
下载掌阅APP,畅读海量书库
立即打开



人工智能的浪潮正在席卷全球,这也使得人们对人工智能的认知程度日益提升。无论是IT行业革新,还是传统产业转型,人工智能的蓬勃发展都将充当有力推手,并为行业赋能和发展提供坚实基础。为了帮助读者更好地理解人工智能的发展及现状,并逐步过渡到联邦学习技术范式,本节简要介绍人工智能的由来和机器学习中的数据问题。
人工智能正在革新许多行业,它模拟和扩充人类工作的方式,代替人类执行复杂的工作流程。人工智能的目标是将智能编程到机器中,从经验中不断学习,并通过对环境变化的感知来模拟人类的决策和推理。
人工智能可以分为弱人工智能和强人工智能。弱人工智能即现在所有AI可以达到的程度,它仅能执行一项或多项特定的任务,对该任务以外的其他事项基本无能为力。例如,AlphaGo被设计出来专门下围棋,但是如果将它用于其他棋种,哪怕是下象棋它也无能为力。比起“智能”,弱人工智能更多地依靠统计学原理和基本的推理知识,寻找高维空间中输入与输出之间的联系。相较于弱人工智能,强人工智能被认为拥有“意识”,它可以模拟人类的智能化行为,并具有学习与应用知识以解决问题的能力,它可以在给定的条件下像人类一样思考、理解与行动。一般来说,强人工智能被认为是难以实现的。而目前人们所提及的人工智能,一般指的是弱人工智能,且在很大程度上专指机器学习、深度学习等。
20世纪40年代至50年代,来自各个领域(数学、心理学、工程学、经济学和政治科学等)的少数科学家开始讨论创建人造大脑的可能性,这成为人工智能领域研究的开端。1950年,艾伦·麦席森·图灵(Alan Mathison Turing)发表了一篇具有里程碑意义的论文,其中提出了著名的图灵测试:如果一台机器可以进行与人的对话,并且相较于人与人之间的对话没有区别,那么可以说该机器在“思考”。图灵测试被认为是检验机器是否具有智能的方法。1956年,达特茅斯会议提出进行人工智能方面的研究,并使用“人工智能”作为这一领域的名称,因此人们也广泛认为,这次会议标志着人工智能的诞生。
20世纪50年代至70年代,人工智能出现了许多探索性的研究方向和成果。例如,搜索推理算法就是一种早期人工智能程序普遍使用的基础算法。为了实现某个目标(如赢得游戏或证明定理),该算法通过演绎一步步地朝着目标前进,就像在迷宫中搜索一样,一旦到达死胡同就“回头”。沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)深入研究了大脑如何使用被称为神经元的相互连接的基本细胞,并由此提出了麦卡洛克—皮茨模型 [1] ,即MCP模型,该模型为人工神经网络的发展作出了重要贡献。然而,在20世纪70年代,人工智能的发展遇到了瓶颈,针对人工智能的研究出现了严重限制,而这些限制在当时是无法被克服的。
第一,当时计算机的能力是有限的,只能完成非常简单的任务,没有足够的内存或处理速度来解决任何真正有价值的问题,比如现在AlphaGo能完成的下棋任务在当时的情况下是不可能的。第二,理查德·卡普(Richard Karp)通过定理证明,许多问题可能只能在输入规模的指数时间内解决 [2] 。也就是说,除非问题的输入规模很小,否则要找到这些问题的最佳解决方案,需要花费大量的计算时间。第三,视觉或自然语言等许多重要的人工智能应用程序倚赖大量的数据信息,而在20世纪70年代没有人可以建立如此庞大的数据库,也没人知道一个程序如何学习这么多的信息。因此,人工智能领域进入了第一个“寒冬”。
从20世纪80年代开始,人工智能的发展出现转机。1982年,物理学家约翰·霍普菲尔德(John Hopfield)证明了某种形式的神经网络(通常称为霍普菲尔德网)可以以全新的方式学习和处理信息 [3] 。大约在同一时间,杰弗里·辛顿(Geoffrey Hinton)和大卫·鲁姆哈特(David Rumelhart)普及了一种训练神经网络的方法,称为反向传播 [4] 。这两个发现重启了神经网络的相关研究。朱迪亚·珀尔(Judea Pearl)于1988年将概率和决策理论引入了人工智能 [5] 。贝叶斯网络、隐马尔可夫模型、信息理论、随机建模和经典优化成为了人工智能使用的新工具。同时,诸如神经网络和进化算法之类的“计算智能”范式也开启了精确的数学描述。
在21世纪的前几十年中,更容易获取、访问和存储的大量数据,高性能计算机,先进的机器学习和深度学习技术的出现和广泛应用,推动着人工智能逐步进入黄金发展期。
机器学习作为实现人工智能的重要技术方法得到了越来越广泛的应用,它是从聚合后的大数据中学习数据特征并形成模型,进而完成回归、分类等任务。但在实际应用中,数据通常无法进行有效聚合,存在严重的“数据孤岛”问题。本小节介绍机器学习的定义与分类,讨论机器学习中的数据问题。
机器学习算法 [6] 是根据经验自动学习和提升的计算机算法,它被视为人工智能的子集。机器学习算法会基于样本数据(又称训练数据)建立数学模型,以便后续进行推断或预测。
在20世纪90年代,机器学习作为一个单独的领域开始蓬勃发展,该领域的目标从实现人工智能转变为解决实际问题。同时,相对于当时所提及的人工智能,它将焦点转移到基于统计和概率论的方法和模型上。
一般来说,机器学习方法根据系统输入信号是否具有反馈分为3大类。
(1)有监督学习。这种学习方法向计算机提供示例输入及其期望的输出(通常被称为标签),目标是学习将输入映射到输出的一般规则。
(2)无监督学习。这种学习方法没有为学习算法提供标签,仅靠学习算法即可寻找输入中的关系。无监督学习本身可以是目标(如发现数据中的隐藏模式),也可以是达到目的的手段(特征学习)。此外,无监督学习中的一个重要技术——自监督学习(Self-Supervised Learning,SSL)也发展迅猛,区别于传统的无监督学习方法,主要是希望能够学习到一种通用的特征表达,用于下游任务。其主要的方式就是通过自己监督自己,例如把一段话里面的几个单词去掉,通过上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的部分。
(3)强化学习。计算机程序与动态环境进行交互,在特定环境中,计算机为了达到特定的目标(如驾驶车辆或与对手玩游戏),持续执行动作与环境交互,并从环境中获得奖励,就是强化学习。强化学习的优化目标是将奖励最大化。
机器学习基于概率论和统计学的理论,其模型将使用数据和算法不断地进行迭代改进,而模型的性能与数据的关系非常密切。第一,数据量是很重要的,这也是机器学习往往与大数据一词相联系的原因,我们需要“足够”的数据来捕获输入和输出变量之间的关系。图1-1 [7] 展示了不同类型算法的性能与训练数据量的关系,可以看到的是,在模型训练的过程中,性能提升通常与数据量级呈正相关。第二,为了使这些模型有效运行,需要有高质量的数据。例如,为了进行模型训练,需要对原始数据进行去重、降噪、打标签等预处理操作。与建立模型所需的训练工作相比,这项工作同样艰巨。
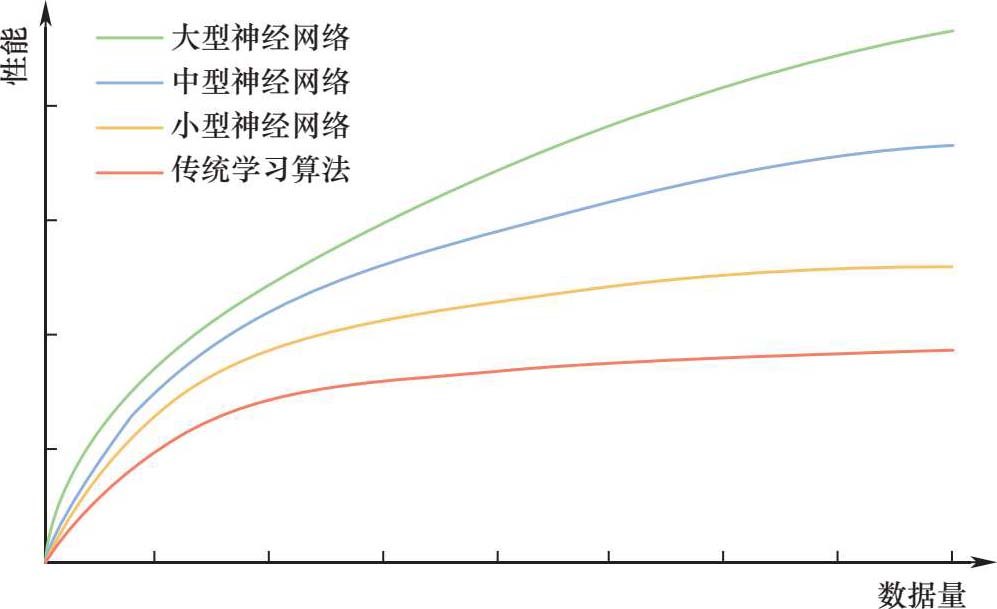
图1-1 不同类型算法的性能与训练数据量的关系
数据作为人工智能技术发展的“原料”,其重要价值不言而喻,但由它引发的一系列关于数据安全和隐私保护的担忧,让人们对数据安全问题变得愈发重视,如何在应用过程中保护用户数据隐私、防止信息泄露已经成为新的挑战。本节介绍隐私保护问题,以及常见的隐私攻击方式与保护技术。
基于云计算、大数据、人工智能新技术的多种应用(如智能音箱、可穿戴设备、AR/VR眼镜和无人驾驶汽车)可以提供一系列服务,这些设备会收集有关个人特定状况的隐私信息,并依据这些信息执行智能算法、发出命令。
令人不安的是,绝大多数的消费用户无法掌握他们的哪些信息被收集了,以及被谁收集了。他们正面临着一个深刻的矛盾,是享受智能设备的便捷,还是坚持日常活动中对隐私的严格控制。美国“棱镜门”、脸书(Facebook)用户数据泄露等层出不穷的互联网隐私泄露事件更加剧了用户对使用人工智能时隐私保护问题的担忧。
现在,隐私保护愈发受到国内外的重视和关注,许多政府、行业协会和非政府组织都参与了数字隐私保护的讨论。美国提出的消费者隐私权利法案,建立在公平信息实践原则(Fair Information Practice Principles,FIPPs)的基础上 [8] ,解决了私营部门实体应该如何处理个人数据的问题。该法案对公司收集和保留的个人数据进行合理限制,消费者有权对公司从他们那里收集的数据,以及他们如何使用这些数据行使控制权。类似的,欧盟针对可穿戴设备的隐私保护建议强调,隐私政策应具体说明收集什么数据,以及如何收集、存储、使用、保护和披露数据。2017年6月起施行的《中华人民共和国网络安全法》第42条指出,“网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息”。2018年3月,欧盟的GDPR正式生效,该条例对企业处理用户数据的行为提出了明确要求,企业在用户不知情时进行数据收集、共享与分析已被视为一种违法行为。
在这样的背景之下,对于机器学习而言,隐私问题主要表现在以下两个方面。
(1)因数据收集和数据分享导致的隐私泄露。第一,不可靠的数据收集者可能在未经人们许可的情况下擅自收集个人信息、非法进行数据共享和交易等。第二,拥有敏感数据的机构和企业为了构建性能更好的模型而相互交换数据,而这样的方式本身就存在隐私泄露的风险,违背了相关法律法规和市场监管的要求。
(2)模型在训练、推理过程中因受外部恶意攻击导致的间接隐私泄露。恶意的数据窃取者通过与模型进行交互等多种方式会逆向推理出未知训练数据中的个体敏感属性,即隐私保护的相关攻击。
在与隐私相关的攻击中,对手的目标是获取非预期共享的有关知识,例如关于训练数据的知识或关于模型的信息,更有甚者可以提取到有关数据属性的信息。隐私保护的攻击可以分为4种类型:成员推理攻击、重构攻击、属性推理攻击和模型提取攻击。
成员推理攻击会试图推测输入样本x是否在模型训练的数据集之中,这是最流行的攻击方式之一。有监督的机器学习模型、生成模型,如生成式对抗网络(Generative Adver sarial Network,GAN)和变分自编码器(Variational Auto-Encoder,VAE)容易受到该攻击 [9] 。在某些场景下,成员推理攻击可能造成严重的后果,例如对于由艾滋病患者数据构建的诊断模型,若某人的医疗数据被推断是该模型的训练数据,便意味着此人可能患有艾滋病。
重构攻击试图重新创建一个或多个训练样本及标签,这些重建可以是针对部分数据的,也可以是针对全部的。一般来说,重构攻击是利用给定的输出标签和某些特征的部分知识,使用属性推断或模型反演等方式,试图恢复敏感特征或整个数据样本。
另外,虽然不是针对机器学习模型,“重构攻击”一词也被用于描述利用公开可访问数据推断目标用户敏感属性的攻击。例如,攻击方查询了所有学号对应同学的身高和,之后又查询了除了学号1同学以外所有同学的身高和,两次公开数据相减就得到了学号1同学的身高隐私数据。
获取与学习任务不相关的数据集本身的统计属性信息,并试图凭此恢复敏感特征的行为,称为属性推理攻击。属性推理攻击的一个例子是,当性别不是某患者数据集的编码属性或标签时,提取该数据集中男女比例的信息。在某些情况下,这些信息的泄露可能涉及隐私,同时这些属性还可能暴露更多关于训练数据的信息,从而可能导致对手使用这些信息创建类似的模型。
模型提取攻击是一种黑盒攻击,攻击对手方试图提取信息,并有可能完全重建模型或创建一个非常类似于原模型的替代模型 [10] 。创建替代模型的依据是输入一些与测试集数据分布相关的学习任务,又或者其输入点不一定与学习任务相关。前者被称为任务精度提取,而后者被称为保真度提取。在前一种情况下,对手感兴趣的是创建一个替代对象,这个替代对象能同样或更好地学习与目标模型相同的任务;在后一种情况下,对手的目标是创建一个尽可能忠实地还原模型的决策边界的替代品。
模型提取攻击可以作为进行其他类型攻击的铺垫,如对抗性攻击或隶属关系推断攻击。在这两种情况下,都假定对手希望尽可能高效完成攻击任务,即使用尽可能少的查询。因此,创建一个与被攻击模型具有相同或更高复杂度的替代模型是必要的。
除了创建替代模型,还有一些攻击专注于从目标模型中恢复信息,如恢复目标函数中的超参数,或关于各种神经网络结构属性的信息,如函数激活类型、优化算法、层数等。
有大量的研究致力于在不暴露敏感数据的情况下改进学习模型,而常见的针对机器学习的隐私保护技术主要可以分为两大类:第一类是若干基于密码学的方式,常用的有安全多方计算(Secure Multi-party Computation,SMC)、同态加密(Homomorphic Encryp tion,HE)等;第二类则对原始数据制造扰动,即向数据中添加随机的噪声,使输出结果与真实结果具有一定程度的偏差,如差分隐私机制。
安全多方计算起源于姚期智院士在1982年提出的百万富翁问题 [11] ,其目的是解决一组不可信用户之间协同计算时保护隐私的问题。安全多方计算需要确保输入、计算的独立性与准确性,即不会将输入值泄露给参与计算的其他成员,独立、准确地完成计算。
然而,直接在神经网络训练中使用安全多方计算具有一定的困难。例如,如果使用基于混淆电路的安全多方计算技术,在训练过程中计算Sigmoid或Softmax等非线性激活函数的代价较大。此外,混淆电路适用于两方或者三方安全计算,不容易扩展到有更多用户的协作环境。因此,研究人员致力于探讨如何在机器学习模型训练中使用安全多方计算。例如,有研究提出了一个用于隐私保护训练的双服务器模型,用户将他们的数据分割成两个独立的副本,并将它们发送到两台不同的服务器,两台服务器使用安全的双方计算(2PC)来训练神经网络和其他机器学习模型。因此,在训练过程中,两台服务器都无法查看用户的完整数据。
同态加密是一种对数据进行加密的方法,并可以在不解密数据的情况下对其执行某些操作,执行的结果解密之后与原始数据执行同样操作的结果相同,这是因为同态加密机制在计算时保留了一些原始的消息空间结构。
在协作场景的机器学习训练中应用同态加密时,每个用户首先使用系统公钥加密自己的本地数据,然后将密文上传到服务器。服务器用密文执行与学习过程相关的大部分操作,并将加密的结果返回给用户。在这个过程中,服务器不知道用户的数据,用户也不知道服务器的模型。
差分隐私最初由C. Dwork提出,该方法将随机噪声注入由原始敏感数据计算的统计结果中,当替换或删除原始数据集中的单个记录时,并不会影响输出结果的概率分布,这一定程度上避免了攻击者通过捕捉输出差异进而推测个体记录的敏感属性值。形式上,差分隐私的定义 [12] 如下:
定义 对任意的数据集 D 1 和 D 2 , D 1 、 D 2 ⊆ D ,即 D 1 、 D 2 是非单个元素的子集,给定随机算法 f : D → R 和任意的输出结果 S ⊆ R ,若不等式
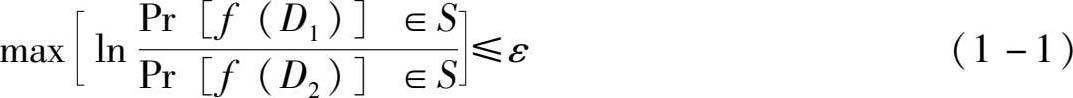
成立,即通过特定构造数据集执行随机算法得到无法区分这两个数据集的结果,则称算法 f 满足 ε 差分隐私。
差分隐私机制将算法的隐私损失控制在一个有限的范围内, ε 越小,则算法的隐私保护效果越好。常用的差分隐私算法有拉普拉斯机制、指数机制和高斯机制。