
下载掌阅APP,畅读海量书库
立即打开



 1.2 统计学习的分类
1.2 统计学习的分类
统计学习或机器学习是一个范围宽阔、内容繁多、应用广泛的领域,并不存在(至少现在不存在)一个统一的理论体系涵盖所有内容。下面从几个角度对统计学习方法进行分类。
统计学习或机器学习一般包括监督学习、无监督学习、强化学习。有时还包括半监督学习、主动学习。
监督学习(supervised learning)是指从标注数据中学习预测模型的机器学习问题。标注数据表示输入输出的对应关系,预测模型对给定的输入产生相应的输出。监督学习的本质是学习输入到输出的映射的统计规律。
(1)输入空间、特征空间和输出空间
在监督学习中,将输入与输出所有可能取值的集合分别称为输入空间(input space)与输出空间(output space)。输入与输出空间可以是有限元素的集合,也可以是整个欧氏空间。输入空间与输出空间可以是同一个空间,也可以是不同的空间;但通常输出空间远远小于输入空间。
每个具体的输入是一个实例(instance),通常由特征向量(feature vector)表示。这时,所有特征向量存在的空间称为特征空间(feature space)。特征空间的每一维对应于一个特征。有时假设输入空间与特征空间为相同的空间,对它们不予区分;有时假设输入空间与特征空间为不同的空间,将实例从输入空间映射到特征空间。模型实际上都是定义在特征空间上的。
在监督学习中,将输入与输出看作是定义在输入(特征)空间与输出空间上的随机变量的取值。输入输出变量用大写字母表示,习惯上输入变量写作 X ,输出变量写作 Y 。输入输出变量的取值用小写字母表示,输入变量的取值写作 x ,输出变量的取值写作 y 。变量可以是标量或向量,都用相同类型字母表示。除特别声明外,本书中向量均为列向量。输入实例 x 的特征向量记作
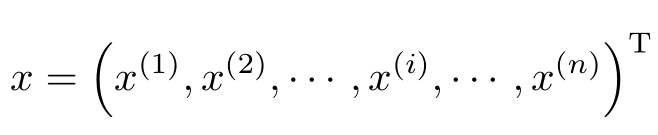
x ( i ) 表示 x 的第 i 个特征。注意 x ( i ) 与 x i 不同,本书通常用 x i 表示多个输入变量中的第 i 个变量,即
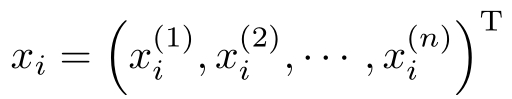
监督学习从训练数据(training data)集合中学习模型,对测试数据(test data)进行预测。训练数据由输入(或特征向量)与输出对组成,训练集通常表示为
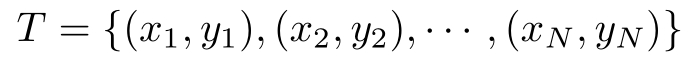
测试数据也由输入与输出对组成。输入与输出对又称为样本(sample)或样本点。
输入变量 X 和输出变量 Y 有不同的类型,可以是连续的,也可以是离散的。人们根据输入输出变量的不同类型,对预测任务给予不同的名称:输入变量与输出变量均为连续变量的预测问题称为回归问题;输出变量为有限个离散变量的预测问题称为分类问题;输入变量与输出变量均为变量序列的预测问题称为标注问题。
(2)联合概率分布
监督学习假设输入与输出的随机变量 X 和 Y 遵循联合概率分布 P ( X , Y )。 P ( X , Y )表示分布函数,或分布密度函数。注意在学习过程中,假定这一联合概率分布存在,但对学习系统来说,联合概率分布的具体定义是未知的。训练数据与测试数据被看作是依联合概率分布 P ( X , Y )独立同分布产生的。统计学习假设数据存在一定的统计规律, X 和 Y 具有联合概率分布就是监督学习关于数据的基本假设。
(3)假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射由模型来表示。换句话说,学习的目的就在于找到最好的这样的模型。模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space)。假设空间的确定意味着学习的范围的确定。
监督学习的模型可以是概率模型或非概率模型,由条件概率分布 P ( Y | X )或决策函数(decision function) Y = f ( X )表示,随具体学习方法而定。对具体的输入进行相应的输出预测时,写作 P ( y | x )或 y = f ( x )。
(4)问题的形式化
监督学习利用训练数据集学习一个模型,再用模型对测试样本集进行预测。由于在这个过程中需要标注的训练数据集,而标注的训练数据集往往是人工给出的,所以称为监督学习。监督学习分为学习和预测两个过程,由学习系统与预测系统完成,可用图1.1来描述。
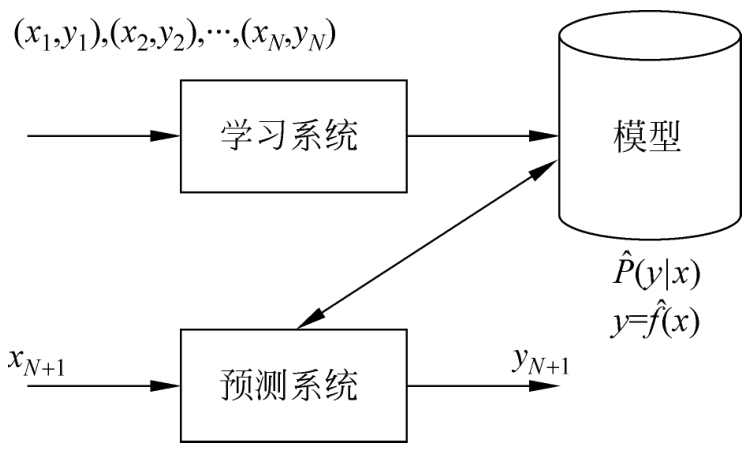
图1.1 监督学习
首先给定一个训练数据集
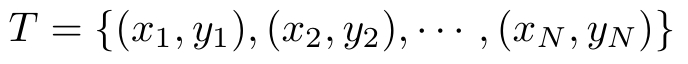
其中( x i , y i ), i =1,2,…, N ,称为样本或样本点。 x i ∈ X ⊆ R n 是输入的观测值,也称为输入或实例, y i ∈ Y 是输出的观测值,也称为输出。
监督学习分为学习和预测两个过程,由学习系统与预测系统完成。在学习过程中,学习系统利用给定的训练数据集,通过学习(或训练)得到一个模型,表示为条件概率分布
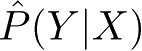 或决策函数
或决策函数
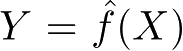 。条件概率分布
。条件概率分布
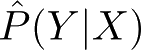 或决策函数
或决策函数
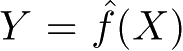 描述输入与输出随机变量之间的映射关系。在预测过程中,预测系统对于给定的测试样本集中的输入
x
N
+1
,由模型
描述输入与输出随机变量之间的映射关系。在预测过程中,预测系统对于给定的测试样本集中的输入
x
N
+1
,由模型
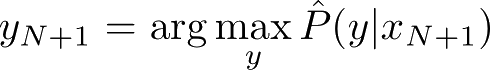 或
或
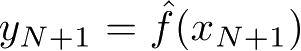 给出相应的输出
y
N
+1
。
给出相应的输出
y
N
+1
。
在监督学习中,假设训练数据与测试数据是依联合概率分布 P ( X , Y )独立同分布产生的。
学习系统(也就是学习算法)试图通过训练数据集中的样本( x i , y i )带来的信息学习模型。具体地说,对输入 x i ,一个具体的模型 y = f ( x )可以产生一个输出 f ( x i ),而训练数据集中对应的输出是 y i 。如果这个模型有很好的预测能力,训练样本输出 y i 和模型输出 f ( x i )之间的差就应该足够小。学习系统通过不断地尝试,选取最好的模型,以便对训练数据集有足够好的预测,同时对未知的测试数据集的预测也有尽可能好的推广。
无监督学习
 (unsupervised learning)是指从无标注数据中学习预测模型的机器学习问题。无标注数据是自然得到的数据,预测模型表示数据的类别、转换或概率。无监督学习的本质是学习数据中的统计规律或潜在结构。
(unsupervised learning)是指从无标注数据中学习预测模型的机器学习问题。无标注数据是自然得到的数据,预测模型表示数据的类别、转换或概率。无监督学习的本质是学习数据中的统计规律或潜在结构。
模型的输入与输出的所有可能取值的集合分别称为输入空间与输出空间。输入空间与输出空间可以是有限元素集合,也可以是欧氏空间。每个输入是一个实例,由特征向量表示。每一个输出是对输入的分析结果,由输入的类别、转换或概率表示。模型可以实现对数据的聚类、降维或概率估计。
假设
X
是输入空间,
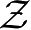 是隐式结构空间。要学习的模型可以表示为函数
z
=
g
(
x
),条件概率分布
P
(
z
|
x
),或者条件概率分布
P
(
x
|
z
)的形式,其中
x
∈
X
是输入,
是隐式结构空间。要学习的模型可以表示为函数
z
=
g
(
x
),条件概率分布
P
(
z
|
x
),或者条件概率分布
P
(
x
|
z
)的形式,其中
x
∈
X
是输入,
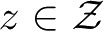 是输出。包含所有可能的模型的集合称为假设空间。无监督学习旨在从假设空间中选出在给定评价标准下的最优模型。
是输出。包含所有可能的模型的集合称为假设空间。无监督学习旨在从假设空间中选出在给定评价标准下的最优模型。
无监督学习通常使用大量的无标注数据学习或训练,每一个样本是一个实例。训练数据表示为 U ={ x 1 , x 2 ,…, x N },其中 x i , i =1,2,…, N ,是样本。
无监督学习可以用于对已有数据的分析,也可以用于对未来数据的预测。分析时使用学习得到的模型,即函数
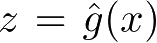 ,条件概率分布
,条件概率分布
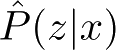 ,或者条件概率分布
,或者条件概率分布
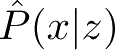 。预测时,和监督学习有类似的流程。由学习系统与预测系统完成,如图1.2所示。在学习过程中,学习系统从训练数据集学习,得到一个最优模型,表示为函数
。预测时,和监督学习有类似的流程。由学习系统与预测系统完成,如图1.2所示。在学习过程中,学习系统从训练数据集学习,得到一个最优模型,表示为函数
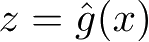 ,条件概率分布
,条件概率分布
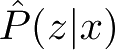 或者条件概率分布
或者条件概率分布
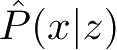 。在预测过程中,预测系统对于给定的输入
x
N
+1
,由模型
。在预测过程中,预测系统对于给定的输入
x
N
+1
,由模型
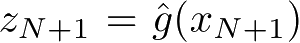 或
或
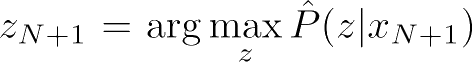 给出相应的输出
z
N
+1
,进行聚类或降维,或者由模型
给出相应的输出
z
N
+1
,进行聚类或降维,或者由模型
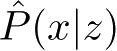 给出输入的概率
给出输入的概率
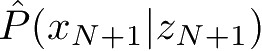 ,进行概率估计。
,进行概率估计。
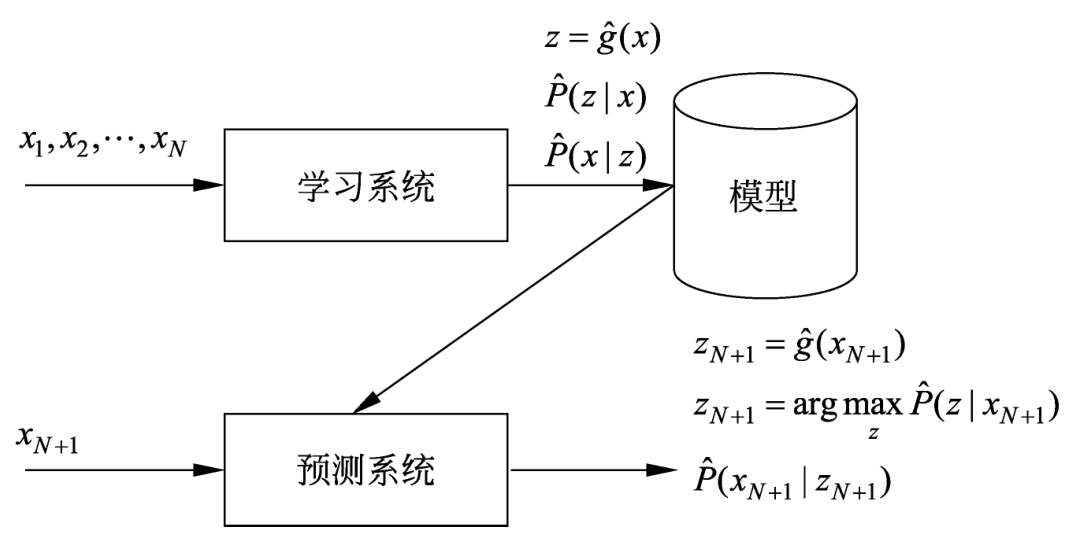
图1.2 无监督学习
强化学习(reinforcement learning)是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。假设智能系统与环境的互动基于马尔可夫决策过程(Markov decision process),智能系统能观测到的是与环境互动得到的数据序列。强化学习的本质是学习最优的序贯决策。
智能系统与环境的互动如图1.3所示。在每一步 t ,智能系统从环境中观测到一个状态(state) s t 与一个奖励(reward) r t ,采取一个动作(action) a t 。环境根据智能系统选择的动作,决定下一步 t +1的状态 s t +1 与奖励 r t +1 。要学习的策略表示为给定的状态下采取的动作。智能系统的目标不是短期奖励的最大化,而是长期累积奖励的最大化。强化学习过程中,系统不断地试错(trial and error),以达到学习最优策略的目的。
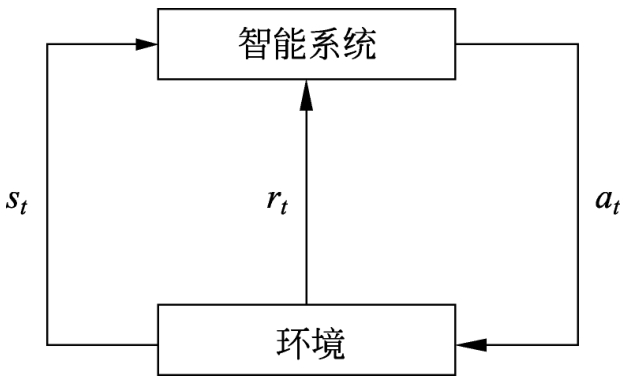
图1.3 智能系统与环境的互动
强化学习的马尔可夫决策过程是状态、奖励、动作序列上的随机过程,由五元组< S , A , P , r , γ >组成。
· S 是有限状态(state)的集合
· A 是有限动作(action)的集合
· P 是状态转移概率(transition probability)函数:
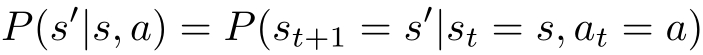
· r 是奖励函数(reward function): r ( s , a )= E ( r t +1 | s t = s , a t = a )
· γ 是衰减系数(discount factor): γ ∈[0,1]
马尔可夫决策过程具有马尔可夫性,下一个状态只依赖于前一个状态与动作,由状态转移概率函数 P ( s' | s , a )表示。下一个奖励依赖于前一个状态与动作,由奖励函数 r ( s , a )表示。
策略 π 定义为给定状态下动作的函数 a = f ( s )或者条件概率分布 P ( a | s )。给定一个策略 π ,智能系统与环境互动的行为就已确定(或者是确定性的或者是随机性的)。
价值函数(value function)或状态价值函数(state value function)定义为策略 π 从某一个状态 s 开始的长期累积奖励的数学期望:
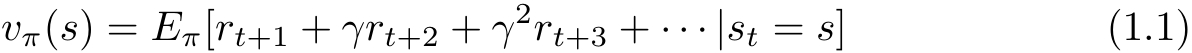
动作价值函数(action value function)定义为策略 π 的从某一个状态 s 和动作 a 开始的长期累积奖励的数学期望:
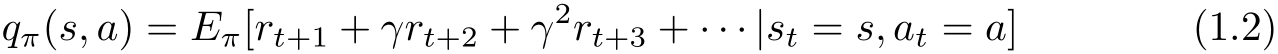
强化学习的目标就是在所有可能的策略中选出价值函数最大的策略 π * ,而在实际学习中往往从具体的策略出发,不断优化已有策略。这里 γ 表示未来的奖励会有衰减。
强化学习方法中有基于策略的(policy-based)、基于价值的(value-based),这两者属于无模型的(model-free)方法,还有有模型的(model-based)方法。
有模型的方法试图直接学习马尔可夫决策过程的模型,包括转移概率函数 P ( s' | s , a )和奖励函数 r ( s , a )。这样可以通过模型对环境的反馈进行预测,求出价值函数最大的策略 π * 。
无模型的、基于策略的方法不直接学习模型,而是试图求解最优策略 π * ,表示为函数 a = f * ( s )或者是条件概率分布 P * ( a | s ),这样也能达到在环境中做出最优决策的目的。学习通常从一个具体策略开始,通过搜索更优的策略进行。
无模型的、基于价值的方法也不直接学习模型,而是试图求解最优价值函数,特别是最优动作价值函数 q * ( s , a )。这样可以间接地学到最优策略,根据该策略在给定的状态下做出相应的动作。学习通常从一个具体价值函数开始,通过搜索更优的价值函数进行。
半监督学习(semi-supervised learning)是指利用标注数据和未标注数据学习预测模型的机器学习问题。通常有少量标注数据、大量未标注数据,因为标注数据的构建往往需要人工,成本较高,未标注数据的收集不需太多成本。半监督学习旨在利用未标注数据中的信息,辅助标注数据,进行监督学习,以较低的成本达到较好的学习效果。
主动学习(active learning)是指机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。通常的监督学习使用给定的标注数据,往往是随机得到的,可以看作是“被动学习”,主动学习的目标是找出对学习最有帮助的实例让教师标注,以较小的标注代价,达到较好的学习效果。
半监督学习和主动学习更接近监督学习。
统计学习或机器学习方法可以根据其模型的种类进行分类。
统计学习的模型可以分为概率模型(probabilistic model)和非概率模型(nonprobabilistic model)或者确定性模型(deterministic model)。在监督学习中,概率模型取条件概率分布形式 P ( y | x ),非概率模型取函数形式 y = f ( x ),其中 x 是输入, y 是输出。在无监督学习中,概率模型取条件概率分布形式 P ( z | x )或 P ( x | z ),非概率模型取函数形式 z = g ( x ),其中 x 是输入, z 是输出。
本书介绍的决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型是概率模型。感知机、支持向量机、 k 近邻、AdaBoost、 k 均值、潜在语义分析,以及神经网络是非概率模型。逻辑斯谛回归既可看作是概率模型,又可看作是非概率模型。
条件概率分布 P ( y | x )和函数 y = f ( x )可以相互转化(条件概率分布 P ( z | x )和函数 z = g ( x )同样可以)。具体地,条件概率分布最大化后得到函数,函数归一化后得到条件概率分布。所以,概率模型和非概率模型的区别不在于输入与输出之间的映射关系,而在于模型的内在结构。概率模型通常可以表示为联合概率分布的形式,其中的变量表示输入、输出、隐变量甚至参数。而非概率模型则不一定存在这样的联合概率分布。
概率模型的代表是概率图模型(probabilistic graphical model),概率图模型是联合概率分布由有向图或者无向图表示的概率模型,而联合概率分布可以根据图的结构分解为因子乘积的形式。贝叶斯网络、马尔可夫随机场、条件随机场是概率图模型。无论模型如何复杂,均可以用最基本的加法规则和乘法规则(参照图1.4)进行概率推理。

图1.4 基本概率公式
统计学习模型,特别是非概率模型,可以分为线性模型(linear model)和非线性模型(non-linear model)。如果函数 y = f ( x )或 z = g ( x )是线性函数,则称模型是线性模型,否则称模型是非线性模型。
本书介绍的感知机、线性支持向量机、 k 近邻、 k 均值、潜在语义分析是线性模型。核函数支持向量机、AdaBoost、神经网络是非线性模型。
深度学习(deep learning)实际是复杂神经网络的学习,也就是复杂的非线性模型的学习。
统计学习模型又可以分为参数化模型(parametric model)和非参数化模型(non-parametric model)。参数化模型假设模型参数的维度固定,模型可以由有限维参数完全刻画;非参数化模型假设模型参数的维度不固定或者说无穷大,随着训练数据量的增加而不断增大。
本书介绍的感知机、朴素贝叶斯、逻辑斯谛回归、 k 均值、高斯混合模型、潜在语义分析、概率潜在语义分析、潜在狄利克雷分配是参数化模型。决策树、支持向量机、AdaBoost、 k 近邻是非参数化模型。
参数化模型适合问题简单的情况,现实中问题往往比较复杂,非参数化模型更加有效。
统计学习根据算法,可以分为在线学习(online learning)与批量学习(batch learning)。在线学习是指每次接受一个样本,进行预测,之后学习模型,并不断重复该操作的机器学习。与之对应,批量学习一次接受所有数据,学习模型,之后进行预测。有些实际应用的场景要求学习必须是在线的。比如,数据依次达到无法存储,系统需要及时做出处理;数据规模很大,不可能一次处理所有数据;数据的模式随时间动态变化,需要算法快速适应新的模式(不满足独立同分布假设)。
在线学习可以是监督学习,也可以是无监督学习,强化学习本身就拥有在线学习的特点。以下只考虑在线的监督学习。
学习和预测在一个系统,每次接受一个输入
x
t
,用已有模型给出预测
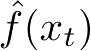 ,之后得到相应的反馈,即该输入对应的输出
y
t
;系统用损失函数计算两者的差异,更新模型;并不断重复以上操作。见图1.5。
,之后得到相应的反馈,即该输入对应的输出
y
t
;系统用损失函数计算两者的差异,更新模型;并不断重复以上操作。见图1.5。
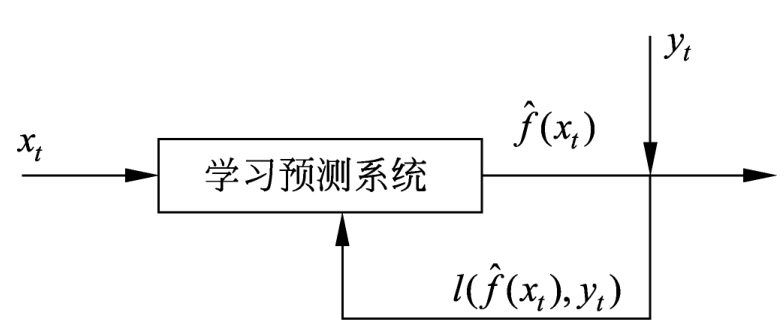
图1.5 在线学习
利用随机梯度下降的感知机学习算法就是在线学习算法。
在线学习通常比批量学习更难,很难学到预测准确率更高的模型,因为每次模型更新中,可利用的数据有限。
统计学习方法可以根据其使用的技巧进行分类。
贝叶斯学习(Bayesian learning),又称为贝叶斯推理(Bayesian inference),是统计学、机器学习中重要的方法。其主要想法是,在概率模型的学习和推理中,利用贝叶斯定理,计算在给定数据条件下模型的条件概率,即后验概率,并应用这个原理进行模型的估计,以及对数据的预测。将模型、未观测要素及其参数用变量表示,使用模型的先验分布是贝叶斯学习的特点。贝叶斯学习中也使用基本概率公式(图1.4)。
本书介绍的朴素贝叶斯、潜在狄利克雷分配的学习属于贝叶斯学习。
假设随机变量 D 表示数据,随机变量 θ 表示模型参数。根据贝叶斯定理,可以用以下公式计算后验概率 P ( θ | D ):

其中 P ( θ )是先验概率, P ( D | θ )是似然函数。
模型估计时,估计整个后验概率分布 P ( θ | D )。如果需要给出一个模型,通常取后验概率最大的模型。
预测时,计算数据对后验概率分布的期望值:
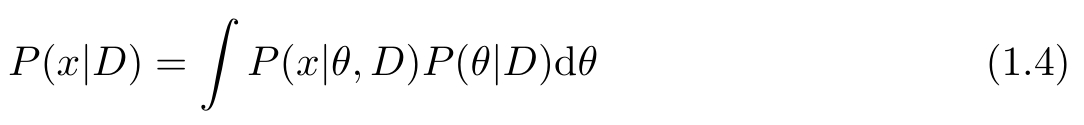
这里 x 是新样本。
贝叶斯估计与极大似然估计在思想上有很大的不同,代表着统计学中贝叶斯学派和频率学派对统计的不同认识。其实,可以简单地把两者联系起来,假设先验分布是均匀分布,取后验概率最大,就能从贝叶斯估计得到极大似然估计。图1.6对贝叶斯估计和极大似然估计进行比较。
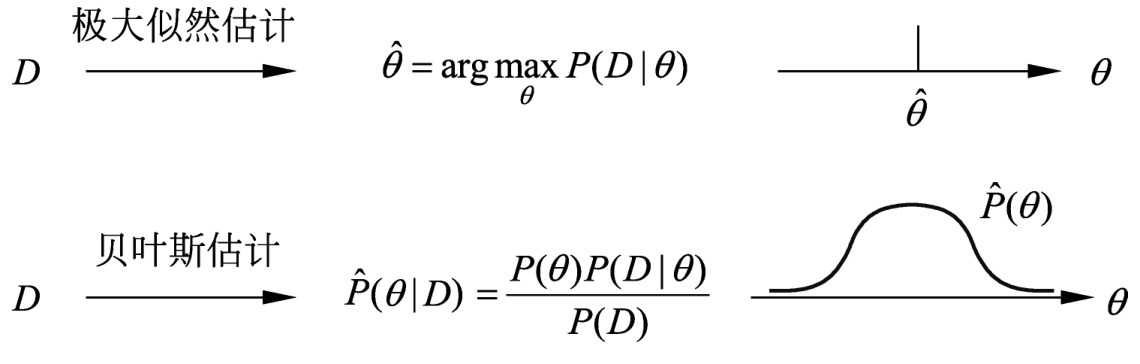
图1.6 贝叶斯估计与极大似然估计
核方法(kernel method)是使用核函数表示和学习非线性模型的一种机器学习方法,可以用于监督学习和无监督学习。有一些线性模型的学习方法基于相似度计算,更具体地,向量内积计算。核方法可以把它们扩展到非线性模型的学习,使其应用范围更广泛。
本书介绍的核函数支持向量机,以及核PCA、核 k 均值属于核方法。
把线性模型扩展到非线性模型,直接的做法是显式地定义从输入空间(低维空间)到特征空间(高维空间)的映射,在特征空间中进行内积计算。比如,支持向量机,把输入空间的线性不可分问题转化为特征空间的线性可分问题,如图1.7所示。核方法的技巧在于不显式地定义这个映射,而是直接定义核函数,即映射之后在特征空间的内积。这样可以简化计算,达到同样的效果。
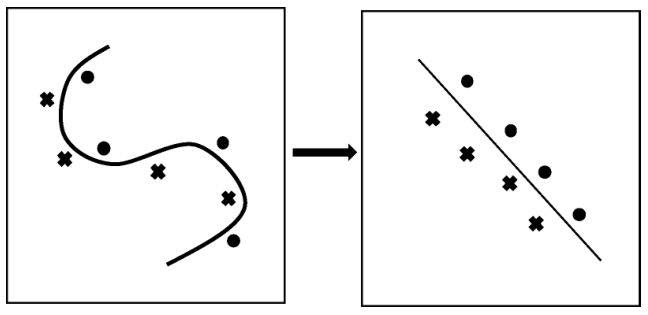
图1.7 输入空间到特征空间的映射
假设 x 1 和 x 2 是输入空间的任意两个实例(向量),其内积是< x 1 , x 2 >。假设从输入空间到特征空间的映射是 φ ,于是 x 1 和 x 2 在特征空间的映像是 φ ( x 1 )和 φ ( x 2 ),其内积是< φ ( x 1 ), φ ( x 2 )>。核方法直接在输入空间中定义核函数 K ( x 1 , x 2 ),使其满足 K ( x 1 , x 2 )=< φ ( x 1 ), φ ( x 2 )>。表示定理给出核函数技巧成立的充要条件。