
下载掌阅APP,畅读海量书库
立即打开



 5.3 决策树的生成
5.3 决策树的生成
本节将介绍决策树学习的生成算法。首先介绍ID3的生成算法,然后再介绍C4.5中的生成算法。这些都是决策树学习的经典算法。
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一棵决策树。ID3相当于用极大似然法进行概率模型的选择。
算法5.2(ID3算法)
输入:训练数据集 D ,特征集 A 阈值 ε ;
输出:决策树 T 。
(1)若 D 中所有实例属于同一类 C k ,则 T 为单结点树,并将类 C k 作为该结点的类标记,返回 T ;
(2)若 A =∅,则 T 为单结点树,并将 D 中实例数最大的类 C k 作为该结点的类标记,返回 T ;
(3)否则,按算法5.1计算 A 中各特征对 D 的信息增益,选择信息增益最大的特征 A g ;
(4)如果 A g 的信息增益小于阈值 ε ,则置 T 为单结点树,并将 D 中实例数最大的类 C k 作为该结点的类标记,返回 T ;
(5)否则,对 A g 的每一可能值 a i ,依 A g = a i 将 D 分割为若干非空子集 D i ,将 D i 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 T ,返回 T ;
(6)对第 i 个子结点,以 D i 为训练集,以 A−{A g }为特征集,递归地调用步(1)~步(5),得到子树 T i ,返回 T i 。
例5.3 对表5.1的训练数据集,利用ID3算法建立决策树。
解 利用例5.2的结果,由于特征 A 3 (有自己的房子)的信息增益值最大,所以选择特征 A 3 作为根结点的特征。它将训练数据集 D 划分为两个子集 D 1 ( A 3 取值为“是”)和 D 2 ( A 3 取值为“否”)。由于 D 1 只有同一类的样本点,所以它成为一个叶结点,结点的类标记为“是”。
对 D 2 则需从特征 A 1 (年龄), A 2 (有工作)和 A 4 (信贷情况)中选择新的特征。计算各个特征的信息增益:
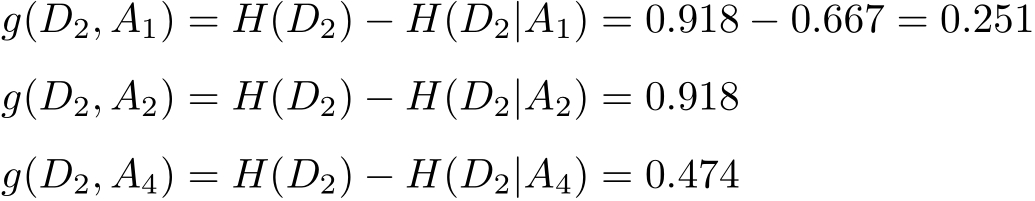
选择信息增益最大的特征 A 2 (有工作)作为结点的特征。由于 A 2 有两个可能取值,从这一结点引出两个子结点:一个对应“是”(有工作)的子结点,包含3个样本,它们属于同一类,所以这是一个叶结点,类标记为“是”;另一个是对应“否”(无工作)的子结点,包含6个样本,它们也属于同一类,所以这也是一个叶结点,类标记为“否”。
这样生成一棵如图5.5所示的决策树。该决策树只用了两个特征(有两个内部结点)。
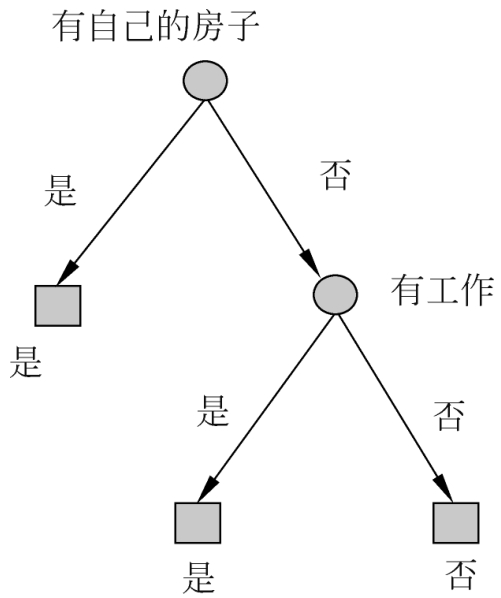
图5.5 决策树的生成
ID3算法只有树的生成,所以该算法生成的树容易产生过拟合。
C4.5算法与ID3算法相似,C4.5算法对ID3算法进行了改进。C4.5在生成的过程中,用信息增益比来选择特征。
算法5.3(C4.5的生成算法)
输入:训练数据集 D ,特征集 A 阈值 ε ;
输出:决策树 T 。
(1)如果 D 中所有实例属于同一类 C k ,则置 T 为单结点树,并将 C k 作为该结点的类,返回 T ;
(2)如果 A =∅,则置 T 为单结点树,并将 D 中实例数最大的类 C k 作为该结点的类,返回 T ;
(3)否则,按式(5.10)计算 A 中各特征对 D 的信息增益比,选择信息增益比最大的特征 A g ;
(4)如果 A g 的信息增益比小于阈值 ε ,则置 T 为单结点树,并将 D 中实例数最大的类 C k 作为该结点的类,返回 T ;
(5)否则,对 A g 的每一可能值 a i ,依 A g = a i 将 D 分割为子集若干非空 D i ,将 D i 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 T ,返回 T ;
(6)对结点 i ,以 D i 为训练集,以 A−{A g }为特征集,递归地调用步(1)~步(5),得到子树 T i ,返回 T i 。