
下载掌阅APP,畅读海量书库
立即打开



2.4 神经网络 |

|
人工神经网络(Artificial Neural Network),简称神经网络,是由一些具有适应性的简单单元组成的连接网络,能够通过模拟生物神经系统对真实世界物体所做出的交互反应。
之前讨论的线性模型,比如线性回归和对数概率回归,是非常好用的模型,可以通过解析解或者优化方法,实现高效且可靠的拟合。但是这种方法对非线性关系有很大的局限性,并且无法处理变量与变量之间的关系。为了扩展线性模型,之前提到过使用一个非线性的连接函数将输出与最终目标相联系。剩下的问题就是如何选择这样一个非线性的连接函数。其中一种方法是选择使用一个通用的连接函数,这个函数有足够高的维度,有足够的能力来拟合训练数据集,但是这样得到的结果往往会过拟合,有很大的泛化误差。另一种方法是手动地设计连接函数,在深度学习出现以前,这是比较主流的方法,但是由于这种方法需要对每个单独的任务进行研究,往往需要很多的时间与经验,并且各个任务上使用的连接函数不能跨任务使用。最后一种方法就是即将要讨论的神经网络的方法,本节将先介绍神经元模型的基本结构,然后介绍前馈神经网络及反向传播算法的理论推导,最后介绍深度学习的概念。
神经网络中最基本的构成成分是神经元模型,也就是上述所说的简单单元。在生物神经网络中,每个神经元与其他神经元相连接,当它处于触发状态时,就会给相邻神经元发送信号,神经元收到来自其他神经元的信号,如果累计加权值达到某个阈值,就处于触发状态并传递信号。
人工神经网络的构造就来自于生物神经网络模型,如图2.10所示,每个神经元模型包含 n 个输入、1个输出,以及2个计算功能。每个神经元接收来自其他 n 个神经元模型的输入,并且每个输入带有权值,然后神经元对输入值按照权值进行计算,最后通过激活函数并将结果输出到其他相连接的神经元。
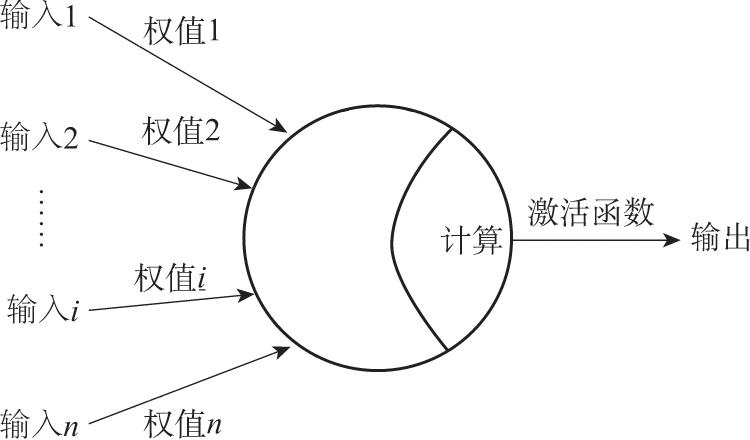
图2.10 神经元模型
如果用 x 表示上一层神经元模型的输入, w 表示输入所带的权值, g 表示激活函数,那么每个神经元模型做的计算任务就是:
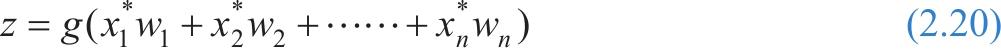
激活函数就是引入非线性因素,如果没有激活函数,所有神经元的连接最终都可以化简成输入的线性组合,常用的激活函数有Sigmoid和ReLu等,如图2.11所示。
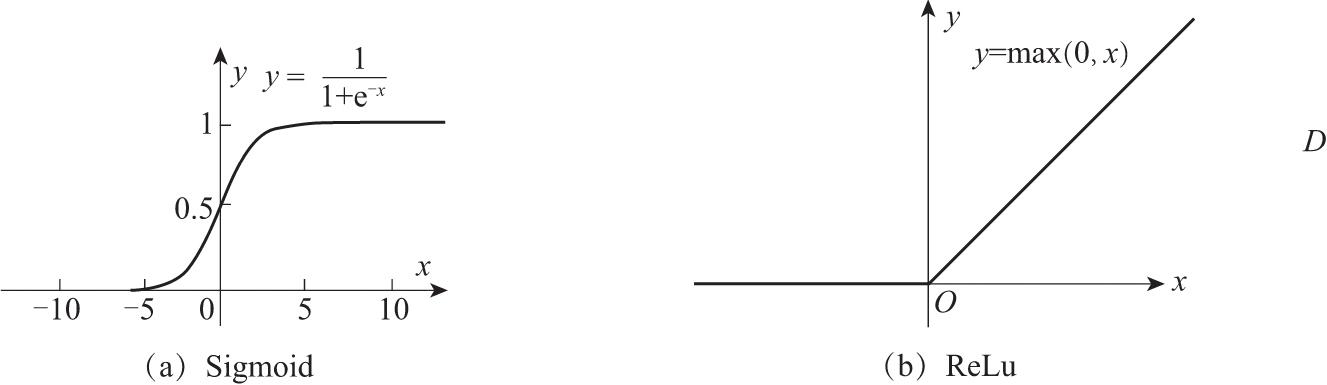
图2.11 常用激活函数
单个神经元模型可以理解为线性模型,类似一个对数概率回归模型,通过输入和权值的线性组合拟合输出,权值跟参数一样是通过训练得到的。
把多个神经元模型按照一定的层次结构连接起来,就得到了前馈神经网络模型,也叫作多层感知机。如图2.12所示为一个具有基本结构的三层神经网络模型,包含一个输入层、一个输出层和一个中间层,输入层和中间层各有两个神经元,并带有一个权值向量。输入层神经元接收外界输入,中间层和输出层对信号进行加工计算,最后由输出层输出结果。
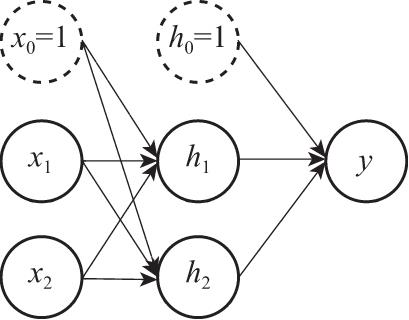
图2.12 三层神经网络示意图
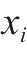 表示输入层的值,
y
表示输出层的值,
表示输入层的值,
y
表示输出层的值,
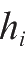 表示中间层,
表示中间层,
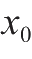 和
和
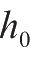 分别表示输入层和中间层的偏置量。为了求出最后的输出值
y
,需要求出前面每一层神经元的输出值,而每一层的值都是上一层神经元经过类似对数概率回归模型的计算得来的。用
分别表示输入层和中间层的偏置量。为了求出最后的输出值
y
,需要求出前面每一层神经元的输出值,而每一层的值都是上一层神经元经过类似对数概率回归模型的计算得来的。用
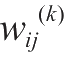 表示第
k
层第
i
个神经元到第
j
个神经元的权值,
表示第
k
层第
i
个神经元到第
j
个神经元的权值,
 表示中间层的计算结果,有
表示中间层的计算结果,有
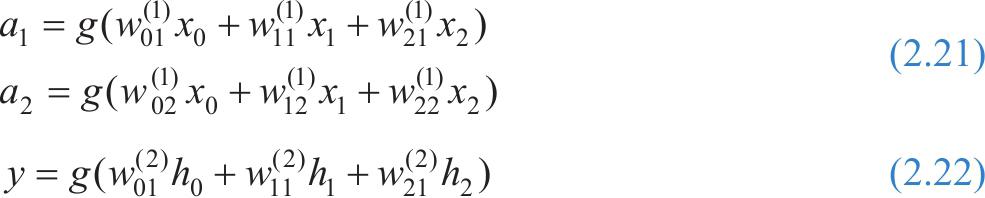
g ()表示激活函数,写成矩阵形式可以表示为

对于第
i
层第
j
个神经元,神经元的带权输出值
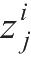 和激活输出值
和激活输出值
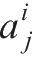 可以表示为
可以表示为

事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。因此,隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。
有研究证明,加入一层神经元数量足够多的中间层,神经网络就可以无限逼近任意连续函数。不过也正因为如此强大的表达能力,神经网络经常遭遇过拟合,训练误差持续降低,因此在使用的时候应提前考虑这一情况。
在设计一个神经网络时,输入层的节点数需要与特征的维度相匹配,输出层的节点数与目标维度相匹配,而中间层的节点数,由设计者自己指定。但是,节点数的设置,会影响到整个模型的效果。至于中间节点数及其他参数的确定,目前还没有完善的理论,一般是根据经验来设置的,先预先设定几个可选值,然后通过切换这几个值来查看整个模型的预测效果,选择效果最好的值作为最终选择。这也就是所谓的网格搜索(Grid Search)。
神经网络训练和使用梯度下降训练没有太大的区别,都是基于梯度使得损失函数下降。当使用前馈神经网络接收输入 x 并产生输出 y 时,信息流从前往后传播,输入 x 提供初始信息,然后传递到中间层,最终输出层产生输出 y ,这是所谓前向传播。
但是由于神经网络的参数数量非常庞大,尤其是当神经网络的层数非常高的时候,如果使用前向传播的梯度下降去优化整个学习算法,所需的计算代价非常之大,而反向传播算法使用简单和廉价的程序来有效率地解决求解梯度这一问题。并且,反向传播算法不仅可以用在前馈神经网络模型中,在其他的神经网络模型和其他学习算法中都是可以运用的。所谓的反向传播就是信息流从输出层反向传递,直到最后到达输入层。下面给出反向传播算法的数学推导。
对于给定包含
n
个数据的数据集
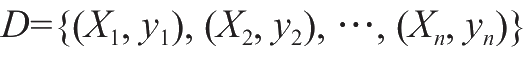 ,如图2.13所示,对于每组的输入
X
,神经网络在最后一层(即第1层)的激活输出为
,如图2.13所示,对于每组的输入
X
,神经网络在最后一层(即第1层)的激活输出为
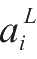 ,上标
L
表示第l层(即输出层),真实结果为
,上标
L
表示第l层(即输出层),真实结果为
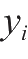 ,为了方便求导,使用均方误差的如下式子作为损失函数:
,为了方便求导,使用均方误差的如下式子作为损失函数:

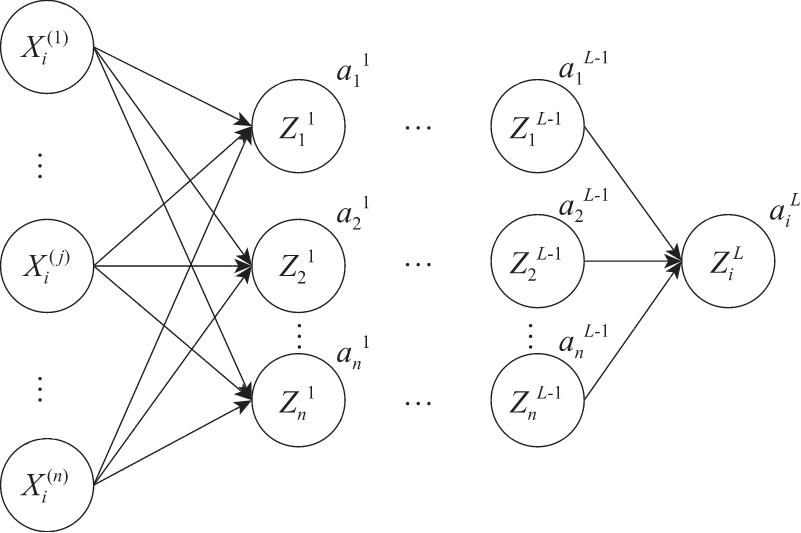
图2.13 反向传播算法示例图
需要优化的参数为权值
w
和偏置
b
,求解梯度也就是求解
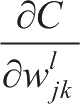 和
和
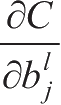 ,表示损失函数对第1层第
j
个神经元对第
k
个神经元的权值。在这里需要引入
,表示损失函数对第1层第
j
个神经元对第
k
个神经元的权值。在这里需要引入
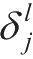 ,表示第1层第
j
个神经元的误差,反向传播算法将会对每一层计算
,表示第1层第
j
个神经元的误差,反向传播算法将会对每一层计算
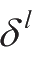 ,然后得到相应的
,然后得到相应的
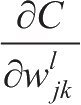 和
和
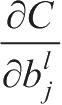 。
。

根据式(2.24)、式(2.25)和链式法则,可以将第
L
层(也就是输出层)的误差
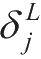 化简得到如下式子:
化简得到如下式子:

其中,
g
′是激活函数的导数,可以很容易求得。由于假设输出层只有一个神经元,因此在此求得的
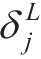 也就是该层的总误差
也就是该层的总误差
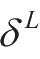 。然后代价函数对第
l
层误差的偏导数可以由链式法则给出,第
l
层每个神经元的输出值会对第
l
层所有神经元造成影响,于是第
l
层的误差与第
l
+1层误差的关系可表示如下:
。然后代价函数对第
l
层误差的偏导数可以由链式法则给出,第
l
层每个神经元的输出值会对第
l
层所有神经元造成影响,于是第
l
层的误差与第
l
+1层误差的关系可表示如下:
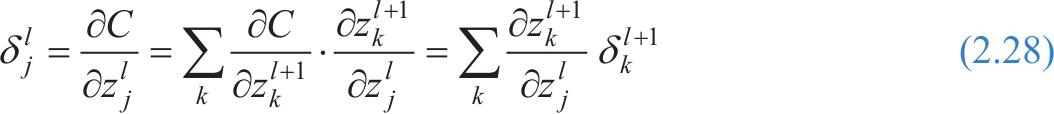
由式(2.24)可得,第
l
+1层的计算值
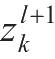 与第
l
层的计算值关系如下:
与第
l
层的计算值关系如下:
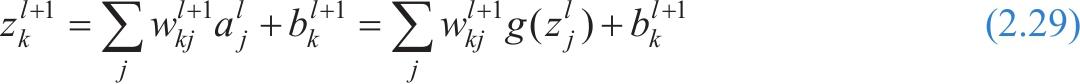
对式(2.29)做微分,再代入式(2.28),可以得到第 l 层误差与第 l +1层误差的反向传播公式如下:
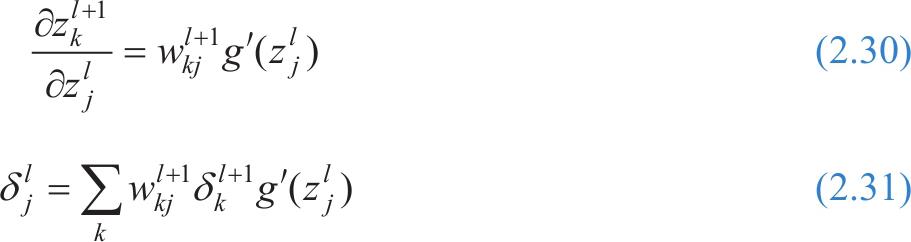
通过式(2.28)和式(2.29)就可以计算任意层的误差 δ l ,首先用式(2.31)计算出最后一层的误差,再根据式(2.27)递归地求解前一层的误差,如此一步一步地便可以反向传播整个完整网络。
得知误差的求解,就很容易推导出代价函数与偏置 b 的关系,根据式(2.21)及求导法则,代价函数对 b 的偏导数恰好等于之前定义的误差 δ ,因此可以很容易地给出其关系:

然后求解代价函数与权值的关系,由于有了误差这一中间变量,代价函数与权值的关系也很容易给出,如下式所示:
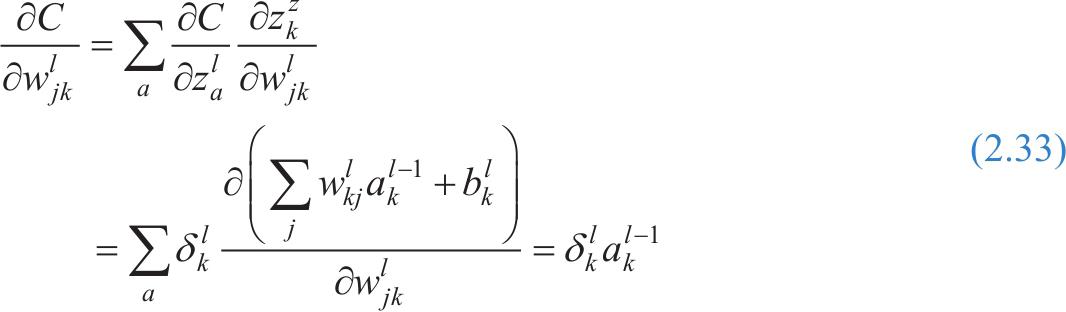
写成矩阵形式可简写为

基于以上的推导过程,我们可以总结出优化一个神经网络参数的全过程:首先初始化神经网络,并对每个神经元的参数
w
和
b
随机赋初值,然后对神经网络进行前向传播计算,得到各个神经元的带权输出
z
和激活输出
a
,并且在输出层求得第
l
层的误差
δ
,再根据反向传播算法向前传递误差,求出每个神经元的
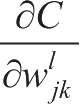 和
和
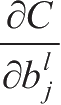 ,再乘以学习率完成对参数的更新,直到最后训练得到一个损失比较小的神经网络。
,再乘以学习率完成对参数的更新,直到最后训练得到一个损失比较小的神经网络。
理论上说,参数越多,模型复杂度就越高,因为更多参数意味着能完成更复杂的学习任务,拟合更复杂的情况。但是,参数过多容易导致过拟合,并且大量的参数使得训练过程计算量非常高,带来的计算开销难以承受,因此深度学习在提出之初并没有受到广泛关注。而随着云计算、大数据时代的到来,计算能力的大幅度增强使得深度神经网络的计算开销变得可接受,而大数据带来的海量数据则可以有效降低过拟合风险,因此,深度学习开始受到广泛关注和研究。
典型的深度学习模型就是中间层数很多的神经网络。显然,对于一个神经网络模型,增加复杂度的办法就是增加单层神经元的数量和增加中间层的层数。前面提到过,一层中间层的神经元模型就可以无限逼近任意一个连续函数,可以看出,单中间层的神经网络已经具有非常强的学习能力,因此,继续增加单层神经元数量带来的收益相对没那么明显。而增加中间层数量不仅可以增加神经元的数量,提高了模型的复杂度,还可以增加激活函数的层数,带来更多的可能性。
但是,中间层太多的神经网络模型有时候会因此误差在传递过程中发散,而不能收敛到一个稳定状态,因此难以用反向传播算法进行优化。因此有学者提出了无监督逐层训练,也就是所谓的“预训练”。这是一种多中间层网络的常用训练手段,其基本方法是每次训练一层中间层,训练时将上一层的输出作为输入,本层的输出作为下一层的输入,训练完成之后再对整个网络进行微调。这样的预训练加微调的训练方法可以看作先将大量参数进行分组,先找到局部比较合理的参数设置,再对这些局部较优的参数结合起来寻找全局最优,这样就在保持整个模型足够大复杂度的同时,有效降低了训练开销。
另一种节省开销的方法是“权值共享”,即让一组神经元使用相同的连接权。例如,在卷积神经网络(Convolution Neural Network,CNN)中,用反向传播算法进行训练,无论是卷积层还是采样层,每一神经元都使用相同的连接权,从而大幅度减少训练的计算开销。
如果从另一个角度来理解,中间层对上一层的输出进行处理的机制,可以看作是对输入信号的逐层处理,把初始的、与输出目标联系不太密切的输入,逐步地转化为与输出更密切的表示。也就是说,通过多个中间层的处理,将输入的低维特征转化为高维特征,再用数学模型对高维的特征进行拟合,这样可以将深度学习理解为“特征学习”或者“表示学习”。以往在用机器学习解决问题的时候,往往需要人为地设计和处理特征,也就是所谓的“特征工程”,而深度学习相当于让机器在海量的数据中自己寻找特征,再完成对数据的学习。
但是,深度学习的强大也带来了对应的问题——黑箱化。黑箱的意思是,深度学习的中间过程不可知,深度学习产生的结果不可控。一方面,我们很难知道深层神经网络具体在做些什么,另一方面,我们很难解释神经网络在解决问题的时候,为什么要这么做。在传统的机器学习模型中,算法的结构大多充满了逻辑(例如,线性模型和树模型),这种结构可以被人分析,最终抽象为某种流程图或者公式,具有非常高的可解释性。而深度学习似乎始终蒙着一层面纱,难以捉摸。深度学习的工作原理,可以理解为通过一层层神经网络,使得输入的信号在经过每一层时,都做一个数学拟合,这样每一层都提供了一个函数,通过每一层函数的叠加,最终的输出就无限逼近目标。这样一种“万能近似”,可能只是输入和输出在数值上的耦合,而不是真的找到了一种代数上的表达式。因此,未来关于深度学习可解释性的研究,可能会是人们对深度学习的真正探索。