
下载掌阅APP,畅读海量书库
立即打开



机器学习的方法与你学习的方法相同,都是通过训练,但如何训练呢?机器学习是在得出正确答案时奖励某个数学函数,以及在得出错误答案时惩罚该函数的过程,但奖励或者惩罚某个函数意味着什么呢?
你可以将 函数 看成从一个地方到另一个地方的指令集。如图1-4所示,为了从A点到达B点,方向可能如下所示:
(1) 往右走;
(2) 往上走一点;
(3) 往下走一点;
(4) 往下走一大截;
(5) 往上走;
(6) 往右走。
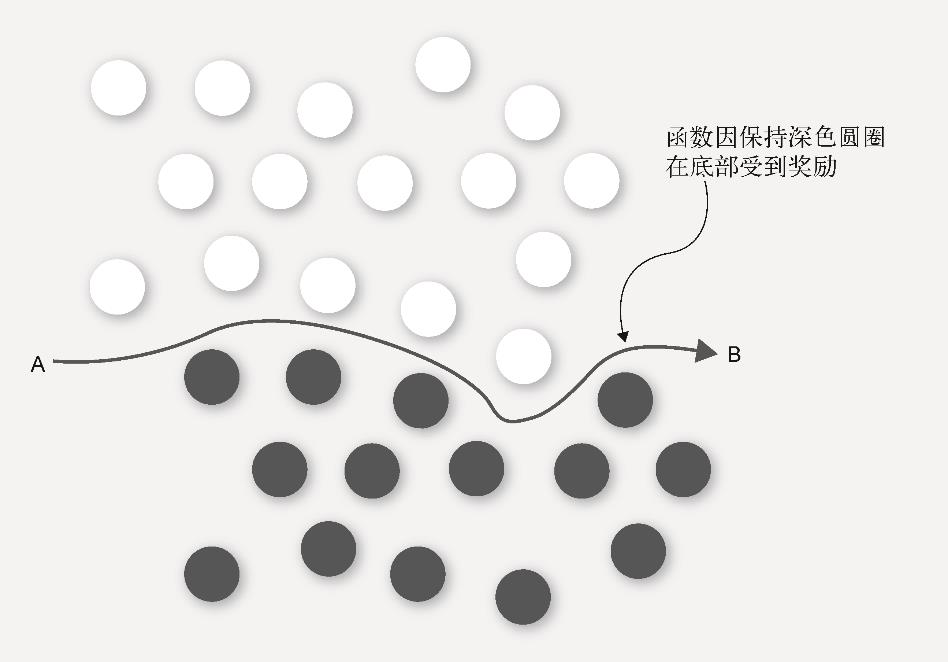
图1-4 机器学习函数可识别数据中的模式
机器学习应用程序是一种工具,可以确定函数何时正确(告诉函数执行更多操作)或错误(告诉函数执行更少的操作)。函数知道自己做对了,因为它在基于特征预测目标变量方面变得更加成功了。
下面我们扩展图1-4中的数据集,来看一个更大的样本,如图1-5所示。可以看到数据集包括两种类型的圆圈:深色圆圈和浅色圆圈。在图1-5中,我们从数据中可以看到一个模式。数据集的四周有很多浅色圆圈,中间有很多深色圆圈。这意味我们的函数给出了如何将深色圆圈与浅色圆圈分开的指令,它将从图的左侧开始,并在其返回起点之前绕着深色圆圈转一大圈。
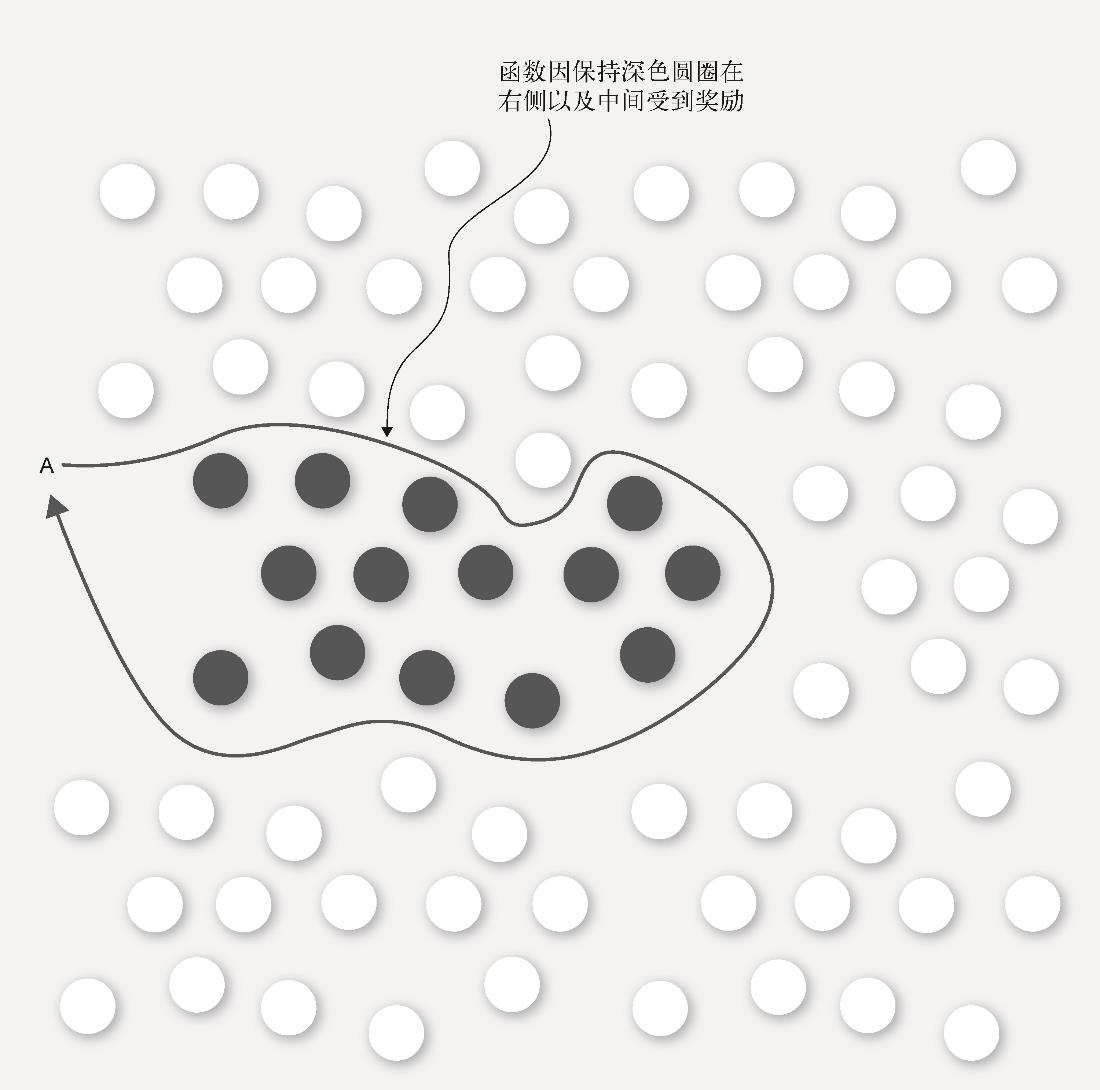
图1-5 识别数据集中相似元素集合的机器学习函数
函数表现正确时,我们就奖励它。我们可以将这个过程视为奖励深色圆圈出现在其右边的函数,惩罚深色圆圈出现在其左边的函数。如果你还奖励左侧出现浅色圆圈的函数,惩罚右侧出现浅色圆圈的函数,就可以更快地训练它。
因此,在这个背景下训练机器学习应用程序时,你要做的就是向系统展示大量的示例。该系统构建了数学函数来区分数据中的某些内容,这些区分的内容就是 目标变量 。函数区分出更多的目标变量时就会得到奖励,反之则会受到惩罚。
机器学习问题可以分为两种类型:
除了特征之外,就本书而言,机器学习的另一个重要概念是监督机器学习与无监督机器学习之间的区别。
顾名思义, 无监督 机器学习就是我们将大量数据交给机器学习应用程序并告诉它去做事情。聚类是无监督机器学习的一个示例。例如,我们向机器学习应用程序提供了一些客户数据,它决定如何将客户数据分组到具有相似客户的类别。相比之下,分类是 监督 机器学习的一个示例。例如,你可以利用销售团队历史致电客户的成功率数据作为训练机器学习应用程序如何识别最有可能接听电话的客户的一种方法。
注意 本书的绝大多数章节会专注于监督机器学习,在这种情况下,不是让机器学习应用程序挑选模式,而是为机器学习应用程序提供一个历史数据集,该数据集包含展示正确决策的样本。
利用机器学习解决业务自动化项目的最大优势之一是,你通常可以很容易地得到优质的数据集。在Karen的案例中,她有数千笔以前的订单可供提取,对于每笔订单,她都知道它是否已发送给技术审批人。在机器学习术语中,这种数据集称为 有标签的 数据集,这意味着每个样本都包含该样本的目标变量。就Karen而言,她需要的历史数据集是这样的:该数据集展示了购买了什么产品,是否由IT部门人员购买了产品,以及Karen是否将其发送给了技术审批人。