
下载掌阅APP,畅读海量书库
立即打开




数据的聚合指的是通过转换数据让每一个数组生成一个单一的数值。本节将介绍按指定列聚合、多字段分组聚合、自定义聚合等,使用的数据文件为“不同地区商品退单量2.xls”。
在介绍Pandas数据聚合之前,先创建一个关于不同地区商品退单量的数据集,示例代码如下:

运行上述代码,创建的数据集如下:
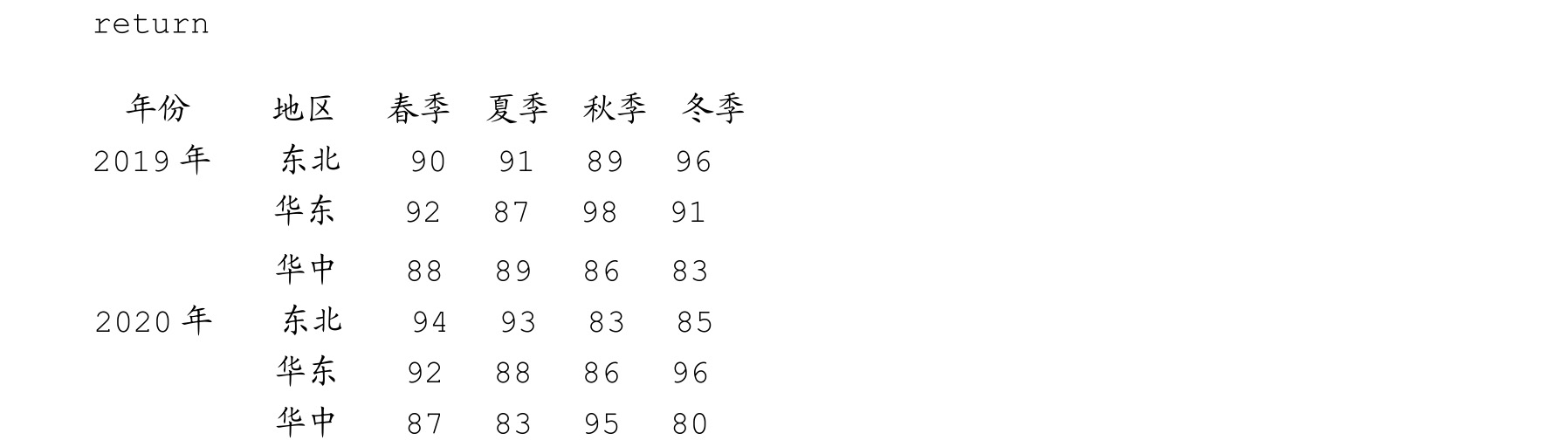
可以使用level参数选项指定在某列上进行数据统计,例如统计最近两年的平均退单量,示例代码和输出如下:

level参数不仅可以使用列名称,还可以使用列索引号,例如统计不同地区的平均退单量,示例代码和输出如下:

下面重新创建一个关于不同地区商品退单量的数据集,示例代码如下:

运行上述代码,创建的数据集如下:
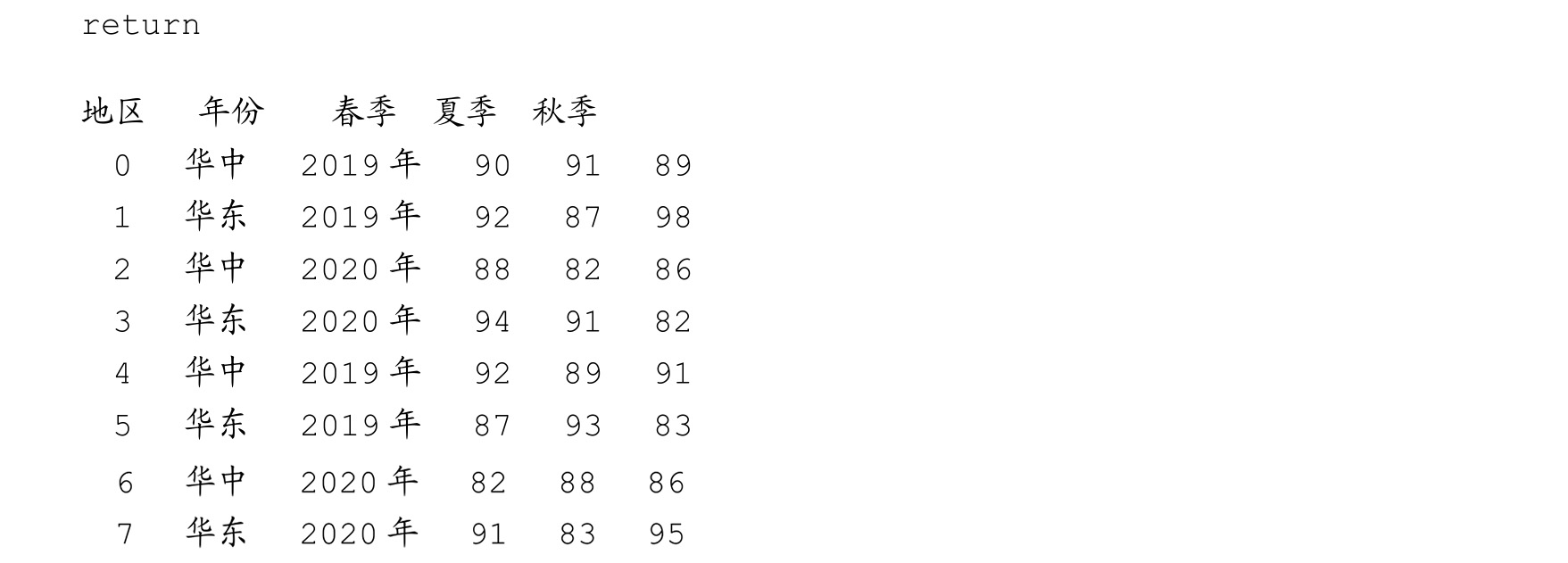
此外,groupby()函数可以实现对多个字段的分组统计,例如统计最近两年不同地区的平均退单量,示例代码和输出如下:

在Python中,计算一些描述性统计指标通常是调用describe()函数,例如个数、平均值、标准差、最小值和最大值等,示例代码和输出如下:
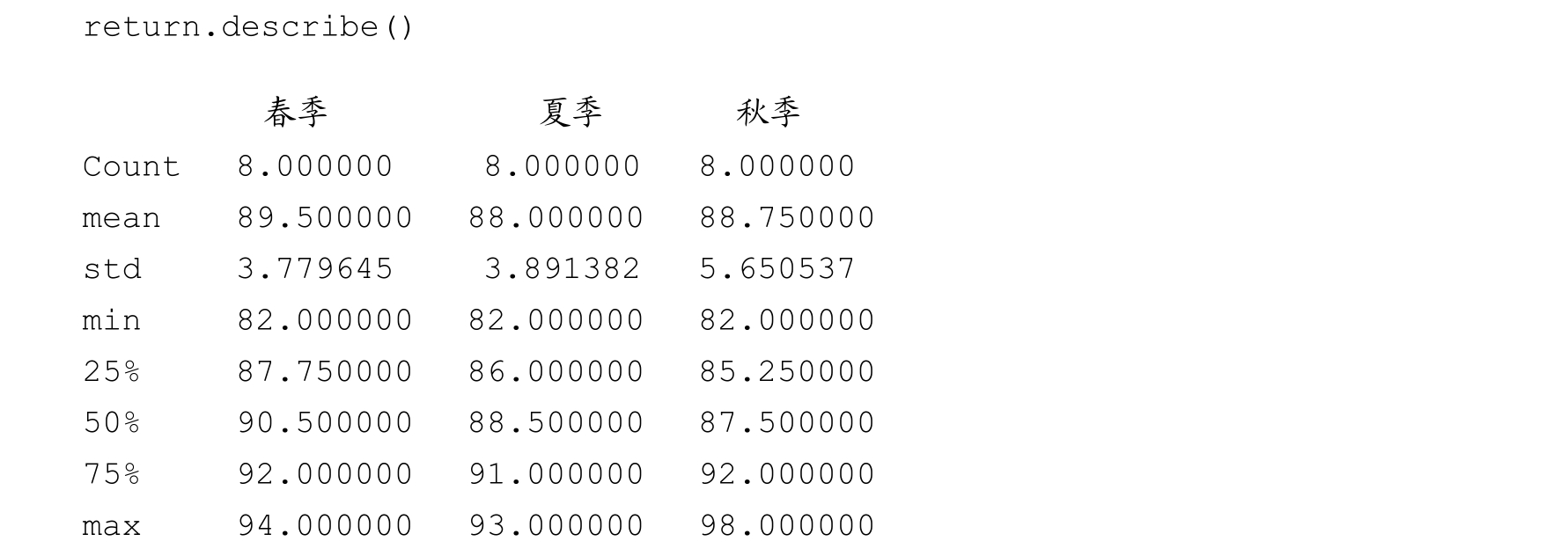
但是,如果要使用自定义的聚合函数,只需将其传入aggregate()或agg()函数,例如这里定义的是sum、mean、max、min,示例代码和输出如下:
