
下载掌阅APP,畅读海量书库
立即打开



本节中我们将专注于如何使用Prometheus进行监控,它能够很好地与Kubernetes标签、服务发现以及元数据集成。本节中实现的高级概念同样适用于其他监控系统。
Prometheus是由CNCF托管的开源项目。它最初由SoundCloud开发,其大量的概念来自谷歌内部的监控系统BorgMon。它通过键值对实现了多维数据模型,其工作原理与Kubernetes的标签系统非常类似。Prometheus以可读的格式暴露监控指标,如下所示:

Prometheus使用拉模型来采集指标,拉模型通过爬取指标端点来采集指标数据,并将其提取到Prometheus服务器中。Kubernetes这类系统已经将指标数据以Prometheus的格式进行暴露,这让指标的采集变得更为简单。很多其他Kubernetes生态中的项目(例如NGINX、Traefik、Istio、LinkerD等)同样以Prometheus的格式暴露了它们的指标数据。Prometheus还可以通过Exporter来采集你的应用服务指标,并将其转换为Prometheus的格式。
Prometheus的架构非常简单,如图3-1所示。
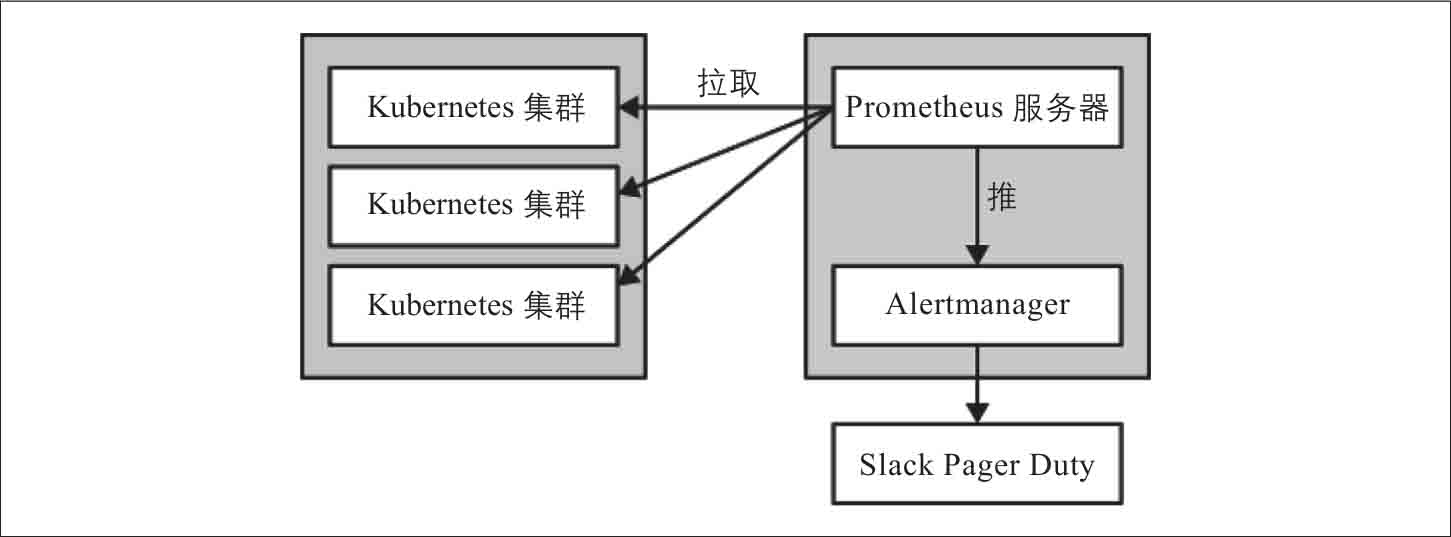
图3-1:Prometheus架构
 可以将Prometheus安装在集群内或集群外,使用独立的工具集群进行监控是一个好的实践,这样可以避免生产故障对监控系统造成影响。诸如Thanos之类的工具可以提供Prometheus的高可用性,而且能够让你将指标数据导出到外部存储。
可以将Prometheus安装在集群内或集群外,使用独立的工具集群进行监控是一个好的实践,这样可以避免生产故障对监控系统造成影响。诸如Thanos之类的工具可以提供Prometheus的高可用性,而且能够让你将指标数据导出到外部存储。
对Prometheus架构的深入介绍超出了本书范围,如果你想要了解更多关于Prometheus的知识,可以参考由O’Reilly出版的 Prometheus: Up & Running 。
接下来让我们更进一步了解Prometheus,并在Kubernetes中安装它。安装Prometheus的方式有很多,其部署方式也随之不同。在本章中,我们使用的是Prometheus Operator:
Prometheus Server
拉取并且存储从系统中采集到的指标数据。
Prometheus Operator
能够让你以Kubernetes原生的方式对Prometheus以及Alertmanager集群进行配置、管理和运维,你可以通过定义Kubernetes原生资源来创建、销毁以及配置Prometheus资源。
Node Exporter
用于从Kubernetes集群的节点中导出主机相关的指标。
kube-state-metrics
用于采集Kubernetes的特定指标。
Alertmanager
用于配置告警并将其转发到外部系统。
Grafana
为Prometheus提供可视化的仪表盘功能。

在安装了Operator之后,你应该能够看到以下Pod已经被部署到集群中:
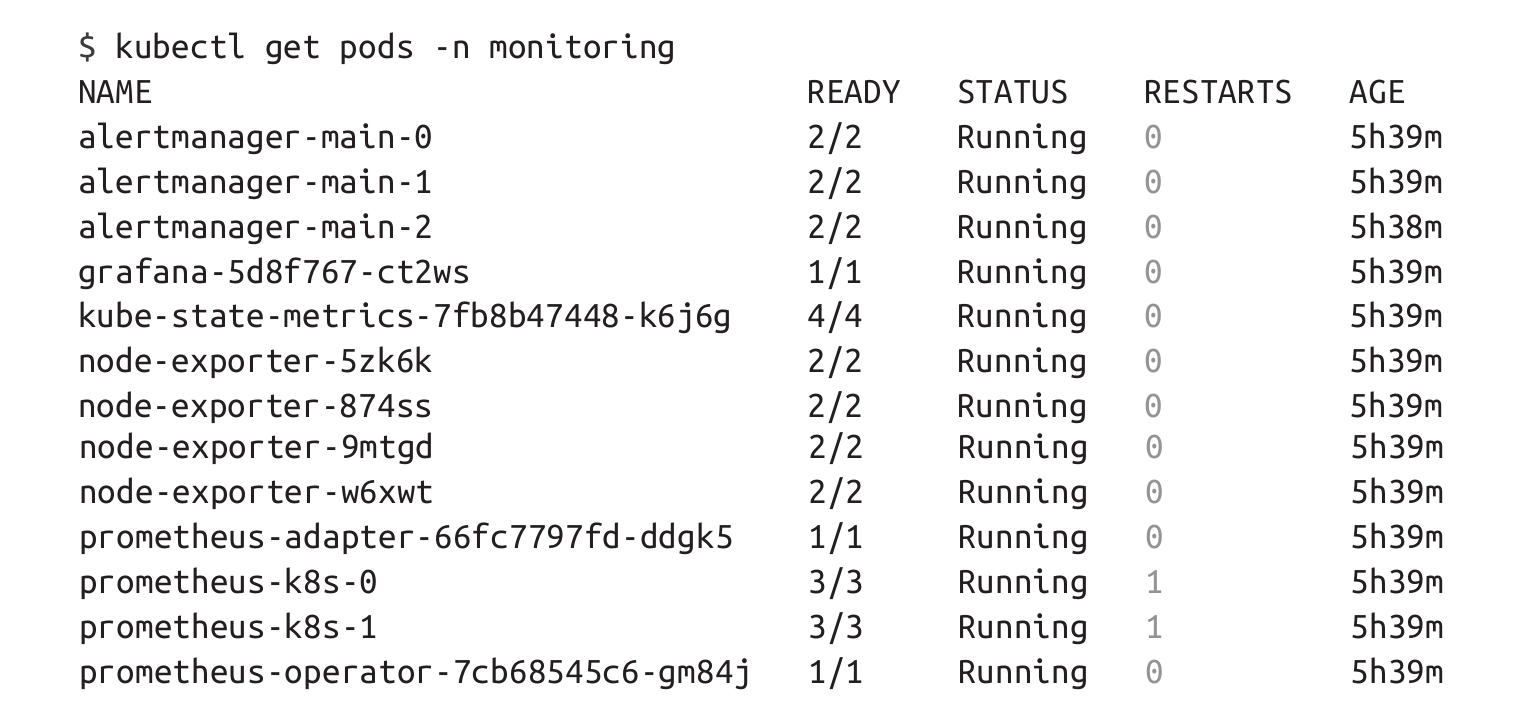
让我们将目光转向Prometheus服务器,了解如何运行查询来检索Kubernetes指标:

上述命令将创建Prometheus服务器到本地9090端口的转发通道。现在,我们可以打开浏览器并且通过 http://127.0.0.1:9090 连接到Prometheus服务器。
如果你已经成功部署了Prometheus,将会看到如图3-2所示的界面。
图3-2:Prometheus仪表盘
现在Prometheus已经部署完成,让我们通过Prometheus的PromQL查询语言来浏览一些Kubernetes指标。想了解PromQL的更多细节,请参考PromQL基础指南。
在本章前面的内容中我们探讨过USE方法,现在来采集一些节点上的CPU利用率和饱和度指标。
在查询输入框中输入如下查询表达式:

该查询将返回整个集群的CPU平均利用率。
如果想要获取指定节点的CPU利用率,可以使用如下查询:
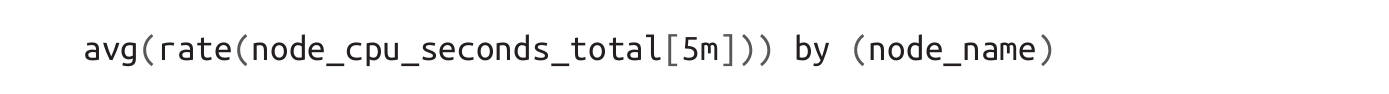
它将返回集群中特定节点的CPU平均利用率。
现在你已经有了一些Prometheus指标查询的经验,接下来让我们看一看如何通过Grafana来为USE方法中常见的指标建立可视化仪表盘。Prometheus Operator很出色的一点在于它自带了一些预装的Grafana仪表盘,可以开箱即用。
创建通往Grafana Pod的端口转发通道,这样就可以从本机访问Grafana:

可以在浏览器中访问 http://localhost:3000 并使用以下凭据登录:
在Grafana的仪表盘中可以找到一个名为“Kubernetes/USE Method/Cluster”的仪表盘。该仪表盘为Kubernetes的集群利用率和饱和度提供了一个很好的概览,这是USE方法的核心所在。图3-3展示了此仪表盘的样例。
图3-3:Grafana仪表盘
你可以继续花一些时间来探索Grafana中的其他仪表盘和指标的可视化。
尽量避免创建太多的仪表盘(又名“图表墙”),因为这会给排查故障的工程师造成困扰。你可能会认为,仪表盘中包含更多的信息意味着更好的监控,但是在大多数情况下,它会让仪表盘的查看者更加困惑。仪表盘的设计重点应该是如何帮助解决问题以及减少解决问题所花费的时间。