
下载掌阅APP,畅读海量书库
立即打开



FedAvg算法 [15] 是对FedSGD算法的改进。在FedSGD算法中,各参与方在每轮通信前只对各自的局部模型参数进行一次梯度下降,参数更新频率很低,导致各参与方的模型训练不充分,从而对全局模型的性能带来影响。FedAvg算法对所有参与方模型参数的更新更加充分,主要是在每轮模型训练中,通过多个训练轮数和多个批次增加对局部模型参数的更新次数,从而提升全局模型的性能。
FeAvg算法的框架如图3-2所示,参数及含义见表3-2。
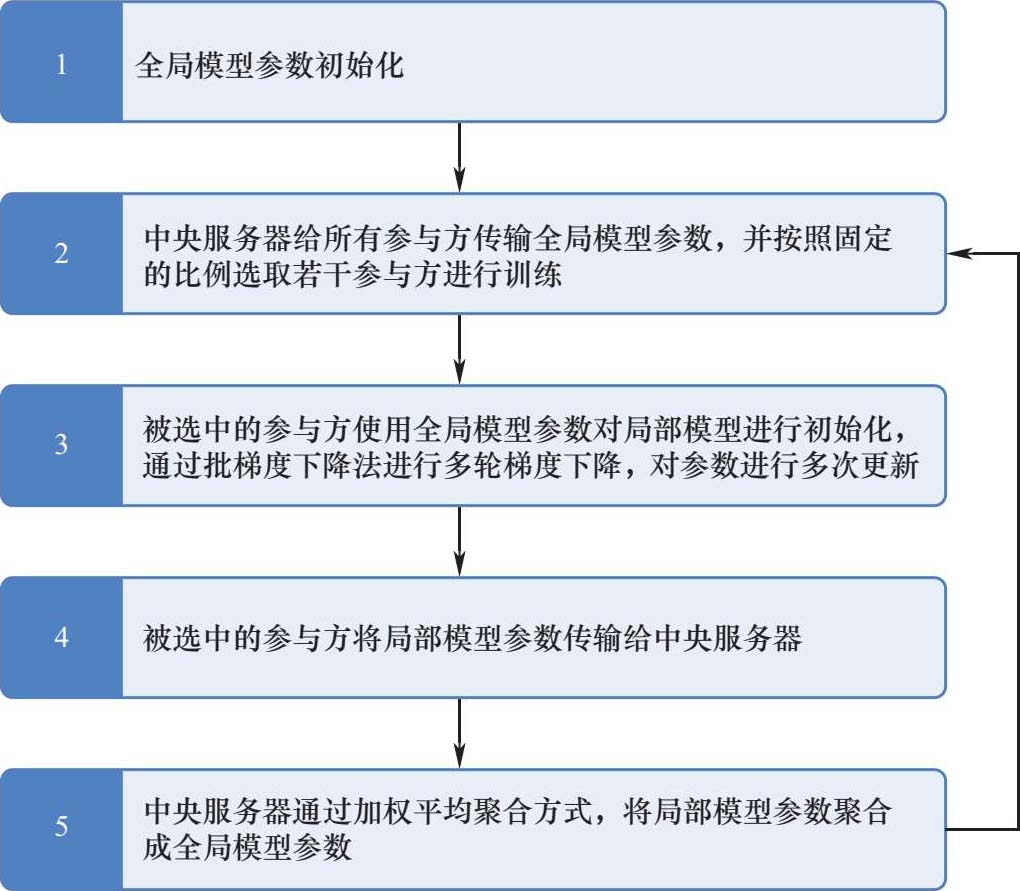
图3-2 FedAvg算法的框架
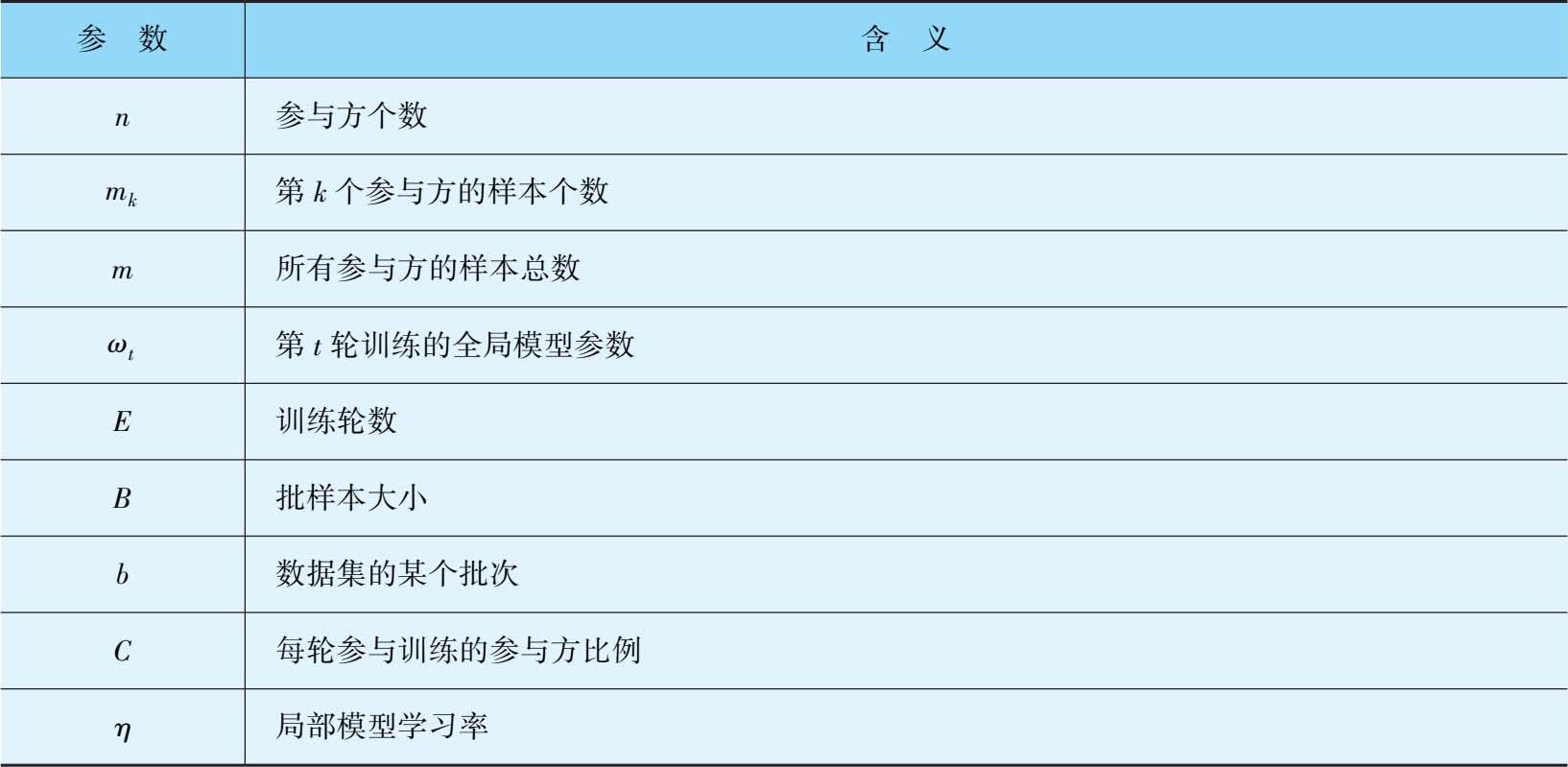
表3-2 FedAvg算法的参数及含义
记联邦学习中参与方 k ( k =1,2,…, n )的目标函数为

其中, B 是批样本大小(Batch Size); b ∈ P k ,是参与方 k 的数据索引集 P k 中由 B 个样本组成的一个批次; f i ( ω )是样本( x i , y i )在参数 ω 下的目标值,一般取 f i ( ω )= l ( x i , y i ; ω )为某个损失函数,表示样本( x i , y i )在参数 ω 下的损失函数值。
记联邦学习的总目标函数为

其中,
m
k
=|
P
k
|,是参与方
k
的数据索引集的大小;
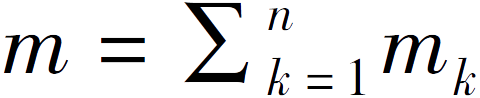 ,是所有参与方的数据集的总样本个数。
,是所有参与方的数据集的总样本个数。
FedAvg算法的流程如算法流程3-2所示。
输入 :全局模型参数初始值 ω 0 ,参与方个数 n ,批样本大小 B ,训练轮数 E ,参与方比例 C ,局部模型学习率 η ,各参与方的样本个数 m k 。
输出 :最后一次迭代的全局模型参数 ω t +1 。
1.中央服务器初始化全局模型参数 ω 0 ,并传输给所有参与方。
2.对 t =0,1,2,…,迭代以下步骤直到全局模型参数 ω t +1 收敛。
(1)中央服务器根据参与方比例 C ∈(0,1],计算参与第 t 轮迭代的参与方个数:
m ←max( C × n ,1)
(2)中央服务器随机选取 m 个参与方,构成参与方集合 S t 。
(3)对∀ k ∈ S t ,通过以下步骤更新局部模型参数:
①使用接收到的模型参数
ω
t
进行模型初始化
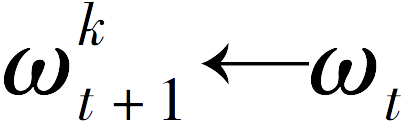 。
。
②将数据索引集 P k 按照批样本大小 B 分为若干个批次,记由这些批次构成的集合为 B k 。
对每次训练 j =1,…, E ,使用∀ b ∈ B k ,更新局部模型参数:
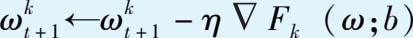
将更新好的局部模型参数
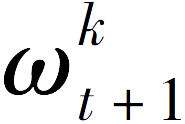 传输给中央服务器。
传输给中央服务器。
(4)中央服务器聚合所有参数
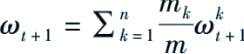 并传输回所有参与方。
并传输回所有参与方。
当训练轮数 E =1,且批样本大小 B 是对应的参与方的总样本个数时,FedAvg算法退化为FedSGD算法。