
下载掌阅APP,畅读海量书库
立即打开



数据是人工智能时代的“石油”。近些年,随着国家法律法规、市场监管等方面对保护数据隐私的要求趋严,加之企业、机构间出于竞争壁垒的考虑,使得数据孤岛问题日益凸显。为有效解决这一问题,联邦学习方案被提出。联邦学习基于机器学习框架,是一种新型的安全多方计算技术,该技术能在保证本地数据隐私安全的前提下,实现多方共同建模,从而扩充全局模型的信息量,提升模型效果。
联邦学习一般由参与方和中央服务器组成,其系统架构如图2-1所示。各参与方拥有自己的本地数据,这些数据可能不足以训练模型或者所得模型不准确。为了提升模型精准度,各参与方寻求与其他拥有数据的参与方合作。当大于等于两方参与时,中央服务器启动联合建模。首先,服务器负责收集每个参与方上传的加密模型参数,并采用联邦聚合算法更新原模型。然后,服务器将更新后的模型分发给各参与方,准备下一轮的模型训练。这一过程会持续进行,直到模型达到收敛条件。此外,联邦学习也存在不包含中央服务器的对等网络架构,如图2-2所示,以一个参与方的交互为例。在该架构中,参与方之间直接交互,避免了第三方参与,但是需要更多的加密、解密操作。
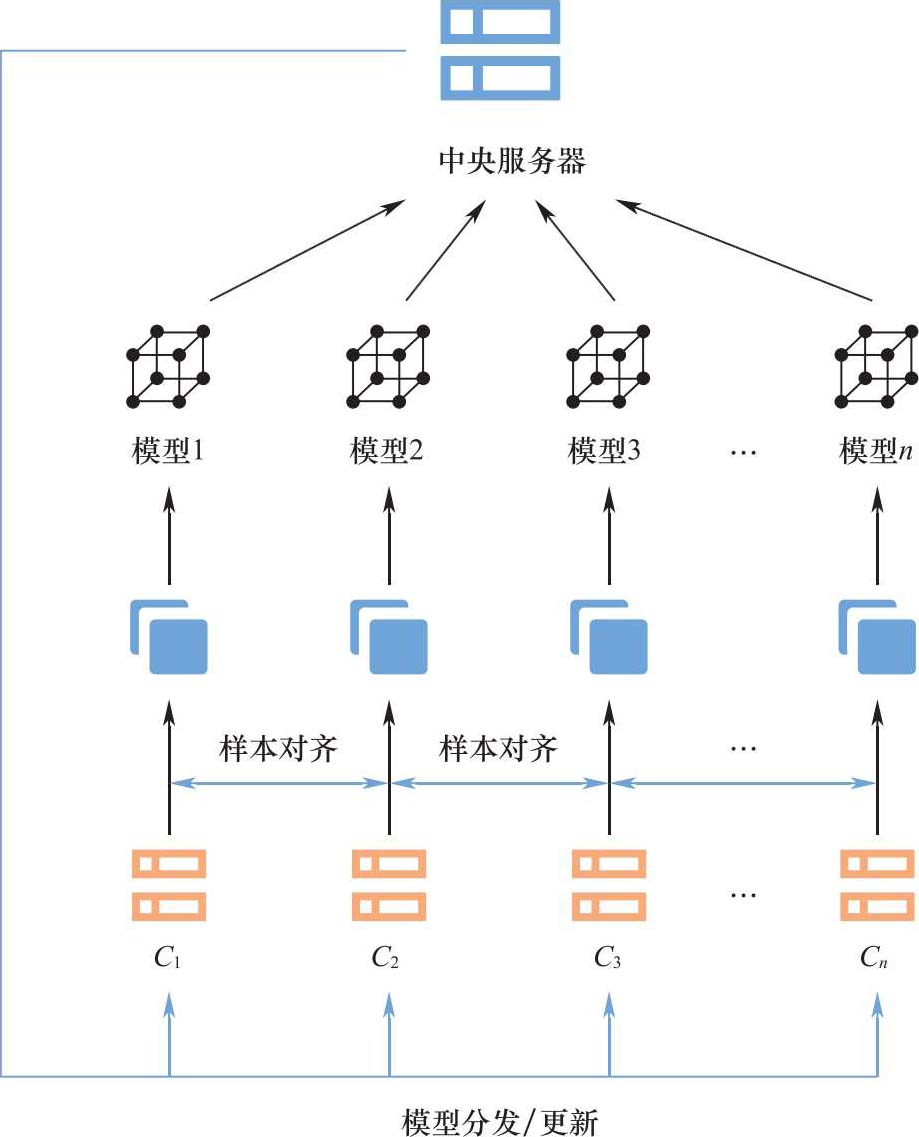
图2-1 联邦学习的系统架构
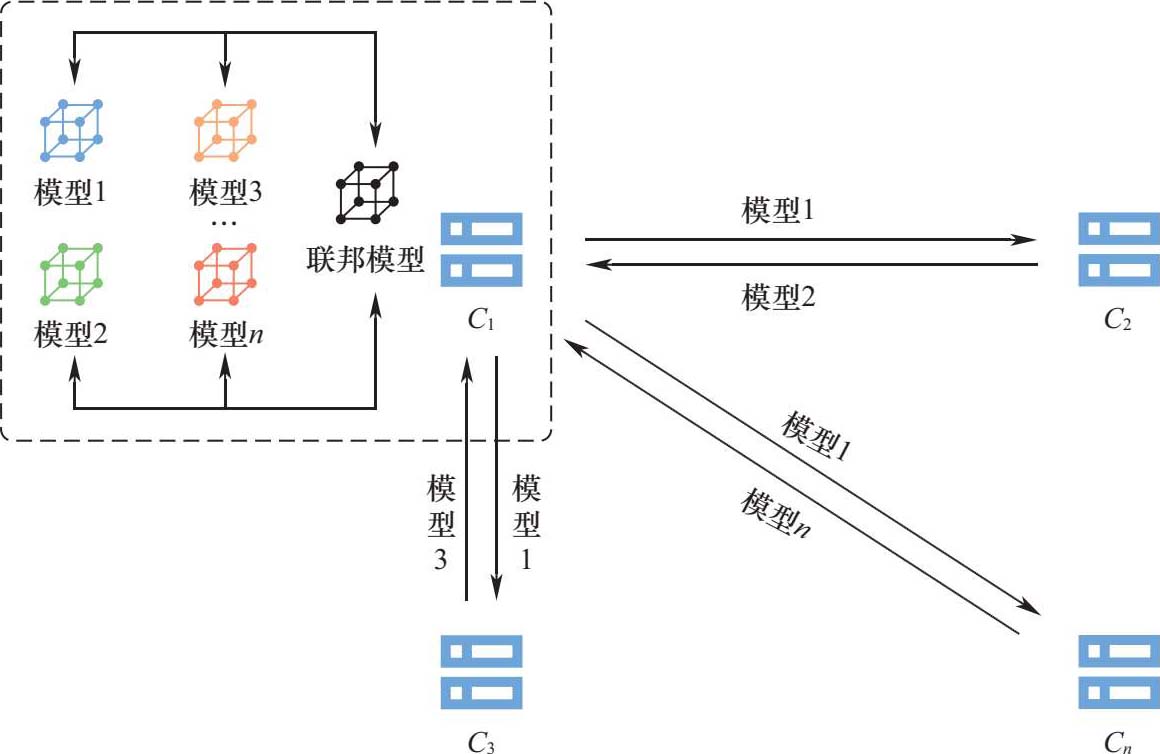
图2-2 联邦学习的对等网络架构
联邦学习有以下几点优势。
(1)隐私性。参与联邦学习的各数据持有方,建模过程中全程保持数据本地化,数据库独立于联邦学习系统之外。参与全局建模的训练时,各数据持有方采用参数交换来替代数据交换,传输过程中不涉及数据本身。
(2)合法性。目前出台的相关法律法规对数据隐私、数据保护等内容提出了严格的要求,联邦学习在建模过程中无须打通数据,满足政策和法律法规的要求。
(3)普遍性。联邦学习的概念基于庞大的数据持有方群体,对数据持有方来说参与门槛较低,如小型公司的数据库、个人用户数据集甚至个人移动设备的数据都可以作为数据持有方参与联邦学习。
总的来说,联邦学习的过程中,参与方的数据保存在本地,只需要交互加密后的模型参数,极大地保证了各方数据的安全与隐私;且各方地位平等,都可以获得模型增益。此外,联邦学习方案严格遵循法律法规,合理运用异构数据集进行模型训练,打破了数据孤岛壁垒,有效地解决了人工智能面临的数据难题。