
下载掌阅APP,畅读海量书库
立即打开



具有中央服务器的联邦学习流程大致如下。
(1)模型参数分发:中央服务器将初始模型参数分发给各参与方。
(2)本地模型更新:参与方收到新模型参数,将其加入到本地训练中。
(3)全局更新:参与方将本地更新的模型发送到中央服务器,服务器按照一定的规则聚合,更新当前的全局模型。
(4)收敛判停:在所训练的模型达到收敛条件、迭代次数或者训练时间时,停止训练模型。
由于参与联合训练的数据集不同,联邦学习可以分为横向联邦学习、纵向联邦学习与联邦迁移学习3类。此外,联邦强化学习为提高效率提供了新思路。下面简要介绍这4种联邦学习。
横向联邦学习以数据的特征维度为对齐导向,取出参与方数据特征相同而用户不完全相同的部分进行联合训练。如图2-3所示,各参与方拥有不同客户的数据,这些数据具有较多重叠的特征。例如,两家不同的电商企业,他们拥有不同用户,因此样本空间不同;然而由于业务相似性,两方数据特征类似。这种情况下,在进行联合训练时就可以采用横向联邦学习技术。横向联邦学习的过程如下:
(1)中央服务器分发模型给各参与方;
(2)各参与方利用本地数据集分别训练,采用差分隐私、同态加密等技术对模型参数加密后,上传至中央服务器;
(3)中央服务器对所获得的信息进行安全聚合,并反馈给各参与方;
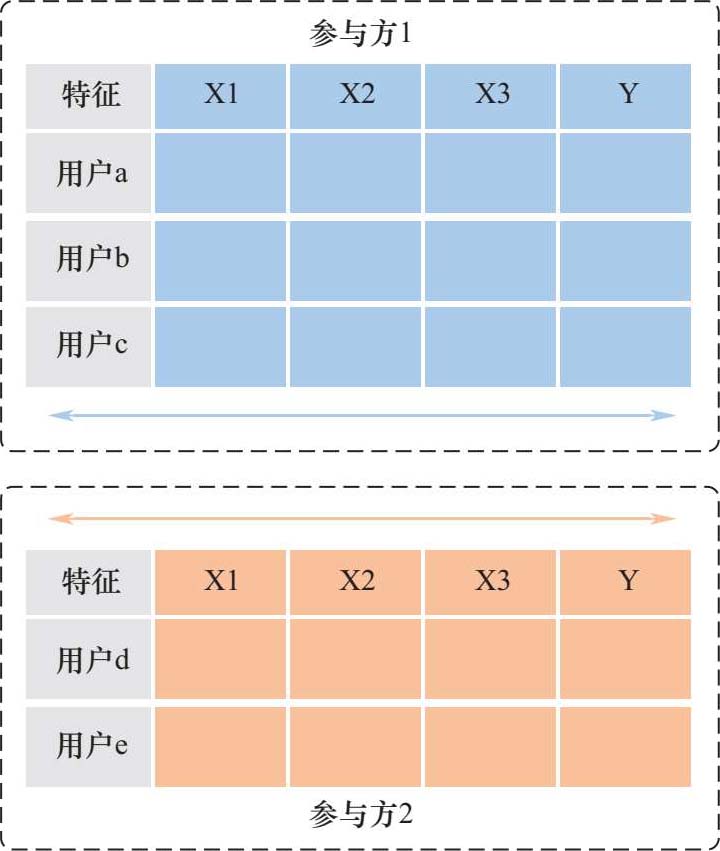
图2-3 横向联邦学习图解
(4)各参与方对收到的参数解密,并更新本地模型。
横向联邦学习通过扩大样本空间来提高模型的精准度,参与方维护相同且完整的模型,可以独立进行预测。同时,横向联邦学习采用的加密技术保证了参与方本地数据的安全和隐私性。
纵向联邦学习是以共同用户为数据的对齐导向,取出参与方用户相同而特征不完全相同的部分进行联合训练。如图2-4所示,参与方数据集中样本空间重叠较多,但是特征空间交集较小。例如,同在一区的公安局与民政局,两者数据集样本空间均包含当地居民,然而其中各居民的特征值不同,在这种情况下采用纵向联邦学习技术,可以在更多的特征维度下建立共享的机器学习模型。由于样本空间的重叠,在联合训练之前,纵向联邦学习需要进行样本对齐操作。样本对齐是指参与方对齐加密后的样本ID,获得样本重叠部分。之后的联合训练基于此重叠部分进行。为了保护各参与方非交叉的数据,样本对齐操作在系统级进行。纵向联邦学习的过程如下:
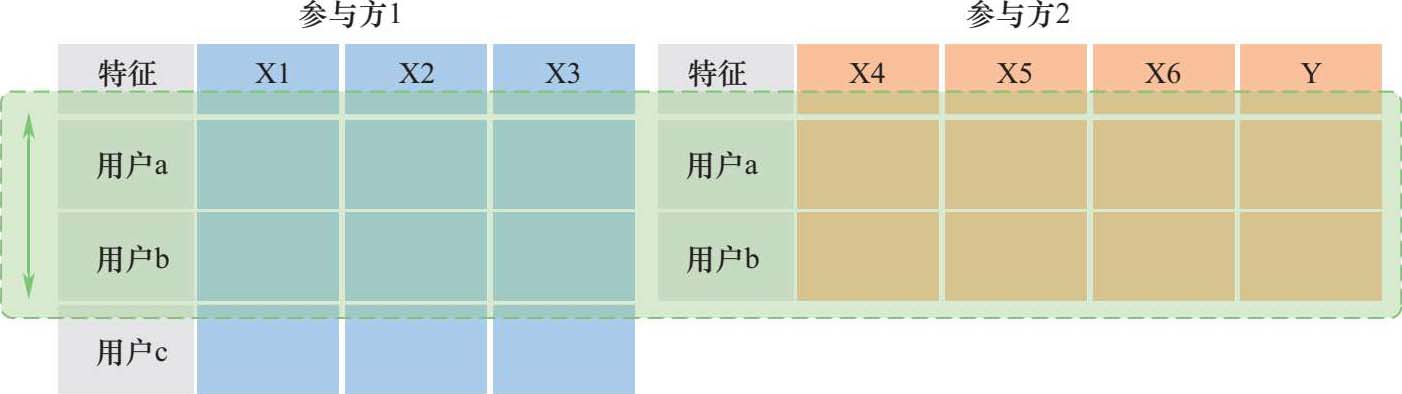
图2-4 纵向联邦学习图解
(1)各参与方获得加密后的ID相同的样本数据,即加密样本对齐;
(2)中央服务器向各参与方分发初始模型和公共密钥(简称公钥);
(3)参与方根据本地数据集中的特征对模型进行训练,之后将中间结果加密,与其他参与方交换,并根据其他参与方的中间结果求解本地模型的梯度与损失;
(4)各参与方加密并上传模型参数,中央服务器解密并汇总结果;
(5)中央服务器将汇总后的结果反馈给各参与方,各参与方更新模型。
在整个纵向联邦学习的过程中,参与方维护的只是基于本地数据特征的模型,称为半模型。在后续采用模型预测时,需要各方共同参与。
联邦迁移学习是迁移学习在多方联合训练下的应用。当参与方之间的数据集样本空间和特征维度均有较少重叠时,采用联邦迁移学习可以获得比单独训练更好的模型,很好地优化以下两种情况:
(1)在横向联邦学习时,参与方的特征空间交集较小,联合训练出的机器学习模型性能较差;
(2)在纵向联邦学习时,参与方的特征维度相差很大,直接纵向联邦会出现负迁移。
为避免以上两种情况,联邦迁移学习可以为参与方提供挑选或者加权样本的机会。联邦迁移学习要求参与方在本地训练各自模型,然后在加密后联合训练,得出最优模型,再向各参与方反馈。
强化学习是指某个智能体根据目前的环境状态,作出下一步动作决策,并在过程中通过不断地交互学习和调整策略,以实现最大化的期望奖励。随着状态、决策空间的不断增大,人们在强化学习中加入了分布式方案,用来缩短学习过程的时间和降低算力。然而,分布式强化学习存在隐私泄露隐患,为增强对各参与方的数据保护,联邦强化学习被提出。联邦强化学习分为两种,即横向联邦强化学习和纵向联邦强化学习。
当代理在不同的环境下训练,使同一个奖励任务的效果最大化时,可采用横向联邦强化学习持续优化模型。其运行过程与横向联邦学习类似:
(1)各参与方训练并维护本地的模型,然后将加密过的模型参数上传给中央服务器;
(2)中央服务器融合所有模型参数,然后反馈给参与方;
(3)参与方根据反馈更新本地模型。
纵向联邦强化学习用于各参与方在同一环境下执行不同决策任务的情况。它考虑部分参与方在作出决策时没有奖励机制,那么需要利用其他有奖励机制的参与方的经验来提高决策质量。纵向联邦强化学习的架构如图2-5所示,主要过程如下:
(1)每个参与方维护一个Q网络,并将Q网络输出值加密后进行传递;
(2)参与方收集除自身外的Q网络输出值;
(3)基于神经网络建立感知模型,输入本地Q学习值和其他代理的Q学习值,输出全局Q学习值;
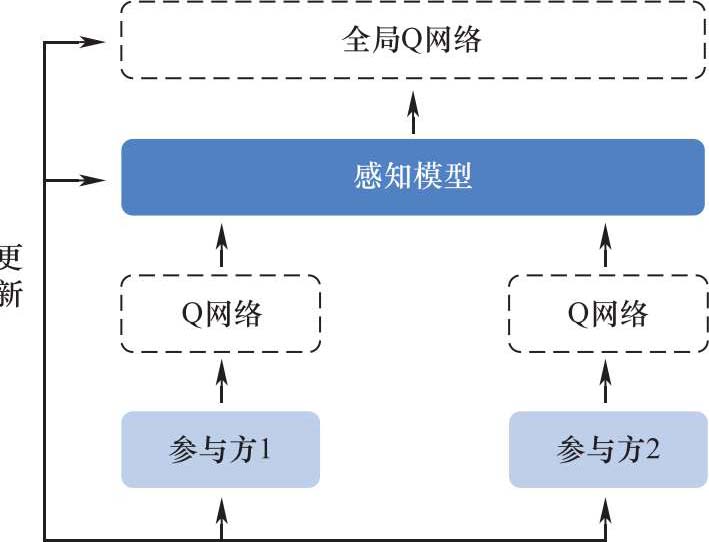
图2-5 纵向联邦强化学习的架构
(4)根据全局Q学习值更新本地Q网络和感知模型。
其中,感知模型是共享的,参与方的Q网络只对自己可见,且传递的参数无法反向推导。联邦强化学习可以有效地提高样本效率,加速学习进程,优化参与方决策,获得更准确的强化模型。