
下载掌阅APP,畅读海量书库
立即打开




魔术师和他的搭档表演猜硬币游戏。桌子上任意排列着9枚硬币,这些硬币中有的硬币是正面朝上,有的硬币是反面朝上,这是事先由观众随机调整的,魔术师和搭档都不能随便翻转调整硬币。魔术师被蒙上双眼,所以看不到这9枚硬币的状态。然后,他的搭档从口袋中又取出一枚硬币放置在最后,这样桌子上就凑成了10枚硬币。接下来搭档请台下的观众上台,任意翻转这10枚硬币中的一枚,当然也可以不翻转硬币。最后请魔术师摘下眼罩,魔术师观察这桌上的10枚硬币,便可以说出刚才观众是否翻转了硬币。你知道魔术师是怎样做到的吗?
魔术师是怎样猜出观众是否翻转了硬币的呢?细心的读者一眼就能看出,问题就出在搭档最后放的那枚硬币上。因为从始至终魔术师都是被蒙着眼睛的,不可能了解观众的行为,所以,他的搭档就成为将这些信息传递给魔术师的唯一途径。搭档通过放置额外的一枚硬币“告诉”了魔术师这10枚硬币是否被观众翻转过。我们模拟一个具体的实例,通过图1-6重现整个游戏的过程。
图1-6展示了一个具体实例中魔术师与搭档配合猜硬币的全过程,在第二步中,搭档在9枚硬币之后又放置了一枚硬币,这样魔术师就可以轻而易举地猜出在第三步中观众翻转了硬币,所以,问题的关键就出在最后这枚硬币上。最后这枚硬币究竟要如何放置呢?是正面朝上还是反面朝上呢?这里面有什么讲究没有?
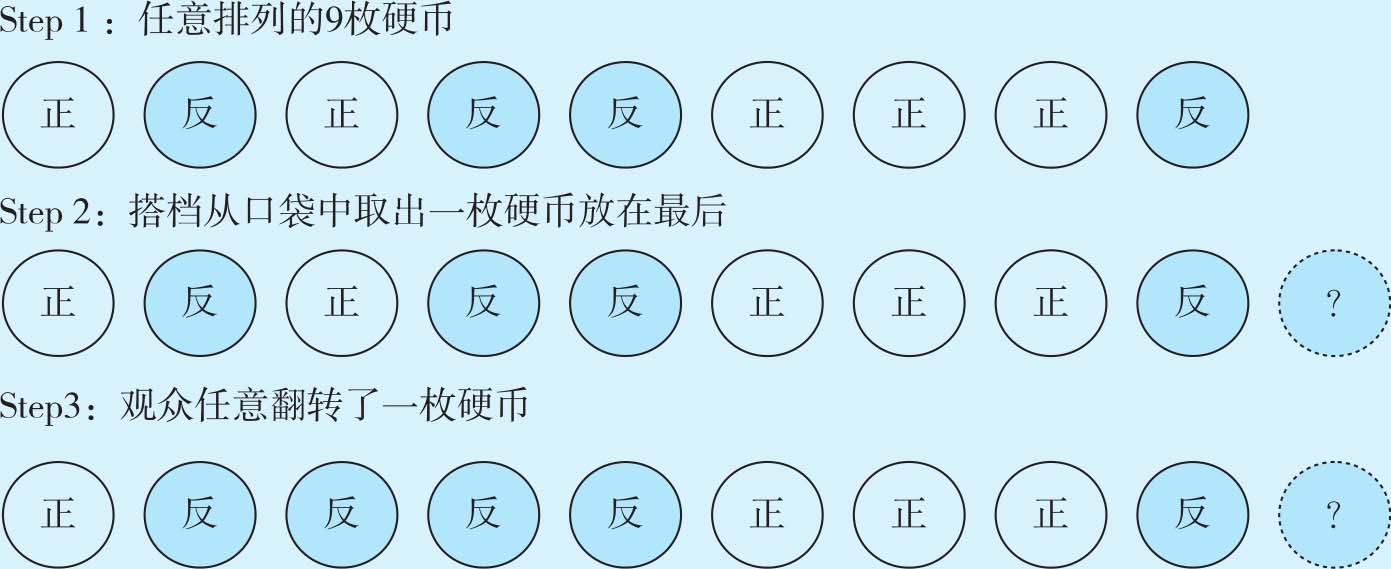
图1-6 重现整个猜硬币游戏的过程
其实,只要魔术师和搭档事先约定“反面(或者正面)的硬币数一定为偶数(或者奇数)”,那么,魔术师每次都可以轻而易举地知道观众是否翻转过硬币。在这里,搭档放置的最后一枚硬币就起了关键的作用。
假设魔术师和他的搭档约定的是“反面的硬币数一定为偶数”,搭档在放置最后一枚硬币之前需要观察前面的9枚硬币中反面朝上的硬币个数。
· 如果为偶数个,则最后这枚硬币要置成正面;
· 如果为奇数个,则最后这枚硬币要置成反面。
这样就确保了桌子上这10枚硬币中反面朝上的硬币个数一定为偶数个。
接下来是观众任意翻转某个硬币,当然观众也可以选择不翻转。因为之前的硬币中反面朝上的硬币的个数为偶数,所以,只要观众翻转了其中任何一枚硬币,反面朝上的硬币数都会变为奇数。这样魔术师只要数一下反面朝上的硬币数是否还是偶数就可以知道观众是否翻转了硬币。
前面已经提到,在整个猜硬币游戏的过程中,搭档放置的最后一枚硬币起到了关键的作用。正是通过最后一枚硬币作为冗余的信息,才使得魔术师可以获取更多的信息量,从而很容易知道是否有硬币被翻转过。不要小看这个简单而巧妙的方法,将它应用到现代通信技术上就是为人们所熟知的“奇偶校验法”(Parity Check)。
现代通信多采用数字通信方式,也就是说信息都是以0/1码的方式在信道中传输的。在信息传输的过程中就难免遇到干扰,而导致发出的一串0/1码信息中的某一位(或者某几位)发生改变。例如,原本希望发送的0/1码数据流为0101001,但由于信号干扰,可能最后的一位发生了跳变而变成了0101000。这样信息就失真了,接收方就无法得到正确的结果。于是,人们便想到在所要传输的0/1码数据流的最后添加一位“校验位”,以此来标识所要传输的数据是否在传输过程中发生了错误。
添加校验位的方法就类似于我们的猜硬币游戏中搭档放置最后一枚硬币,只需在数据流最后添加一位1或者0,使得整个0/1数据流中1的个数为奇数(称之为奇校验)或者1的个数为偶数(称之为偶校验)。至于采用何种校验方式都是事先通信双方约定好的。
如果采用奇校验方式,则添加校验位后0/1数据流中1的个数为奇数。这样接收方在接收到这串数据后就要统计数据流中1的个数是否为奇数,如果是奇数个,则认为这串数据传输无误;如果不是奇数个,则这串数据在传输过程中肯定发生了错误,于是接收方可以向发送方发出错误码(Error Code)信息,要求重新发送这串数据。偶校验的方式跟奇校验类似,只需在接收到数据后判断数据流中1的个数是否为偶数个即可。
采用奇偶校验方法的优点在于简单方便,易于实现,且冗余信息少(只需要1位校验位信息),数据的编码成本和传输成本都非常小。因此在精准度要求不十分高的通信中,采用奇偶校验的方式是非常可行的。但是奇偶校验自身也存在很多缺陷,例如:
· 奇偶校验只能用于检错,而不能用于纠错——使用奇偶校验不能准确定位出错误码的位置,而只能知道是否发生了错误;
· 只能实现奇数位的检错,如果数据流中有偶数个位置都发生了错误,则奇偶校验无法检出是否发生了错误。
因此,为了提高信息通信的容错能力,实现更为安全精准的数据传输,人们发明了许多更加高级的检错、纠错机制,例如,常见的循环冗余校验(Cyclical Redundancy Check)、海明码校验(R.W.Hamming Check)等,这些技术都广泛应用于现代通信、数据存储和信息安全等领域。
在数据的存储和传输过程中很可能会发生错误。产生这些错误的原因有很多,例如:设备的临界工作状态,外界的高频干扰,收发设备中的间歇性故障以及电源偶然的瞬变现象等。这些错误都是随机产生的,并且不可预知,所以无法通过提高设备的性能,增强设备可靠程度来彻底避免错误的发生。要想最大限度地提高系统的可靠性,避免错误的发生,就要在数据编码上寻找出路。
差错控制码就是一种能够避免错误发生,并具有检错纠错能力的编码。不同的差错控制系统需要不同的差错控制码。根据差错控制码的功能,可将常见的差错控制码分为三类。
· 检错码:只能发现错误但不能纠正错误的编码。
· 纠错码:能够发现错误也能纠正错误的编码。
· 纠删码:能够发现并纠正或删除错误的编码。
一般系统中常用的差错控制码主要是检错码和纠错码。检错码与纠错码的不同之处在于,检错码只能根据接收到码的内容得知该码是否在传输或存储中发生了错误,并不能定位该错误发生在哪一(几)位上,因此,它是一种比较低端的差错控制码。我们前面讲到的奇偶校验码就是一种最常用的检错码。而纠错码不但可以检测出该码是否在传输或存储中发生了错误,而且还能通过计算得出错误发生的位置,并加以纠正。因此,纠错码在实际使用中较为广泛,且实用性更强。在分类上,纠错码可以按照不同的方式进行分类。如图1-7所示,其中使用较多的纠错码是线性分组码。目前较为常见的线性分组码主要有海明码、CRC码(循环冗余校验码)、BCH码、RS码(里德-索洛蒙码)、戈帕码等。这些纠错产生的理论不同,编码和译码的方法也不同,因此,纠错能力和编码性能也不尽相同。
差错控制码是信息论和系统容错技术研究的一个重要分支,里面涉及到很深的数学理论,因此在这里只做概要性的介绍,有兴趣进一步了解差错控制码及其相关技术的读者可以参考《信息论》《现代编码理论》等书籍。
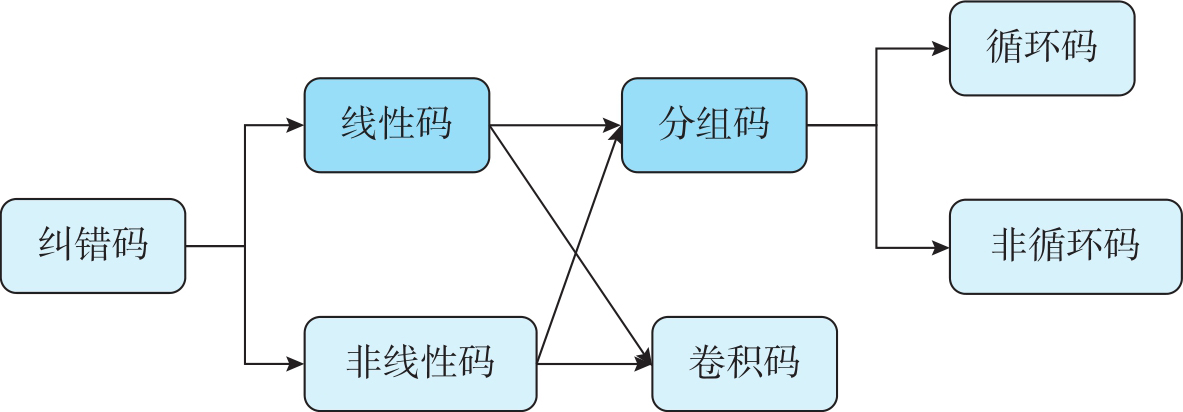
图1-7 纠错码的分类