
下载掌阅APP,畅读海量书库
立即打开



数据作为人工智能技术发展的“原料”,其重要价值不言而喻,但由它引发的一系列关于数据安全和隐私保护的担忧,让人们对数据安全问题变得愈发重视,如何在应用过程中保护用户数据隐私、防止信息泄露已经成为新的挑战。本节介绍隐私保护问题,以及常见的隐私攻击方式与保护技术。
基于云计算、大数据、人工智能新技术的多种应用(如智能音箱、可穿戴设备、AR/VR眼镜和无人驾驶汽车)可以提供一系列服务,这些设备会收集有关个人特定状况的隐私信息,并依据这些信息执行智能算法、发出命令。
令人不安的是,绝大多数的消费用户无法掌握他们的哪些信息被收集了,以及被谁收集了。他们正面临着一个深刻的矛盾,是享受智能设备的便捷,还是坚持日常活动中对隐私的严格控制。美国“棱镜门”、脸书(Facebook)用户数据泄露等层出不穷的互联网隐私泄露事件更加剧了用户对使用人工智能时隐私保护问题的担忧。
现在,隐私保护愈发受到国内外的重视和关注,许多政府、行业协会和非政府组织都参与了数字隐私保护的讨论。美国提出的消费者隐私权利法案,建立在公平信息实践原则(Fair Information Practice Principles,FIPPs)的基础上 [8] ,解决了私营部门实体应该如何处理个人数据的问题。该法案对公司收集和保留的个人数据进行合理限制,消费者有权对公司从他们那里收集的数据,以及他们如何使用这些数据行使控制权。类似的,欧盟针对可穿戴设备的隐私保护建议强调,隐私政策应具体说明收集什么数据,以及如何收集、存储、使用、保护和披露数据。2017年6月起施行的《中华人民共和国网络安全法》第42条指出,“网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息”。2018年3月,欧盟的GDPR正式生效,该条例对企业处理用户数据的行为提出了明确要求,企业在用户不知情时进行数据收集、共享与分析已被视为一种违法行为。
在这样的背景之下,对于机器学习而言,隐私问题主要表现在以下两个方面。
(1)因数据收集和数据分享导致的隐私泄露。第一,不可靠的数据收集者可能在未经人们许可的情况下擅自收集个人信息、非法进行数据共享和交易等。第二,拥有敏感数据的机构和企业为了构建性能更好的模型而相互交换数据,而这样的方式本身就存在隐私泄露的风险,违背了相关法律法规和市场监管的要求。
(2)模型在训练、推理过程中因受外部恶意攻击导致的间接隐私泄露。恶意的数据窃取者通过与模型进行交互等多种方式会逆向推理出未知训练数据中的个体敏感属性,即隐私保护的相关攻击。
在与隐私相关的攻击中,对手的目标是获取非预期共享的有关知识,例如关于训练数据的知识或关于模型的信息,更有甚者可以提取到有关数据属性的信息。隐私保护的攻击可以分为4种类型:成员推理攻击、重构攻击、属性推理攻击和模型提取攻击。
成员推理攻击会试图推测输入样本x是否在模型训练的数据集之中,这是最流行的攻击方式之一。有监督的机器学习模型、生成模型,如生成式对抗网络(Generative Adver sarial Network,GAN)和变分自编码器(Variational Auto-Encoder,VAE)容易受到该攻击 [9] 。在某些场景下,成员推理攻击可能造成严重的后果,例如对于由艾滋病患者数据构建的诊断模型,若某人的医疗数据被推断是该模型的训练数据,便意味着此人可能患有艾滋病。
重构攻击试图重新创建一个或多个训练样本及标签,这些重建可以是针对部分数据的,也可以是针对全部的。一般来说,重构攻击是利用给定的输出标签和某些特征的部分知识,使用属性推断或模型反演等方式,试图恢复敏感特征或整个数据样本。
另外,虽然不是针对机器学习模型,“重构攻击”一词也被用于描述利用公开可访问数据推断目标用户敏感属性的攻击。例如,攻击方查询了所有学号对应同学的身高和,之后又查询了除了学号1同学以外所有同学的身高和,两次公开数据相减就得到了学号1同学的身高隐私数据。
获取与学习任务不相关的数据集本身的统计属性信息,并试图凭此恢复敏感特征的行为,称为属性推理攻击。属性推理攻击的一个例子是,当性别不是某患者数据集的编码属性或标签时,提取该数据集中男女比例的信息。在某些情况下,这些信息的泄露可能涉及隐私,同时这些属性还可能暴露更多关于训练数据的信息,从而可能导致对手使用这些信息创建类似的模型。
模型提取攻击是一种黑盒攻击,攻击对手方试图提取信息,并有可能完全重建模型或创建一个非常类似于原模型的替代模型 [10] 。创建替代模型的依据是输入一些与测试集数据分布相关的学习任务,又或者其输入点不一定与学习任务相关。前者被称为任务精度提取,而后者被称为保真度提取。在前一种情况下,对手感兴趣的是创建一个替代对象,这个替代对象能同样或更好地学习与目标模型相同的任务;在后一种情况下,对手的目标是创建一个尽可能忠实地还原模型的决策边界的替代品。
模型提取攻击可以作为进行其他类型攻击的铺垫,如对抗性攻击或隶属关系推断攻击。在这两种情况下,都假定对手希望尽可能高效完成攻击任务,即使用尽可能少的查询。因此,创建一个与被攻击模型具有相同或更高复杂度的替代模型是必要的。
除了创建替代模型,还有一些攻击专注于从目标模型中恢复信息,如恢复目标函数中的超参数,或关于各种神经网络结构属性的信息,如函数激活类型、优化算法、层数等。
有大量的研究致力于在不暴露敏感数据的情况下改进学习模型,而常见的针对机器学习的隐私保护技术主要可以分为两大类:第一类是若干基于密码学的方式,常用的有安全多方计算(Secure Multi-party Computation,SMC)、同态加密(Homomorphic Encryp tion,HE)等;第二类则对原始数据制造扰动,即向数据中添加随机的噪声,使输出结果与真实结果具有一定程度的偏差,如差分隐私机制。
安全多方计算起源于姚期智院士在1982年提出的百万富翁问题 [11] ,其目的是解决一组不可信用户之间协同计算时保护隐私的问题。安全多方计算需要确保输入、计算的独立性与准确性,即不会将输入值泄露给参与计算的其他成员,独立、准确地完成计算。
然而,直接在神经网络训练中使用安全多方计算具有一定的困难。例如,如果使用基于混淆电路的安全多方计算技术,在训练过程中计算Sigmoid或Softmax等非线性激活函数的代价较大。此外,混淆电路适用于两方或者三方安全计算,不容易扩展到有更多用户的协作环境。因此,研究人员致力于探讨如何在机器学习模型训练中使用安全多方计算。例如,有研究提出了一个用于隐私保护训练的双服务器模型,用户将他们的数据分割成两个独立的副本,并将它们发送到两台不同的服务器,两台服务器使用安全的双方计算(2PC)来训练神经网络和其他机器学习模型。因此,在训练过程中,两台服务器都无法查看用户的完整数据。
同态加密是一种对数据进行加密的方法,并可以在不解密数据的情况下对其执行某些操作,执行的结果解密之后与原始数据执行同样操作的结果相同,这是因为同态加密机制在计算时保留了一些原始的消息空间结构。
在协作场景的机器学习训练中应用同态加密时,每个用户首先使用系统公钥加密自己的本地数据,然后将密文上传到服务器。服务器用密文执行与学习过程相关的大部分操作,并将加密的结果返回给用户。在这个过程中,服务器不知道用户的数据,用户也不知道服务器的模型。
差分隐私最初由C. Dwork提出,该方法将随机噪声注入由原始敏感数据计算的统计结果中,当替换或删除原始数据集中的单个记录时,并不会影响输出结果的概率分布,这一定程度上避免了攻击者通过捕捉输出差异进而推测个体记录的敏感属性值。形式上,差分隐私的定义 [12] 如下:
定义 对任意的数据集 D 1 和 D 2 , D 1 、 D 2 ⊆ D ,即 D 1 、 D 2 是非单个元素的子集,给定随机算法 f : D → R 和任意的输出结果 S ⊆ R ,若不等式
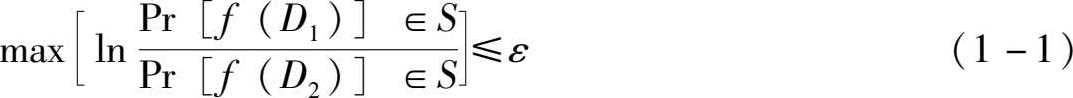
成立,即通过特定构造数据集执行随机算法得到无法区分这两个数据集的结果,则称算法 f 满足 ε 差分隐私。
差分隐私机制将算法的隐私损失控制在一个有限的范围内, ε 越小,则算法的隐私保护效果越好。常用的差分隐私算法有拉普拉斯机制、指数机制和高斯机制。