
下载掌阅APP,畅读海量书库
立即打开



 3.1
k
近邻算法
3.1
k
近邻算法
k 近邻算法简单、直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。下面先叙述 k 近邻算法,然后再讨论其细节。
算法3.1( k 近邻法)
输入:训练数据集
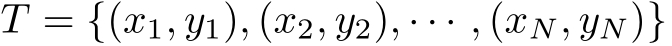
其中, x i ∈ X ⊆ R n 为实例的特征向量, y i ∈ Y ={ c 1 , c 2 ,…, c K }为实例的类别, i =1,2,…, N ;实例特征向量 x ;
输出:实例 x 所属的类 y 。
(1)根据给定的距离度量,在训练集 T 中找出与 x 最邻近的 k 个点,涵盖这 k 个点的 x 的邻域记作 N k ( x );
(2)在 N k ( x )中根据分类决策规则(如多数表决)决定 x 的类别 y :
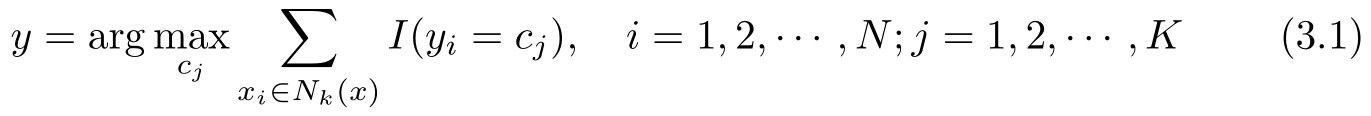
式(3.1)中, I 为指示函数,即当 y i = c j 时 I 为1,否则 I 为0。
k 近邻法的特殊情况是 k =1的情形,称为最近邻算法。对于输入的实例点(特征向量) x ,最近邻法将训练数据集中与 x 最邻近点的类作为 x 的类。
k 近邻法没有显式的学习过程。