
下载掌阅APP,畅读海量书库
立即打开



人工智能的浪潮正在席卷全球,这也使得人们对人工智能的认知程度日益提升。无论是IT行业革新,还是传统产业转型,人工智能的蓬勃发展都将充当有力推手,并为行业赋能和发展提供坚实基础。为了帮助读者更好地理解人工智能的发展及现状,并逐步过渡到联邦学习技术范式,本节简要介绍人工智能的由来和机器学习中的数据问题。
人工智能正在革新许多行业,它模拟和扩充人类工作的方式,代替人类执行复杂的工作流程。人工智能的目标是将智能编程到机器中,从经验中不断学习,并通过对环境变化的感知来模拟人类的决策和推理。
人工智能可以分为弱人工智能和强人工智能。弱人工智能即现在所有AI可以达到的程度,它仅能执行一项或多项特定的任务,对该任务以外的其他事项基本无能为力。例如,AlphaGo被设计出来专门下围棋,但是如果将它用于其他棋种,哪怕是下象棋它也无能为力。比起“智能”,弱人工智能更多地依靠统计学原理和基本的推理知识,寻找高维空间中输入与输出之间的联系。相较于弱人工智能,强人工智能被认为拥有“意识”,它可以模拟人类的智能化行为,并具有学习与应用知识以解决问题的能力,它可以在给定的条件下像人类一样思考、理解与行动。一般来说,强人工智能被认为是难以实现的。而目前人们所提及的人工智能,一般指的是弱人工智能,且在很大程度上专指机器学习、深度学习等。
20世纪40年代至50年代,来自各个领域(数学、心理学、工程学、经济学和政治科学等)的少数科学家开始讨论创建人造大脑的可能性,这成为人工智能领域研究的开端。1950年,艾伦·麦席森·图灵(Alan Mathison Turing)发表了一篇具有里程碑意义的论文,其中提出了著名的图灵测试:如果一台机器可以进行与人的对话,并且相较于人与人之间的对话没有区别,那么可以说该机器在“思考”。图灵测试被认为是检验机器是否具有智能的方法。1956年,达特茅斯会议提出进行人工智能方面的研究,并使用“人工智能”作为这一领域的名称,因此人们也广泛认为,这次会议标志着人工智能的诞生。
20世纪50年代至70年代,人工智能出现了许多探索性的研究方向和成果。例如,搜索推理算法就是一种早期人工智能程序普遍使用的基础算法。为了实现某个目标(如赢得游戏或证明定理),该算法通过演绎一步步地朝着目标前进,就像在迷宫中搜索一样,一旦到达死胡同就“回头”。沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)深入研究了大脑如何使用被称为神经元的相互连接的基本细胞,并由此提出了麦卡洛克—皮茨模型 [1] ,即MCP模型,该模型为人工神经网络的发展作出了重要贡献。然而,在20世纪70年代,人工智能的发展遇到了瓶颈,针对人工智能的研究出现了严重限制,而这些限制在当时是无法被克服的。
第一,当时计算机的能力是有限的,只能完成非常简单的任务,没有足够的内存或处理速度来解决任何真正有价值的问题,比如现在AlphaGo能完成的下棋任务在当时的情况下是不可能的。第二,理查德·卡普(Richard Karp)通过定理证明,许多问题可能只能在输入规模的指数时间内解决 [2] 。也就是说,除非问题的输入规模很小,否则要找到这些问题的最佳解决方案,需要花费大量的计算时间。第三,视觉或自然语言等许多重要的人工智能应用程序倚赖大量的数据信息,而在20世纪70年代没有人可以建立如此庞大的数据库,也没人知道一个程序如何学习这么多的信息。因此,人工智能领域进入了第一个“寒冬”。
从20世纪80年代开始,人工智能的发展出现转机。1982年,物理学家约翰·霍普菲尔德(John Hopfield)证明了某种形式的神经网络(通常称为霍普菲尔德网)可以以全新的方式学习和处理信息 [3] 。大约在同一时间,杰弗里·辛顿(Geoffrey Hinton)和大卫·鲁姆哈特(David Rumelhart)普及了一种训练神经网络的方法,称为反向传播 [4] 。这两个发现重启了神经网络的相关研究。朱迪亚·珀尔(Judea Pearl)于1988年将概率和决策理论引入了人工智能 [5] 。贝叶斯网络、隐马尔可夫模型、信息理论、随机建模和经典优化成为了人工智能使用的新工具。同时,诸如神经网络和进化算法之类的“计算智能”范式也开启了精确的数学描述。
在21世纪的前几十年中,更容易获取、访问和存储的大量数据,高性能计算机,先进的机器学习和深度学习技术的出现和广泛应用,推动着人工智能逐步进入黄金发展期。
机器学习作为实现人工智能的重要技术方法得到了越来越广泛的应用,它是从聚合后的大数据中学习数据特征并形成模型,进而完成回归、分类等任务。但在实际应用中,数据通常无法进行有效聚合,存在严重的“数据孤岛”问题。本小节介绍机器学习的定义与分类,讨论机器学习中的数据问题。
机器学习算法 [6] 是根据经验自动学习和提升的计算机算法,它被视为人工智能的子集。机器学习算法会基于样本数据(又称训练数据)建立数学模型,以便后续进行推断或预测。
在20世纪90年代,机器学习作为一个单独的领域开始蓬勃发展,该领域的目标从实现人工智能转变为解决实际问题。同时,相对于当时所提及的人工智能,它将焦点转移到基于统计和概率论的方法和模型上。
一般来说,机器学习方法根据系统输入信号是否具有反馈分为3大类。
(1)有监督学习。这种学习方法向计算机提供示例输入及其期望的输出(通常被称为标签),目标是学习将输入映射到输出的一般规则。
(2)无监督学习。这种学习方法没有为学习算法提供标签,仅靠学习算法即可寻找输入中的关系。无监督学习本身可以是目标(如发现数据中的隐藏模式),也可以是达到目的的手段(特征学习)。此外,无监督学习中的一个重要技术——自监督学习(Self-Supervised Learning,SSL)也发展迅猛,区别于传统的无监督学习方法,主要是希望能够学习到一种通用的特征表达,用于下游任务。其主要的方式就是通过自己监督自己,例如把一段话里面的几个单词去掉,通过上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的部分。
(3)强化学习。计算机程序与动态环境进行交互,在特定环境中,计算机为了达到特定的目标(如驾驶车辆或与对手玩游戏),持续执行动作与环境交互,并从环境中获得奖励,就是强化学习。强化学习的优化目标是将奖励最大化。
机器学习基于概率论和统计学的理论,其模型将使用数据和算法不断地进行迭代改进,而模型的性能与数据的关系非常密切。第一,数据量是很重要的,这也是机器学习往往与大数据一词相联系的原因,我们需要“足够”的数据来捕获输入和输出变量之间的关系。图1-1 [7] 展示了不同类型算法的性能与训练数据量的关系,可以看到的是,在模型训练的过程中,性能提升通常与数据量级呈正相关。第二,为了使这些模型有效运行,需要有高质量的数据。例如,为了进行模型训练,需要对原始数据进行去重、降噪、打标签等预处理操作。与建立模型所需的训练工作相比,这项工作同样艰巨。
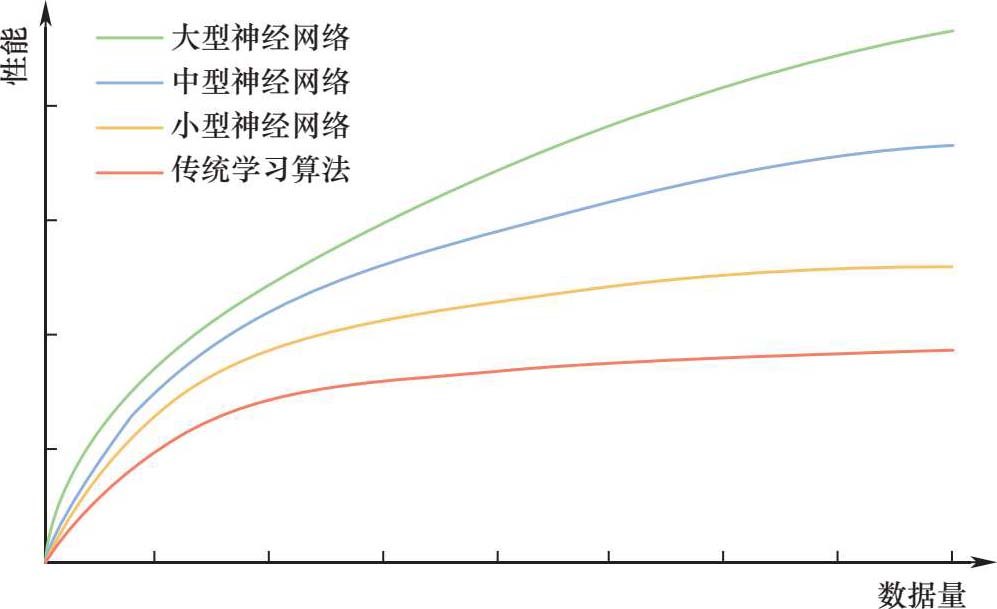
图1-1 不同类型算法的性能与训练数据量的关系