExecutionEnvironment.getExecutionEnvironment
val inputDataSet: DataSet[String] = env.readTextFile("D:\\zwy\\words.txt")
本地文件D:\\zwy\\words.txt中存储了单词数据,数据内容如下:
hello hadoop
hello java
hello scala
java
数据转换流程如图1-29所示。
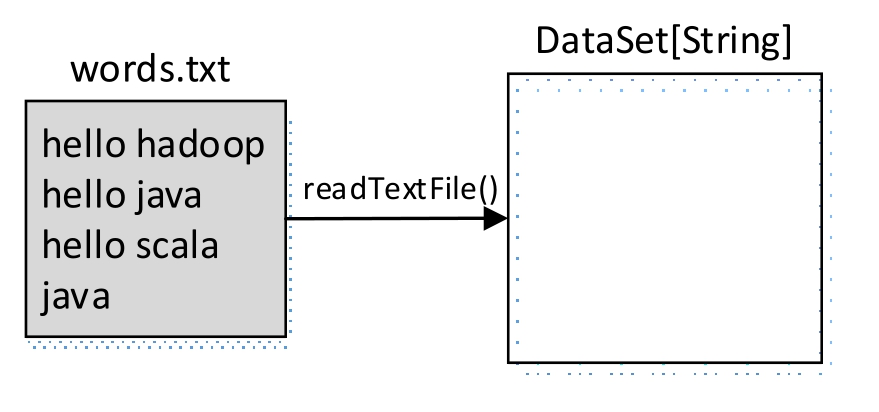
图1-29 读取的单词数据为DataSet数据集
接下来对读取的数据集应用flatMap()转换操作(也称转换算子),将单词按照空格进行分割并合并为一个新的DataSet数据集,代码如下:
val wordDataSet: DataSet[String] = inputDataSet.flatMap(_.split(" "))
数据转换流程如图1-30所示。
接下来对wordDataSet数据集应用map()转换操作,将每一个单词转换成(单词,1)格式的元组,并产生一个新的DataSet数据集,代码如下:
val tupleDataSet: DataSet[(String, Int)] = wordDataSet.map((_,1))
数据转换流程如图1-31所示。
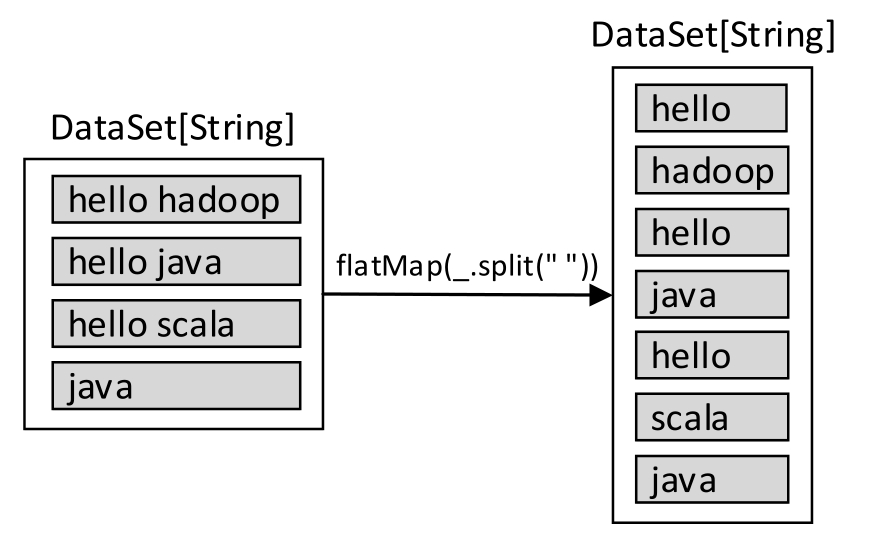
图1-30 对数据集应用flatMap()转换操作
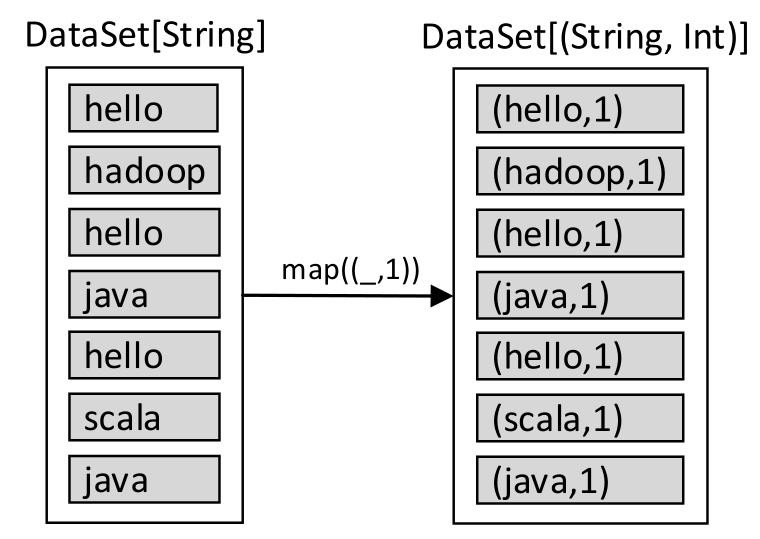
图1-31 对数据集应用map()转换操作
接下来对tupleDataSet数据集应用groupBy()操作进行聚合,按照每个元素的第一个字段进行重新分区(关于分区,将在2.3节详细讲解),第一个字段(即单词)相同的元素将被分配到同一个分区中。聚合后将产生一个GroupedDataSet数据集,代码如下:
val groupedDataSet: GroupedDataSet[(String, Int)] = tupleDataSet.groupBy(0)
数据转换流程如图1-32所示。
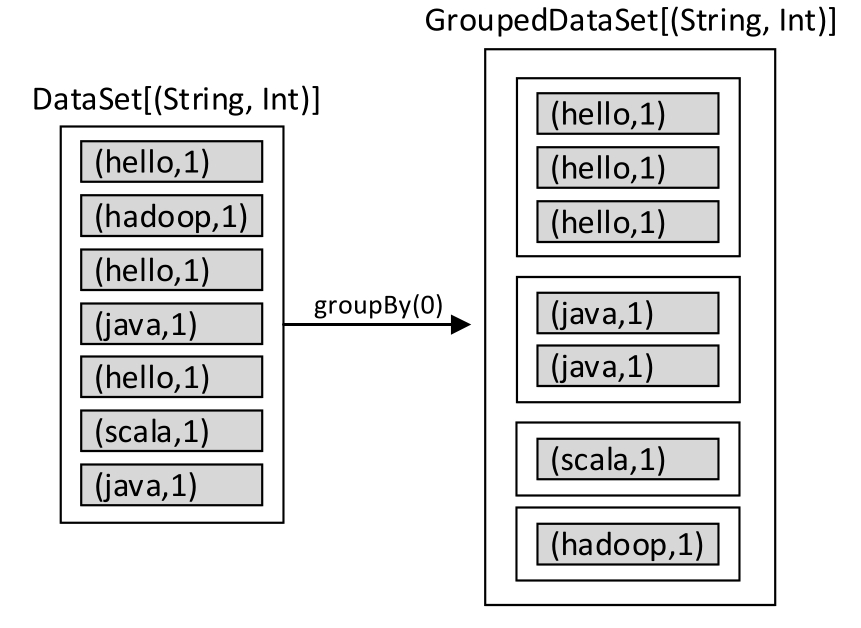
图1-32 对数据集应用groupBy(0)重分区操作
接下来对groupedDataSet数据集应用sum()操作,计算相同key值(单词)下第二个字段的求和运算,代码如下:
val resultDataSet: DataSet[(String, Int)] = groupedDataSet.sum(1)
数据转换流程如图1-33所示。
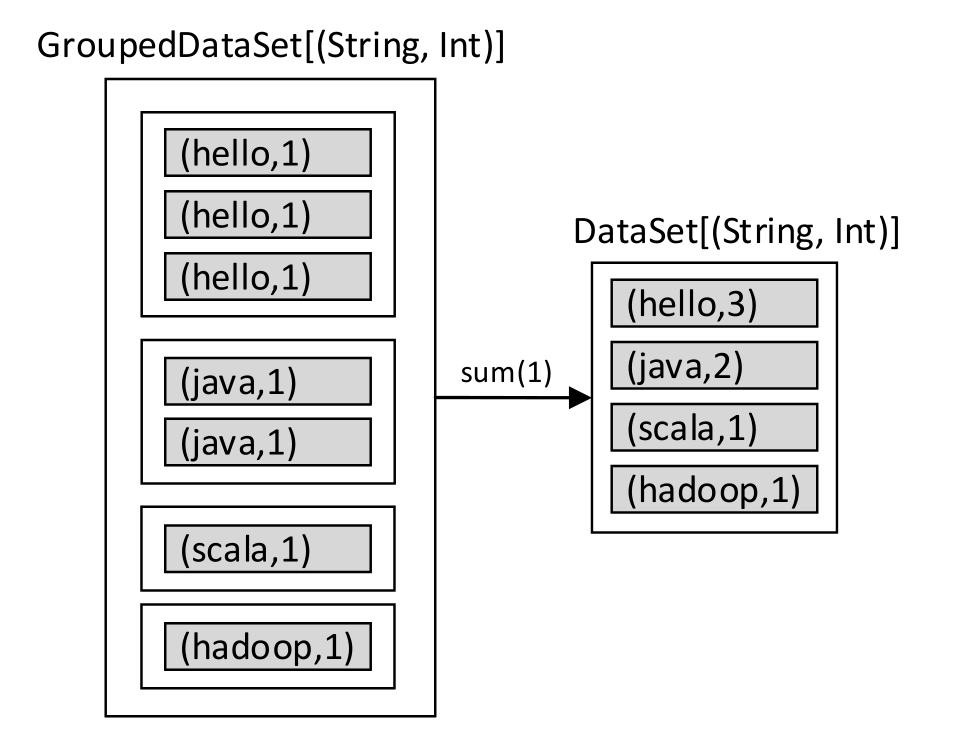
图1-33 对数据集应用sum()求和操作
最后将结果DataSet打印到控制台,代码如下:
resultDataSet.print()
整个过程的完整代码如下:

在IDEA中直接运行上述代码,控制台输出结果如下:
(hadoop,1)
(java,2)
(scala,1)
(hello,3)
1.程序编写
在项目的flink.demo包中新建一个StreamWordCount.scala类,然后向其写入流处理单词计数的程序,程序编写步骤如下。
首先创建一个流处理的执行环境对象StreamExecutionEnvironment,然后使用该对象提供的socketTextStream()方法实时读取外部单词数据,同时将数据转为DataStream数据集,代码如下:
val env=StreamExecutionEnvironment.getExecutionEnvironment
val data:DataStream[String]=env.socketTextStream("localhost",9999)
socketTextStream()方法将创建一个DataStream数据集,其中包含从套接字(Socket)无限接收的字符串。接收到的字符串由系统的默认字符集解码。该方法的两个参数分别为指定数据源的连接地址和端口。
接下来对读取的数据集应用一系列转换操作进行处理。例如,使用flatMap()操作将单词按照空格进行分割并将结果合并为一个新的DataStream数据集;使用filter()操作过滤数据集中的空字段;使用keyBy(_._1)操作按照每个元素的第一个字段进行重新分区(关于分区,将在2.3节详细讲解),第一个字段(即单词)相同的元素将被分配到同一个分区中;使用sum(1)操作按照数据集元素的第二个字段进行求和累加。代码如下:

最后将结果DataStream打印到控制台,代码如下:
result.print()
与批处理不同的是,流处理需要在程序最后调用StreamExecutionEnvironment对象的execute()方法触发任务的执行,并指定作业名称,否则任务不会执行。execute()方法返回一个JobExecutionResult对象,该对象中包含程序执行的时间和累加器等指标,代码如下:
//触发执行,指定作业名称为StreamWordCount
env.execute("StreamWordCount")
整个过程的完整代码如下:

2.程序执行
流式应用程序的执行需要有外部持续产生数据的数据源。此处使用本地Windows系统中安装的Netcat服务器作为数据源(关于Netcat的安装,此处不做讲解),Netcat安装好后,在CMD窗口中执行以下命令启动Netcat,并使其处于持续监听9999端口的状态:
nc –l –p 9999
接下来在IDEA中运行上述流式单词计数应用程序,程序启动后将实时监听本地9999端口产生的数据。
此时在已经启动的Netcat中输入单词数据(分两次输入,一次一行),如图1-34所示。
观察IDEA控制台输出的单词计数结果,如图1-35所示。
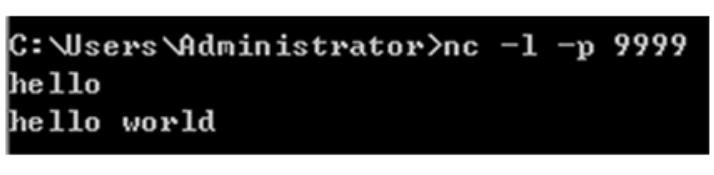
图1-34 在Netcat中输入单词数据
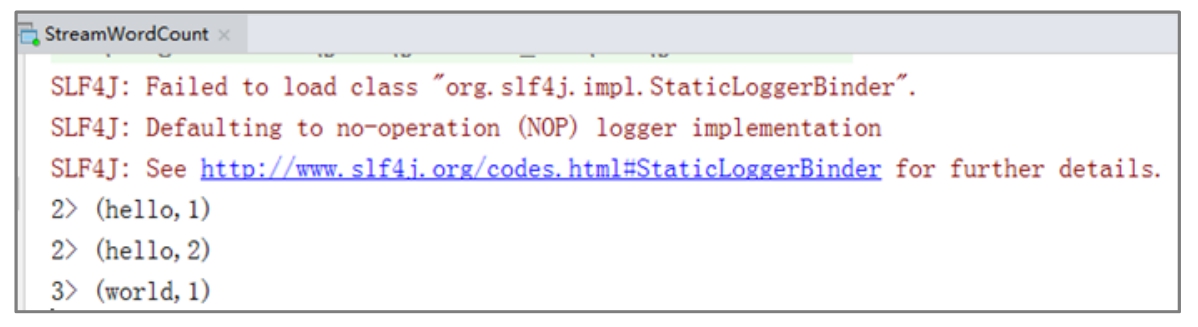
图1-35 IDEA控制台实时输出的计算结果
计数结果前面的数字表示的是执行线程的编号,且相同单词所属的线程编号一定是相同的。从计数结果可以看出,随着数据源不停地发送数据,单词的计数数量也在不断增加。
总的来说,批处理与流处理应用程序的编写步骤基本相同,都包含以下4步:
1)创建执行环境。
2)读取源数据。
3)转换数据。
4)输出转换结果。
流处理应用程序除了上述4步外,还需要有第5步:
5)触发任务执行。