
下载掌阅APP,畅读海量书库
立即打开



联邦学习是新引入的一项机器学习、深度学习技术,它简单地尝试回答这个问题:我们是否可以在不需要将数据传输到中心位置的情况下训练模型?
联邦学习框架允许使用各种算法从数据中学习以获得经验,同时重点聚焦分布式节点间的训练协作,这是通过标准机器学习算法无法完全实现的。联邦学习已被应用于各种场景,如金融、医疗、物联网、交通和机器人等。不过,尽管联邦学习有着巨大的潜力,但是它在一些技术组成部分,如平台系统、硬件环境以及其他关于数据隐私和数据访问方面的问题还没有得到完全的解决和广泛的共识。本节介绍联邦学习的提出、范式和应用。
谷歌在2016年提出联邦学习概念。区别于要求训练数据中心化的传统机器学习方法,联邦学习通过多个手机等移动设备的协作与交互进行模型训练,同时将所有训练数据保留在设备上,从而将机器学习的能力与将数据存储在云中的需求分离。
本质上,由谷歌提出的联邦学习是一种加密的分布式机器学习技术,它允许参与者建立一个联合训练模型,但参与者均在本地维护其底层数据而不将原始数据进行共享。之后,联邦学习的概念被扩展为所有保护隐私的多方协作机器学习技术,它不仅可以处理基于样本的水平分区数据,还可以处理基于特征的垂直分区数据。在后者的场景,联邦学习可以使跨组织的企业纳入联邦框架。例如,拥有客户购买力数据的银行可以与拥有产品特征数据的电子商务平台合作开发产品推荐系统,从而智能地构建多个实体、多个数据源、不同特征维度的联合模型,这使得多方企业能够在保护数据隐私的前提下,共同实现跨平台、跨区域的价值创造。
联邦学习是一种机器学习框架,其中多个参与方在中央服务器或服务提供商的协调下协作解决机器学习问题。每个参与方的原始数据都存储在本地,它不是直接交换或转移原始数据,而是将多个参与方的训练结果聚合并进行迭代更新,用于实现学习目标。多个数据拥有方 F i ( i =1,2,…, N )的目的是将各自的数据 D i 联合,共同训练机器学习模型。传统做法是把数据整合到一方形成全局数据集 D ={ D i , i =1,2,…, N },并利用 D 训练生成模型 M sum 。然而,该方案因违背数据隐私保护条例而难以实施。为了解决这一问题,联邦学习思想的定义如下:
定义 联邦学习是指使得这些数据拥有方 F i 在不用给出己方数据 D i 的情况下也可进行模型训练并得到全局模型 M fed 的计算过程,并能够保证模型 M fed 的效果 V fed 与传统模型 M sum 的效果 V sum 间的差距足够小,即

其中, δ 为设定的小正量值。
基于此定义可以总结出,联邦学习框架的基本实现思想是:数据拥有方之间在不共享原始数据的前提下,基于加密机制进行参数交换和共享,并依赖弱中心化服务器维护一个全局共有的机器学习模型,其中多个数据拥有方被称为参与方,而全局模型维护方被称为服务器。
如图1-2所示,联邦学习的生命周期可以被划分为多个连续的通信轮,在这些轮次之间不断地迭代,并在全局模型达到预期的精度时停止。
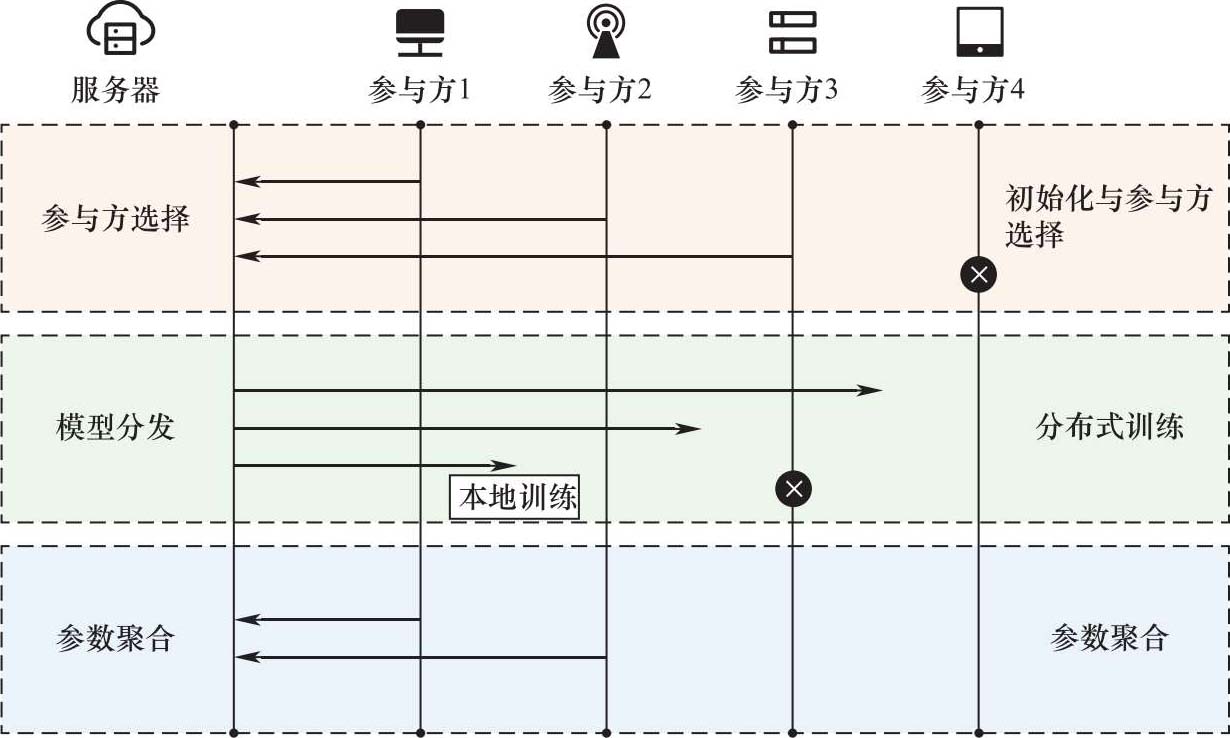
图1-2 联邦学习的生命周期
服务器首先生成一个通用模型,然后每轮执行以下步骤。
(1)服务器选择参与方的一个子集进行本轮训练,选择设备的典型条件是设备本身可靠、当前设备空闲以及网络连接良好。
(2)选定的参与方从服务器下载当前的模型参数/权重,并使用这些权重初始化本地联邦学习模型。
(3)每个被选择的参与方使用其本地的培训数据对全局模型进行训练和优化。在典型和最常用的技术中,参与方运行随机梯度下降(Stochastic Gradient Descent,SGD)算法来计算更新。在通信带宽受限的情况下,计算一个梯度并将其发送回服务器是不够的,为了更好地进行模型更新和降低通信成本,参与方在一个通信轮次中处理多个训练轮数(Epoch)的梯度下降与更新迭代,并整合、发送回服务器。
(4)训练完成后,参与方将优化后的参数发送给服务器。由于连接不良、计算资源有限、训练数据量大等原因,部分参与方可能会在训练或参数传输阶段退出。因此,服务器会计算失败参与方的百分比,并继续处理接收到的更新数量,如果及时报告的客户数量不够,则放弃当前活动轮。
(5)服务器收集所有参与方的更新,根据参与方数据集的大小对其进行加权聚合(通常使用FedAvg),并由此产生一个新的全局模型。该全局模型会在下一次迭代中得到更好的增强。
联邦学习的核心问题有昂贵的通信费用、系统异构性、统计异质性、隐私问题和激励问题。
(1)昂贵的通信费用。在联邦网络中,通信是一个关键的瓶颈。由于发送原始数据存在隐私问题,每个设备上生成的数据必须保持在本地。不过,实际的联邦网络可能包含大量设备,例如数百万部智能手机,由于带宽、能量等资源有限,网络中的通信可能比本地计算慢很多个数量级。因此,为了使一个模型适用于联邦网络中的设备生成数据,开发通信效率高的方法变得至关重要。例如,在训练过程中迭代地发送小消息或模型更新,而不是通过网络发送整个更新集合。为了在这样的环境下进一步减少通信,需要考虑两个关键因素:第一,减少通信轮的总数;第二,压缩每轮传输的消息的大小。
(2)系统异构性。联邦网络中每个设备的存储、计算和通信能力可能会因硬件(CPU、内存等)、网络连接(4G、5G和WiFi等)和功率(电池级别等)的不同而有所差异。此外,每个设备上的网络情况和与系统相关的限制通常导致只有一小部分设备同时处于活动状态,如一个拥有数百万个设备的网络中只有数百个活动设备。并且,出于网络连通性或能量限制的原因,活动设备在迭代过程中退出也很常见。这些系统特征极大地增加了缓解通信延迟和容错的难度。因此,开发出来的联邦学习方法必须满足低参与度、兼容异构硬件、足够的健壮性,以及容忍在通信网络中删除设备。
(3)统计异质性。设备在整个联邦网络中频繁地以高度不一致的方式生成和收集数据,例如,移动电话用户在进行下一个单词预测任务时使用不同的语言。此外,跨设备的数据点数量可能会有很大差异,这种数据生成范式违反了分布式优化中经常使用的独立同分布(Independently Identically Distribution,IID)假设,并可能增加问题建模、理论分析和解决方案等经验评估方面的复杂性。在这方面,领先的联邦学习方法和元学习之间也有密切的联系,多任务和元学习透视图都支持个性化或特定于设备的建模,这通常是处理数据的统计异质性以实现个性化的有效方法。
(4)隐私问题。隐私通常是联邦学习应用的主要关注点。联邦学习通过共享模型更新信息(如梯度信息)而不是原始数据,向保护在每个设备上生成的数据迈出了一步。然而,在整个训练过程中,传递模型更新信息仍然会向第三方或中央服务器泄露敏感信息。尽管有改进方法使用诸如SMC或差分隐私等工具来增强联邦学习的隐私性,但这些方法通常以降低模型性能或系统效率为代价。
(5)激励问题。理想情况下,联邦学习所有参与训练的参与方均提供模型所需的真实数据并有良好的终端计算能力和通信传输环境,现有的联邦学习框架也主要在客户端均诚实的条件下关注网络性能和模型质量的优化。然而在真实联邦场景下,没有合理的激励机制难以吸引参与方的加入,同时由于联邦学习信息不对等的特性,参与方上传的子模型参数对于全局模型的贡献难以评估,甚至在开放网络环境下,可能出现作恶参与方阻碍全局模型的训练或者骗取模型收益。因此,在一个信任缺失或有限的数据联邦环境中设计分布式网络环境的激励机制以维护联邦生态非常重要。
许多行业和公司开始将联邦学习合并到他们自己的工作周期和产品中,许多基于联邦学习的应用 [13] 也正在浮出水面。本节介绍一些典型的应用案例。
这是联邦学习的第一个应用,称为Gboard输入法,谷歌试图使用联邦学习来提高键盘搜索建议的质量。Gboard输入法必须尊重消费者的隐私,不能收集消费者的键盘搜索历史信息,同时该应用不能有任何延迟。这对于一个移动设备的应用来说是至关重要的,因此必须确保用户数据的使用和用户体验不会受到负面影响。谷歌设法构建了一个客户机—服务器体系结构,服务器将在连接了一定数量的客户机后,设定一个训练任务并分配给每个客户机,而客户机负责使用本地的数据执行这些任务。为了管理跨设备的负载,客户机会被告知再次与服务器通信之前需要等待多长时间。
类似的,联邦学习也被用于键盘预测和关键字定位,与Gboard输入法的不同在于使用了不同的训练模型。为实现这个目标,联邦学习试图训练一个循环神经网络(Recurrent Neural Network,RNN),并对模型进行了多种性能约束。它可以保证这些模型的体积足够小,并能同时在低端和高端设备上运行,还可以满足用户在输入事件发生后约20ms内得到可见的键盘响应的期望。
患者聚类场景的重点对象是电子病历(Electronic Medical Record,EMR),它是医疗保健领域最重要的组成部分,是开展数字化医疗服务的关键。以往,人们使用传统的机器学习机制处理电子病历,但这种处理方式存在一个错误的前提,即电子病历可以很容易地被共享并存储在集中的位置。事实上,电子病历是由不同医疗机构和诊所的病人产生的,它们本质上是敏感的,在存储、安全性、私密性、成本和共享医疗数据的可用性方面都具有更高的要求。
功能性磁共振成像分析也存在类似的问题,模型构建的重点是医疗机构的高质量数据。通常,出于隐私方面的担忧,模型无法获得高质量的数据:病人担心他们的医疗数据被滥用,而卫生服务提供者担心卫生统计数据被公开后会失去病人。
联邦学习可以在很大程度上解决这些问题。在联邦学习中,没有必要收集与共享来自各方的不同数据,也不用关心数据是如何建立、存储在哪里的,通过各方在本地的训练即可形成性能较好的相关模型。
在金融活动中,消费者可能会在多家金融机构有活动记录,包括银行、保险公司等,集中多家金融机构的数据,可以对消费者的信誉历史进行更精确的建模,以产生信用分数。金融机构可以依据消费者的信用评分评估用户违约的风险,确定其信用的价格和服务(如利率区间)。
但是,出于保护用户隐私的要求,考虑金融法律限制和审计安全等因素,金融机构之间的数据壁垒难以打破,多方无法互相交换数据。因此,联邦学习是一个良好的解决方案。利用联邦学习的特性,人们不用导出企业数据,就能够为三方联合构建机器学习模型,既充分保护用户隐私和数据安全,又为用户提供了个性化的产品服务,从而实现了多方共同受益。