
下载掌阅APP,畅读海量书库
立即打开



聚类分析是多元统计分析的方法之一,也是统计模式识别中非监督模式分类的一个重要分支 [35] ,其任务是用某种相似性度量的方法,把一个未标记的样本集按某种准则组织成有意义的和有用的若干子集,要求相似的样本尽量归为一类,而不相似的样本应在不同的类。采用这种分析方法可以定量地确定研究对象之间的亲疏关系,从而达到对其进行合理分类、分析等目的。本质上,数据聚类是一种数据驱动的非监督学习方法。
在传统的聚类方法中,基于目标函数的聚类算法由于把聚类问题归结为一个优化问题,具有深厚的泛函基础,从而成为聚类算法研究的主流。C-均值算法就是其中最具代表性的一种 [36] ,但由于它以聚类中心为原型,因而不能检测特征空间中非线性子空间中存在的聚类,为此人们对聚类原型模式进行了相应的扩展,形成了从特征空间中的点到线、面、壳以及二次曲线等诸多类型的原型,提出了C-线、C-面、C-壳、C-二次曲线 [37-39] 等一系列的针对各种原型的聚类算法,实现了对各种不同原型的聚类分析。
但是这种基于目标函数的聚类算法存在的最大问题就是对聚类先验知识要求的增加,因为在聚类分析之前,必须给定聚类原型的类型以及聚类类别数 c ,否则将会对算法产生误导 [36] ,从而得到一个错误的划分;同时这类算法要求数据集中不同类别的样本只能呈同一种类型的分布模式,即对每个子集的分析采用的是同一种聚类原型,只是原型的参数有所差别,从而限制了其实际应用的范围。在实际的应用中,很多情况下同一数据集中往往含有多种不同原型的样本子集,而且当样本点处于高维空间时,很难获得聚类类别数 c 。
文献[40]提出一种多类原型模糊聚类算法,将现有的原型聚类算法集成并统一在一起。但这种方法更增添了初始化的难度,因为在该算法中,多种类型模式子集的原型共存,只能用开关回归方法进行分析,因此,基于多类原型模糊聚类的成败几乎全部依赖于初始化。相关研究表明,基于原型的聚类算法求解过程极不稳定,因为目标函数的局部极值点非常多,稍有不慎就会陷入局部极值点 [41-42] ,得不到最优划分。为了解决局部极值问题,随着GA的出现,研究者提出了基于GA的聚类方法,尽管该方法能以较高的概率收敛到全局最优点,但收敛速度较慢,而且还容易出现早熟现象。
针对类别数 c 未知的问题,William等提出采用自组织映射(Self-Organization Feature Mapping,SOFM)神经网络进行聚类 [43] ,虽然能解决预先设定类数问题,但却对多类原型的数据分析却是无能为力。
聚类分析以非监督学习著称,而上述的各种算法显然都需要先验知识。随着AIS方法的兴起,人们又提出利用人工免疫网络进行聚类分析的方法,真正实现了无监督分类,但这种方法仅适合于各样本子集边界清晰的情况,如果各子集间交集非空,就得不到有效的网络结构。
同时作为数据挖掘的一种有力工具,聚类分析常常需要处理大量高维数据集,而且这些数据通常既包含数值也包含类属值。传统的将类属值转化为数值的方法不是总能得到有效的结果,这是因为类属域是无序的。只有很少几种算法能较好地处理混合属性数据聚类问题,例如 k- 原型算法等 [44] ,但这些方法同样要求聚类类别数 c 和聚类原型先验知识。
为了研究具有混合属性特征数据的聚类问题,首先定义一种新的距离测度函数,将不同属性特征相结合,从而达到对具有混合属性特征的数据进行聚类分析的目的。
令 X ={ x 1 , x 2 ,…, x n }表示一组具有 n 个样本的数据集,其中 x i =[ x i 1 , x i 2 ,…, x im ] T 表示第 i 个样本的 m 个特征值。令 k 是一个正整数,那么对 X 进行聚类的目的就是要找到一个最优划分,将 X 分为 k 类。
对于给定的 n 个样本,样本集可能的划分数目是非常巨大的 [37] ,为了找到最好的一个划分,而去逐个研究每一个划分是不切实际的。因此,通常的解决方法是选择一个聚类准则 [37] 来指导搜索划分。下面,定义一个目标函数作为聚类准则。
目前广泛使用的聚类目标函数是类散布矩阵的迹 [40] ,如下所示:
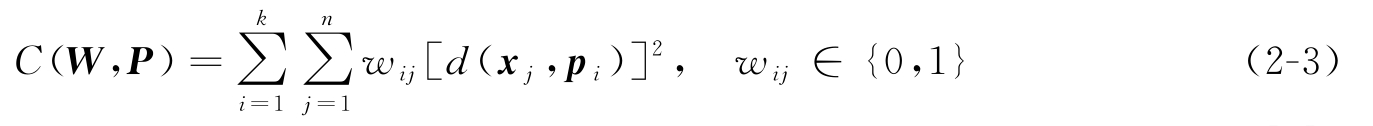
其中,
p
i
=[
p
i
1
,
p
i
2
,…,
p
im
]
T
表示第
i
类的原型;
w
ij
是目标
x
j
属于第
i
类的隶属度
[40]
;
W
是
k
×
n
阶的划分矩阵,且满足概率约束
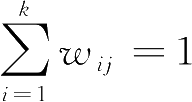 ,∀
j
;
d
(·)是定义为欧几里得距离(Euclidean distance)的相异性测度。对于具有实特征的数据集,即
,∀
j
;
d
(·)是定义为欧几里得距离(Euclidean distance)的相异性测度。对于具有实特征的数据集,即
 ,则有
,则有
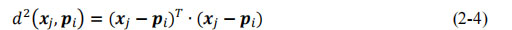
因为 w ij 是样本 x j 属于第 i 类的隶属度当 w ij ∈{0,1}时,称 W 是硬 k- 划分。在硬划分中, w ij =1表示样本 x j 属于第 i 类。
当样本具有数值和类属混合特征时,假设每个样本用表示,混合类型样本 x i 和 x j 之间的相异性测度为:
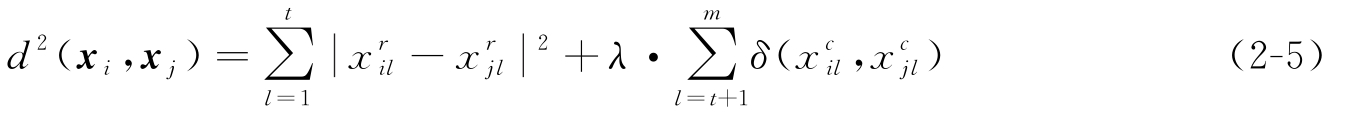
其中,第一项是数值特征上的欧几里得距离的平方;第二项是类属特征上的简单的相异匹配测度,定义为:

权值 λ 用来调节两种特征在目标函数中的比例,以避免偏向任何一种特征。
对于混合类型的目标,可以通过修正式(2-5)来得到新的目标函数。此外,还可将硬 k- 划分扩展为模糊划分,这样对于模糊聚类问题,目标函数将进一步修正为:
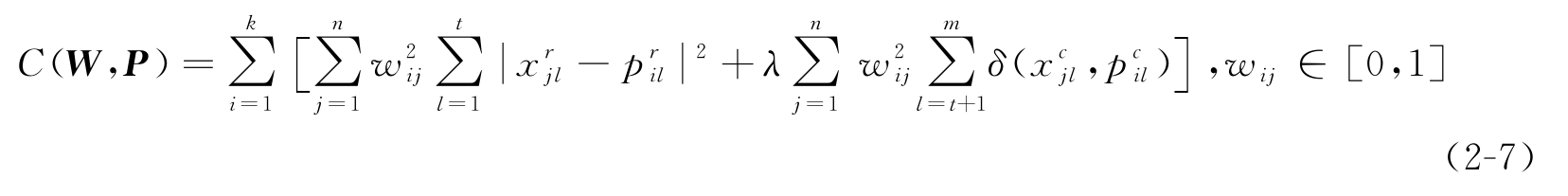
令

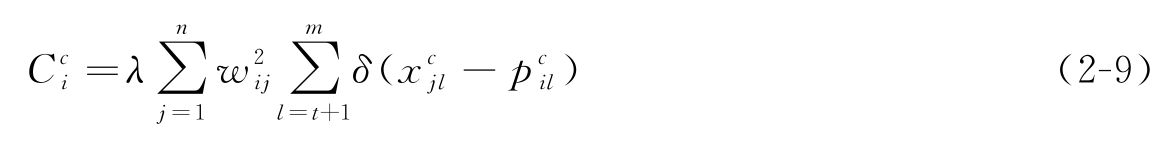
可将式(2-7)重写为:

对具有数值和类属混合特征的数据集进行模糊聚类分析时,式(2-10)就是其目标函数。因为
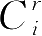 和
和
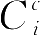 都是非负的,所以可以通过分别极小化
都是非负的,所以可以通过分别极小化
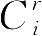 和
和
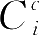 ,来达到极小化的目的。需要指出的是,给
w
ij
加上幂指数2,是为了保证硬划分向模糊划分的扩展是非平凡的。
,来达到极小化的目的。需要指出的是,给
w
ij
加上幂指数2,是为了保证硬划分向模糊划分的扩展是非平凡的。
利用免疫科隆选择算法解决数据集聚类问题,首先需要解决以下3个问题:如何将聚类问题的解编码到抗体中;如何构造抗体-抗原亲和度函数来度量每个抗体对聚类问题的响应程度;如何选择、确定克隆选择操作的参数,以确保快速收敛到最优解。
由式(2-10)定义的聚类目标函数可知,聚类的目标就是要获得数据集 X 的一个模糊划分矩阵 W 和聚类的原型 P 。而 W 和 P 是相关的,即已知其一就可求得另一个的解,所以,在基于CSA的模糊聚类算法中,可令一组聚类原型 P 是一个抗体,这样把原型中的 k 组特征连接起来,根据各自的取值范围,就可以将其量化值(用二进制串表示)编码成一个抗体。
由聚类目标函数定义可知,目标函数越小,则聚类效果越好,而此时抗体-抗原亲和度应该越大。因此借助目标函数来构造抗体-抗原亲和度函数:
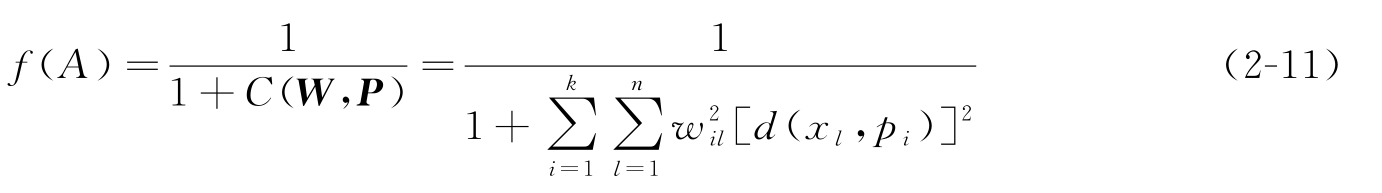
除了克隆算子包括克隆操作、免疫基因操作(克隆重组和克隆变异)以及克隆选择和克隆死亡4个部分以外,在该聚类算法中又定义了一个新的算子:步迭代算子。对于每个抗体,将其解码到聚类原型 P 之后,再进一步迭代算子。一步迭代算子包含以下两个步骤:
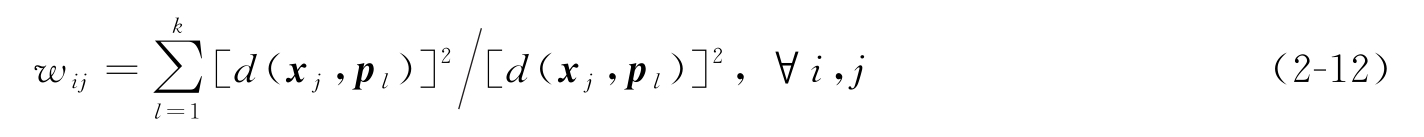
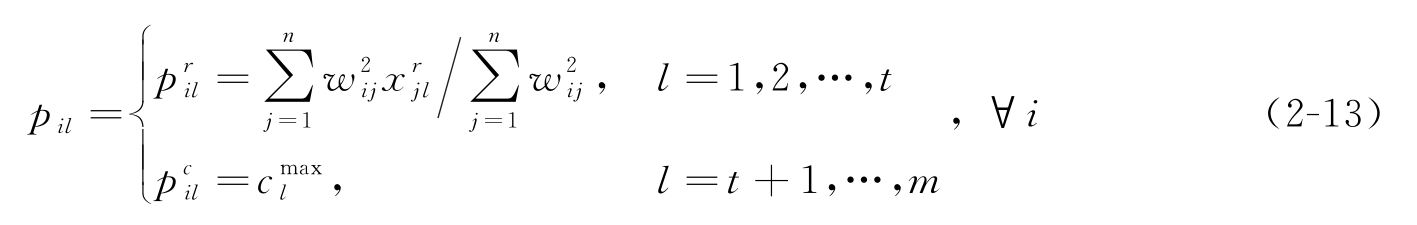
其中,
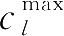 表示属于第
i
类的样本中在第
l
维特征上占优势的类属特征值。克隆获得了新的聚类原型后,再将其编码到抗体中,并重新进行上述克隆算子的操作,直到聚类原型收敛到最优解。
表示属于第
i
类的样本中在第
l
维特征上占优势的类属特征值。克隆获得了新的聚类原型后,再将其编码到抗体中,并重新进行上述克隆算子的操作,直到聚类原型收敛到最优解。
基于免疫克隆选择算法的模糊聚类新算法中的流程可用图2.4表示。
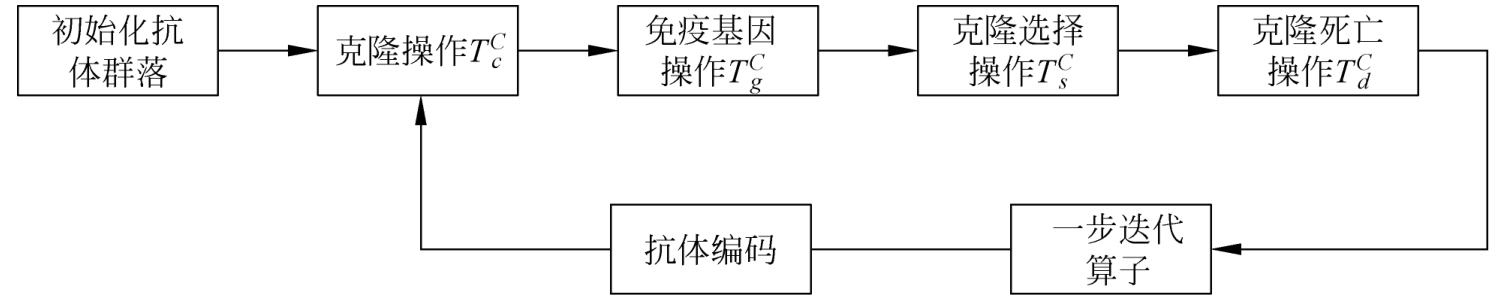
图2.4 基于克隆选择算法的聚类新算法流程框图